基于并行化BP 神经网络的配电变压器故障快速诊断方法
2022-01-23赵志新赵宗罗王子凌俞建飞李忠民
赵志新,赵宗罗,赵 颖,王子凌,俞建飞,李忠民
(1.国网浙江富阳市供电有限公司,杭州 311400;2.国网浙江省电力有限公司电力科学研究院,杭州 310014;3.西安交通大学 电气工程学院,西安 710049)
0 引言
作为电力系统的重要组成部分,配电网承担了由电网主干部分向各实际用电客户分配电能的重要任务。与主网相比,配电网发展相对落后,整体架构较为薄弱,网络拓扑结构较为单一,故障率较高。据相关统计,配电网故障造成的电网区域性停电事故占比达80%以上[1]。因此,保障配电网的稳定运行,是进一步提升电网可靠性及供电质量的重要途径[2]。对于配电变压器各类故障的检修工作,目前仍以预防性检修及故障后抢修方式为主。上述方式存在明显的弊端:定期检修方式存在检修不及时、检修过度等问题;故障后抢修属应急维修手段,故障问题已经造成实际经济损失。随着电网投资逐步向配电网倾斜[3],各类多运用于主网的设备在线监测技术,如油中溶解气体分析、电能质量检测、局部放电监测及红外成像监测技术,逐步在配电网设备运维工作中推广使用。集成配电网设备状态监测、运行调度等数据的统一化信息平台也已初步建立,但相关技术在配电网设备状态检修中的应用仍处于起步阶段。
就配电变压器而言,实现其状态检修的关键在于开展设备故障预测与诊断工作,以准确判断其运行状态,并依此辅助制定检修策略。
配电变压器故障一般可按故障发生位置划分为外部故障和内部故障两大类,外部故障即变压器油箱、套管及引线等裸露部分出现的故障,内部故障包括各类变压器箱体内部的放电及过热故障[4]。目前,配电变压器故障监测及诊断手段包括绝缘油试验、局部放电试验及红外成像试验等,其中DGA(溶解气体分析)技术由于不受外部环境因素的干扰,是有效的内部故障监测手段。DGA 基于油中溶解气体类型与内部故障的对应关系,采用气相色谱仪分析溶解于油中的气体,根据气体的组分和含量来判断变压器内部有无异常情况,并判断故障类型、大概部位、严重程度和发展趋势,能够实现变压器的不停电检测和早期故障诊断,并在此基础上发展出了三比值法和特征气体判别法等故障判断方法。