基于双判别器加权生成对抗网络的图像去模糊方法
2022-01-25黄梦涛
黄梦涛,高 娜,刘 宝
基于双判别器加权生成对抗网络的图像去模糊方法
黄梦涛,高 娜,刘 宝
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
原始生成对抗网络(generative adversarial network, GAN)在训练过程中容易产生梯度消失及模式崩溃的问题,去模糊效果不佳。由此本文提出双判别器加权生成对抗网络(dual discriminator weighted generative adversarial network, D2WGAN)的图像去模糊方法,在GAN的基础上增加了一个判别器网络,将正向和反向KL(Kullback-Leibler)散度组合成一个目标函数,引入加权的思想调整正向和反向KL散度的比例,利用两个散度的互补特性,在学习清晰图片过程中避免不良模式的形成。实验结果表明,与现有方法相比,本文方法能更真实地恢复图像细节部分,且在评价指标峰值信噪比和图像结构相似度上有更好的表现。
生成对抗网络;加权;双判别器;图像去模糊;
0 引言
图像去模糊技术是指将得到的模糊图像通过一定技术恢复出它所对应的清晰图像。目前图像去模糊在智能监控[1-2]、无人机[3]、遥感影像[4-5]以及医疗图像[6]等领域具有很重要的作用。由于拍摄设备晃动或者目标物体的运动,难免会获得模糊的图片,不利于后续的处理。因此,对图像去模糊技术的研究具有一定的现实意义。
传统的图像去模糊方法一般假设模糊核已知,利用模糊核与模糊图像进行反卷积得到清晰图像。此类方法为非机器学习的方法,其中起源较早、应用最为广泛的经典图像去模糊方法之一为LR(Lucy-Richardson)算法[7-8],它假设模糊图像服从泊松分布,通过最大似然估计迭代求解得到复原图像。在简单图像中,LR算法可以有效还原出清晰图像,但图像较复杂时,复原的图像容易产生振铃效应,随着迭代次数的增加,振铃效应趋于严重。
随着机器学习与图像处理技术的快速发展,尤其是2014年生成对抗网络[9](Generative Adversarial Networks,GAN)的出现,使得图像去模糊应用不再需要假设模糊核信息,因此,机器学习方法为图像去模糊的发展开阔了思路。GAN主要应用在图像超分辨率重建、迁移学习、图像修复等领域[10-13]。GAN中生成器所定义的损失函数等价于真实分布data与生成器生成分布G之间的JS(Jensen-Shannon)散度,优化过程中会产生梯度消失和模式崩溃的问题,导致训练不稳定,影响去模糊效果。Kupyn等人将条件生成对抗网络[14]应用到图像去模糊中,对Isola等人提出的Pix2Pix网络框架做出适当修改,提出Deblur GAN网络[15],是目前图像去模糊领域效果好的方法之一。相比传统GAN,用此方法去模糊后有更好的视觉体验,但在实验中发现,使用Deblur GAN复原图像时,会丢失部分细节信息。
