基于随机森林的航站楼负荷预测及特征分析
2022-01-23杨胜维吴利瑞刘东
杨胜维 吴利瑞 刘东
同济大学机械与能源工程学院
航站楼作为典型的公共交通建筑,每平方米耗电量远远高于普通公共建筑,其中空调系统运行电耗占比最大,为61%[1]。航站楼空调负荷中新风负荷和人员负荷之和占比为45%~60%[2],客流量的变化对实际负荷需求的有显著的影响[3]。而航站楼区域供冷系统水力半径大,长距离的冷冻水输送会导致冷源供应侧和需求侧的延迟较大,传统反馈调节的控制方式不能反映系统的实时负荷变化[4]。通过准确的负荷预测建立前馈的控制策略是应对这一问题的有效方法。本文针对航站楼空调负荷特点,建立了随机森林负荷预测模型,并分析了不同的输入特征选择对模型预测准确性及效率的影响,为空调设备实际运行调控及优化提供指导依据。
1 随机森林算法
随机森林是一种并行式集成学习算法,在以分类回归决策树(CART)为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择,由森林中所有决策树投票得出结果。随机森林的泛化性能强、简单易实现、计算开销小,在很多分类、回归任务当中具有较高的准确度[5]。
1.1 CART 决策树
决策树是 Breiman L 等人于 1984 年提出的一种决策树学习算法,使用“基尼指数”来选择划分属性。假设数据集D包含m个类别,则其基尼指数GD的计算公式为:
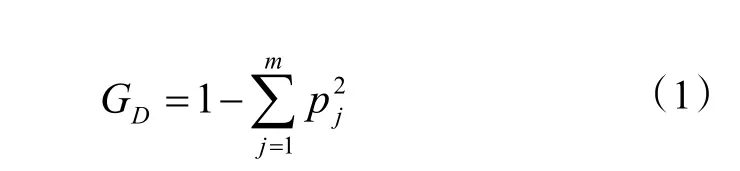
式中:pj为j类元素出现的频率。
基尼指数反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,基尼指数越小,数据集D的纯度越高。因此,在m个类别中,挑选基尼指数最小的类别作为最优划分属性。
1.2 随机森林算法流程
随机森林在 CART 决策树的基础上引入了Bagging 方法提高基学习器的泛化能力并增强单棵决策树的性能,同时降低泛化误差[6]。此外,随机森林还有袋外估计的特点,不需要额外挑选训练集。随机森林的算法流程可分为以下几步:
1)随机抽取样本:通过Bootstrap 重抽样方法从原始数据样本中抽取n个样本作为训练集,理论上往往会有大约1/3 的原始数据没有被选中,这部分数据则会作为测试集,评估其泛化误差。
2)随机抽取特征:对于每一个Bootstrap 样本集进行决策树建模,假设其中有d个特征,则随机抽取k个特征(k≤d),从k个特征中选择最佳分割特征作为节点建立CART 决策树。
3)建立森林:重复以上步骤m次,建立m课CART 决策树组成随机森林。
4)对于测试集的样本,通过森林中所有决策树的投票结果(对于分类问题)或算术平均值(对于回归问题)得到最终预测值作为输出。
