针对近重复视频的FD-means聚类清洗算法
2022-01-22付燕,韩泽,叶鸥
付 燕,韩 泽,叶 鸥
西安科技大学计算机科学与技术学院,西安 710054
在我国煤矿行业内,主要通过人工与智能视频监控技术相结合的方式监控灾情隐患。对比单一的人工监控方式,智能视频监控技术可持续、实时、全面的监控煤炭生产过程中各个环节,减少因煤矿开采造成的人员伤亡和经济损失。随着智能视频监控技术[1]的广泛应用,井下视频数据规模不断增大,近重复视频数据不断涌现,视频数据质量问题越来越突出,视频数据的维护和管理工作也越来越具有挑战性,不利于提早发现安全隐患问题以及灾后的事故调查。因此,针对视频数据质量问题研究对保障煤矿安全生产具有重要意义。视频质量[2]主要关注视频数据的清晰程度,而视频数据质量则主要关注视频数据集的整体质量,强调数据一致性、正确性、完整性和最小性在信息系统中得到满足的程度,属于数据质量[3]的概念范畴。近重复视频的产生不但会影响视频的数据质量,也会涉及版权保护和视频检索等领域正常视频的应用。因此,如何检测并自动清洗近重复视频数据,已成为日益关注的热点研究问题之一。
近重复视频检测技术是发现近重复视频数据的一种重要技术,也是发现视频数据质量问题的有效方法。目前近重复视频检测的研究主要在特征提取,签名生成两个方面。特征提取包括低层特征(如LBP[4]、局部特征[4-5]、颜色直方图[6]等)以及近年较热的深度特征[7-9]。签名生成分为帧级签名生成方法(如帧间匹配[6]、可视化词袋[10])和视频级签名生成方法(如聚合特征向量[6]和哈希码[11])。尽管目前针对视频检测问题的理论成果可以用于发现煤矿井下近重复视频数据,并反映出视频数据质量问题,但该类方法较难自动清理隐藏在视频数据集中的近重复视频数据。
数据清洗是指检测数据集合中存在的不符合规范的数据,并进行数据修复,以提高数据质量的过程[12]。数据清洗研究主要包括结构化数据清洗,多媒体数据清洗以及大数据清洗。近重复视频数据清洗是保证视频数据质量的有效手段,但目前存在的近重复视频清洗方法结果易受到滑动窗口尺寸和Hash冲突的影响。为解决上述问题,本文提出了一种融合VGG-16深度网络与feature distance-means(FD-means)聚类的近重复视频清洗方法。该方法首先借助MOG2 模型[13]和中值滤波算法对视频进行背景分割和前景降噪;其次使用预训练的VGG-16 提取视频背景与前景的特征;最后提出一种FD-means聚类算法,通过迭代产生的近重复视频簇,利用优化函数,更新簇类中心点,并最终删除簇中中心点之外的近重复视频数据。本文的创新点在于提出利用无监督聚类清洗的思想,融合深度神经网络和聚类算法,解决近重复视频的清洗问题。