针对上述问题,本文提出一种基于双判别器加权生成对抗网络(D2WGAN)的图像去模糊方法,在原始生成对抗网络的基础上,额外加入一个判别器,将KL(Kullback-Leibler)散度与反向KL散度进行结合,并引入加权的思想重构目标函数,期望通过调节权值系数来平衡正向和反向KL散度的占比,更好地复原出清晰图像。
1 本文方法
1.1 D2WGAN网络结构
为提升图像去模糊的性能,本文提出基于双判别器加权生成对抗网络(D2WGAN)的图像去模糊方法,将真实分布data与生成分布G之间的KL散度和生成分布G与真实分布data之间的KL散度,即反向KL散度组合成一个目标函数。利用KL散度生成的数据会涵盖真实数据的多种模式,然而,也会产生一些真实数据中不存在的样本;而利用反向KL散度,生成的数据更倾向于真实数据的单一模式,会忽略其他模式,产生模式崩溃的问题[16]。因此,两者相互补充,具有互补特性。理论证明,反向KL散度与JS散度具有相同的性质[17],因此本文在引入新的判别器后,在正向KL散度权值为0,反向KL散度权值为1时,理应和GAN具有相似的结果。如若将KL散度与反向KL散度结合,其互补特性会缓解GAN中的模式崩溃问题,因此,图像去模糊的性能也必然会提升。
D2WGAN的模型结构如图1所示,其输入不再是原始GAN的噪声数据,而是模糊图片。生成器会依据输入生成自己学习到的较为清晰的图像(),随后将生成器生成的图像()以及模糊图像所对应的清晰图像输入判别器1、2中。判别器1对清晰图像得高分,对生成器生成的图像()得低分;判别器2对生成器生成的图像()得高分,对清晰图像得低分。生成器的目的是使生成的()图像同时欺骗判别器1、2,三者进行互相博弈,直到达到三者的平衡。、1和2都为多层感知器,整个模型通过反向传播进行训练。
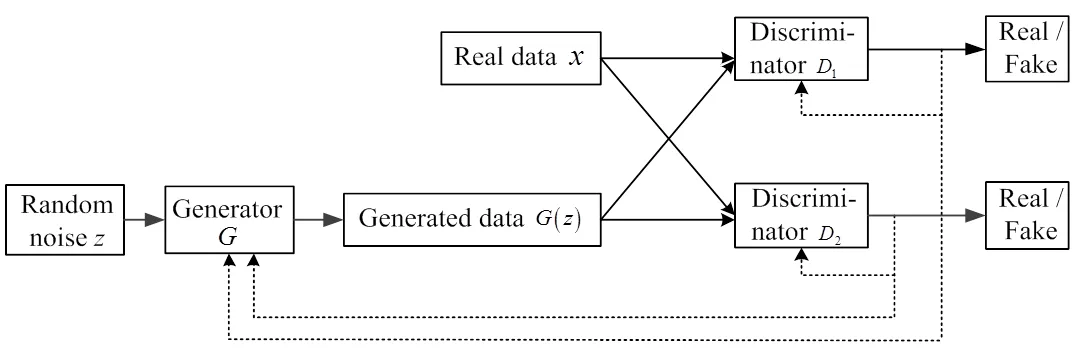
图1 D2WGAN网络模型结构
本质上,D2WGAN将与()之间的KL散度和反向KL散度进行加权融合,通过调节权值系数,从而达到更好的去模糊的效果。本文受双判别器生成对抗网络[16]的启发,构建D2WGAN损失函数如下:
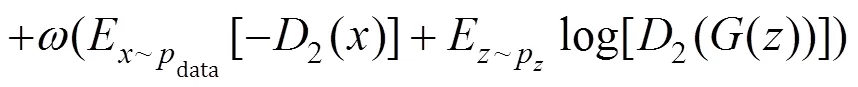
D2WGAN引入了两个超参数和,其中+=1,0≤,≤1,引入加权思想,结合正向KL散度和反向KL散度的优势,使生成的模式多样化。
接下来验证D2WGAN算法在最优判别器下,通过最小化模型与真实数据之间的KL散度和反向KL散度,生成器可以恢复出真实数据。
首先在固定生成器时,最优的判别器1D()和2D()为:
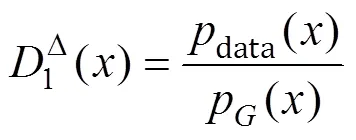
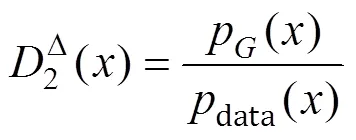
其次在最优判别器基础上,最优生成器为:
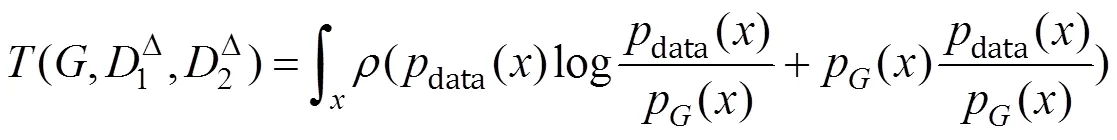
