基于Q学习算法的城轨列车智能控制策略
2022-01-22金则灵武晓春
金则灵,武晓春
(兰州交通大学自动化与电气工程学院,兰州 730070)
随着城市的快速发展,城市人口数量大幅增加,交通问题日益突出,城市轨道交通以其运量大、速度快、占地少的特点,成为缓解城市交通的有效途径。据统计,截止2020年底,我国城市轨道交通运营总长度7 545.5 km,大规模、高密度的行驶使得城市轨道交通的运行能耗急剧增长,其中,站间的牵引能耗占系统总能耗的50%。因此,减少牵引能耗,优化控制策略成为近几年研究的热门。
列车的实际运行情况通常较为复杂,再加上机械磨损等不确定因素带来控制参数的变化,以PID为代表的经典控制器,很难精准控制列车运行[1]。
近年来,智能控制和算法迅速发展,越来越多的学者将无模型的解决方法应用于列车运行控制过程。成莉,俞花珍等[2-3]利用遗传算法求解高铁列车和重载列车的节能运行控制;黄友能,李诚等[4-5]利用粒子群算法分层优化列车节能驾驶策略;徐凯等[6-8]将列车运行过程划分为多阶段的决策过程,采用动态规划和时间差分进行求解;张淼等[9]将司机驾驶经验与智能驾驶技术结合,设计了基于策略的强化学习方法;郭艳梅[10]通过深度强化学习,根据列车的需求生成一套模糊控制方案。
强化学习(Reinforcement Learning,RL)是一种基于奖惩原则的学习策略,起源于行为心理学的发展和应用[11]。与其他人工智能算法不同的是,强化学习无需先验知识,具有较强的鲁棒性。Q学习算法是强化学习中典型的无模型算法,由Watkins等在1992年提出的类似于动态规划算法的一种激励学习方法,目前已经被广泛应用于各个领域[12-13]。
在大多数城市轨道交通的节能运行控制中,采用离线计算的方式优化行车曲线,在列车运行过程中跟踪优化的曲线,且面对突发情况时,往往由ATO系统转向人工驾驶模式,大大降低鲁棒性。针对上述问题,以城市轨道列车为研究对象,建立列车的动力学模型,以杭州地铁5号线三坝—萍水站线路为例,提出了一种基于Q学习算法的城轨列车控制策略,将列车连续状态划分为离散的状态空间,建立列车时间和能耗奖惩函数作为算法学习的方向,对算法进行迭代训练。在列车运行过程中,根据列车的行驶状态,在不使用离线速度曲线的情况下,实时计算最佳控制策略。在Q学习算法中,引入参考专家驾驶经验的-greedy策略和按三角衰减的周期变化学习速率,有效提高了传统Q学习算法的学习速率,解决了收敛慢的问题。
1 列车动力学方程
研究的对象为城轨列车,城轨车辆一般为6节编组,故将列车简化成单质点模型[14]进行计算。对列车进行受力分析,根据牛顿定律,给出单质点运动方程为
(1)
式中,v(t)为列车当前速度,m/s;M为列车总质量,t;F(v)为列车施加的牵引力(或制动力);R(v)为列车的基本阻力;G(i)为线路坡道阻力。
列车的基本阻力在实际应用中以戴维斯公式表示,计算公式为
R(v)=(av2+bv+c)·M·g
(2)
式中,g为重力加速度常数,取9.8 m2/s;a,b,c为与机械阻力相关的系数,一般通过拟合不同的车型得出曲线。
列车在坡道受到的阻力称为坡道阻力,坡道阻力的计算公式为
G(i)=i·M·g
(3)
式中,i为坡道坡度千分数。在城轨列车中,线路坡道对列车的牵引制动影响远大于其他阻力,因此将坡度因素从阻力中独立出来[15]。列车在运行过程中还会受到曲线附加阻力、隧道空气附加阻力的影响,这些影响较小,为简化计算可忽略不计。
2 Q学习算法
Q学习算法通过函数迭代的方式,获取相应的奖惩值,不断逼近最优策略,Q学习算法是由一个四元组

图1 Q学习算法原理
状态-动作值函数Q(s,a)为状态s下执行动作a对应的期望回报,计算过程为
E[Rt+1+λRt+2+…+λn-1Rt+n|st,at]
(4)