另一方面,随着信息智能化处理技术的广泛应用,国内外学者结合数据挖掘技术,如ANN(人工神经网络)[5-7]、SVM(支持向量机)[8-11]及贝叶斯网络[12-15]等,提出了许多基于DGA 的变压器智能故障诊断方法。其中以基于ANN 方法的设备故障诊断技术应用最为广泛,但目前该类方法存在一些共性问题,包括网络训练时的收敛速度较慢、分类结果易陷入局部最优值等[16-17],不利于实际应用。
针对目前基于ANN 方法的变压器故障诊断技术存在的主要问题,本文提出一种基于MapReduce 并行化的BP(反向传播)神经网络算法——MR-BPNN 算法,以实现对于配电变压器故障的快速诊断,并借助Hadoop 平台实现MR-BPNN的优化运行。最后,基于所采集的某电力公司配电变压器油中溶解气体数据,验证所提方法运用于设备故障诊断时的有效性。
1 BP 神经网络算法
ANN 按学习策略可粗略地分为两大类:有监督的ANN 和无监督的ANN。
BP 神经网络是一种典型的有监督前馈型ANN,由非线性变换神经单元组成,一般呈现多层结构,具备优秀的非线性映射逼近能力与预测性能。
神经元(Neuron)也称为节点(Node),是ANN的基本单元,同层中的神经元具有相同的非线性转换函数,不同层的神经元则可能具有相同或不同的非线性转换函数。组成BP 神经网络的神经元模型如图1 所示,主要由5 部分组成:
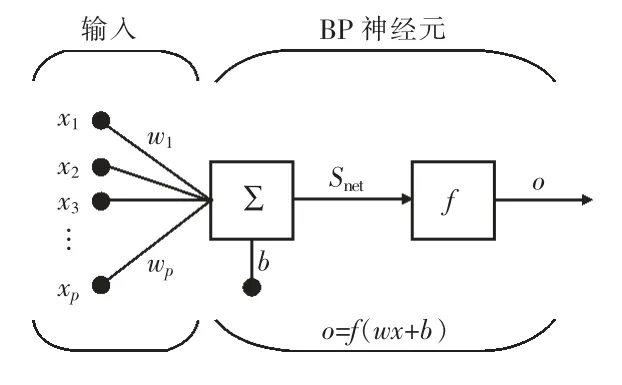
图1 BP 神经网络神经元模型
1)输入。x1,x2,x3,…,xp为神经元的p 个输入变量。
2)网络权值与阈值。x1,x2,x3,…,wp为网络权值;b 为神经元的阈值(或者称为偏置值)。
3)求和模块。

4)传递函数f。对求和模块的计算结果进行函数运算,得到神经元的输出。
5)输出。输入变量经神经元加权求和,得到最终的输出o=f(wx+b)。
BP 神经网络一般由输入层、隐含层和输出层组成。图2 描述了典型的3 层BP 神经网络的拓扑结构,其中圆圈表示神经元。