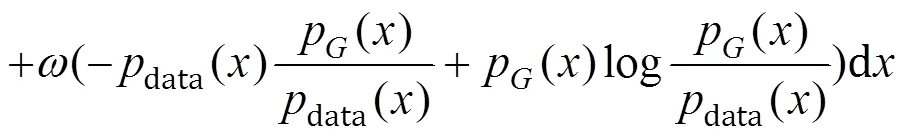
因+=1,
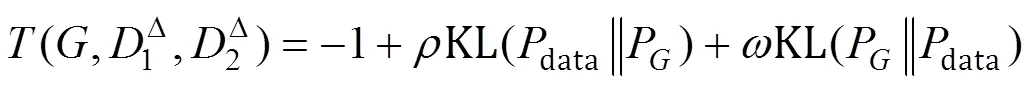
理论证明在生成器能学习到最优判别器时,当且仅当P=data时,KL散度和反向KL散度为0,(,1D,2D)=-1,得到全局最小值,即生成模型学习到了真实数据分布。此时判别器无法区分生成分布与真实分布,对两分布都返回相同的得分为1。
1.2 生成器模型搭建
本文研究的生成器模型如图2所示,主要任务是在输入模糊图像时,学习清晰图像的分布,生成的近似分布()。生成器模型具体搭建步骤如下:
1)对输入的3×256×256的模糊图片进行一次卷积核大小为7×7,卷积核数量为64,步长为1的卷积;一次实例正则化层和修正线性单元(Rectified Linear Unit,ReLU)激活函数。
2)两个卷积核数量分别为128、256对应的卷积核大小为3×3,步长为2的二维卷积,实例正则化和ReLU激活函数。
3)9个由一个卷积核大小为3×3,卷积核数量为256,步长为1的卷积层,一个标准化层和一个ReLU激活层,一个Dropout层随机失活比例为0.5组成的ResBlock块。
4)两个卷积核数量分别为128、64对应的卷积核大小为3×3,步长为1的反卷积,实例正则化和ReLU激活函数。目的是将卷积后的小尺寸高维度特征图恢复到原始的尺寸。
5)为提高运算速度,本文生成网络为全卷积网络,不使用全连接层和pooling层,最后一层经过一次卷积核大小为7×7,卷积核数量分别为3,步长为1的反卷积,使用Tanh作为激活函数。
因使用Batch Normalization[18]进行标准化训练可能会导致生成的图像有伪阴影,而且在图像去模糊中,去模糊效果依赖于模糊图像对应的清晰图像,本文使用Instance Normalization[19]进行归一化操作可以加速模型收敛,并且保持每个图像实例之间的独立。
1.3 判别器模型搭建
普通的判别器最后一层为全连接层,输出为输入样本来自真实数据的概率,即结果为一个实数。本文将普通的判别器换成了全卷积网络,采用PatchGAN[20]判别器,将输入映射为×的patch矩阵块,将得到的patch块求均值,为判别器最后的输出,这样在训练的时候能更好的恢复细节。其中每一个patch块代表了一个感受野,可以追溯到原图的某一个位置。文中两个判别器使用同一个网络模型,因损失函数不同,其优化方向也不同。判别器模型结构如图3所示,网络结构如表1所示,输入为256×256的三通道图像,经过5层卷积网络,卷积核大小均为4×4,输出为一个30×30的矩阵,代表着图像中一个比较大的感受野,相比于输出单个值的鉴别器效果更好。非线性激活函数使用带泄露修正线性单元(Leaky ReLU)[21],斜率设为0.2。
1.4 损失函数
本文使用对抗性损失和内容损失结合的损失函数,其中对抗损失着重于恢复图像的纹理细节,感知损失着重于恢复图像的内容。损失函数表达式如下:
