改进的M2det内窥镜息肉检测方法
2022-01-25张丽媛师为礼杨华民蒋振刚
王 博,张丽媛,师为礼,杨华民,蒋振刚
长春理工大学 计算机科学技术学院,长春 130022
结直肠癌已成为世界上第三大常见的恶性肿瘤,其中90%是由肠腺瘤引起的[1]。肠腺瘤属于肿瘤性息肉,在临床上肿瘤性和非肿瘤性息肉不易区分,所以息肉都会被摘除,待病理学确诊后再进一步分类。如果早期发现息肉并且进行医学干预,可以有效降低结直肠癌的发病率和病死率。医生通过内窥镜来检查患者的肠道,这项工作面临着两大挑战,其一,肠道内部环境极其复杂、不同患者的生理结构存在巨大差异、早期的息肉一般比较隐蔽等因素会给医生在做内窥镜检查时带来息肉漏检。其二,胃肠道疾病患者增多,导致内窥镜影像数据剧增,不易于人工处理,内窥镜检测技术十分依赖于内科医生的经验与能力,年轻医生可能无法胜任,因此在时间和精力上会给医生造成大量损耗。有科学依据表明,目前内窥镜检测技术误诊率高达26%[2],因此通过开发计算机辅助诊断技术去帮助内科医生进行息肉检测具有重大意义。
通过计算机辅助诊断实现内窥镜影像异常检测的方法分为两类:基于图像特征的方法和基于卷积神经网络(convolutional neural network,CNN)[3]的方法。早期很多内窥镜病灶检测都是基于图像特征的,整体流程可以概括为:图像预处理、特征提取、病灶检测。Shen等人[4]采用颜色直方图的统计变量作为特征,对检测单元的各通道进行轮廓波变换,在产生的子带中得到纹理特征和灰度共生矩阵,最后进行目标检测,该方法应用多尺度方法更好地实现了异常检测,但错误率高达13.99%。Tajbakhsh等人[5]提出了一种基于形状和上下文信息的息肉检测模型,首先利用上下文信息删除非息肉结构,之后采用形状信息进行息肉定位,实验结果表明敏感度为88%,有待提升。基于图像特征的方法首先需要大量的图像预处理,这是一个费时又费力的工作,其次需要提取图像的颜色特征和纹理特征,该方法不能充分地利用图像特征,导致识别精度较低,达不到临床要求。目前已经有很多国内外学者基于CNN的方法来实现病灶检测,该方法可以略去大量的图像预处理,自动地提取内窥镜图像特征,病灶检测的精度较高。Yuan等人[6]提出了一个旋转不变和图像相似性约束的密集连接卷积网络(RIIS-DenseNet),增强了训练样本学习特征和对应旋转版本之间的映射关系,将图像类别信息强加于特征上,以保持类内的小分散性,该方法精度达到了95.62%,但是没有标记出病灶的位置,本质上是一个分类任务。Mo等人[7]提出了一种更快的基于区域的卷积神经网络(Faster R-CNN),首先通过主干网络进行特征提取,其次采用区域生成网络(region proposal network,RPN)对图像进行粗略筛选,得到候选框,最后用基于区域的卷积神经网络(Fast R-CNN)[8]进行精确的识别与定位,可以有效地检测出息肉,但是对小型息肉存在漏检。基于CNN的息肉检测方法可以达到较为理想的精度和速度,但是一些方法只是对息肉进行分类操作,没有框出息肉位置,另一些方法对小型息肉检测不敏感。
本文采用基于CNN的方法来实现内窥镜影像异常检测,基于CNN的目标检测算法主要分为两大部分one stage类型[9]和two stage类型[10]。One stage网络首先将数据输入到模块中进行特征提取,然后将得到的特征用等同的网格进行划分,最后对每一个网格分别进行回归与分类,检测速度较快,但是存在正负样本不平衡问题。two stage网络首先通过主干网络进行特征提取,然后采用RPN筛选候选框,最后结合主网络进行精准的识别与定位,可以达到较高的目标检测精度,但是检测速度较慢。基于多级特征金字塔网络的单镜头目标检测器(a single-shot object detector based on multilevel feature pyramid network,M2det)[11]属于one stage类型网络,在自然场景下目标检测精度达到了较优的效果。本文采用改进的M2det方法进行息肉检测,实验结果表明本文方法优于其他方法,mAP达到了98.25%,本文贡献如下:
采用特征融合模块v1(feature fusion module v1,FFMv1)将三个不同层次的特征进行融合,用特征融合模块v3(feature fusion module v3,FFMv3)将稀疏U型模块(thinned U-shape module,TUM)生成的两个最大的有效特征层进行融合,该方法充分利用了图像特征,增强了图像特征的鲁棒性,从而提高了检测的精度。
在规模化特征聚合模块(scale-wise feature aggregation module,SFAM)中采用改进的压缩激励网络(squeeze-and-excitation network,SENet)[12],即空间和通道上的压缩激励网络(spatial and channel squeeze-andexcitation network,scSENet)[13],该方法可以给特征金字塔在通道和空间上分配权重,使有效的特征得到充分利用,抑制无用特征。
采用迁移学习来微调网络,用早停法(early stopping)[14]防止过拟合,用焦点损失函数(Focal loss)[15]计算分类损失,解决了正负样本不平衡问题,在多层特征金字塔网络(multi-level feature pyramid network,MLFPN)中采用Mish[16]激活函数。
1 实验方法
本文采用改进的M2det用于内窥镜息肉检测,首先进行内窥镜图像预处理,采用letterbox_image方法将尺寸不一的内窥镜图像变换到320×320,该方法不会产生图像信息丢失、图像形变,通过缩放、翻转、扭曲进行数据增强,M2det利用主干网络(backbone network)和多层特征金字塔网络(MLFPN)从输入的图像提取特征,根据学习到的特征生成边界框和类别分数。在MLFPN中,首先通过FFMv1模块将主干网络中的三个不同层次的特征进行融合,得到基础特征,其次将TUM模块生成的两个最大的有效特征层通过FFMv3模块进行特征融合,FFMv3融合的结果和基础特征通过FFMv2模块进行融合,得到多层次多尺度特征,最后通过SFAM模块将特征聚合成多层次的特征金字塔。在实验中,使用了8个TUM模块,采用VGG[17]作为主干网络,在MLFPN中引入了Mish激活函数,改进的M2det网络模型如图1所示。