1 相关理论
近重复视频指在相同场景下视频语义相同或者相似的视频数据[6]。监控视频数据中的近重复视频数据,在数据采集、整合和处理过程中都可能会产生不同形式的近重复视频数据。例如,在数据采集阶段,视觉角度的变化、光线的影响、设备自身的因素等情况会产生近重复视频数据。在视频数据整合阶段,由于数据来源不同,可能存在不同格式、长度的重复视频数据。在视频处理阶段,人工拷贝、编辑视频数据等操作可能造成重复或异常脏视频数据的产生。如图1 展示了监控视频中的近重复视频样例。

图1 近重复监控视频Fig.1 Near-duplicate surveillance video
现有的近重复视频检测根据视频特征方法可以划分如下两类:(1)基于低层特征的近重复视频检测方法,包括方向梯度类特征(LBP[4]、SCSIFT[5]、SIFT[6]),颜色特征(HSV[6-7]、RGB[7])等。Wu等人[6]先使用视频的颜色直方图过滤掉内容差异较大的视频,再使用SIFT 局部特征通过帧间匹配的方法计算视频相似度,该方法极大地降低了冗余视频,但是帧的成对匹配异常耗时。(2)基于深度特征的近重复视频检测方法,包括卷积神经网络[8-9]、循环神经网络[9]、两层3D 卷积网络[10]等。文献[8]通过融合卷积神经网络中间层特征,拟合视频特征映射到欧氏空间的映射函数,使得近重复视频之间的距离要小于非相似视频之间的距离,该方法具有出色的性能。
然而,上述近重复视频检索方法尽管可以识别出视频数据集中的近重复视频,但是较难直接自动清洗近重复视频数据,改善视频数据质量。数据清洗技术是改善数据质量的一种重要技术途径,主要包括结构化数据清洗[14-15]、大数据清洗[16-17]以及多媒体数据清洗[18]。
其中,在结构化数据清洗研究方面,郝爽等人[14]针对数据缺失、数据冗余、数据冲突和数据错误四种类型的脏数据介绍了不同的检测技术,从数据清洗方式上把数据清洗算法分为基于完整性约束的清洗算法、基于规则的清洗算法、基于统计的清洗算法和人机结合的清洗算法,并分析了优点和缺点。文献[15]基于快速移动窗口和小波分析方法对Urban 行驶数据中的异常及离群数据进行识别清洗,首次将数据清洗用在了自动车牌识别中,并提高交通网络监控和管理的数据质量。