=GAN+*X(6)
式中:GAN为对抗性损失;X为内容损失;为比重参数,文中设置为100。
对抗损失函数使用两个判别器,这两个判别器的模型结构基本相同,因其训练时损失函数不同,所以这两个判别器会朝着不同的方向优化。第一个判别器损失函数为:
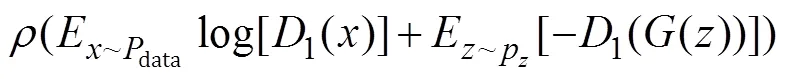
式中:0≤r≤1,该判别器主要侧重于真实数据。第二个判别器损失函数为:
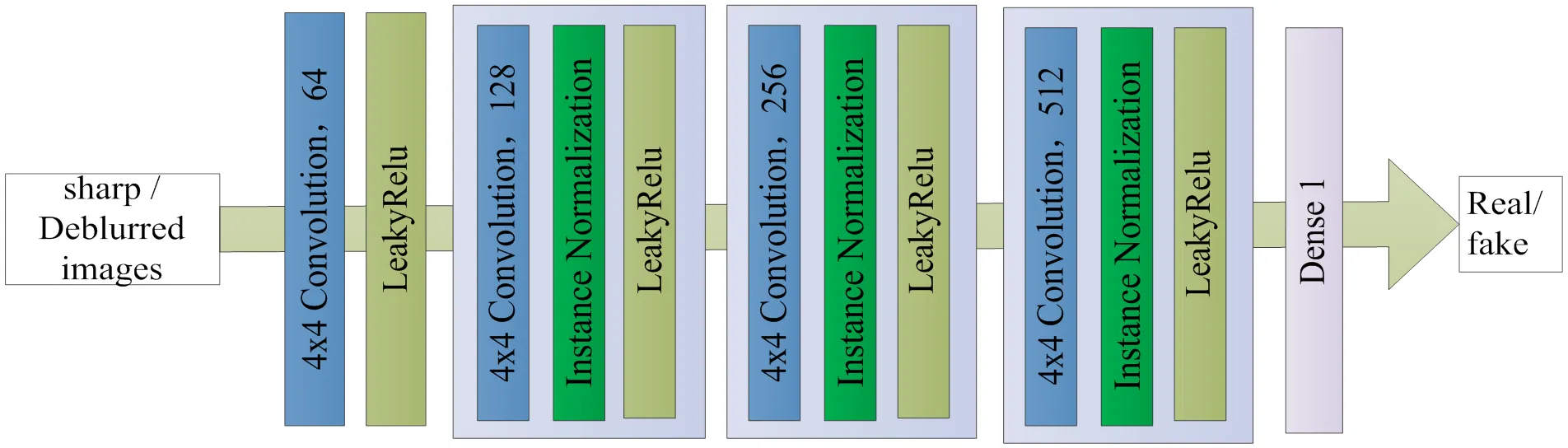
图3 判别器模型结构

表1 判别器网络结构
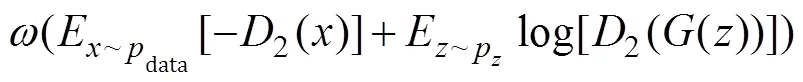
式中:0≤≤1,该判别器主要侧重于生成器生成的数据。两个判别器之间通过加权连接,两个参数之间关系为:+=1。
内容损失函数:采用Johnson等人提出的感知损失[22],该损失函数严格来说也是一种L2损失,多用在图像风格转换中。将清晰图像和修复的模糊图像分别输入训练好的VGG-19网络[23],计算每一层特征图之间的误差,最终的累计误差就是感知损失,计算公式如下所示:
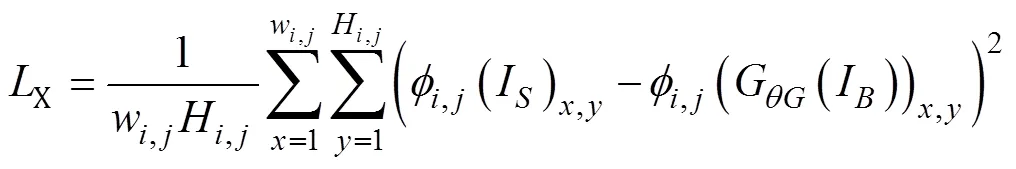
式中:,j是VGG19网络在第个最大池化层之前通过第个卷积之后产生的特征图;w,j和H,j是特征图的维度;I是输入的模糊图像;I是经过生成器模型产生的清晰图像。
2 实验
2.1 数据集与训练细节
本文所使用的数据集为Nah等人提出的GOPRO数据集[24],由GOPRO相机拍摄的33段不同场景的清晰视频而来,其中的22段场景视频作为训练集,11段场景视频作为测试集。对每段视频相邻的7~13帧图像取平均值得到模糊图像,一共生成了3214对模糊-清晰图像,分辨率为1280×720。其中,训练数据有2103对,测试数据有1111对。
为了将每张模糊图像与清晰图像各个像素一一对应,在输入数据集前,首先将模糊图片与清晰图片合并为一张图片,如图4所示。其次将输入的合并后的图片裁剪为1280×360,最后在裁剪后的图片上随机选取256×256大小的模糊图像与对应的清晰图像进行训练。

图4 合并后的图片
此次实验在Windows 10操作系统下进行,处理器为Inter Xeon E5-2620 v4,显卡为NVIDIA GeForce RTX 2080Ti,使用pycharm编辑器,使用PyTorch深度学习框架。训练迭代300次,初始学习率为0.0001,前150次迭代的学习率采用初始值,后150次迭代的学习率按线性衰减至0,选择Adam[25]优化算法,批量大小设置为8。
2.2 实验结果
GOPRO数据集中测试集为GoPro摄像机拍摄的11段视频,共1111张图像组成。本文在经过多次训练后,发现权值在=0.1,=0.9时去模糊效果最好,实验结果如图5所示,本文方法的去模糊效果较明显,可以有效地恢复图像的细节部分。