图1 改进的M2det网络模型Fig.1 Improved M2det network model
1.1 改进的M2det
M2det是由特征融合模块(FFMs)、稀疏U型模块(TUMs)、规划特征聚合模块(SFAM)三部分组成。如图2(a)所示M2det在小型息肉以及复杂环境下具有漏检和误检,导致真阳性和检测精度降低,因此针对这个问题提出了改进的M2det方法,在主干网络中加入浅层特征Conv_3,特征融合模块中加入FFMv3模块,使特征得到了充分利用,在规模化特征聚合模块中加入scSENet注意力机制,使有用特征得到充分利用,抑制无用特征,在损失函数中加入Focal loss,解决了正负样本不平衡问题,如图2(b)所示,在复杂的环境下成功地识别出了小型息肉,基于M2det改进的细节具体如下。

图2 比对结果Fig.2 Comparison result
1.2 特征融合模块(feature fusion module,FFMs)
FFMs由FFMv1、FFMv2、FFMv3三部分组成,目的是进行特征融合。在FFMv1模块中,本文新增了浅层特征并且通过FFMv1模块将浅层特征、中层特征和深层特征进行融合,融合之前采用卷积来压缩通道数量,上采样操作增大特征尺寸,使其达到融合的标准,最后得到基础特征,该基础特征包含了三种不同深度的特征。FFMv2原理类似于FFMv1,差别是融合的特征不同,先通过1×1的卷积操作来压缩基础特征的通道,之后通过FFMv2模块将基础特征与FFMv3模块生成的特征进行融合,并将结果用作下一个TUM模块的输入,该操作可以充分地利用前面的有效特征和基础特征,本文新增FFMv3模块将TUM模块生成的最大的有效特征进行融合,在融合前,先将较小的有效特征进行上采样,使其达到同样尺寸,融合之后进行1×1的卷积操作,压缩通道大小为128,该操作可以充分地利用TUM模块生成的有效特征层。FFMv1、FFMv2和FFMv3模块的操作细节分别如图3(a)、(b)、(c)所示,其中蓝色模块的四个参数分别为输入通道、卷积核尺寸、步长大小、输出通道。