在大数据的广泛应用中也会产生各种脏数据,文献[16]介绍了Clean Cloud 大数据清理系统,在每个从服务器上运行补差、实体解析、真相发现以及基于规则修复四个算子,这些算子基于Map-Reduce 实现,对大数据具有良好的适用性。文献[17]针对冗余计算和同一输入文件的简单计算进行合并,减少Map Reduce的轮数,从而减少系统运行的时间。目前,多媒体视频清洗的研究较少,文献[18]采用邻近排序方法(sorted neigh borhood method,SNM)对近重复视频进行清洗,该方法采用局部敏感哈希(locality sensitive hashing,LSH)方法对特征构建视频签名,对视频签名进行排序后使用SNM 扫描排序后的特征列表,并剔除其中的近重复视频。该方法在一定程度上可以有效解决近重复视频的清洗问题,但是该方法对特征向量的Hash映射,造成部分特征信息的丢失,并且SNM方法过度依赖窗口尺寸。
总的来说,目前视频数据清洗的研究成果较少,存在算法结果易受到滑动窗口尺寸和Hash 冲突的影响。为解决上述问题,本文融合VGG-16 深度神经网络和FD-means 聚类算法,以避免特征向量的Hash 映射和固定滑动窗口对近重复视频清洗的影响,改善近重复视频清洗的效果。
2 融合VGG-16 深度网络与FD-means 聚类的近重复视频清洗方法
由于实际生活中,较难直接获取到具有代表性的近重复视频作为先验知识,为满足视频数据集的最小完整性原则,需要通过无监督学习的聚类思想识别具有代表性的近重复视频数据,以此为基准,删除视频数据集中冗余的其他近重复视频数据。为此,本文提出融合VGG-16 深度网络与FD-means 聚类的近重复视频清洗方法,该方法总体思路如图2所示。

图2 融合VGG与FD-means的视频清洗流程框架Fig.2 Framework of video cleaning process combining VGG and FD-means
首先对输入视频使用MOG2 模型和中值滤波算法进行背景分割和去噪。在此基础上,利用VGG-16网络模型提取视频的前景及背景特征。通过构建新的FDmeans 算法迭代产生的近重复视频簇,更新簇类中心点,删除簇中中心点之外的近重复视频数据,实现近重复视频的无监督聚类清洗。
2.1 VGG-16特征提取