本文将D2WGAN算法与原始GAN、LR滤波及DeblurGAN方法的图像去模糊效果进行对比,结果如图6所示。表2为图6中不同方法的峰值信噪比(peak signal to noise ratio,PSNR)与图像结构相似度(structural similarity,SSIM)。
图6(b)中LR算法进行去模糊时,边缘的高频信息有所改善,但整体会出现锐化的现象,视觉体验一般;图6(c)中GAN在复原图像时会出现棋盘伪影的现象;图6(d)中DeblurGAN方法整体复原效果较好,但仍有部分细节没有复原出来。图6(e)中本文方法去模糊的细节恢复较好,基本没有棋盘伪影、锐化过度等视觉效果,恢复的图像更加真实,而且从表2的评价指标中可以看出,对比LR算法,本文方法有质的飞跃。

图5 本文方法去模糊前后效果对比图

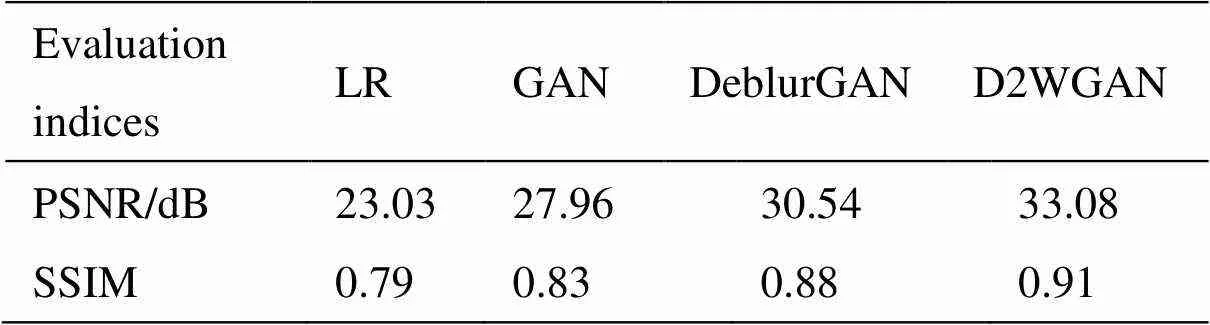
表2 不同方法对图6中单张图像的质量评价结果
实验中LR滤波算法在迭代150次时处理一张图片平均用时约2.5min,而本文测试集共1111张图片,如果使用LR滤波在1111张图片上测试,大约需要46h,时间代价太大。因此本文只对GAN、DeblurGAN以及本文方法在GOPRO验证集上测量平均PSNR与SSIM值,结果如表3所示。
从表3可以得知,相比DeblurGAN方法,本文方法在评价指标PSNR上提升了约6.7%,在SSIM上提升了约9%,其结果说明本文提出的双判别器加权生成对抗网络方法是有效的。
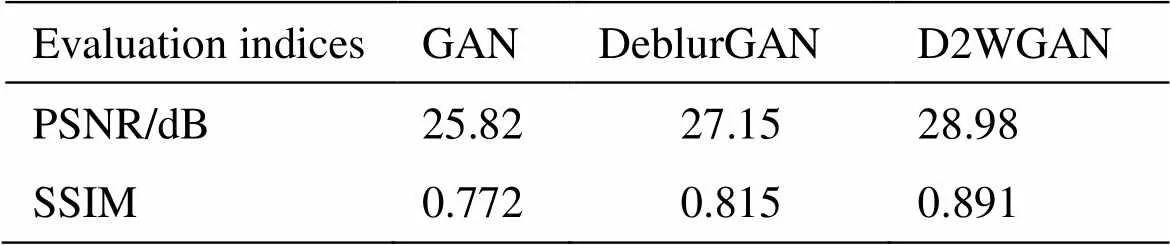
表3 不同方法在GOPRO验证集上的图像质量评价
3 结论
为解决现有方法在恢复模糊图像时仍存在的边缘模糊现象,本文在原始生成对抗网络的基础上,增加了一个判别器,引入加权的思想,提出基于双判别器加权生成对抗网络的图像去模糊方法。通过搭建生成器、判别器模型,引入双判别器对抗损失和感知损失来恢复图像的细节部分。实验中使用GOPRO数据集来训练模型,将本文方法与原始GAN、LR算法及DeblurGAN方法进行对比,发现本文方法可以有效地恢复出运动模糊图像的细节部分,且没有棋盘伪影、锐化等现象,提升了图像视觉效果,在评价指标PSNR与SSIM上有更好的表现。本文方法简单且通用,为图像去模糊的发展提供了一种新的思路。
[1] 李明东, 张娟, 伍世虔, 等. 基于RANSAC变换的车牌图像去模糊算法[J]. 传感器与微系统, 2020, 39(2): 153-156, 160.
LI Mingdong, ZHANG Juan, WU Shiyu, et al. A deblurring algorithm for license plate image based on RANSAC transform[J]., 2020, 39(2): 153-156, 160.
[2] 马苏欣, 王家希, 戴雅淑, 等. 监控视频下模糊车牌的去模糊与识别探析[J]. 信息系统工程, 2019(11): 111-113.