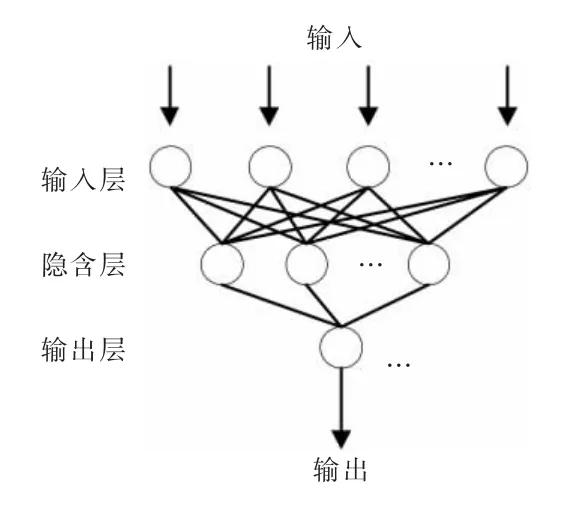
图2 三层BP 神经网络的拓扑结构
数据经过标准化处理后,由BP 神经网络的输入层输入,再经施以权重后传输到隐含层,数据在隐含层进行权值和阈值的调整以及激励函数的运算,并将处理好的数据传输到输出层,由输出层输出数据的预测值,将此预测值和期望值相比,如果有误差,则将误差从输出层反向传播,根据误差的大小对权值和阈值进行相应的调整,使BP 神经网络的输出逐渐与期望值一致。
直接采用BP 神经网络进行色谱数据分析时,学习过程误差收敛速度较慢,权值的调整可能需要数万次才能收敛,计算量庞大,故本文提出采用Hadoop 集群计算平台,从而实现BP 神经网络的并行化计算,大幅度提升训练效率。
2 Hadoop 集群计算平台
Hadoop 是 由Apache Software Foundation 公司开发的开源集群计算平台软件框架,可以让用户在廉价的计算机集群上部署运行。Hadoop 为程序的分布式运行提供了大量的接口和服务。Hadoop 由9 个项目构成,如图3 所示,每个项目的功能如表1 所示。
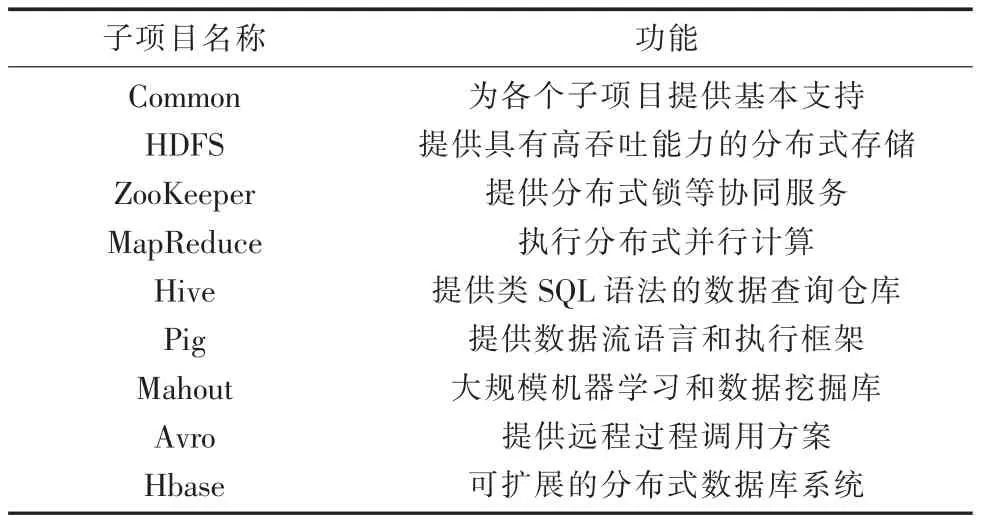
表1 Hadoop 组成项目功能
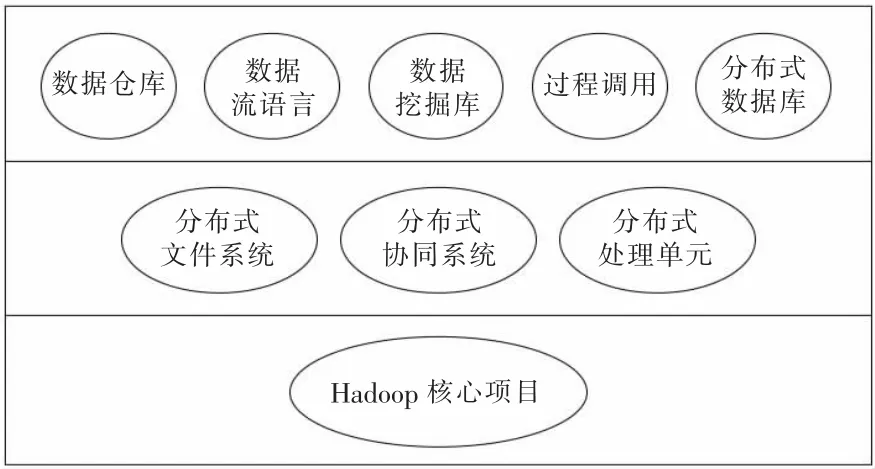
图3 Hadoop 的组成结构
3 BP 神经网络的MapReduce 并行化实现
Hadoop 集群计算平台中的MapReduce 模型是本文的应用重点,其由Map 和Reduce 两阶段组成,Map 阶段对任务进行分解,Reduce 阶段对子任务结果进行汇总。HDFS(分布式文件系统)负责数据存储,当获得大型数据集后,首先要存储到HDFS 中,实际文件存储到集群中的多个节点上,然后再经MapReduce 将数据集分成更小的数据块进行处理。