VGGNet网络模型[19]在解决图像定位与分类问题中表现出优异的性能。该网络的特点是使用3×3 的卷积核替换较大尺寸的卷积核,这种方式在不影响卷积层感受野的条件下增加决策函数的非线性,并减少了参数数量。此外,深层特征可以更加有效表达原图所包含的信息。因此,本文利用VGG-16深度网络模型提取视频的深度外观特征,其具体网络结构如图3 所示,包含13 个卷积层、5个池化层和3个全连接层。VGG-16中的最后一个全连接层用于分类任务,本文只需要提取特征不用分类,因此本文只保留前两层全连接层。
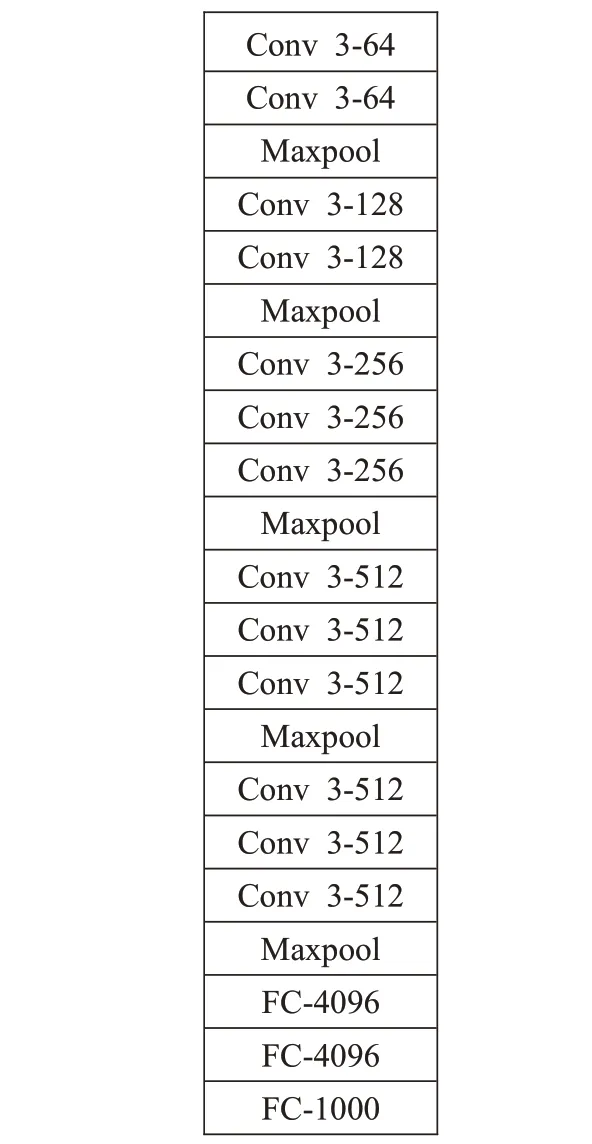
图3 VGG-16网络结构Fig.3 VGG-16 network structure
在图3中,Conv3-64、Conv3-128、Conv3-256、Conv3-512 分别表示使用64、128、256、512 个尺寸为3×3 的卷积核进行卷积操作,卷积步长为1;MaxPool表示对上层输出进行最大池化操作,池化步长为2;FC-4096、FC-1 000 分别表示1×4 096 和1×1 000 的全连接层。此外,本文使用ReLU 函数作为激活函数以增强网络模型的拟合能力,并对网络输出的特征向量进一步进行归一化处理,加快视频的聚类清洗速度。
2.2 FD-means聚类算法
传统的SNM方法容易造成漏删或者误删近重复视频的问题,并在数据降维过程中损失特征的有效信息。为此,本文借鉴K-means聚类算法提出了一种新的FD-means 聚类算法。尽管K-means 模型由于其本身的聚类效果好、聚类速度快的优点[20],但该算法需要预先确定参数K值。但在实际应用中,监控系统应用场景数量不一定是固定的,近重复视频的产生来源多样,因此K-means 算法模型较难完全适用于近重复视频清洗的任务。笔者认为,视频特征能够描述视频的内容信息,通过样本特征间的距离可以反应视频内容的差异,距离越近差异越小,距离越远差异越大。为此,本文构建了一个新的FD-means聚类算法模型对视频进行聚类清洗。该算法根据特征之间的距离进行聚类清洗。如果距离过远,即构造新的簇;若距离较近,则划分到本簇。通过该算法,可以对不同类别的视频特征进行无监督分类,并实现近重复视频的自动清洗。

其中||⋅||2表示对象之间的欧氏距离,m、n分别表示V、W中对象的个数,V、W表示由聚类对象组成的向量。
FD-means 的聚类过程,该算法主要由三个部分构成,更新聚类中心,更新簇以及融合簇,当聚类中心不发生改变时聚类结束,输出聚类结果。以下给出FDmeans聚类部分伪代码。
