HEVC整像素运动估计的并行螺旋搜索算法及其硬件实现
2022-01-21张志勇施隆照杨小玲罗隆
张志勇,施隆照,杨小玲,罗隆
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
随着人们对视频质量的更高要求,视频分辨率逐渐提升,从以前的720 px×1 280 px、1 080 px×1 920 px发展至现在的2 K、4 K甚至是8 K.然而在提升视频清晰度的同时,视频码流也成倍增加,上一代视频编码标准H.264的压缩效率很难满足4 K、8 K视频的实时编码要求.HEVC视频编码标准在H.264/AVC的基础上,新增了一套特殊的图像分割模式,包括对编码单元(coding unit,CU)、预测单元(prediction unit, PU)、变换单元(transform unit, TU)的模式划分,HEVC编码视频在同等峰值信噪比(peak signal to noise ratio, PSNR)的条件下码流相比H.264可节省50%[1].HEVC在编码效率上的出色表现得益于其拥有先进的编码结构和各种先进技术,但是这也使得HEVC在编码时间上远远超过了H.264编码标准.新的编码结构和更多不同尺寸的预测单元允许编码单元有更多样的划分方式,这增加了运动估计的复杂度.在视频编码过程中,帧间预测占据整个编码复杂度的80%[2-3],而这其中尤属运动估计的编码时间最高,大约是整个帧间预测的70%[3].因此,针对如何减少运动估计编码时间、缩短硬件加速运动估计过程的研究是非常有必要的.
目前已有许多算法来研究减少整像素运动估计编码时间的方法,并且达到了很好的加速效果.文[4-10]采用散点搜索方式,通过减少搜索点数来达到加速运动估计的效果,称之为快速搜索算法.快速搜索算法一般以钻石搜索(DS)[4]或者增强的预测性区域搜索(EPZS)[8]为基础,先对起点周围像素点进行匹配得到当前最佳匹配点(P点)后,再以P点为起点搜索周围的像素点,逐步逼近最佳点.快速搜索算法可以节省大量的编码时间,但是这类算法得到的最佳点容易陷入局部最优点.另外,采用散点搜索方式逐步逼近最佳点的办法需要根据上一步(或上一层)搜索结果来确定下一步(或下一层)的起点位置,相邻步骤间紧密的依赖关系不利于硬件上流水线设计,且无规律的搜索点为像素数据获取带来不便.
针对上述问题,前人提出了许多面向硬件设计的运动估计算法.文献[11-12]提出快速全搜索算法,在全搜索算法的基础上添加提前结束判断,跳过不必要的搜索点达到节省编码时间的目的.但是快速全搜索算法节省的编码时间十分有限,相比全搜索算法仅减少30%~40%[11-12]的计算复杂度.文献[13]提出一种中心自适应搜索算法,结合快速中心搜索算法(FCSA)和自适应搜索窗口算法(ASWA),从中心点利用块匹配方法进行搜索,采用提前终止标准和自适应搜索窗口范围来减少搜索点,达到缩减时间的目的.中心自适应搜索算法适用于运动缓慢的视频序列,但是对于运动剧烈的视频序列表现不佳,复杂度较高.文献[14]提出一种面向硬件的并行聚集树(PCTS)算法,并行处理具有相同运动矢量(motion vector,MV)的不同PU单元组,共享搜索过程,以此来节省搜索时间.但是不同组的类别个数未知,硬件上需要预留内存,造成空间浪费.
本研究采用并行螺旋搜索算法,该算法以固定的螺旋搜索遍历搜索框内的搜索点,在每个搜索点处并行处理所有PU块,再结合提前终止机制减少不必要的搜索点,以此减少搜索时间.提出一种基于并行螺旋搜索算法的硬件架构,通过并行处理所有PU块和提前终止机制来降低计算复杂度,同时硬件上复用4次32 px×32 px计算单元来处理一个64 px×64 px的树形编码单元(coding tree unit, CTU),有效控制硬件资源的增加,能够很好地平衡计算复杂度和资源硬件.
