基于改进免疫算法的容量限制工厂选址仿真
2022-01-22李睿雪
李睿雪,马 良,刘 勇
(上海理工大学管理学院,上海 200093)
1 引言
传统容量限制工厂选址问题解决的仅是针对某一区域网络中的备选点和需求点之间最优路径问题,选取能使总距离最小同时能满足需求点需求的位置作为最佳备选点。但是在实际生产活动中,工厂的选址问题不仅涉及到备选点的位置,还涉及到备选点的生产能力。一个好的工厂位置可以降低工厂的运输成本,并能在满足需求的前提下减少一定的成本消耗。因此,对于处于最优位置并能够满足需求的备选位置,需要建立生产规模合适的工厂,使投入成本达到最低。
相关学者针对容量限制的设施选址问题做出了大量研究。于宏涛[1]在针对工厂容量受限的问题上改进了基础的容量限制模型,将其转化为背包问题,提出贪婪蚁群算法,得到了模型的最优解,但是在算法的改进效果不足。肖俊华[2]在无容量限制的多目标多级覆盖的问题上加入了容量限制,并设计了上升式启发式算法,对模型加以验证。漆杨[3]分析了容量受限的工厂选址问题的现有不足,将传统的免疫克隆算法中的抗体生产和抗体变异过程进行改进,但算法的收敛性略有不足。俞武扬[4]将设施的容量作为限制条件,建立模型,采用了模拟退火算法对数值例子进行求解,得到了不同容量的选址策略。陈中武[5]在对成本约束的选址模型中加入了以顾客的随机需求的随机参数,利用拉格朗日松弛算法得到了较好的效果。袁藩[6]从单种产品的容量限制的设施选址问题拓展为k种产品,并采用了近似算法得到最优解,但是对于某些单位置多工厂的方案仍未解决。尚志勇[7]针对带有容量限制的配送中心选址问题,改进了布谷鸟算法的发现概率,得到了较好的效果。
通过以上分析发现容量限制选址模型研究中多考虑固定的生产能力,忽略了备选位置的生产规模带来的影响以及该位置的二次扩建。为此本文对每一个工厂的生产能力进行了划分,设置分阶段的可选择的生产规模。对CPLP(Capacitated Plant Location Problem)[7]模型进行了改进,将建设成本分解为生产成本和固定建设成本,其中生产成本是根据需求量的大小来决定的。从而构建考虑生产能力的容量限制工厂选址模型进行优化。
2 容量限制下的工厂选址模型
2.1 传统容量限制选址的数学模型
在容量限制的选址模型中目标是在备选位置中选择能使距离成本最小和建设成本最小的最优位置。设I为备选工厂的位置集;J为需求点的位置集;ai为备选工厂i在固定成本ci下的生产能力;dj为需求点的需求量;tij表示从备选工厂i到需求点j之间的运输成本。其目标在于不超出工厂的生产能力的前提下,选择最优的备选位置。模型如下[14]
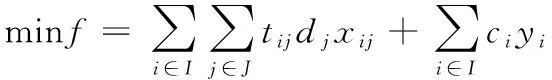
(1)
s.t.
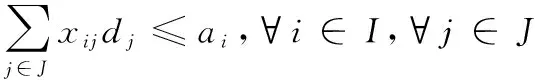
(2)
xij=0,1 ∀i∈I,∀j∈J
(3)
yi=0,1 ∀i∈I
(4)
xij≤yij∀i∈I,∀j∈J
(5)
模型中目标函数是(1)表示工厂选址的运输成本和固定生产成本之和最小;约束式(2)表示备选工厂所服务的需求点的需求之和不超出该备选工厂的最大生产能力;式(3)、式(4)表示为决策变量约束,xij为工厂i对需求点j服务,yi为在备选位置i选择建设工厂,其中开放取值为1,否则是关闭取值为0;式(5)表示确保需求点和开放的备选位置保持对应。
2.2 改进容量限制选址模型
对原有的基础模型和文献[8]的模型进行改进,其中文献[8]的模型尽管考虑到了对生产能力进行分段考虑,但是缺少对需求点和备选点的距离的考虑。借鉴这一思想将基础模型中的固定成本分解为生产成本和固定成本,生产成本由生产能力决定,而生产能力设置为分阶段式,根据备选工厂所需要满足的总需求量来选择最合适的生产能力阶段;并且基于实际生产情况考虑,在生产能力规模较大时,单位生产成本较小;固定成本则是由备选点决定的固定值。由此建立了全新的数学模型:
设I为工厂备选位置的合集;J为需求点的位置合集;tij为备选位置i到需求点j的运输成本;dj表示需求点j的需求量;ein表示备选位置i的实际选择的第n阶段生产规模;gi表示备选位置i的最大生产规模;hi表示工厂i在该地点的基础建设成本;kin表示工厂i在n阶段生产能力下每单位的生产建设成本。模型如下

(6)
s.t.