图3 特征融合模块Fig.3 FFMs model
1.3 稀疏U型模块(TUMs)
TUM模块采用了稀疏的U型结构,TUM模块分为编码操作和解码操作,编码由步长为2的一系列3×3卷积组成,在解码操作中将上采样的结果和在解码操作中同等尺寸的特征进行融合,此外,通过1×1的卷积层,增强学习能力,压缩通道数,每一个TUM模块都能输出多尺度特征,8个TUM模块就可以输出8个不同深度的多尺度特征,其中第一个TUM模块的输入只有基础特征,剩下的TUM模块的输入通过FFMv2和FFMv3来实现,多层次多尺度特征输出的计算公式如下:

其中,Xbase为基础特征,为第l个TUM模块输出的最大尺度的特征,和分别为第l-1个TUM模块输出的次大尺度和最大尺度的特征,L为TUM最大数,Tl为第l个TUM模块的操作,F为FFMv2操作,Y为FFMv3操作,具体操作细节如图4所示。
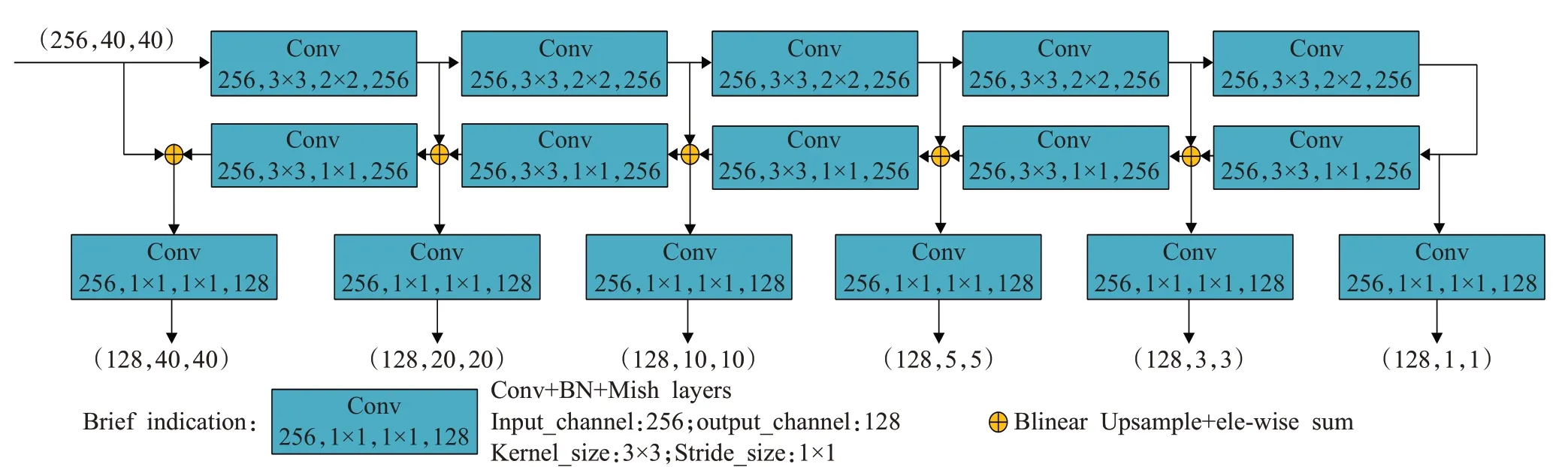
图4 稀疏U型模块Fig.4 TUM model
1.4 规模化特征聚合模块(SFAM)
SFAM模块的目的是将TUMs生成的多层次多尺度特征聚合成多层次特征金字塔,如图5所示。首先SFAM模块将尺寸相同的有效特征层进行聚合,聚合后的特征金字塔可以表示为X=[X1,X2,…,Xi],其中Xi=为第i个尺度的特征,l为层数,Concat为聚合操作,RWi×Hi为空间大小,因此每一个特征金字塔都包含不同深度的特征。然后对特征金字塔通过注意力机制(SENet)进行通道上的权值分配,首先对各个通道上的注意力机制进行调整,判断每一个通道数应该有的权重,在squeeze步用全局平均池化来生成通道统计信息z∈RC,为了更好地获得通道依赖,通过两个1×1的全连接层学习注意力机制,得到通道上的权重分配Sc:

图5 规模化特征聚合模块Fig.5 SFAM model

其中,δ为ReLU激活函数,σ为sigmoid激活函数,W1、W2为通道上的权重,Sc为通道上的权重分配。通过对输入的Xi使用激活Sc重新加权得到通道上的注意力机制Yc:

其中,Xi为输入,Sc为通道上的权重分配,Yc为通道上的注意力机制,Fc为通道上的操作。
本文新增了特征金字塔在空间上的权值分配,首先对各个空间上的注意力机制进行调整,判断每一个空间应该有的权重,统计空间信息z∈RS,然后进行1×1×1的卷积操作,得到空间上的权重分配Ss:

其中,σ为sigmoid激活函数,W3为空间上的权重,Ss为空间上的权重分配。通过对输入的Xi使用激活Ss重新加权得到空间上的注意力机制Ys:

其中,Xi为输入,Ss为空间上的权重分配,Fs为空间上的操作,Ys为空间上的注意力机制。
最后,将特征金字塔在通道上的注意力机制Yc和空间上的注意力机制Ys进行张量上的相加,得到最终的注意力机制Ysc:

1.5 损失函数
One stage目标检测方法存在正负样本不平衡问题,本文新增Focal loss解决以上问题,在训练时采用Focal loss计算分类损失,降低分类损失,Focal loss计算如下:
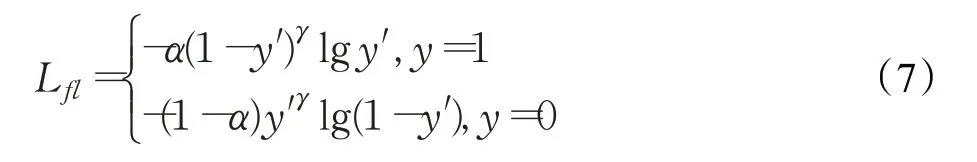
其中,y′是预测输出,y是真实样本的标签,α是正负样本权重,γ是易分类样本和难分类样本权重。
采用Smooth L1[10]计算回归损失,当预测框与真实样本标签差值过大时,梯度值不至于过大,当预测框与真实样本标签差值很小时,梯度足够小,训练时可以收敛得更快,loss对离群点、异常值不敏感,可控制梯度的量级使训练时不容易跑飞,计算公式如下:

其中,x是预测框与真实样本标签的差值。最终本文采用的损失函数是Focal loss与Smooth L1的结合体:

2 实验
2.1 实验数据集
本文采用的数据集是CVC-Clinic(CVC15)[18],由西班牙巴塞罗那医院从29个内窥镜视频中挑选出来612个384×288的静止帧,标签是由西班牙巴塞罗那计算机视觉中心(CVC)标记,该数据集用于内窥镜视频息肉检测的MICCAI2015和SBI2015子挑战。
2.2 模型训练
在训练数据集不足以表征所有样本特征的情况下,会导致网络过拟合,因此本文采用迁移学习的方法来训练网络,首先用VOC数据集训练M2det模型,得到相应的权重,然后用CVC15数据集来微调参数即可。采用早停法(early stopping)来避免继续训练导致的过拟合,将原始的训练数据集划分为训练集和验证集,比例为9∶1,每次迭代都计算验证损失,当验证损失值达到局部最优时,继续迭代6次,如果模型不再收敛就停止训练。模型参数采用Adam[19]进行优化,batch size设置为2,学习率初始化为1×E-4,当2次迭代优化指标不下降时,使学习率衰减5×E-5,循环迭代步数设置为50,当迭代步数达到30时,重新设置学习率为1×E-5,采用python的keras框架在DGX-Station上训练。
2.3 模型检测
通过SFAM模块得到6个特征金字塔,每一个特征金字塔包含不同深度的特征,即获得了6个有效的特征,对每个有效特征层都进行priors×4的卷积和priors×classes的卷积,其中priors、classes分别为先验框个数和息肉类别加背景数量,实验中设置priors、classes分别为6和2,priors×4卷积用来预测每个网格上每一个先验框的变化情况,priors×classes卷积用来预测每个网格上每一个预测框中目标对应的类别。
通过先验框与prioris×4的卷积操作得到了预测结果,然后将预测结果对应真实框进行调整,其中4个参数分别为先验框中心相对于真实框中心的偏移值x、y,先验框宽高相对于真实框的偏移值w、h。在特征图上进行等同大小的网格划分,用网格中心坐标加上x、y偏移量得到候选预测框中心,再将先验框的宽高进行w、h尺度偏移,就可以得到候选预测框。由于候选预测框数量比较大,因此要将候选预测框按照分数进行排序并且进行非极大值抑制(NMS)[20]操作得到最终的预测框。
2.4 模型评估指标
根据测试样本的输出类别与真实标签的类别进行对比,得到四种结果,真阳性(TP)表示正确判断出息肉,假阳性(FP)表示把背景误判为息肉,真阴性(TN)表示正确判断出背景区域,假阴性(FN)表示把息肉误判为背景。精确率(precision,P)表示为正确检测到的息肉(TP)占被检测到的息肉(TP+FP)的比例,召回率(recall,R)表示为被正确检测到的息肉(TP)占应该被检测到的息肉(TP+FN)的比例,计算公式如下所示:

由于精确率和召回率是相互制约的,因此采用Fsorce进行调和,F1-score中P和R的权重相同,因此精确率和召回率都重要,F2-score更加看重召回率,计算公式如下:
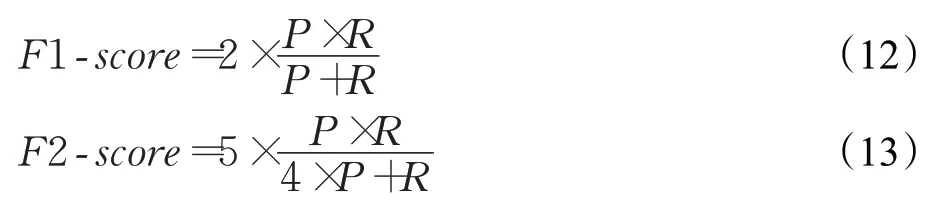
平均精度均值(mean average precision,mAP)是目标检测方法最重要的评估指标,在不同置信度阈值下获得精确率和召回率,以P、R为横纵作标轴绘制PR曲线,PR曲线与横纵作标轴围成的面积就是mAP值,mAP计算公式如下:

对数平均误检率(log-average miss rate,Lamr),xn是第n个图像的误检率,计算公式如下:

2.5 实验结果与分析
超参数设置的好坏对网络至关重要,本文对比了在不同置信度(confidence)和批量大小(batch size)设置下对网络性能的影响。置信度和类别分数都介于0到1之间,若预测框包含某类别目标分数大于置信度,则保留该分数,当置信度较大时,真阳性会下降,当置信度较小时,假阳性会上升,因此选择一个合适的置信度至关重要,设置置信度分别为0.3、0.4、0.5进行实验性能对比,综合各项评估指标,置信度取值0.4最为合适,实验结果如表1所示。

表1 不同confidence的实验对比Table 1 Experimental comparison of different confidence
batch size的取值会直接影响模型的泛化性能,决定梯度下降的方向,大的batch size更新量不足,泛化能力差,梯度不易修正,小的batch size训练速度慢,网络不易收敛,因此选择一个合适的batch size至关重要,由于网络对2的次幂的batch size训练最优,因此在置信度取值0.4的情况下,batch size分别取值2、4、8,对比结果如表2所示,当batch size为2时,各项评估指标都达到了最优。

