融合残差和对抗网络的跨模态PET图像合成方法
2022-01-22肖晨晨陈乐庚王书强
肖晨晨,陈乐庚,王书强
1.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004
2.中国科学院深圳先进技术研究院数字所生物医学信息技术研究中心,广东 深圳 518055
随着科学技术的发展,医学图像的获取方式多种多样,不同模态的医学图像具有不同的优点和缺点。例如,磁共振成像(magnetic resonance imaging,MRI)对人体没有辐射,软组织结构显示清晰,能够获得丰富的诊断信息,但采集时间较长,容易产生伪影;正电子发射型计算机断层扫描(positron emission computed tomography,PET)能够通过病变区域组织功能性的改变对疾病做出早期诊断,但价格昂贵,图像分辨率低。经研究表明,人体因疾病引起的形态或功能异常往往表现在各个方面,单一模态成像设备获取的信息往往无法全面反映疾病的复杂特征[1],但临床上同时采集不同模态的医学图像需要大量的时间和财力。因此,如何利用现有模态的医学图像,通过计算机技术精准地合成所需模态的图像是近几年的研究方向。
目前,医学图像跨模态合成方法多基于深度学习,根据所用数据的不同可分为基于成对数据的跨模态合成方法和基于不成对数据的跨模态合成方法。由于基于不成对数据的跨模态合成无法生成特定受试者的图像,因此本文研究基于成对数据的跨模态合成方法。Li等人[2]利用3D CNN 进行从MRI 到PET 的预测,为增加样本数据量,实验将每个样本图像分成多个图像块,该算法生成的PET 图像得到了较好的分类效果。Gao等人[3]提出深度残差编解码网络(residual inception encoder-decoder neural network,RIED-Net)来学习不同模态图像间的映射,提高了生成性能。Nie等人[4]提出用自动上下文模型实现上下文感知的生成对抗网络,获取MRI 到CT(computed tomography,电子计算机断层扫描)图像的映射,具有较高的准确性和鲁棒性。Bi等人[5]提出一种利用多通道生成对抗网络合成PET 图像的方法,实验在50 个肺癌病人的PET-CT 数据上进行,能够获得较真实的PET图像。Ben-Cohen等人[6]将全卷积网络与条件生成对抗网络结合,用给定的CT 数据生成预测的PET数据,得到了不错的效果。Yaakub等人[7]提出基于残差网络的3D 生成对抗网络模型,学习从MRI 到FDG(Fluoro deoxy glucose,氟脱氧葡萄糖)PET 的映射,对局灶性癫痫患者的临床评估比统计参数映射分析更有效。以上跨模态合成方法虽然都取得了不错的效果,但由于医学图像空间结构复杂,以上合成结果仍不能很好地表示人体组织的边缘信息,存在信噪比低、边缘模糊等问题。另外,现有公开的医学图像数据集中成对数据较少,以上方法所采用的数据多是自己采集,需要耗费大量的人力物力。