2 航站楼负荷预测模型
本文以华东某机场卫星厅为负荷预测对象,通过空调系统实际运行的历史数据,该机场航站楼总建筑面积约为 62 万m2,设计总冷负荷为 93577 kW,分为S1 和S2 两部分。主要功能区包括值机大厅、安检区、候机区、旅客到达走廊、行李提取大厅、接待大厅等,并根据功能特点设置相应的商业店铺,以满足旅客餐饮、购物等需求。航站楼的空调负荷由能源中心的区域供冷系统承担,空调水系统为三级泵冷水直供系统,从能源中心产生的冷水,经二级泵系统输送至航站楼内三个热力站内,再通过设置在热力站的三级泵输送至航站楼内各个空调末端。该空调系统间歇运行,每日凌晨2:30~4:30 停止供冷。
2.1 数据预处理
采集的原始数据包括室外干球温度、室外相对湿度、进出人数、系统总供回水温度、冷冻水流量。各项数据的时间范围为7 月1 日至10 月1 日,涵盖整个制冷季节,时间间隔为 30 min,原始数据集共包含 4416组数据样本。由于数据传感器故障或干扰信号等因素,原始数据集中存在数据缺失、数据异常、数据波动等现象。这些异常数据的存在会使机器学习模型的性能降低,因此数据预处理是必不可少的一步。通过数据清洗、缺失值补充、离群点剔除等手段,可以提高数据的质量、提升模型的准确性、缩短计算过程。
缺失值处理:对于室外温湿度的缺失值,则根据Wunder Ground 全球气象数据库中当地对应时刻的室外温湿度数据进行补全。对于进出人数、系统总供回水温度、冷冻水流量等参数的缺失值,采用插值补全,用相邻时间点的数据平均值代替。
离群点处理:由系统总供回水温度与冷冻水流量计算可以得到各个时刻对应的冷负荷,冷负荷的概率分布图如图1 所示,可以看到冷负荷服从正态分布。通过判断冷负荷数据是否满足拉依达准则(3σ准则)来剔除离群点:冷负荷数据落在(μ- 3σ,μ+3σ)区间之外的被认为是异常数据,将剔除该冷负荷对应时间点的数据。其中冷负荷在0 MW~5 MW 区间概率分布较高是因为空调系统间歇运行导致,因此拉依达准则对于低负荷离群点的剔除较为局限,需要结合间歇运行的时间判断低负荷数值是否为离群点:若低负荷数值出现在凌晨2:30~4:30 则认为是正常数据,反之则作为异常数据剔除。
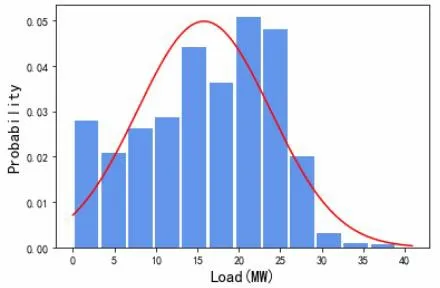
图1 冷负荷分布图
噪声处理:即使对应的冷负荷落在置信区间内,对于进出人数、室外温湿度等数据,仍然不可避免地存在数据噪声,如图2 所示为每日进出累计人数,这是由传感器高频测量的物理变量的随机误差导致的。因此,为了降低噪声干扰,需要对曲线进行滤波,让曲线过渡更平滑。本文采用 Savitzky-Golay 滤波器对数据进行平滑处理,其核心思想:是对一定长度窗口内的数据点进行k阶多项式拟合,从而得到拟合后的结果。这种滤波器的最大特点:在滤除噪声的同时可以确保信号的形状、宽度不变。平滑处理后得到的每日进出累计人数的曲线如图3 所示。