对于BP 神经网络而言,MapReduce 并行化包括两个过程:第一个是Map 过程,该过程将数据集分成多个数据块,每个数据块作用于一个计算节点中的神经网络,计算节点中的神经网络训练数次后满足收敛条件则输出神经网络权值;第二个过程是Reduce 过程,汇总Map 过程输出的神经网络权值,若权值偏移量小于一定的阈值,则停止迭代,输出最终结果。以下对上述过程的设计进行详细阐述。
在Map 过程中,计算节点从HDFS 中读取神经网络初始权值,然后根据初始权值设定一个BP 神经网络,并读取训练样本数据块,训练BP神经网络,当训练达到收敛条件后,就认为在该计算节点上基于该训练样本数据块训练的网络收敛。Map 以一组键值对
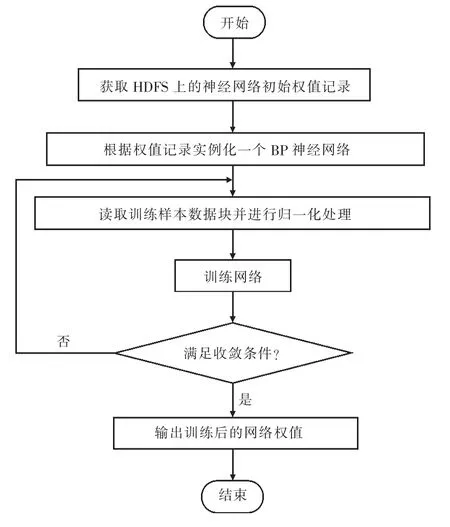
图4 BP 神经网络的Map 流程
Reduce 过程的输入是Map 过程输出的键值对组,获取Map 输出的网络权值,并根据value的数目和value 的累加和计算权值的算术平均值,然后读取HDFS 中存储的神经网络权值,将其与更新的权值对比,求差值。如果差值小于设定的阈值,则停止迭代,输出权值;否则用训练后的权值替代HDFS 中的权值,作为下次Map 迭代训练任务的初始权值。并行化BP 神经网络的Reduce 流程如图5 所示。
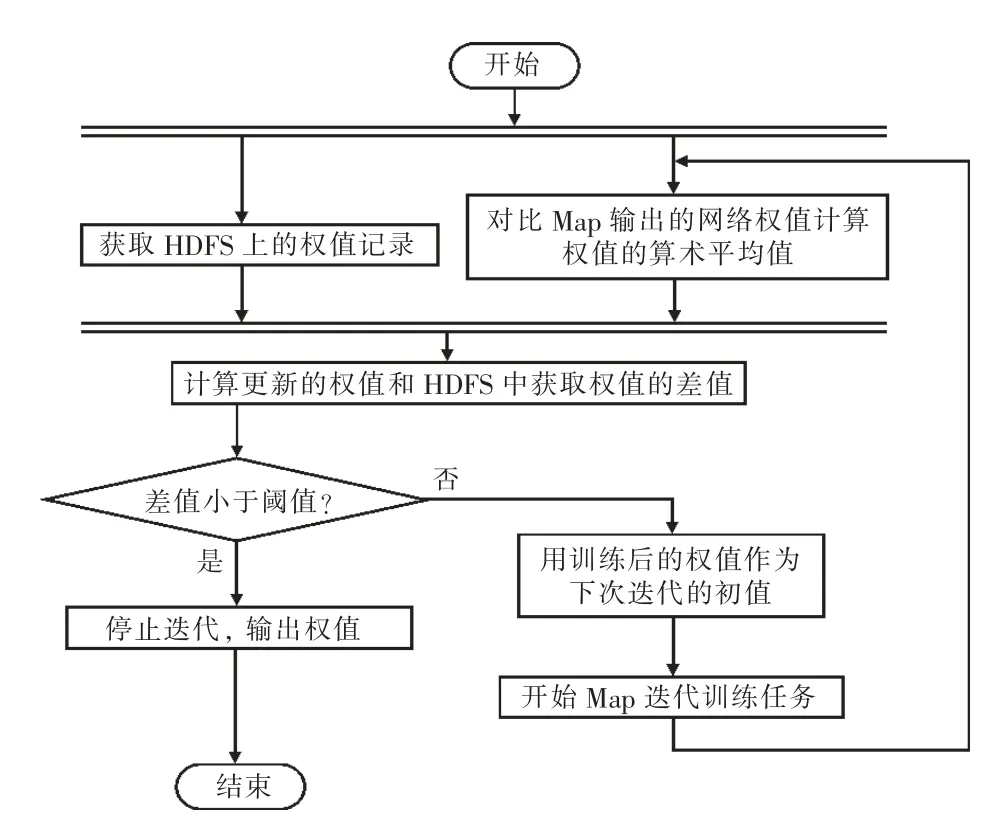
图5 BP 神经网络的Reduce 流程
4 基于MR-BPNN 的配电变压器故障诊断实例分析
为了测试本文所提方法的性能,以下通过针对配电变压器的故障诊断实例进行说明,所使用的数据来自于某电力公司2015—2020 年的配电变压器检测数据,挑选其中的357 台配电变压器共计2 642 条数据作为样本数据集。
4.1 数据预处理
初始化阶段首先选取配电变压器油中溶解气体H2,CO,CO2,CH4,C2H6,C2H4,C2H2和 总 烃的含量数据作为网络的输入。对于所采集的任意类型气体数据,均采用极大-极小法进行归一化:
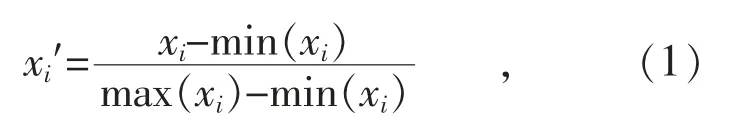
式中:xi为任意种类的气体含量值;为xi经归一化处理后的值;max(xi)为所有该类气体含量值中的最大值;min(xi)为所有该类气体含量值中的最小值。