综上所述,为了在成对数据有限的情况下提高特定受试者PET图像的合成效果,本文提出了一种融合残差模块和生成对抗网络的从MRI图像跨模态合成PET图像的方法。主要工作有以下三点:将改进的残差初始模块和注意力机制引入到生成器中,以充分提取MRI图像的特征;改进pix2pix网络框架,判别器采用多尺度判别器,提高判别性能;损失函数在传统对抗损失和L1损失的基础上添加多层级结构相似损失,更好地保留图像的对比度信息。
1 相关工作
1.1 生成对抗网络
生成对抗网络(generative adversarial network,GAN)最早由Goodfellow 等人[8]于2014 年提出,包括一个生成器G和一个判别器D。生成器接收来自某一分布的噪声z作为输入,将其映射到数据空间,捕获真实样本x的数据分布,从而生成类似真实数据的生成样本G(z)。判别器以生成样本和真实样本作为输入,目标是将生成样本G(z)分类为假,真实样本分类为真。
GAN 的训练是生成器与判别器不断相互对抗,进行极大极小值博弈,最终达到动态平衡的过程。GAN的目标函数定义为:
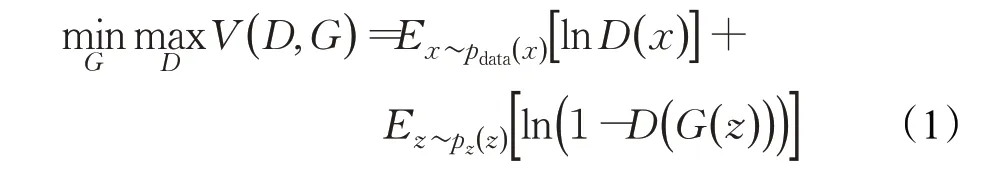
由于不加条件的生成对抗网络生成的结果具有很大的不确定性,Mirza等人[9]提出给生成器和判别器添加额外信息y作为条件,构建条件生成对抗网络(conditional generative adversarial network,CGAN)。CGAN的损失函数定义为:
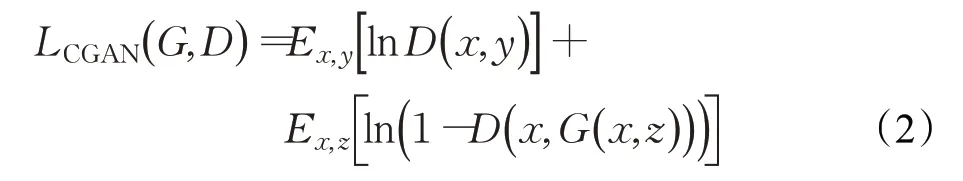
pix2pix网络[10]是CGAN的一种,用于图像翻译。但它不再输入噪声,而是直接将原始图像作为条件输入给生成器,判别器则以目标图像及生成图像与原始图像组成的真假图像对作为输入,判别其真假。
1.2 残差初始块
残差初始块[3]结构如图1 所示,包括两条路径。其中,两个3×3的卷积路径对数据特征进行提取,1×1的初始残差短路连接能够加深(编码器中)或减小(解码器中)卷积核的深度,同时解决输入特征映射与输出特征映射具有不同通道的问题,确保输入输出映射在像素级别的融合。与inception模块相比,残差初始块的参数更少,结构更简单,能够解决网络深度带来的问题。
1.3 注意力模块
Oktay 等人[11]提出用于医学图像的注意力模块,结构如图2 所示。注意力机制通过门控信号g确定每个输入xl上不同区域的注意力系数,从而使网络把注意力放在与任务更相关的区域,抑制无关的背景区域。添加了注意力模块的神经网络具有更高的灵敏度和精度。