图2 去噪前每日进出累计人数
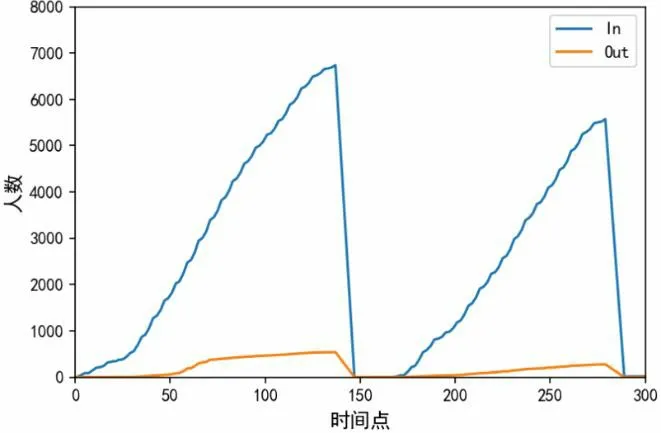
图3 去噪后每日进出累计人数
2.2 特征工程
正确构建的特征可以在不牺牲预测精度的情况下减少数据驱动模型的计算时间[7],对于航站楼空调负荷预测,本文挑选了室外干球温度,室外相对湿度,进出人数,时间及历史负荷作为原始特征,并进一步处理得到更能反映航站楼空调负荷变化规律的输入特征。
2.2.1 时间特征
原始数据中时间的数据是以日期的格式储存的,如2020 年7 月1 日12:00:00。在目前研究的负荷预测模型中,一般将其转化为时间戳格式或 24 h 格式。前者代表了从1970 年 1 月1 日00:00:00(UTC/GMT 的午夜)开始到当前时间所经过的秒数,后者则是日期格式中对应的小时数。因此,时间戳格式表示的时间数据是单调递增的,而24 h 格式表示的时间数据是以24为周期的锯齿状周期函数。而航站楼的空调负荷存在明显的24 h 特征与星期特征,如图 4 和图5 所示。
图4 显示了 2020 年 7 月 30 日 00:00:00~2020 年8 月 1 日 00:00:00 航站楼的 48 h 内每 30 min 的冷负荷变化,可以看到冷负荷表现出明显的 24 h 特征。由于空调系统间歇运行,在每日系统重新开始运行的 1 h内,系统需要处理停机期间的蓄热,此时的冷负荷达到峰值。图5 显示了2020 年8 月3 日~2020 年 8 月 16日航站楼的日负荷变化情况,在两周内室外平均温度基本稳定在30 ℃左右的条件下,冷负荷表现出明显的星期特征。整体趋势为一周内冷负荷随星期数上升,在星期五达到峰值后回落。

图4 冷负荷24 h 特征
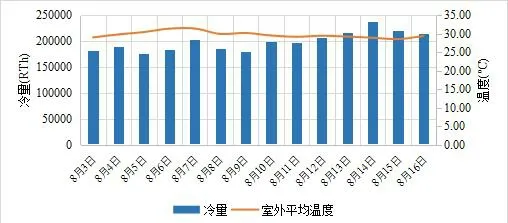
图5 冷负荷星期特征
通过上述分析,将时间拆分为 24 h 特征和星期特征更能反映冷负荷的变化规律。因此,通过式(2)和式(3)将数据样本的时间转化为两组特征。
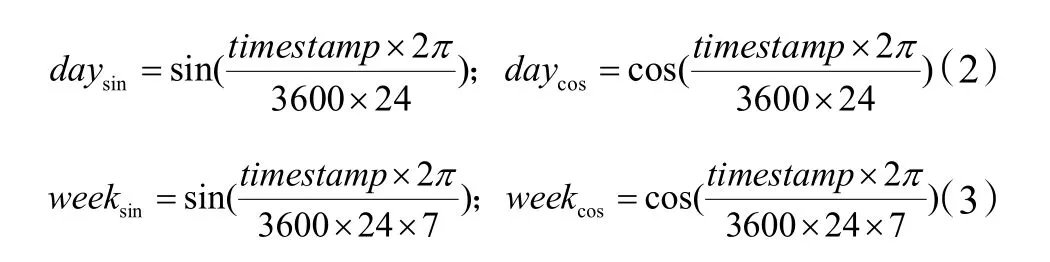
式中:timestamp为数据样本对应的时间戳。
2.2.2 客流特征
人员数量是影响航站楼实际负荷需求的重要因素,航站楼人员密度实际运行阶段的真实值显著低于设计值,导致空调系统新风负荷与人员负荷供需不匹配[8]。目前对于航站楼客流特征常用的数据一般是主要出入口的客流量——进出人数随时间的变化,而某一时刻的客流量并不能直接反映航站楼内对应的人员数量。因此,本文拟通过式(4)计算某一时刻航站楼内的逗留的人员数量。