1 算法概述
1.1 螺旋搜索
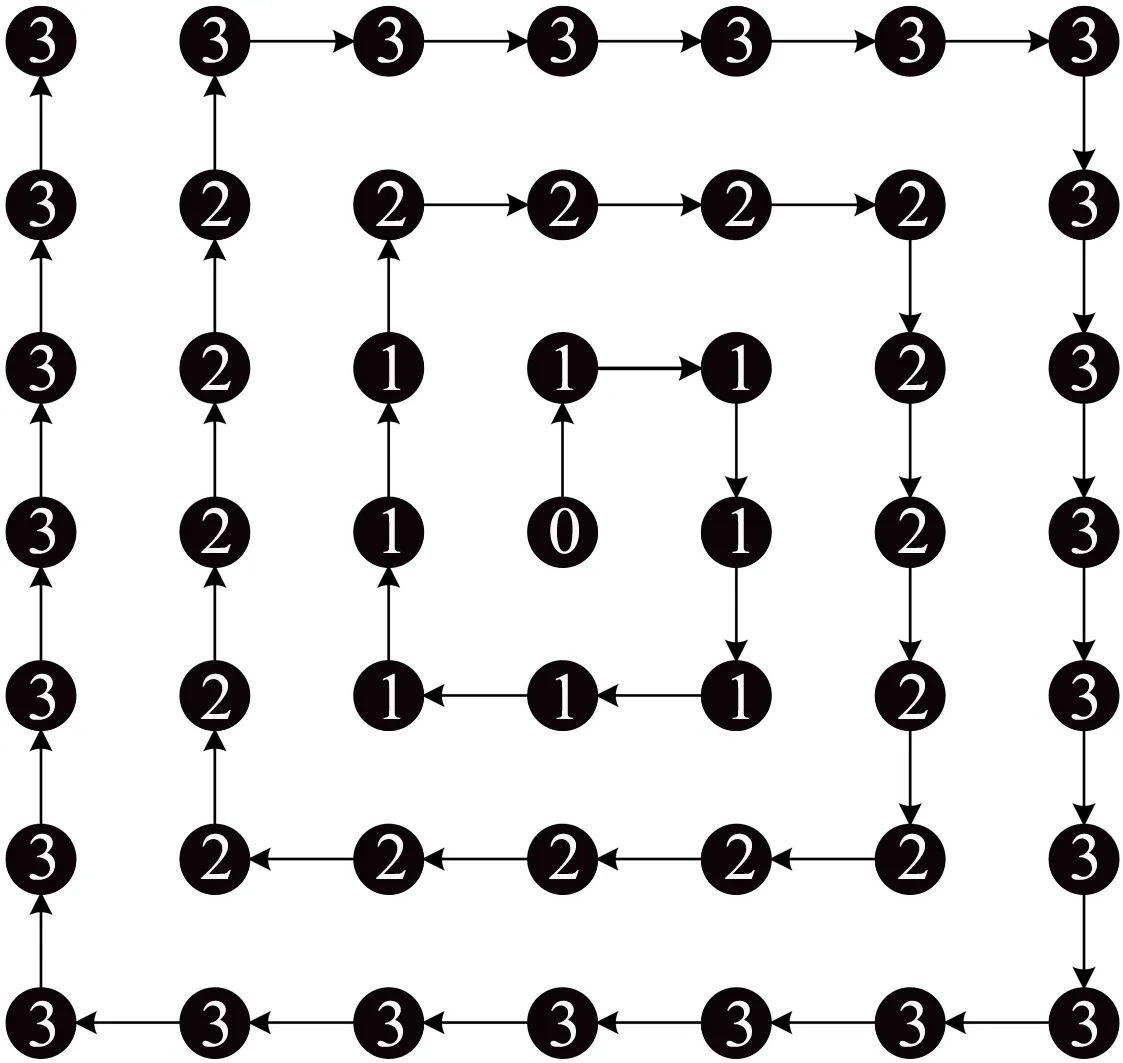
图1 螺旋搜索顺序Fig.1 Spiral search order
根据文献[4, 15]可知,在视频序列中MV是基于中心分布的,即距离中心点越近,出现最佳匹配点的概率越大,而在搜索框边缘则概率明显要小得多.另外在硬件设计中,相比无规律的散点搜索,具有固定搜索顺序的搜索方式在数据获取以及流水线设计方面都更有优势.