算法1 FD-means

FD-means 更新聚类中心过程,首先计算各元素与簇内其他元素距离之和,通过迭代选择距离之和最小的对象作为该聚类簇的中心,如式(2):
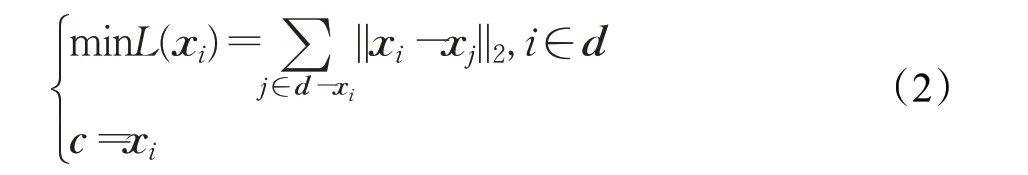
其中d表示聚类的某个簇,d-xi为差集运算,c表示该簇的中心元素。
在更新簇时,首先计算非聚类中心对象与所有聚类中心之间的欧式距离。在K-means中,所有非中心对象根据最近邻原则,将对象划分至最近的聚类中心簇中。与K-means 不同的是,FD-means 将非中心对象与所有聚类中心的距离与特征距离阈值进行比较,如果最小距离不小于距离阈值,则将该对象作为一个新的簇如式(3);否则,根据最近邻原则,将对象划分至最近的聚类中心簇中如式(4),从而实现了自动聚类。
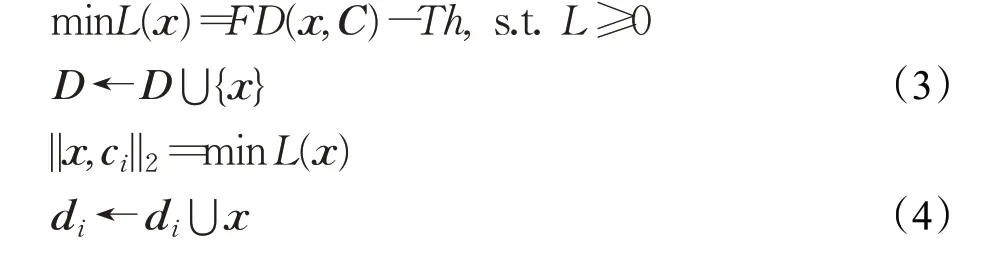
其中ci表示簇di的聚类中心,ci为距离x最近且小于距离阈值Th的聚类中心。
为了消除距离过近的簇,需要对簇进行融合,计算各个聚类中心之间的距离,通过迭代更新优化函数,将距离小于特征距离阈值的簇合并到一个簇,如式(5)所示:
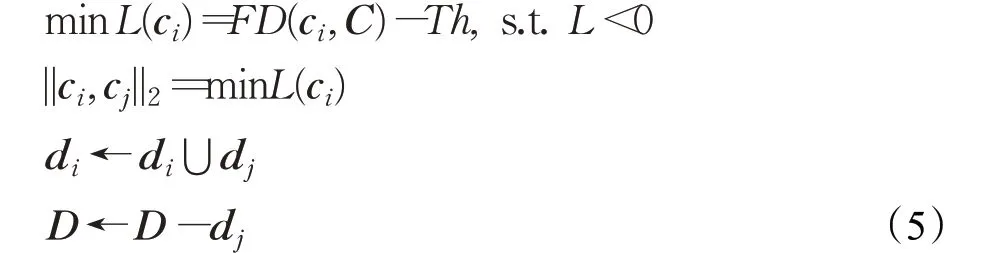
其中ci表示簇di的聚类中心,cj为距离ci最近且小于距离阈值Th的聚类中心,D-dj为差集运算。
在针对近重复视频进行自动清洗时,为了保证视频数据集的最小完整性、正确性、唯一性和有效性,不能把聚类得到的近重复视频全部剔除。为此,需要从近重复视频中保留一个具有代表性的视频,并自动删除其他近似重复视频数据,以提高视频数据质量,达到近重复视频清洗的目的。传统的图像去重或者数据清洗中,偏向于保留首次检测到的数据,去除后面相似的数据,这种保留方式不完全具有代表性。通过FD-means算法将近重复视频聚类,同一个类内视频都是近重复的,在该前提下进行视频清洗,样本特征间的距离可以反应视频内容的差异。因此,聚类中心能够代表聚类簇中的近重复视频数据,通过保留聚类中心的视频,删除聚类中心点之外的视频,达到近重复视频清洗的效果,如式(6)所示。
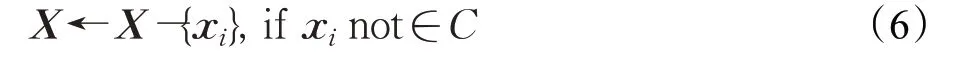
其中,“-”为差集运算。虽然删除非聚类中心视频会损失这些视频的细节信息,但近重复视频在整体上是相同或者近似的,删除非中心视频不会损失这些近重复视频的主要信息,并且保证了数据集的最小性、一致性、完整性和数据的正确性。