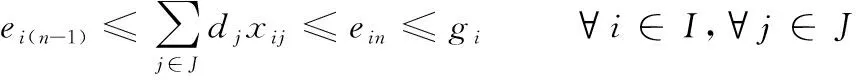
(7)
xij=0,1 ∀i∈I,∀j∈J
(8)
yi=0,1 ∀i∈I
(9)
xij≤yij∀i∈I,∀j∈J
(10)
模型中目标函数是(6)表示工厂选址的运输成本和生产成本之和最小,其中生产成本由基础建设成本和生产成本。约束式(7)表示需求点的需求之和大于备选工厂i的n-1阶段生产能力且小于备选工厂i的n阶段生产能力并且不超过备选工厂的最大生产能力;式(8)、式(9)表示为决策变量约束,xij为工厂i对需求点j服务,yi为在备选位置i以选择建设工厂,其中开放取值为1,否则是关闭取值0;式(10)表示确保需求点和开放的备选位置保持对应。
3 改进免疫遗传算法求解
3.1 传统免疫遗传算法的原理
传统免疫遗传算法(Immune Genetic Algorithm,IGA)[9]是基于生物免疫系统的启发而形成的算法,与遗传算法类似,但是主要区别在于免疫遗传算法对个体的评价标准不仅有适应度还有亲和度,使得出的种群的多样性更加丰富。其中主要的亲和度就是利用了免疫系统的多样性产生和维持机制来保持群体多样性,克服了一般寻优过程中会出现“早熟”现象。
3.2 传统免疫遗传算法设计
1) 编码。将备选工厂编号和工厂与需求点对应关系作为解,因此采取整数编码。个体编码由前半部分的位置编号信息和后半部分的选择点和需求点对应关系共同组成;
2) 抗体群的产生。初始的抗体在解空间中用随机的方法产生;
3) 解的评价。亲和力是抗体对抗原的识别,本算法中抗体和抗原的亲合力函数Av:
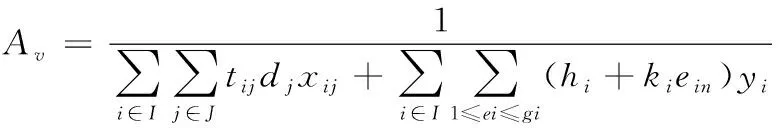
(11)
其中,分母中第一项为目标函数。抗体和抗体之间的亲和力函数Sv
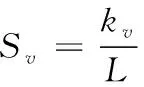
(12)
其中,kv表示为两种抗体中相同的位数,L表示抗体的长度
抗体的浓度,即抗体在种群中的比例函数Cv
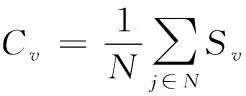
(13)
其中,N为抗体总数。
抗体和抗原间的亲和力和抗体的浓度共同作用形成了期望繁殖概率函数P

(14)
其中,λ是一个常数;