式中:Nt为t时刻航站楼内逗留的人员数量;At为t时刻进入航站楼的人数;Bt为t时刻离开航站楼的人数;Ct为t时刻从该机场飞离的人数;Dt为t时刻降落到该机场的人数。
图6 为航站楼内逗留人员数量示意图。其中,At和Ct可以通过航站楼主要出入口的客流统计摄像头得到,而Bt和Dt则与航班动态相关,较难直接获取相关数据。但后两者与前两者存在时间上的关联,从该机场飞离的人在先前的时间会被入口客流统计捕捉到,而降落到该机场的人则在后续的时间会被出口客流统计捕捉到。同时,将迎接旅客和送别旅客的人群考虑在内,可以将式(4)改写为式(5)。

图6 航站楼内逗留人员数量示意图
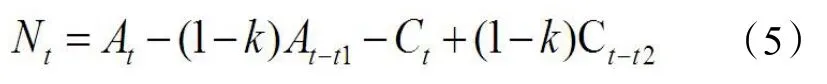
式中:k为迎送比,国内迎送比 0.3,国际迎送比 0.5[9],取平均值0.4;t1 为出发过程停留时间;t2 为到达过程停留时间。
Liu 等人[10]的研究表明:乘客在航站楼出发过程中花费的时间较长,而到达过程往往很快,通过现场调研得到的平均停留时间分别为132 分钟和34 分钟。因此,结合数据集的时间步长,t1 和t2 分别取 120 min和30 min。通过式5 计算得到的航站楼人员数量部分曲线如图7 所示。可以看到,航站楼的逗留人员数量在每日8:00 和16:00 两个时刻达到峰值,这与上下班高峰期的时间吻合。
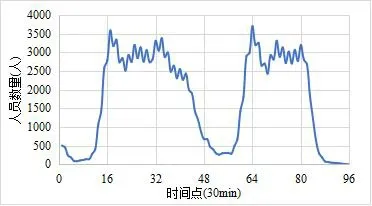
图7 航站楼内逗留人员数量曲线
2.2.3 气象特征
室外温湿度数据反映了室外空气的状态点,而室外空气焓值代表了空调系统将新风处理到送风状态需要提供的冷量。因此,在室内要求的温湿度不变的条件下,室外空气的焓值更能反映空调冷负荷的变化规律。已知室外温湿度数据,可通过式(6)计算对应焓值h。
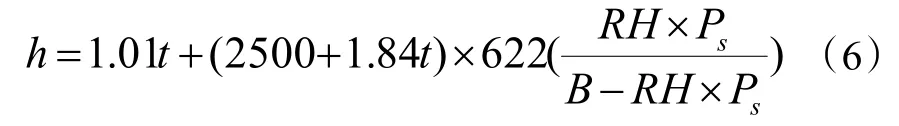
式中:t为室外干球温度,℃ ;RH为室外相对湿度,% ;Ps为水蒸气饱和分压力,可 查水蒸气表,和 温度一一对应,P a;B为大气压,取 101325 Pa。
2.3 模型训练及参数寻优