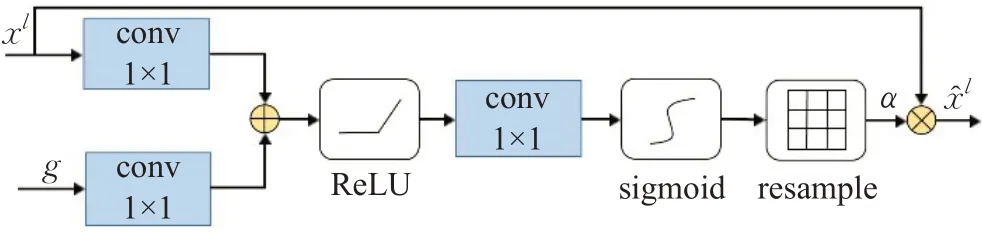
图2 注意力模块Fig.2 Structure of attention module
2 本文算法
本文改进的融合残差模块和生成对抗网络的跨模态PET 图像合成方法的模型框架如图3 所示。生成器以真实MRI 图像作为输入,学习MRI 与PET 之间的特征映射关系,生成与真实MRI相对应的合成PET。合成PET与真实PET分别与真实MRI拼接成真假图像对,两个判别器以真假图像对作为输入进行真假判别,最后将两个判别结果加权平均作为最终结果。
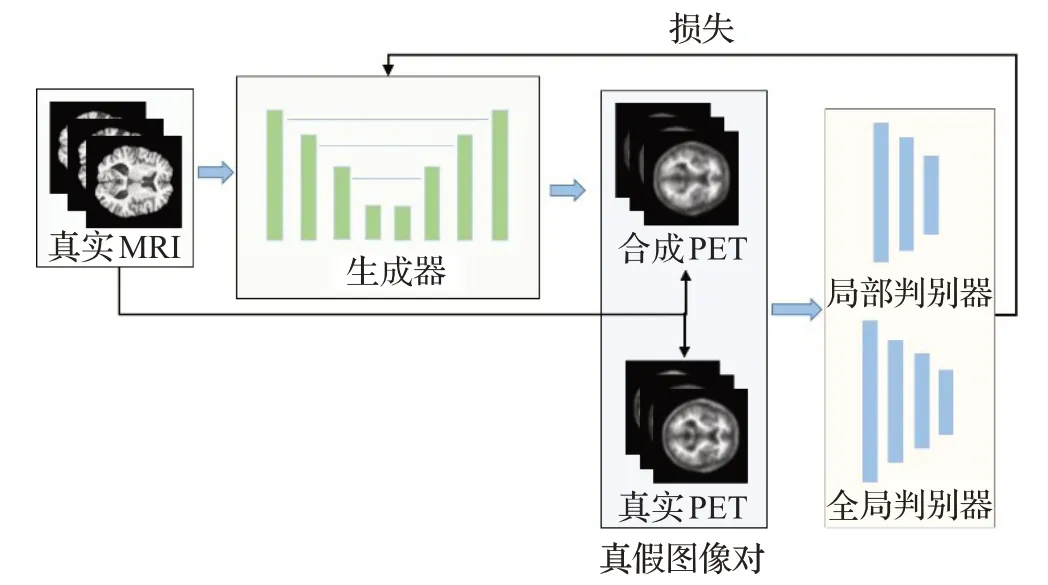
图3 本文模型框架Fig.3 Framework of proposed model
2.1 生成器网络
由于具有良好的性能和对内存的高效利用,U-Net[12]在医学图像分割任务中应用广泛。因此,本文算法以U-Net作为生成器。
生成器结构如图4所示,由编码路径和解码路径组成。编码路径由一系列3×3 卷积、4×4 卷积、批归一化层、激活层构成。算法用卷积层替代U-Net中的最大池化层,通过卷积操作不断提取MRI图像的关键特征,压缩从低层到高层提取的重要信息。解码路径由一系列3×3卷积、4×4反卷积、批归一化层、激活层组成,从编码路径压缩的特征映射中重建出最终输出。
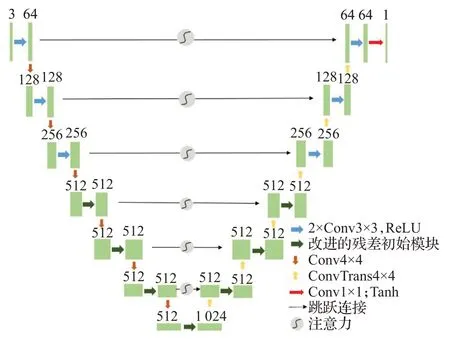
图4 生成器结构Fig.4 Structure of generator
为了更好地学习图像中的像素信息,本文算法将改进的残差初始模块引入到编解码路径中,以保证更好的生成效果。在神经网络中增加卷积核的大小可以扩大感受野,但是一味地增大卷积核会使网络参数变多,给网络的训练带来一定难度。因此,本文算法在残差初始模块的3×3 卷积路径上增加一个3×3 卷积,用3 个小卷积核代替更大的卷积核,在扩大感受野的同时尽可能地减少网络参数。另外,残差初始模块的引入还能解决网络深度带来的梯度消失问题。
由于医学图像结构信息及空间信息较自然图像更加复杂,为更好的提取MRI图像中的关键结构特征,本文算法将生成器的编解码路径深度设置为7 层。但是考虑到网络复杂度和内存消耗问题,算法并没有将改进的残差初始模块放到编解码路径的所有卷积层中,而是通过多次实验对比生成效果,最终将残差初始模块放在网络的中间四层,编码路径的前3层和解码路径的最后3层仅采用两个3×3的卷积,在提高生成质量的同时,减少网络参数和训练时间。