4) 形成父代记忆库。将个体按照繁殖率进行排序,保留s个个体进入记忆库,进入下次迭代;
5) 免疫操作。免疫包括了选择、交叉和变异3种,其中选择方式按轮盘赌策略进行选择;交叉方式按照单点交叉进行交叉操作;变异方式按照随机选择变异位进行变异操作。
3.3 改进的免疫遗传算法
由于传统的免疫遗传优化算法中记忆库中的优秀个体的保留过于保守,随着迭代的进行,种群的质量更高,却不能保存更多的优秀个体,造成收敛速度过慢,计算精度也会受到影响。通过设置动态保留机制,提出了一种动态保留优秀个体免疫遗传算法(New Immune Genetic Algorithm,NIGA)。对记忆库中的优秀个体数s设置为动态变化,随着种群的总体质量的提高,优秀个体的保存数也随之增大。其中s由种群的质量函数确定
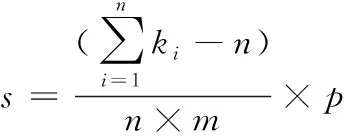
(15)
其中m为备选点数量,n为需求点数量,p为记忆库规模,ki表示选择点和该需求点的距离在备选点和该需求点的距离集总的降序位置。
其次是免疫遗传的选择过程,传统的免疫遗传的遗传部分中选择操作多为轮盘赌等方式操作[10],依靠一定概率来保留最优个体,这样往往会增加计算量和迭代次数,同时也会影响计算精度。因此,本文根据Metropolis准则来对选择操作的种群进行选择[11]。对一个种群中的第i个个体与第i+1个个体进行比较,选择接受第i+1个体规则如下,否则接受第i个体
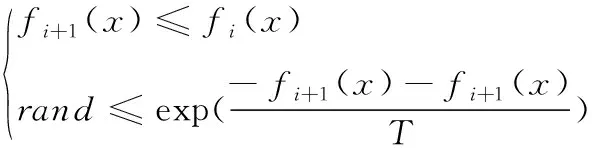
(16)
其中f(x)表示适应度值;rand是在[0,1]上均匀分布的随机数;T为温度。
3.4 改进的免疫遗传算法步骤
1) 产生初始抗体群;
2) 计算种群的适应度值和亲和度值;
3) 对群体中抗体以期望繁殖率P进行评价;
4) 形成父代群体,进行排序后保留s个个体和m个记忆库个体。其中s个个体由种群的质量决定;
5) 判断是否满足结束条件;
6) 对(3)形成的新群体进行选择、交叉、变异操作得到新群体,再取出记忆库个体,形成新群体;
7) 继续执行步骤3)。
4 计算实验
4.1 模型对比