综合上述分析,将时间 24 h 特征、时间星期特征、人员数量、室外干球温度、室外相对湿度、室外空气焓值、历史负荷作为随机森林算法的输入特征进行模型训练。在采用随机森林进行回归任务时,需要对模型参数进行定义,主要参数包括:决策树的数量(n_estimators)、树的最大生长深度(max_depth)、叶子的最小样本数量(min_samples_leaf)、分支节点的最小样本数量(min_samples_split)。对随机森林模型来说,树越茂盛,深度越深,枝叶越多,模型就越复杂。模型过于复杂会导致过拟合且计算效率低,而过于简单则会导致欠拟合且预测精度低,两者都会让泛化误差高。因此需要寻找最优的参数组合建立模型,目前常用的参数优化方法包括网格搜索法和随机搜索法。
其中网格搜索法是指定参数值的一种穷举搜索方法,遍历所有的参数组合通过交叉验证的方法进行优化来得到最优的学习算法。但对于随机森林算法来说,需要调整的参数很多,如果采用网格搜索法则需要大量的搜索时间。而随机搜索法对于多参数的机器学习算法适用性更强[11],这种方法通过在给定参数范围内随机选择参数值进行指定次数的参数组合,然后找出泛化误差最小的一组参数组合。因此,本文采用随机搜索法对随机森林模型进行参数调优,并以最优参数组合进行模型训练。
2.4 模型评价
对于模型的预测性能,根据 ASHRAE 指南14-2014[12]选取了三个指标评估预测结果的准确性:归一化平均绝对误差(NMAE)、累积均方根误差(CVRMSE)以及拟合优度(R2),各项指标的计算公式见式(7)~(9)。
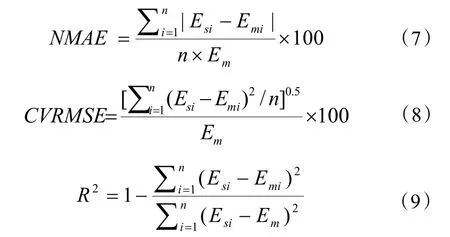
式中:Esi为第i组数据的预测冷负荷,k W;Emi为第i组数据的实际冷负荷,kW;Em为实际冷负荷平均值,kW;n为数据样本数量。
ASHRAE 指南 14-2014 中指出,在使用小时负荷预测值时,负荷预测模型的NMAE 和CVRMSE 应分别保证小于 10%和 30%,此时模型预测的结果是可接受的。
3 模型性能对比及特征分析
为分析不同输入特征组合对负荷预测模型性能的影响,建立了五组模型,其中时间特征均包括24 h特征与星期特征。对于历史负荷,考虑到模型的可用性,时间窗口不宜选择过长,故每组模型的历史负荷时间窗口取值范围为1~4,即采用前1~4 个时刻对应的负荷数据作为历史负荷特征。每组模型挑选出预测性能表现最好的模型进行对比,各组模型性能对比如表1 所示,各组模型参数及训练时间如表2 所示,冷负荷预测准确度的情况如图 8 所示,其中黑色虚线为10%误差线。
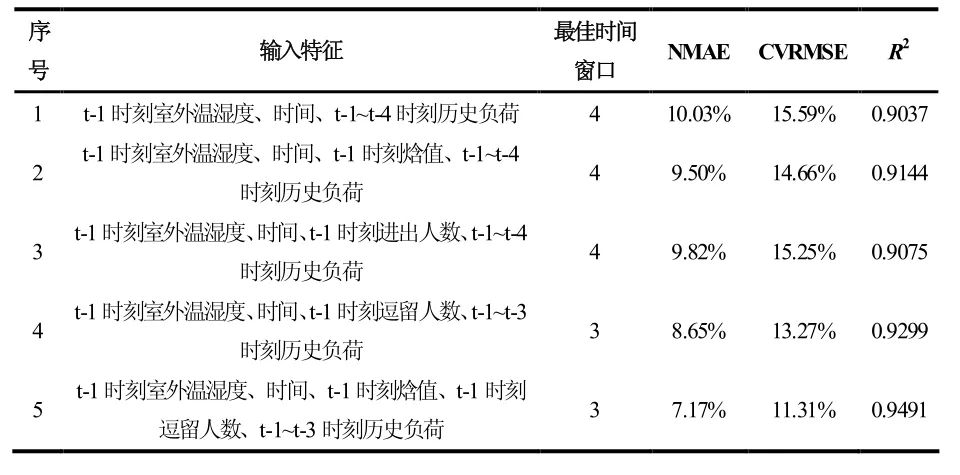
表1 各组模型性能对比情况
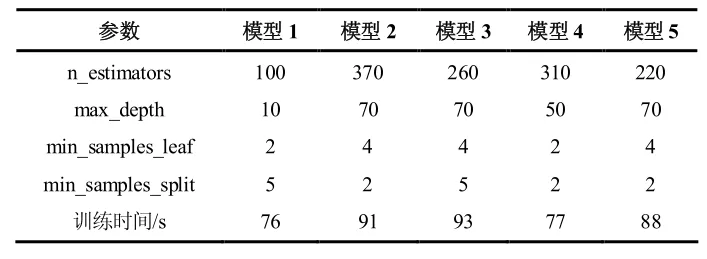
表2 各组模型参数及训练时间
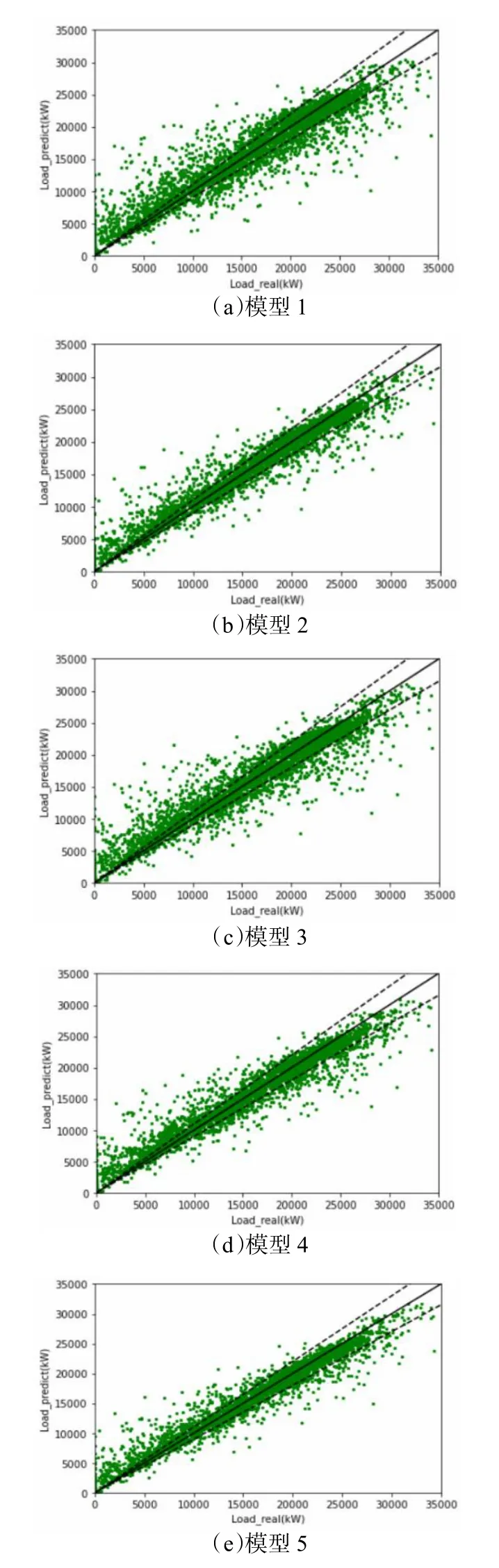
图8 冷负荷预测值与实际值对比图