MA Suxin, WANG Jiaxi, DAI Yashu, et al. Research on the deblurring and recognition of fuzzy license plates under surveillance video[J]., 2019(11): 111-113.
[3] 裴慧坤, 颜源, 林国安, 等. 基于生成对抗网络的无人机图像去模糊方法[J]. 地理空间信息, 2019, 17(12): 4-9, 155.
FEI Huikun, YAN Yuan, LIN Guoan et al. Deblurring method of UAV image based on generative confrontation network[J]., 2019, 17(12): 4-9, 155.
[4] 黄允浒, 吐尔洪江, 唐泉, 等. 一种基于à trous算法的遥感图像模糊集增强算法[J]. 计算机应用与软件, 2018, 35(3): 187-192, 246.
HUANG Yunhu, TU Erhong, TANG Quan, et al. A remote sensing image fuzzy set enhancement algorithm based on à trous algorithm[J]., 2018, 35(3): 187-192, 246.
[5] 张广明, 高爽, 尹增山, 等. 基于模糊图像和噪声图像的遥感图像运动模糊复原方法[J]. 电子设计工程, 2017, 25(18): 82-86.
ZHANG Guangming, GAO Shuang, YI Zengshan, et al. Remote sensing image motion blur restoration method based on blurred image and noise image[J]., 2017, 25(18): 82-86.
[6] 吴庆波, 任文琦. 基于结构加权低秩近似的泊松图像去模糊[J]. 北京航空航天大学学报, 2020, 46(9): 1701-1710.
WU Qingbo, REN Wenqi. Poisson image deblurring based on structure-weighted low-rank approximation[J]., 2020, 46(9): 1701-1710.
[7] RICHARDSON W. Bayesian-based iterative method of image restoration[J]., 1972, 62(1): 55-59.
[8] LUCY B. An iterative technique for the rectification of observed distributions[J]., 1974, 79(6): 745-754.