由于真实数据难以获取,本文采取模拟数据的方法设立两组算例对算法进行验证,运用Matlab2016a编程进行模拟数据实验。首先模拟算例1的数据模型进行验证:假设备选工厂的数量为5个,从中选出2个备选工厂位置对这些需求点进行服务。需求点数量为30。每个需求点的需求量在[0,100]中随机产生,需求点的坐标在4000*4000的网格中随机产生。备选工厂的位置、建厂固定成本、工厂不同阶段的生产规模见表1。
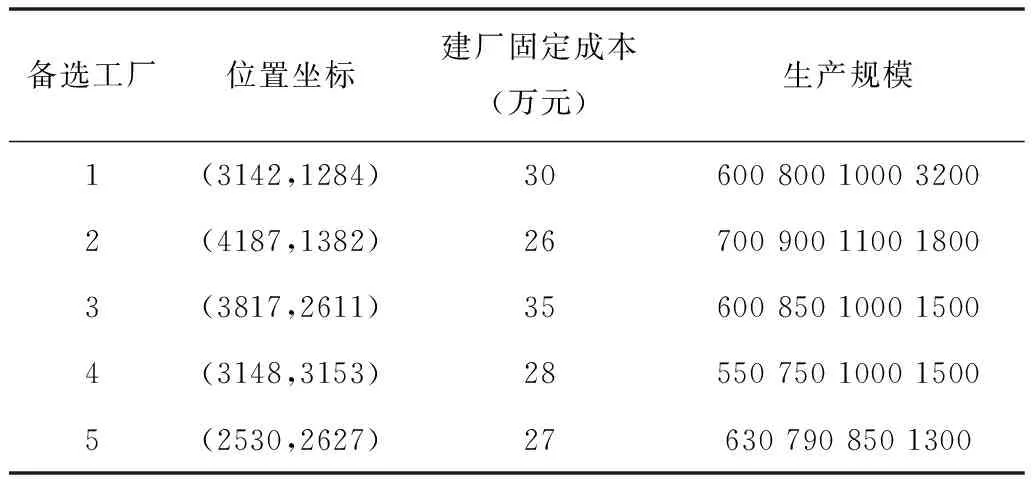
表1 算例1备选工厂数据
改进免疫遗传算法的初始参数设置:初始种群大小为60,记忆库规模为20,交叉概率0.7,变异概率0.2,种群多样性为0.9,迭代次数为150次,初始温度为T为180,终止温度30度。独立运行了20次。得到的结果见表2。

表2 算例1数据集运行结果
从结果中可以看出来,尽管改进模型加入了生产规模的成本,但是相对于基础模型的成本增加并不多,两次结果也计算都算出了最佳的3号工厂位置为最佳位置之一,而在考虑到生产规模后5号位置就明显优于1号位置,其原因是因为5号位置的生产规模选择的成本低于1号位置,使该位置的成本低于1号位置,并对需求进行分配的能力也优于1号位置。可见在改进后的模型中,备选位置的生产规模的选择也是决定一个备选位置的关键因素,能够更加合理的分配了产品的生产和分配。
之后算例2的数据模型进行验证:备选工厂的数量为10个,需求点数量为60。从中选出2个备选工厂位置对这些需求点进行服务。每个需求点的需求量在[0,100]中随机产生,需求点的坐标在4000*4000的网格中随机产生。备选工厂的位置、建厂固定成本、工厂不同阶段的生产规模见表3。
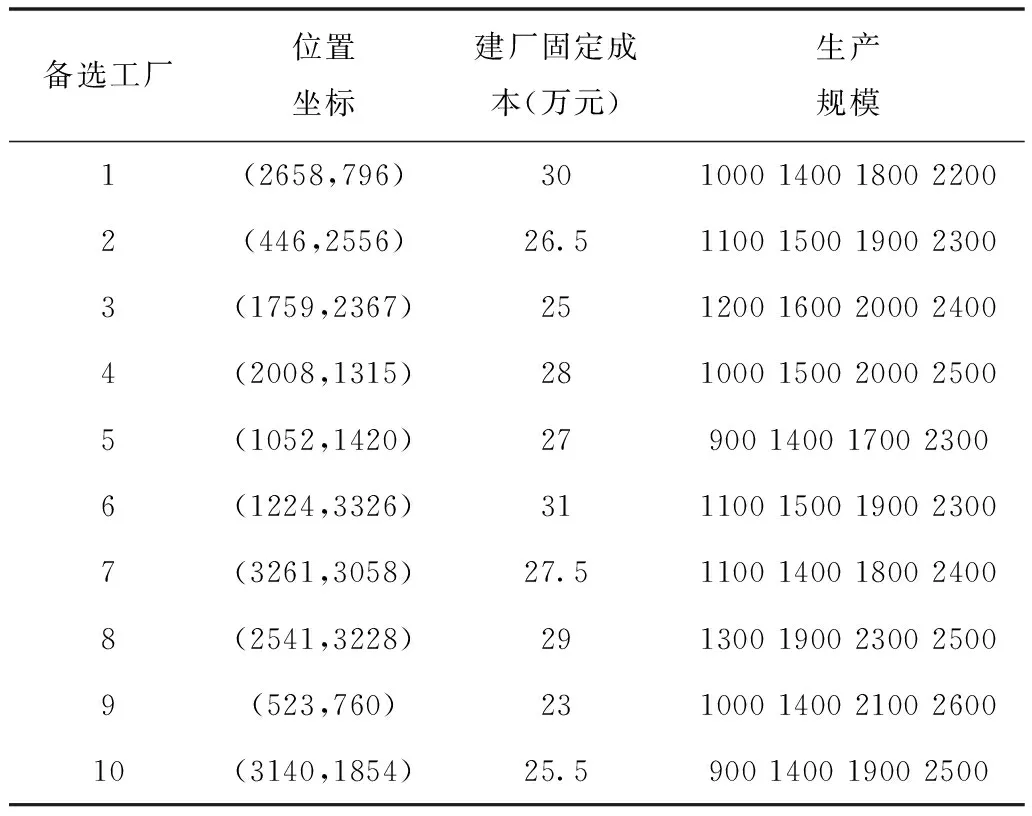
表3 算例2备选工厂数据
改进免疫遗传算法的初始参数设置:初始种群大小为60,记忆库规模为20,交叉概率0.8,变异概率0.3,种群多样性为0.9,迭代次数为200次,初始温度为T为210,终止温度10度。独立运行了20次。得到的结果见表4。
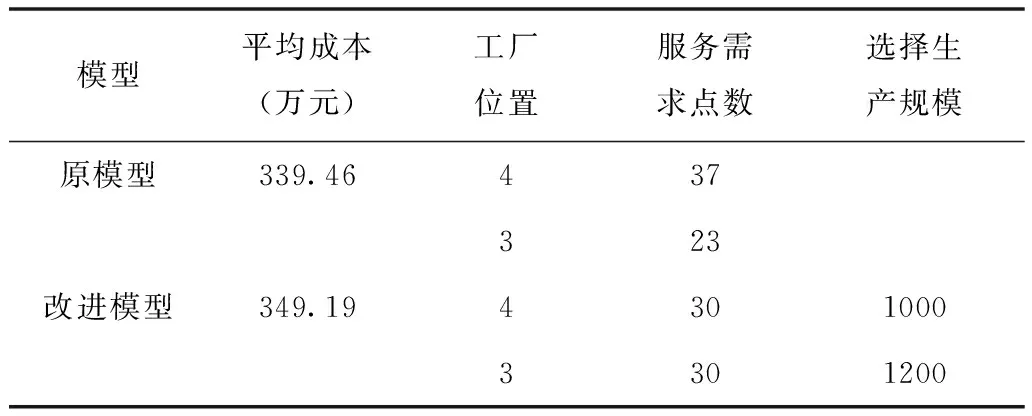
表4 算例2运行结果