表 1 和表 2 显示:除模型 1 外,其余模型均能满足ASHRAE 指南14-2014 要求的性能,且五组模型的训练时间均不超过100 s。由表1 的模型2 与模型4 可以看出,在室外温湿度、时间、历史负荷的基础上,增加焓值或逗留人数作为输入特征均可以提升航站楼负荷预测模型的性能。在模型 3 中,增加原始客流特征——进出人数作为输入特征并不能提升模型性能,这说明进出人数与冷负荷的相关性较弱,不能准确反映冷负荷的变化规律。在正确选择输入特征的条件下,随着输入特征维度的增加,随机森林模型的复杂度反而下降,历史负荷的最佳时间窗口相应下降,且由表2 可知,模型训练的效率也相应提高。
图8 显示了不同模型的预测准确度,各个模型在低负荷区域(0 kW~10000 kW)的准确度较差,这是由于间歇运行系统停机时间存在人为操作的随机性导致的。随着输入特征被正确选取,预测值与实际值的误差逐渐减小。模型5 在15000 kW~35000 kW 负荷范围的预测误差基本控制在10%以内。对模型5 进一步分析,各个输入特征的贡献度如图9 所示。
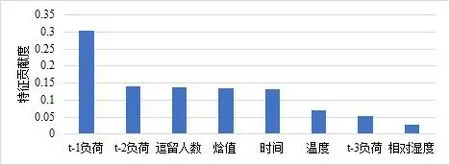
图9 模型5 输入特征贡献度
由图 9 可知:负荷预测模型各个输入特征中对预测结果贡献最大的特征是历史负荷,尤其是前 1 h 内的负荷数据,而时间间隔超过1 h 的负荷数据对预测结果的贡献较小。需要注意的是:客流特征对于负荷预测的相关性仅次于历史负荷,甚至高于常用的室外温湿度特征,这说明航站楼等公共交通建筑中客流特征对于负荷变化有显著的影响。此外,气象特征、时间特征对于负荷预测的贡献相当,气象特征中焓值的贡献度远高于温湿度。这说明相比于温湿度,室外空气焓值是对负荷预测更有效的气象特征。
4 结论
本文基于随机森林建立负荷预测模型,结合航站楼空调负荷特点,对模型输入特征进一步拆分细化,引入客流特征、室外空气焓值、时间 24 h 及星期特征作为输入特征,利用实际运行数据进行训练,并对不同特征组合进行分析研究,得到以下结论:
1)对于航站楼空调负荷,各输入特征对预测结果的贡献度大小排序依次为:前 30 min 负荷>前 1 h 负荷 >逗留人数 >室外空气焓值 >时间 >室外干球温度>前1.5 h 负荷>室外相对湿度。
2)对于输入特征的选择,客流特征是航站楼等公共交通建筑空调负荷的重要影响因素,逗留人数相比于进出人数更能反映负荷的变化规律;前 1 h 内的历史负荷对负荷预测的相关性较高,超过 1 h 的历史负荷对预测结果的贡献较小;室外空气焓值对于空调负荷预测结果的影响比室外温湿度更加显著。
3)随机森林算法在航站楼负荷预测方面对多维度输入特征的适用性较强,在正确选择相关性较高的输入特征的前提下,随着输入特征维度增加,模型的复杂度训练效率更高,预测性能更好。