表2 不同batch size的实验对比Table 2 Experimental comparison of different batch sizes
改进的M2det是由三部分组成的,因此要分别验证每一部分的改进对模型性能的影响:其一,FFMs模块的目的是实现特征融合,将浅层、中层、深层特征进行融合,达到了不同特征之间的优势互补效果,增强了图像特征的鲁棒性,充分利用了图像的特征信息。其二,在SFAM模块中通过scSENet在特征金字塔的通道和空间上增加注意力机制,使更有效的信息得到较大的权重,抑制无用的信息。其三,在训练时采用Focal loss计算分类损失,可以有效地解决正负样本不平衡问题。对比结果如表3所示,在M2det基础上分别单独加入FFMs、scSENet、Focal loss各项评估指标均有较大提升,最后将这三个部分进行整合,TP、Recall、Lamr、mAP都达到了最优,除了Precision评估指标较低外,其他评估指标均有提升。

表3 改进的M2det结果对比Table 3 Improved M2det result comparison
一个TUM模块生成六个有效特征层,当TUM数量较小时,生成的有效特征层较少,存在图像特征利用不足的情况,当TUM数量较大时,参数计算量较大,会对网络运行速度产生影响,针对TUM模块个数对网络性能产生影响问题,TUM个数分别采用4、8进行训练,实验结果如表4所示,当TUM个数取8时各项指标达到了最优。

表4 不同TUM个数的实验对比Table 4 Experimental comparison of different TUM Numbers
通过前面的实验,本文设置confidence为0.4,batch size为2,TUM个数为8,采用改进的M2det进行训练,与目前主流的息肉目标检测算法进行比较,其中ASU、CUMED、OUS[21]方法都来自于内窥镜视频息肉检测的MICCAI子挑战赛,对比实验结果如表5所示,在Precision、Recall评估指标上分别略低于ASU、CUMED方法,但是本文在F1-score、F2-score、mAP评估指标上都达到了最优,表明本文方法可以有效地检测出息肉,PR曲线如图6所示。

图6 PR曲线Fig.6 PR curve

表5 不同算法的检测性能对比Table 5 Comparison of detection performance of different algorithms %
本文具有代表性的检测结果如图7所示,其中绿色框是真实标签,蓝色框是预测结果,红色框是误检结果。文献[7]对于小型结肠息肉存在漏检,本文通过FFMs进行特征融合,得到多层次多尺度特征,从而充分地利用了图像特征,可以有效地检测出小型和对比度低的息肉,如图7(a)、(b)所示;在特征通道和空间上采用scSENet注意力机制,将有用的特征保留下来,抑制无用特征,在形状不规则、含有食物残渣和胃液的场景下可以正确地检测出息肉,如图7(c)、(d)、(e)、(f)所示;在不止一个息肉和息肉被部分遮挡的场景下还可以成功地检测出息肉,如图7(g)、(h)所示,由此可见本文的M2det具有较强的鲁棒性。总体来看本文在内窥镜息肉检测方向取得了一些成果,但是也存在一些不足,对于对比度低且形状不规则的图像存在误检,如图7(i)所示;对于含有高强度反光且形状类似息肉的图像存在误检,如图7(j)所示,这些误检会造成假阳率增大,进而影响检测精度。在今后的研究工作中,针对图7(j)的场景,打算加入颜色特征,通过控制阈值的方法滤除掉高强的反光特征,方法可行性有待商榷。

图7 检测结果Fig.7 Detection results
3 结束语
本文提出一个有效的内窥镜息肉检测方法,通过FFMs模块融合不同深度特征,可以增强图像特征的鲁棒性,在SFAM模块中加入scSENet注意力机制,给有用的特征分配较大的权重,抑制无用特征,在分类损失函数中采用Focal loss解决了正负样本不平衡问题,实验结果表明,该方法可以有效地识别和定位出息肉,并取得了较高的精确度,在CVC15数据集上mAP、F1-score、F2-score分别达到了98.25%,97.30%,97.98%,因此在内窥镜检查时应用该方法可以有效地降低息肉漏检的风险。