从结果中可以得出,在数据量扩大后,相对于算例1总成本提高。原模型在不考虑生产规模的情况下,成本低于改进模型的成本。但是两组算例的成本之差是由于原模型中没有设定生产所产生的成本。在工厂位置上,两模型都找到了最佳的位置,但改进模型对于需求的分配更加平均,而原模型的分配方案有一定程度增加工厂生产负荷的风险。相比之下,改进模型的分配方案更加合理,而且在成本上也是略高于没有考虑生产规模成本的原模型。可见改进模型更加适合工厂生产建设的实际情况。
4.2 算法对比
对模型改进分析后,对算法改进前后的效果进行对比,具体参数保持不变,对两种规模的模型进行对比实验。迭代结果如图1和图2。

图1 算例1改进前后迭代对比图
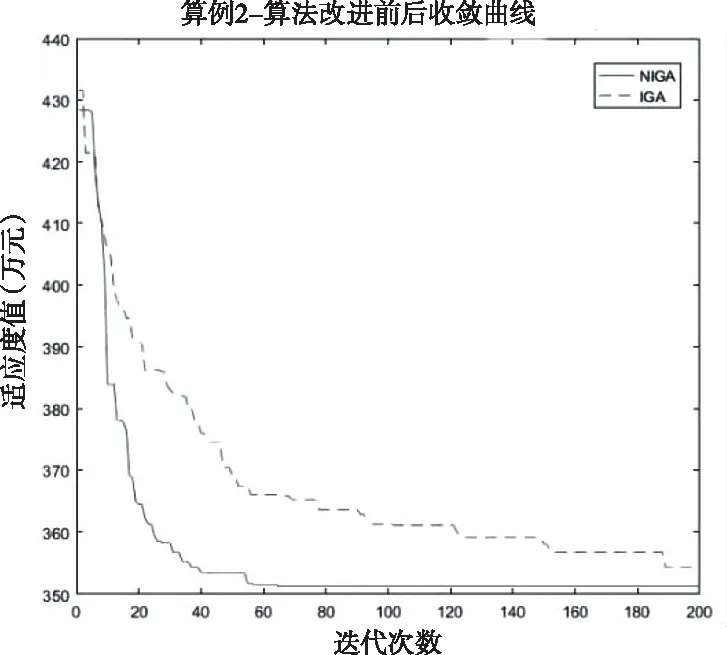
图2 算例2改进前后迭代对比图
由图1可以看出算例1在数据量较少时改进的免疫遗传算法的迭代次数比基本免疫遗传算法提高了很多,很快就可以达到收敛,并且在计算精度也有所提升。因为规模较小时的计算量不大,计算速度较快,所以改进后迭代速度明显提高而精度小幅度提高。而在算例2中数据量相对增加后改进免疫遗传算法收敛速度加快并且精度上也有所提升。因为算例2的种群中个体的编码长度较长,依靠动态的记忆库个体保存机制和新的遗传选择方法可以在每次迭代中更大程度保留最佳的个体,从而更快的找到最优的结果,大大提高计算速度。在计算精度上,两组算例改进算法都可以更加接近最低成本在运算20次后,计算平均成本和标准差。结果见表5。

表5 算法改进前后结果对比
根据表5结果通过多次实验的可以证实,改进的免疫遗传算法对这一模型的计算结果的精度明显提高。相对算例1,算例2的数据量增加后,改进后算法的效果相对传统的免疫遗传算法的提升更加明显。
5 结论
本文提出了全新的容量限制的选址模型并采用改进的免疫遗传算法进行优化。首先,论文针对工厂选址初期的需求问题,提出了分段式的生产规模选址模型;然后,结合选址模型对免疫遗传算法进行改进建立了对应的容量限制选址优化模型;最后,使用MATLAB编程分别对两组数据进行验证方法的有效性。通过数据结果可以看出:改进的模型和算法可以有效地降低成本的同时满足需求,更贴近实际生产情况,并且改进的算法还提高模型计算的运行速度。为了深入的研究容量限制选址问题,接下来将分析有不确定需求等因素的容量限制的选址问题,并进行对其进行深入的研究。