3 实验结果与分析
3.1 实验环境与数据集
本文,采用Python 3.6.5版本编程语言,Windows10操作系统,Intel Core™i5-4200H@2.80 GHz×4 处理器和8.0 GB 内存空间的环境实现所提方法。本文分别在煤矿井下监控视频数据集和CC_WEB_VIDEO 数据集上[6]进行算法对比分析。其中,CC_WEB_VIDEO数据集包含24个场景总共13 129个多媒体视频。本文随机选取其中5 个场景(“The Lion Sleeps Tonight”“Evolution of dance”“Folding Shirt”“Cat Massage”“ok go-here it goes again”)共63个视频来验证算法有效性。为了进一步验证本文方法的有效性,使用复杂背景下的煤矿井下监控视频数据集验证本文方法。煤矿井下监控视频数据集包含10个场景共86个视频,总时长9 678.36 s。
3.2 参数设置与实验方案
在使用MOG2 模型对测试样本的视频数据进行背景分割和中值滤波去噪时,涉及的参数有高斯分量数量NMixtures,背景比率BackgroundRatio 和滤波器尺寸ksize。参数设置如表1所示。

表1 参数设置Table 1 Parameters setting
假设视频集V={V1,V2,…,Vn} ,FD-means 聚类中心对应的视频S={S1,S2,…,Sk} ,需要保留的视频T={T1,T2,…,Tj} 。在近重复视频的数据清洗过程中,一方面要保证视频数据集的完整性,另一方面要尽可能的清除近重复视频数据。为此,本文参考文献[22]采用准确度Acc、召回率Rec以及F1-score 作为实验评价指标。
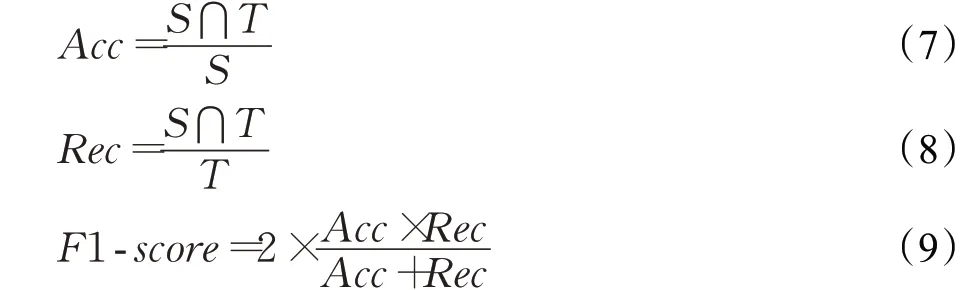
为了验证本文所提方法的有效性及其性能,本文针对CC_WEB_VIDEO和煤矿井下监控视频数据集,通过对比VGG-16+FD-means方法、LSH+SNM[12]、背景分割+SNM(BS_SNM)和本文所提方法背景分割+VGG16+FD-means(BS+VGG16+FD-means),进行实验对比与分析。
3.3 实验结果及分析