U-Net 中的跳跃连接能捕捉编码路径到解码路径的上下文特征,通过底层特征与高层特征的融合能够保留更多高层特征图的细节信息,但其中也可能包含与合成任务不相关的特征信息。因此,为提高合成质量,本文算法在跳跃连接路径中引入自注意力机制,在跳跃连接操作之前结合解码路径提取的特征,通过注意力门机制,减小不相关特征的权重,进一步消除跳跃连接中不相关特征和噪声带来的干扰,突出跳跃连接中的关键特征,从而更好地捕捉MRI 图像的关键信息。
另外,为了防止网络过拟合,算法还在生成器中引入dropout操作。最后,经过编解码后的特征信息,通过Tanh激活函数得到合成的PET图像。
2.2 判别器网络
为了更好地学习PET图像的局部特征和全局特征,提高判别器的博弈能力,使生成器生成更符合真实分布的PET 图像,本文采用多尺度判别器,即局部判别器和全局判别器。通过两个具有不同感受野(70×70和128×128)的判别器,生成器和判别器可以学习空间上距离较短和较长的像素间的关系。
判别器网络基于patchGAN 的思想,先将图像分为N×N块,再分别对每个子块进行真假判别。两个判别器网络分别是5 层和7 层,均由卷积层、批归一化层、激活层交替构成,最后将所有结果加权平均作为判别器的输出。
2.3 损失函数
本文采用对抗损失、L1 损失和多层级结构相似损失(multi-scale structural similarity,MS-SSIM)作为损失函数。
2.3.1 对抗损失
对抗损失能够在一定程度上约束生成结果,使结果更接近真实分布。对抗损失如式(3)所示:
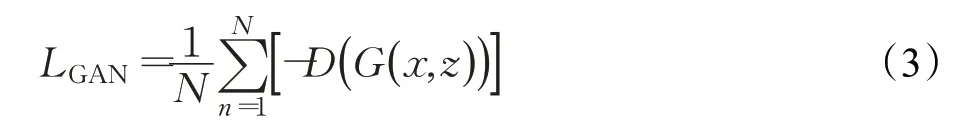
2.3.2 L1损失
L1损失通过生成器来减小真实图像和合成图像之间的差异。L1损失如式(4)所示:

2.3.3 MS-SSIM损失
结构相似性(structural similarity,SSIM)最初被Wang等人[13]提出用来衡量两幅图像的相似性。损失函数中引入多尺度结构相似损失能够更好的保留图像的亮度、对比度信息。
MS-SSIM损失如式(5)所示:
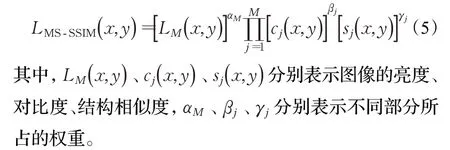
模型最终的损失函数如下式所示:

其中,λi(i=1,2,3 )为各损失的权重系数。
3 实验结果及分析
3.1 实验平台
本文实验在pytorch 框架上进行,实验的硬件配置是Intel i7-6700 CPU,NVIDIA GeForce GTX1080Ti GPU。软件环境为Ubuntu16.04 操作系统,Cuda9.0,Cudnn7.6,Pytorch1.1.0,Pyhton3.7。
3.2 数据准备及参数设置
本文采用来自阿尔茨海默病神经影像学计划(Alzheimer’s disease neuroimaging initiative,ADNI)公共数据集[14]的716 个阿尔兹海默病受试者的成对MRI和PET 图像,去除33 个受试者的异常数据,最终采用683个受试者的数据。