式中,λ为折扣率,表示长期回报的权重。当Agent完成了完整路径后,才能获取该状态奖励。根据贝尔曼原理将公式(4)转化为多阶段决策进行计算
Qπ(st,at)=E[Rt+1+λRt+2+…+λn-1Rt+n|st,at]=
E[Rt+1+λ(Rt+2+…+λn-2Rt+n)|st,at]=
E[Rt+1+λQπ(st+1,at+1)|st,at]
(5)
Q学习根据时间差分思想(Temporal-Difference,TD)进行值迭代[15],在每次迭代过程中优化状态-动作值函数Q,减少和目标值之间的偏差
Q(st,at)=Q(st,at)+
α(Rt+λmaxatQ(st+1,at)-Q(st,at))
(6)
式中,Rt+λmaxatQ(st+1,at)为TD目标;Rt+λmaxatQ(st+1,at)-Q(st,at)为TD偏差;α为学习速率,决定了学习多少误差。
Q学习算法的目标是求解出最大状态-动作函数对应的策略,即
π*=arg maxatQπ(st,at)
(7)
3 基于Q学习的列车控制策略
列车的控制策略π(at|st)取决于t时刻的列车位置以及运行速度,具有马尔可夫性,因此,以列车作为智能体,将列车的运行过程建立为MDP模型,如图2所示,为基于Q学习的列车控制策略更新过程。以列车位置和速度作为状态空间集S,列车对速度的控制作为动作空间集A,运行时间和牵引能耗作为奖励函数R,初始化Q值为奖励函数,即Q(st,at)=R(st,at),给算法提供先验知识。列车的下一个状态根据动力学方程计算得出,按公式(6),更新得到最大状态-动作函数对应的列车控制策略。

图2 基于Q学习的列车控制策略
3.1 状态和动作空间集定义
首先,定义Q(st,at)中的状态s和动作a。如图3所示,根据最大牵引加速度和制动减速度计算出列车最快速度曲线和列车最短运行时间Tmin,在实际运行中列车速度需始终低于该速度。将列车运行的过程离散化,把路程按ds划分为k个,把最快速度按dv划分为l个,组成列车所有的状态集合S={s1,s2,s3,…,sk×l}。以不同速度作为控制列车的动作空间集,即A={a1,a2,a3,…,al}。ds和dv越小,描述列车状态越精确,对应计算量也越大。

图3 列车状态空间集
在满足限速条件下,列车的动作策略需满足列车运行条件的动作,即
(8)
(9)
式中,afmax和abmax为列车的最大牵引加速度和最大制动加速度。列车根据选取出的动作,做匀加速运动至下一个状态,完成状态转移。
3.2 奖励函数设计
奖励函数关系到算法学习的方向,针对准点运行和节能运行的目标,建立运行时间和牵引能耗对应的奖励函数,即时间奖励函数RT和能耗奖励函数RE,设计综合奖励函数如下
R(st,at)=μRE(st,at)+RT(st,at)
(10)
式中,RE和RT为一一对应的关系;μ将RE和RT平衡至同一数量级。根据pareto最优解理论,μ取满足列车运行时间的最大值。当μ=0时,列车以最快驾驶速度策略行驶。对不符合列车运行条件和超速的动作,定义,避免算法学习到此类动作。
(1)时间奖励函数
时间奖励函数可表示为
(11)
式中,Tplan为列车运行计划时间;T为列车两状态间运行时时间。用Tmax-T表示列车在两个状态间运行时间所用越少,奖励越高;运行时间越久,奖励越少。
(2)能耗奖励函数
能耗奖励函数可表示为
RE(st,at)=C-Ei=
(12)
式中,C为大于两状态间最大能耗的常数;E为列车两状态间运行的能耗,同理能耗越大,奖励越少。
3.3 最优控制策略
为输出合理的控制策略,需考虑列车运行过程中的舒适性、列车操纵规则等约束条件,对司机驾驶过程进行数学分析,给出合理的控制策略。
实际列车不同工况之间的转换不是任意的,必须满足转换规则[16],即
(13)
舒适性是控制城轨列车的重要标准,根据文献[17],列车加速度变化率<1 m/s3时,认为乘客是舒适的。
(14)