采用的螺旋搜索是从搜索起点开始,按照固定的螺旋搜索顺序由内向外顺时针遍历整个搜索框.如图1所示,其中“0”点表示搜索起始点.为了标识每一搜索点到搜索起始点的距离,该算法借用“圈”的概念,即以起始点为中心,按照由内往外的顺序画方形圈.其中, “1”“2”“3”标识该搜索点所在圈.
采用有规律的螺旋顺序相比无规律的快速搜索模式更有利于硬件设计;对于全搜索的光栅顺序,采用的螺旋顺序从最佳MV出现概率较高的中心点开始,向概率较低的搜索框边缘进行搜索,结合提前终止机制,能够在保持视频质量的同时,有效减少搜索点数.
1.2 并行螺旋搜索算法流程
HM使用迭代方式遍历CTU内的所有PU块,即在编码当前CU后对该CU的第一个子CU(sub_CU)进行编码,而在sub_CU编码结束后进一步对sub_CU的第一个子CU块进行编码;以此类推,直到CU不再划分后编码同层其余子CU.这种迭代方式普遍运用于各种快速搜索模式,如DS、TZS等,但迭代方式周期长、CU深度频繁切换的特点使其更不适用于硬件设计.采用更有利于硬件实现的并行螺旋搜索算法,该算法采用螺旋搜索方式遍历搜索框内的搜索点,对每个搜索点并行处理CTU内的425个PU块(不包括非对称模式下的PU块),再利用提前中止策略结束对不必要搜索点的搜索,缩减搜索时间.

图2 并行螺旋搜索流程图Fig.2 Flow chart of the PSS algorithm
算法流程图如图2所示,为实现并行处理所有PU块的目的,将CTU中最大尺寸CU(LCU)的预测运动矢量(motion vector prediction, MVP)作为CTU内的425个PU块的MVP.在获取当前待编码CTU块和参考帧后,以LCU为对象利用高级运动矢量预测技术(advanced motion vector prediction, AMVP)得到所有PU块的MVP.考虑到众多PU块的实际MVP并非绝对统一,且可能存在反方向的情况,故将该向量进行预设比例的缩小后才当作统一预测运动矢量(unified motion vector prediction, UMVP).
运动估计是以UMVP所指向的终点作为搜索起始点,搜索框则以搜索起始点为中心,向上下左右各延伸64点.采用的率失真代价计算公式如下式所示:
J=Distortion+λ×R
(1)
式(1): Distortion通常用绝对误差和(sum of absolute difference, SAD)表示;λ为拉格朗日因子;R是当前MV与MVP的运动矢量差值(motion vector difference, MVD)的编码比特数.其中SAD的计算公式如下:
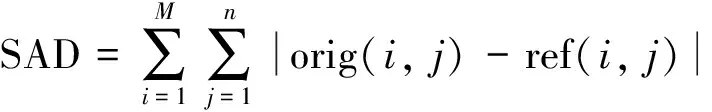
(2)
运动估计根据原始块和参考块像素数据,计算出当前点处CTU的残差;再利用CTU的残差算出每个4 px×4 px单元块的绝对残差和(SAD)并保留下来,用于合成425个不同PU块的SAD,以避免重复计算各个PU块残差,消除计算冗余.每个PU块的SAD再加上当前MVD所需的编码比特数,即为PU块的代价J.同时将这些PU块代价与先前最佳点的相应PU块代价进行比较,更新425个PU块的当前最佳MV和相应代价.
本研究的提前中止策略如下: 当搜索点在N圈内时,判断当前搜索点所在圈数与最佳点所在圈数的差值,如果二者相差大于M则提前中止搜索,否则继续搜索;当搜索点在N圈外时,判断当前搜索点所在圈数与最佳点所在圈数的差值,如果二者相差大于1圈的距离则提前中止搜索,否则继续搜索.