[9] IAN G, JEAN P, MEHDI M, et al. Generative adversarial nets[C]//27th(NIPS), 2014: 2672-2680.
[10] LEDIG C. Photo-realistic single image super-resolution using a generative adversarial network[C]//(CVPR), 2017: 105-114.
[11] LI Y, ZHAO K, ZHAO J. Research on super-resolution image reconstruction based on low-resolution infrared sensor[J]., 2020(8): 69186-69199.
[12] LI Z, WANG W, ZHAO Y. Image Translation by Domain-Adversarial Train[J]., 2018: 1-11. Doi: 10.1155/2018/8974638.
[13] YANG T, CHANG X, SU H, et al. Raindrop removal with light field image using image inpainting[J]., 2020(8): 58416-58426.
[14] Mirza M, Osindero S. Conditional generative adversarial nets[J/OL].: 1411.1784, 2014,https://arxiv.org/abs/1411.1784.
[15] Orest K, Volodymyr B, Mykola M, et al. DeblurGAN: Blind motion deblurring using conditional adversarial networks[C]//, 2018: 8183-8192.
[16] NGUYENT, LE T, VU H. Dual discriminator generative adversarial nets[C]//29th, 2017: 2667-2677.
[17] Lucas T, Aäron V, Matthias B. A note on the evaluation of generative models[J/OL].: 1511.01844, 2015.https:// arxiv.org/abs/1511.01844
[18] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//ICML'15:32nd, 2015, 37: 448-456.
[19] Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: the missing ingredient for fast stylization[C]//(CVPR), 2016: 1-13.
[20] LI C, WAND M. Precomputed Real-time texture synthesis with markovian generative adversarial networks[C]//, 2016: 702-716.
[21] Maas L, Hannun Y, Ng Y. Rectifier nonlinearities improve neural network acoustic models[C]//., 2013: 1-3.
[22] JOHNSON J, ALAHI A, FEI L. Perceptual losses for real-time style transfer and super-resolution[C]//, 2016: 694-711.
[23] SUN J, CAO W, XU Z, et al. Learning a convolutional neural network for non-uniform motion blur removal[C]//(CVPR), 2015: 769-777.
[24] NAH S, KIM H, LEE M. Deep multi-scale convolutional neural network for dynamic scene deblurring[C]//(CVPR), 2017: 257-265.
[25] Kingma D, Ba J. Adam: A method for stochastic optimization[C]//(ICLR), 2015: 1-15.
Image Deblurring Method Based on a Dual-Discriminator Weighted Generative Adversarial Network
HUANG Mengtao,GAO Na,LIU Bao
(College of Electrical & Control Engineering, Xi’an University of Science and Technology, Xi’an 710054, China)
The original generative adversarial network (GAN) is susceptible to the problems of vanishing gradients and mode collapse during the training process, and its deblurring effectiveness is poor. This study proposes an image deblurring method using a dual-discriminator weighted GAN. To extend the original GAN, a discriminator network is added to combine the forward and reverse Kullback–Leibler (KL) divergences into an objective function, and weights are used to adjust the ratio of forward and reverse KL divergences to leverage the complementary characteristics of the two divergences to avoid the formation of undesirable patterns in the process of learning clear pictures. Theoretical analysis proves that when an optimal discriminator is given, the difference between the forward and reverse KL divergences between real and generated data can be minimized. Experimental results demonstrate that compared to the existing methods, the proposed method can restore the details of an image more realistically and provides better performance in terms of the evaluation indexes of peak signal-to-noise ratio and structural similarity.
generation adversarial network, weighted, dual discriminator, image deblurring
TN911.7
A
1001-8891(2022)01-0041-06
2021-01-24;
2021-04-08.
黄梦涛(1965-),女,教授,博士,主要从事基于图像的测量与识别和智能系统等方面的研究。E-mail:huangmt@xust.edu.cn
刘宝(1983-),男,讲师,硕士生导师,主要从事多源信息融合、图像处理等研究。E-mail:xiaobei0077@163.com
陕西省重点研发计划项目(2019GY-097、2021GY-131);西安市科技计划项目(2020KJRC0068);榆林市科技计划项目(CXY-2020-037)。