4.2 确定隐含层节点数
在运用MR-BPNN 算法前,首先根据数据集特性确定隐含层节点的选择方法。隐含层节点是为了从样本数据中抽象出并存储其隐含信息,节点数越少,神经网络的学习时间越短,学习过程中忽略的隐含信息越多,对样本变化规律描述性能越差;相应地,隐含层节点数越多,存储的信息就越多,但过多的节点数会导致神经网络的学习时间过长,学习过程中可能出现过度拟合问题,即将噪声作为知识进行识别。隐含层节点数的确定取决于样本的个数与维度,目前常用的方法为试凑法,即采用不同隐含层节点数进行训练,选择网络误差最小时的节点数。
通过计算不同隐含层节点数网络的收敛性可以发现,就本例而言,当隐含层节点数为10 时误差曲线振荡较小、收敛速度最快,因此确定隐含层节点数为10。测试过程在Hadoop 集群计算平台上进行编程实现,每种情况循环运行10 次,取各指标相应的均值。
4.3 算法测试及结果分析
设置隐含层节点数后,利用百叶窗分组策略将原始数据集随机划分为训练集(占比80%)和验证集(占比20%),训练集用于训练神经网络权值分配,验证集用于评估模型分类性能。随后需要确定输出特征向量,为简化说明,选择过热和电弧放电这两个变压器典型故障类型的发生概率作为神经网络的输出向量,以0~1 的数值表示对应的故障程度,数值越大表示发生此类故障的概率越大,并设定该网络输出层神经元节点数为2。
MR-BPNN 算法执行过程中的参数变化情况如图6 所示,包括均方误差随迭代次数变化曲线(性能曲线)、梯度变化曲线、检验错误数曲线以及学习率变化曲线等。

图6 MR-BPNN 算法执行过程中的参数变化情况
完成数据初始化及网络训练过程后,运用基于溶解气体验证集数据,评估MR-BPNN 算法针对配电变压器故障诊断的性能,并将诊断结果与特征气体法、三比值法的诊断结果进行对比。表2 给出了不同方法针对部分典型样本和部分特征气体的故障诊断结果示例,表3 对比了MRBPNN 与BP 神经网络基于相同油中溶解气体数据集实现故障诊断时的运行时间。

表3 MR-BPNN 与BP 神经网络实现配电变压器故障