由1.1小节可知,并行螺旋搜索算法是按照由中心向四周的搜索顺序进行的,且最佳匹配点落在搜索框边缘的概率要小于中心区域.因此,引入提前终止机制能够在保证性能损失不大的前提下,有效减少搜索框边缘不必要的搜索点,达到降低计算复杂度的目的.
1.3 算法性能测试结果
该算法基于参考软件HM16.7版本的基础上进行修改,测试环境是在64位Window Server 2016操作系统多用户共同使用的服务器下进行测试,其中处理器为Inter(R)Xeon (R) Gold 5122 CPU @3.59 GHz,内存128 GB.算法性能结果与其他算法对比如表1所示:

表1 本研究性能结果与其他IME算法对比
选用多个不同剧烈程度的视频序列进行测试,性能指标分别从峰值信噪比(PSNR),比特率(BR,BDBR[18])以及算法复杂度(T)等多个方面与其他文献进行比较;量化参数选择22,27,32和37,视频编码50帧,配置文件选择lowdelay_P;从表1中可以看到,本研究算法相比同类型其他算法在各项指标上都有明显改进.相比文[17]中提到两种算法,其编码时间增加量为6.14%和14.48%,而该算法在计算复杂度上仅增加0.86%的编码时间;在比特率方面,其他文献中表现较好的是文献[16]和文献[14]中数据,Bit Rate增加量分别为2.2%和1.9%,而本研究算法仅增加1.105%与1.51%.因此,证明了并行螺旋搜索算法在性能方面的有效性.
2 基于并行螺旋搜索算法的IME硬件架构
本研究提出的整像素运动估计硬件框架主要可分为两个部分: IME控制部分与代价计算部分.其中: IME控制部分包括运动矢量生成模块和提前中止判断;代价计算部分包括像素地址生成模块、像素数据缓存、残差计算、SAD计算和代价比较模块等.IME硬件关系如图3所示:
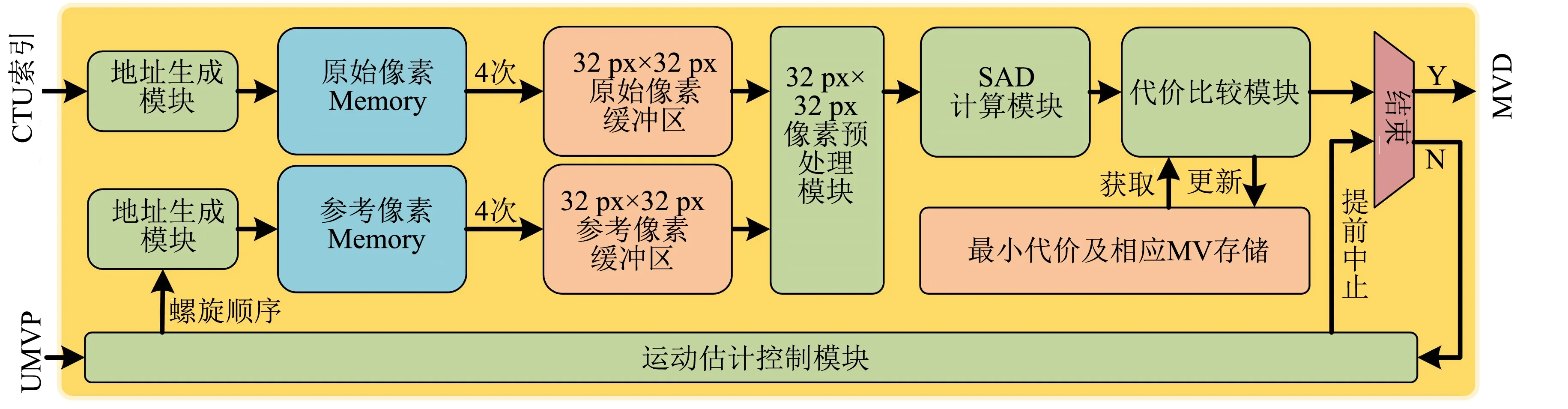
图3 IME硬件关系图Fig.3 IME hardware relationship diagram
2.1 IME控制模块
IME控制模块完成以螺旋顺序逐个生成MV坐标的时序控制逻辑功能,而在计算单元的流水线中每四个时钟周期更换一个CTU的处理,因此要求IME控制模块每隔四个时钟周期更新一次MV坐标,即采用4分频时钟.