为了分析FD-means算法对近重复视频清洗结果的影响,首先对K-means与FD-means算法做了对比实验,如图4 所示。在给出近重复视频种类数及最优距离阈值时,在两个数据集上分别进行5 次实验,在煤矿井下监控视频集中FD-means的F1-score在0.71~0.74范围波动,K-means 的F1-score 在0.58~0.67 范围波动,在CC_Web数据集上,FD-means的F1-score在0.70~0.76范围波动,K-means 算法的F1-score 在0.57~0.64 范围波动。总的来看,FD-means 和K-means 算法均存在初始值敏感问题,但是FD-means 算法波动下限依旧高于K-means算法的波动上限。本文认为这是因为K-means在聚类过程中由于固定的聚类数,将一些差异性较大的数据强行划分到同一个类别中,从而造成了数据误删的情况,这种误删容易破坏视频数据集的完整性,而FD-means 算法在更新聚类簇时,如公式(3)和(4)通过距离阈值尽量避免了强行划分的问题,从而改善聚类结果。
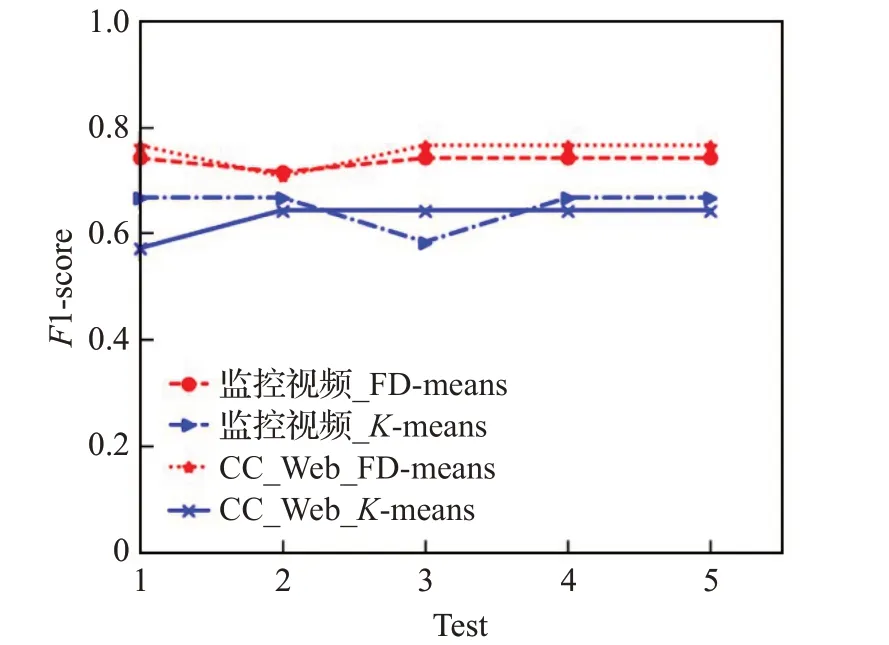
图4 随机初始值对最终聚类算法结果的影响Fig.4 Effect of random initial value on final clustering algorithm result
为了说明特征距离阈值对视频清洗结果的影响,图5显示了F1-score随特征距离阈值Th的变化曲线,可以看出当距离阈值在8~9 之间时结果最佳。本文方法的曲线先增再降,这是由于一开始Th较小,大多数视频被认为不是近重复,此时召回率高,准确度低。随着Th的增加,FD-means能够准确检测到近重复视频,从而提高了准确度。当Th持续增大时,不相似视频被认作近重复视频造成误删,导致算法召回率下降。对比图中曲线,本文算法明显优于传统的LSH+SNM算法。
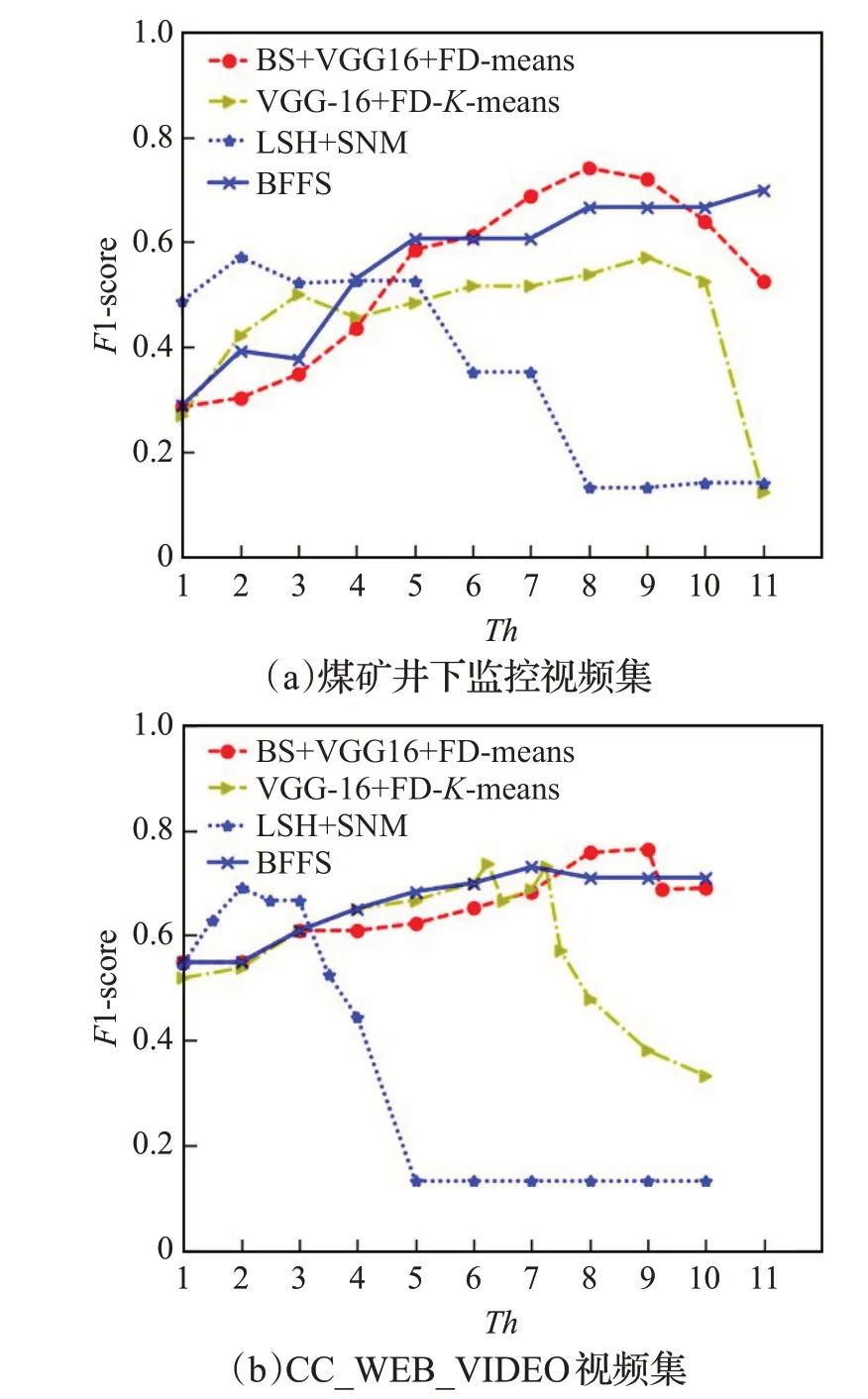
图5 各方法的F1-score随距离阈值的变化曲线Fig.5 Change curve of F1-score with distance threshold for each method
表2 是各方案分别与CC_WEB_VIDEO 数据集在煤矿井下监控视频下的近重复视频清洗方法对比的结果。由表2可见,与使用全局特征的VGG-16+FD-means方法相比,本文提出的方案清洗结果更好,这说明使用煤矿井下监控视频的背景和前景特征能更好的描述视频特征。
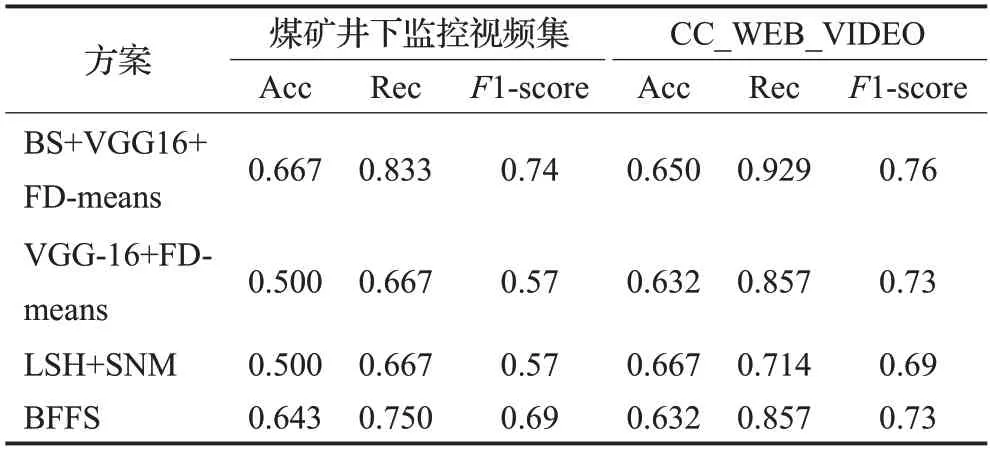
表2 视频清洗结果对比Table 2 Comparison of video cleaning results