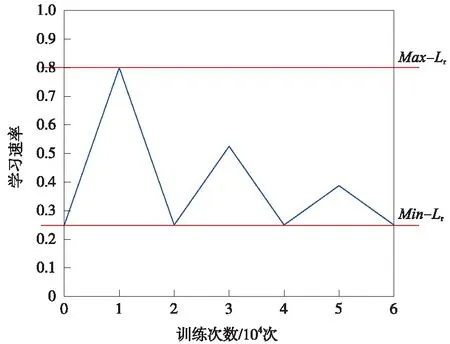
Q算法训练完成后,根据列车当前状态选择满足公式(13)、公式(14)约束条件动作,用公式(7)计算当前状态最优控制策略,列车运行时间和牵引能耗用各个状态间时间和能耗的总和计算,如公式(15)、公式(16)。若列车因故障自身晚点,且小于剩余最短运行时间5 s,即Tplan-T (15) (16) 为克服Q学习算法收敛速度慢的问题,在传统Q学习算法的基础上加入基于驾驶经验的-greedy策略,使算法根据列车的实际情况有目标的进行搜索,同时引入按三角衰减的周期变化学习速率,在保证收敛的情况下,减少算法的迭代次数。 强化学习算法的性能在很大程度上受算法控制策略中的两个重要因素影响,即“探索”和“开发”[18]。随机选择动作为探索,保证了Agent尽可能多的尝试所有动作,但收敛速度慢;选取最大回报的动作为开发,则会让Agent陷入局部最优解。一种常见的方式是使用-greedy策略进行探索和利用。在每一次迭代中以的概率选择随机动作,以1-的概率选择最优动作,同时兼顾探索和利用的平衡。为避免探索到无效的动作,提高Q算法学习效率,提出一种将司机驾驶经验加入到-greedy中的探索过程,实现过程如图4所示。具体步骤为:当Q学习选择随机动作时,计算列车当前的位置st和速度vt,根据位置和速度判断列车当前所处的阶段,并探索相应的驾驶策略。 图4 基于驾驶经验的-greedy策略流程图 运用此基于驾驶经验的随机选择策略,降低了动作选择的盲目性,减少了无效探索的次数,有助于提升算法训练效率。 3.4.2 周期学习速率 学习速率(Learning rate,LR)是强化学习中的一个重要参数,决定着能否收敛到最小值,何时收敛到最小值。根据公式(6)整理得到 Q(st,at)=(1-α)Q(st,at)+ α(Rt+λmaxatQ(st+1,at) (17) 式中,Q(st,at)为更新前的Q值,可以看出,学习速率越大,保留之前的训练效果越少,因此,选择合适的学习率十分重要。在实际应用中,一般采取固定的学习速率,或者离散下降学习率(discrete staircase Learning rate,DSLR),即经过一段轮次的训练,学习速率减半。Smith L N等[19-20]提出一种三角周期学习率,让学习率在边界之间变化,避免陷入局部最优解。文中引用一种按三角衰减的周期变化学习速率(Descent-Triangle Learning rate,DTLR),即学习速率的变化范围随训练次数的增加而减少,变化过程如图5所示。 图5 学习速率变化过程 图5中Max_Lr和Min_Lr为学习速率的最大值和最小值,可通过实验测试得出。在给定的迭代次数内能保证收敛的最小的学习速率设定为Min_Lr,提高学习速率,当训练结束,曲线依然震荡,此学习率设为Max_Lr。在一个变化周期内,学习速率的计算公式为 (18) (19) β=T-1 (20) α=Min_Lr+(Max_Lr-Min_Lr)· (21) 其中,τ为一次周期的长度,根据循环次数及变化的周期次数给定;e为当前的迭代次数;β为所处的周期。每一轮周期结束后,Max_Lr-Min_Lr缩减一半,以提高状态-动作函数的收敛速度。 为验证算法的有效性,选取杭州地铁5号线三坝站至萍水街站为例,线路参数如表1所示。 表1 线路参数 杭州地铁5号线使用AH型地铁列车,假设列车处于额定载荷(AW2),车辆具体参数如表2所示。当列车处于AW2工况下牵引运行时,启动加速度为1.09 m/s2,平均加速度为0.68 m/s2,牵引或者制动时,列车均采用无级控制。 表2 车辆具体参数 设置进行60 000次的训练学习,Q学习算法具体参数设置如表3所示。