实验结果显示,基于给定验证集,应用MRBPNN 算法、特征气体法、三比值法对配电变压器故障诊断的准确率分别为91.67%,58.33%和75%。由表2 中典型诊断结果可见:由于三比值法中提供的编码是由实际案例总结得到,应用过程中编码缺失问题较为严重,许多情况下无法得到诊断结果;特征气体法存在无法全面反映故障状况的问题,易产生误判;相比其他两种方法,采用MR-BPNN 算法对同一故障性质进行判断的准确率有显著提高。另一方面,MapReduce 的引入将数据集进行了拆解,并为每个数据块分配单独的处理单元,同时集合Map 过程、Reduce 过程实现迭代过程的并行化,从而在相同故障诊断准确率的前提下提升收敛速度。
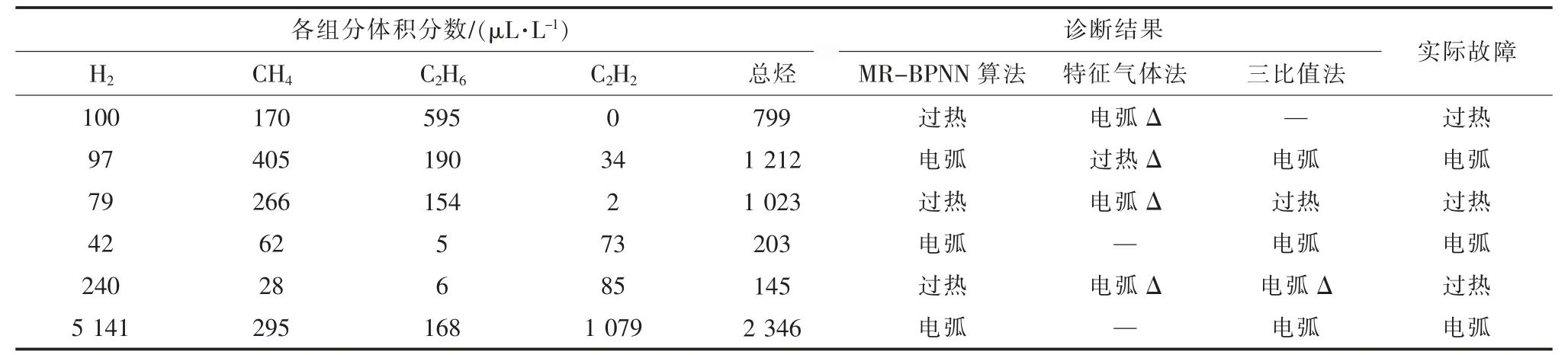
表2 典型故障诊断结果对比
通过对部分故障变压器进行拆解检修,进一步验证了所提方法用于配电变压器故障诊断时的准确性。以表2 中最后一行色谱数据所对应配电变压器为例,其出现故障运行状态后,油箱外观正常,套管瓷瓶无破损,压力释放阀正常,油位计显示油量不足。试验人员首先对设备本体进行了多项试验,结果表明:配电变压器高压侧直流电阻、变比试验及空载损耗测试结果不合格。通过对配电变压器进行离线油色谱分析,发现H2,C2H2及总烃含量不合格,初步提示故障类型为电弧放电。随后,对故障变压器进行了吊芯解体,发现B 相绕组高压侧与下铁轭之间有铜屑,切开后发现第5 层线圈开始出现击穿部位,油道位于第5、第6 层线圈之间,证实故障类型为电弧放电,与本文方法诊断结果一致。
5 结语
本文针对配电网设备状态检修工作中的设备故障快速诊断问题,提出了一种基于MapReduce并行化的BP 神经网络算法——MR-BPNN 算法。相比于传统的特征气体法和三比值法,该方法的故障判断准确率明显改善,且Map 和Reduce 过程的引入使其在相同故障诊断准确性前提下的算法执行效率相较传统BP 神经网络有显著提升。MR-BPNN 算法可实现配电变压器状态的快速识别与诊断,为开展其状态检修工作打下良好的基础。