本文方案与BFFS方法相比,采用FD-means方法的视频清洗结果优于采用SNM 算法的BFFS 方案。本文提出的方法与现有的LSH+SNM方法相比,具有更好的性能。相对于煤矿井下监控视频的清洗结果,在CC_WEB_VIDEO数据下本文提出的方法清洗结果与LSH+SNM相比F1-score更高。其原因在于CC_WEB_VIDEO中的视频为多媒体视频,背景变化复杂多样,在使用视频背景检测近似背景视频时,出现错误结果,从而降低了实验的准确度和F1-score。
此外,如图6 所示,分别在煤矿井下监控视频数据集和CC_WEB_VIDEO数据集上进行视频清洗,可以减少视频占用磁盘大小,降低存储成本。对比图6,在F1-score 最优时,降低了70%的视频所需磁盘大小。视频存储节约的具体情况依赖于近重复视频的密度,同一个类内近重复视频越多,通过视频清洗节约的存储越多。在视频清洗过程中,只保留近重复视频中的中心视频,极大降低视频存储空间。在两个不同数据集上进行实验验证,使用视频背景及前景特征进行FD-means 视频聚类能够准确检测到近重复视频,该方法能够自动清洗视频,且清洗结果也优于其他方法,并且能够有效降低存储。
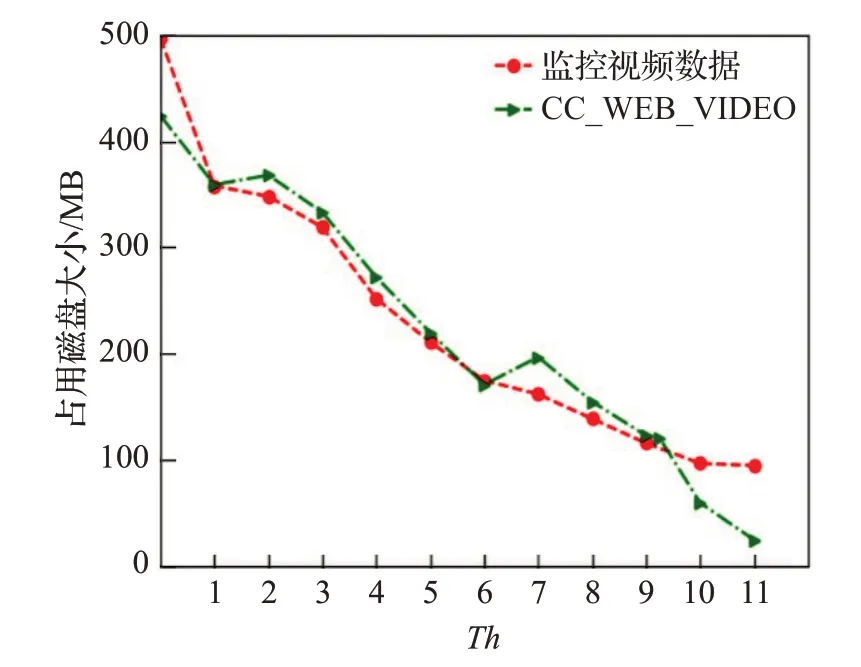
图6 本文方法清洗后结果占用磁盘大小随距离阈值的变化曲线Fig.6 Change curve of occupies disk size with threshold distance of proposed method cleaning results
4 结束语
本文提出了一种融合VGG-16 深度网络与FDmeans 聚类的近重复视频清洗方法,首先,使用MOG2算法对视频背景建模提取前景目标,其次使用VGG-16网络模型提取视频深度特征,最后,提出一种新的FD-means 聚类算法用于进重复视频检测及清洗。本文分别在煤矿井下监控视频集和CC_WEB_VIDEO公共数据集进行实验,结果表明:使用背景和前景特征描述视频比全局特征更好;相比于SNM,使用FD-means 进行视频清洗具有较高的准确率。本文方法在保证视频集完整性的基础上,能够对近重复视频实现自动清洗。将在后期的工作中对本文的方法加以改进,一方面结合数据密度的度量方法降低FD-means算法对初始值的敏感性,另一方面通过结合视频的时空特征或结合视频的其他特征,使其能够提高视频清洗的准确度。