列车初始状态为s1(x1=0,v1=0),列车的加速度由车辆的参数和Q-learning动作策略确定,一旦列车抵达终点,将列车最终状态st(xt=1475,vt=0)重置为初始状态,完成一次训练。 表3 算法参数设置 为验证算法的有效性,将本文算法与最快速度驾驶策略、文献[21]传统动态规划算法进行比较,方案1为最快速度驾驶,方案2为本文驾驶策略,方案3为传统动态规划算法。考虑到存在随机性,对每个算法进行20次仿真取均值,且在训练过程中,-greedy给定相同的随机序列δ,仿真列车运行曲线如图6所示。 图6 列车运行仿真曲线 观察图6的列车运行仿真曲线,3个方案均满足固定限速要求。在牵引阶段,3个方案都以列车最大运行能力加速至最大运行速度,方案2的最大速度低于方案1和方案3;在惰行阶段,方案2和方案3采用了惰行节省能耗,方案3在最后一段上坡道开始时采取惰行策略,而方案2为满足准点运行,在1 000 m左右开始惰行;在制动阶段,方案1最先开始制动,其次是方案3,最后是方案2。仿真计算对比结果如表4所示。 表4 不同方案仿真计算结果 计算运行时差和节能率作为评价正点运行和节能运行目标,对比表4数据可得,3种方案均满足准点运行的要求,方案1站间运行时间最短,牵引能耗最大;方案2和方案3的控制策略能耗较于最快速度的驾驶策略均有不同程度的减少。传统动态规划法所得控制策略,列车运行能耗为29.16 kW·h,运行时间95.13 s,本文所采用的Q学习算法所得控制策略,列车运行能耗为27.94 kW·h,运行时间98.03 s,相较于最快速度驾驶节能效果为13.01%,相较于动态规划算法节能效果进一步提升3.79%。同时对比发现,在相同的线路上,列车运行的时间越长,列车所能选择控制策略越多,节能的效果越好。 为进一步验证算法的有效性,在原线路上增加一段500 m临时限速区段,对方案1和方案2进行重新仿真,仿真列车运行曲线如图7所示,所得仿真计算结果如表5所示。 图7 增加临时限速列车运行曲线 表5 增加临时限速后不同方案仿真计算结果 从图7列车运行曲线看出,经过限速区段后,Q学习算法列车为保证准点运行,没有直接选择惰行策略,而是经过一段时间加速后再选择惰行和制动,运行时间99.57 s,满足列车时刻表要求。增加临时限速后不可避免的增加了牵引能耗7.5%,相较于最快速度驾驶策略节能12.66%,证明Q学习算法在满足准点运行下,仍具有节能效果。同时对比无限速情况发现,增加临时限速后,列车的操纵策略变得复杂,为满足准点运行,节能率会有所降低。 图8 不同探索策略收敛结果 从图8可以看出,相较于前2个方案,基于专家驾驶经验动作选择策略。在前期训练中明显减少了盲目的探索,更快的接近最优解,进一步计算3种方案不同阶段的方差,结果如表6所示。 表6 不同探索方案仿真计算结果 从计算结果看出,在训练初期使用大探索率效果较好,中后期使用小探索率可以更精确的收敛,本文提出基于专家驾驶经验动作选择策略,相较于其他探索策略,前期探索更接近最优速度曲线,训练初期方差降低了16.4%和58%,总体方差降低了20%和47.2%。结果表明,加入了专家驾驶经验的探索策略,在训练初期引导算法朝着目标策略进行学习,减少了无效学习,加快收敛速度。 (1)针对城轨列车的节能运行,以准点性、舒适度和节能运行为指标,提出一种无需使用离线速度曲线的Q学习算法列车智能控制策略,将-greedy策略与司机驾驶经验相结合,提高算法学习效率。 (2)仿真验证表明,Q学习算法在保证准点运行的情况下,可有效解决列车运行的节能问题。在增加临时限速区段后,该算法可根据运行时间,调整列车控制策略。 (3)使用离散化的速度作为状态空间,且未考虑列车运行过程中时刻表调整及列车牵引性能发生变化等情况,细化列车状态空间,进一步提高计算实效性及列车运行时刻表调整后如何在线计算是下一步的研究方向。3.4 优化Q学习算法

4 仿真验证及性能分析
4.1 参数设置



4.2 测试结果分析






5 结论