进行模型训练之前,先对数据进行预处理。本文采用FSL 软件[15]进行数据预处理,预处理步骤包括去脖子、颅骨剥离以及线性配准到MNI152空间。经过预处理之后,得到大小为91×109×91的三维数据。取三维数据的第40个轴向切片,上采样至128×128的大小作为模型输入。为了得到更为准确的实验结果,实验采用5倍交叉验证(5-fold cross-validation)的方法,将所有数据随机分成5组,轮流选取其中4组作为训练集(547个切片),另一组作为测试集(136个切片)。
在网络训练阶段,对损失函数的权重系数进行调整。由于输入图像的像素范围为(0,1),得到的L1损失数量级较小,而MS-SSIM损失系数数量级较大时,合成图像的亮度偏高,数量级较小时对结果的作用较小。因此,经过多次实验调试,最终将各损失函数权重设置为λ1=1,λ2=100,λ3=1。另外,batchsize 设为16,初始学习率设为0.000 2,使用Adam 优化器优化网络,共迭代训练200个epoch。其中,前100个epoch学习率不变,后100个epoch学习率线性降为0。
3.3 实验结果
为验证本文所改进的算法的性能,本文在ADNI数据集上进行实验,算法将pix2pix模型作为基准模型,同时与Ried-Net、pGAN[16]、以残差网络[17]为生成器的GAN(ResnetGAN)、以残差U-net 为生成器的GAN 模型[7]等基于CNN和基于GAN的主流算法进行对比,分别从定性和定量两个方面进行评估,共进行5组交叉实验。
3.3.1 定性评估
本文算法的生成结果与其他算法的生成结果定性对比如图5 所示。由图5 第一行可以看出,与真实图像相比,其他算法存在结果偏差较大及有斑点噪声的问题,本文算法的结果则更加完整。另外,其他算法得到的结果结构边缘看起来过于平滑或模糊,而本文算法生成的结果结构边缘相对更加清晰,对比度也有了一定改善,视觉上更加接近真实图像。
另外,由于不同受试者的大脑大小不一,线性配准到标准空间后仍然存在一定的偏差。如图5第二行、第三行所示,pix2pix和Resnet GAN不能很好地学习这种映射关系,生成的图像存在模糊、大小映射混乱的问题,其他算法虽然能学习到结构大小的变化,但边缘信息缺失很多,仍然存在有噪声和结构误差大的问题。相比之下,本文算法合成的结果边缘完整性更好,且没有噪声斑点,这可能是因为本文引入了改进的残差初始模块,提升了模型性能。由此可见,本文改进的算法生成的结果多样性更好,而且能更完整地保留图像的边缘结构。
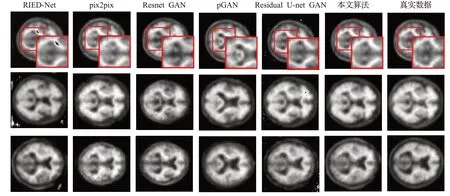
图5 各算法定性结果对比Fig.5 Comparison of qualitative results of algorithms
3.3.2 定量评估
本文采用平均绝对误差(mean average error,MAE)、峰值信噪比(peak singnal-to-noise ratio,PSNR)和结构相似性指数(SSIM)作为评价指标。
MAE、PSNR计算分别如式(7)和(8):
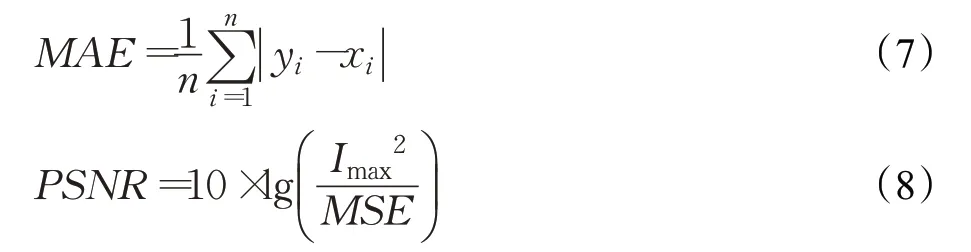
其中,MSE是两张图像的均方误差,Imax表示图像颜色的最大数值,使用8位采样点表示为255。
SSIM计算如式(9):
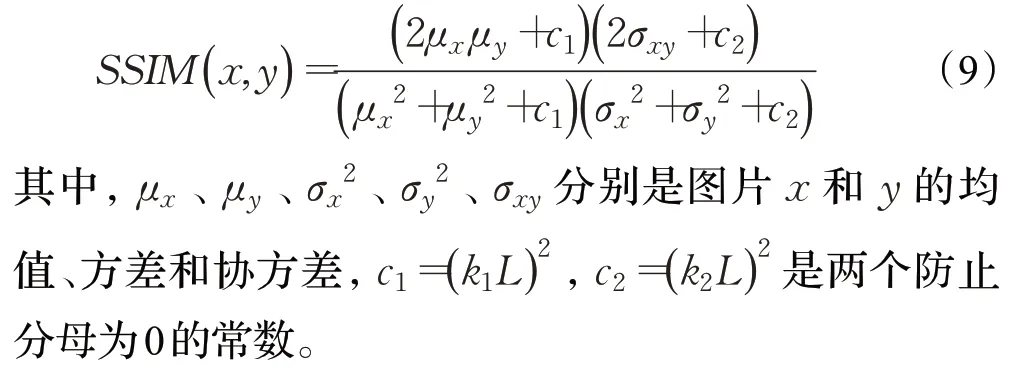
对比实验得到的定量指标如表1所示。可以看出,与其他算法相比,本文算法所合成的结果MAE 指标均有所降低,表明本文改进后的算法更加稳定。相比其他算法,本文结果的SSIM 值分别比其他算法高0.106、0.033、0.029、0.040、0.026,表明本文算法能够提高合成图像的质量。相比MAE 和SSIM 指标,本文算法的PSNR 值提升更加明显。除基于ResidualUnet 的GAN模型外,本文算法的PSNR 值分别提升了0.575 dB、0.056 dB、0.109 dB、0.257 dB,可见算法能够在一定程度上提高合成图像的质量。与基于ResidualUnet 的GAN模型相比,本文算法结果的PSNR值有所降低。这可能是因为PSNR是基于误差敏感的图像质量评价指标,并未考虑人眼的视觉特性,它所反映的图像质量有时与人眼观察的图像质量不完全相符,这一点也能从定性视觉效果上得到验证。

表1 各算法定量评估结果Table 1 Quantitative evaluation results of algorithms
因此,综合实验的定性结果和定量指标,本文算法能够提升合成图像的质量,较好地提升图像的边缘合成效果。
4 结束语
本文针对医学图像跨模态合成任务中合成结果边缘模糊、信噪比低等问题,提出一种融合残差初始模块和生成对抗网络的跨模态PET图像合成方法,通过在生成器中引入改进的残差初始模块和注意力机制,提升生成器的学习能力,采用多尺度判别器提升模型的判别性能。在ADNI数据集下的对比实验结果表明,本文改进的算法能够很好的保留图像的结构信息和对比度信息,生成的图像视觉上更贴近真实图像。但本文仍存在一些不足之处,如不同参数的仪器采集到的医学图像有一定偏差,本文采用相同的预处理步骤处理所有数据,因此数据的采集方式及预处理方法会对实验结果有一定影响。另外,本文在进行跨模态PET合成图像实验时只取图像的轴向切片进行实验,不能完整地展现脑部的三维结构信息。因此,接下来将针对不同的预处理方法以及三维PET图像跨模态合成方法进行研究。