规定搜索顺序是从中心向四周按顺时针方向逐点展开,如图4所示.将搜索点按照“上右下左”为一个单位分层,每层中“上”和“右”方向上前进步数相同,“下”和“左”方向上前进步数相同,且 “下左”方向上的步数总是比同层中的“上右”多一步,比下一层的“上右”少一步.假设S是步数,C是层数,则每一层方向上前进的步数公式如以下两式所示:
S上=S右=2×C-1
(3)
S下=S左=2×C
(4)
硬件上采用有限状态机对IME螺旋搜索部分进行控制,一共分为五个状态,分别是空闲状态(IDLE)、向上状态(UP)、向右状态(RIGHT)、向下状态(DOWN)和向左状态(LEFT);图5表示的是IME控制模块的状态转移图,在IME未启动前处于IDLE空闲状态,当外部上层模块给IME模块一个启动信号后,开始IME过程且状态切换为UP状态,当步数计满后切换成RIGHT状态,按照“上右下左”的顺序依次类推;在提前中止发生时结束螺旋搜索,且任何状态都需要切换到IDLE状态;当不发生提前结束,则在最后一层的LEFT状态步数计满后结束IME过程,且状态切换到IDLE状态.

图4 “上右下左”方向上的点数规律Fig.4 The rule about the number of points in“up, right, bottom, left”

图5 IME控制模块状态转移图Fig.5 State transition diagram of IME control
2.2 代价计算模块
不同于以迭代方式逐个计算CTU内的每一PU块,该设计采用并行方式计算各层PU块的代价,即在获取每个搜索点后,计算出该点处0层(64 px×64 px)至3层(8 px×8 px)所有PU块的代价,再对各PU块进行比较和替换最小代价,直至达到提前结束条件或者搜索框边界.为了减少硬件资源开销,代价计算模块设计成32 px×32 px的代价计算模块,每个64 px×64 px CTU分4次复用32 px×32 px的代价计算模块来计算代价.在获取原始像素和参考像素地址后,像素数据分4个时钟周期读入数据缓冲区,32px×32px像素矩阵的参考像素和原始像素相减得到32 px×32 px大小的残差矩阵.
将残差矩阵送到SAD计算模块,以4个数相加做一级流水,先由4个残差相加得到2 px×2 px大小的SAD,再由4个2 px×2 px SAD相加得到4 px×4 px 的SAD,依次类推得到32 px×32 px的SAD,如图6所示;64 px×64 px的SAD需要等4个32 px×32 px的 SAD获得后再进行相加得到.由于所有PU块都在同一个搜索点处进行处理的,因此具有相同的头比特数,各PU块代价只需要将各自的SAD加上相同的头比特数即可.运动估计需要保留每个PU块的最小代价,进行后续的PU模式选择和CU模式选择,在比较模块中将当前PU块的代价与最小PU代价进行比较,选择出最小代价.

图6 代价计算和比较模块硬件框架Fig.6 Hardware frameworkof cost calculation and comparison module
2.3 流水线设计
采用复用4次32 px×32 px的代价计算模块来处理一个64 px×64 px的CTU,即需要每4个时钟处理一个CTU.32px×32px代价计算模块采用8级流水线设计,其中数据读取和残差计算各占一个时钟,SAD计算需要5个时钟,后面32 px×32 px比较模块需要占用一个时钟,如图7所示.另外,同层的PU块同时进行代价计算和比较,例如PU 8 px×4 px、4 px×8 px的SAD计算和8 px×8 px是同时进行的,都是由4 px×4 px的SAD相加得到;PU 8 px×4 px、4 px×8 px和8 px×8 px的比较模块则是在代价计算后的下一个时钟开始进行,因此需要多一个时钟进行32 px×32 px的最小代价比较.
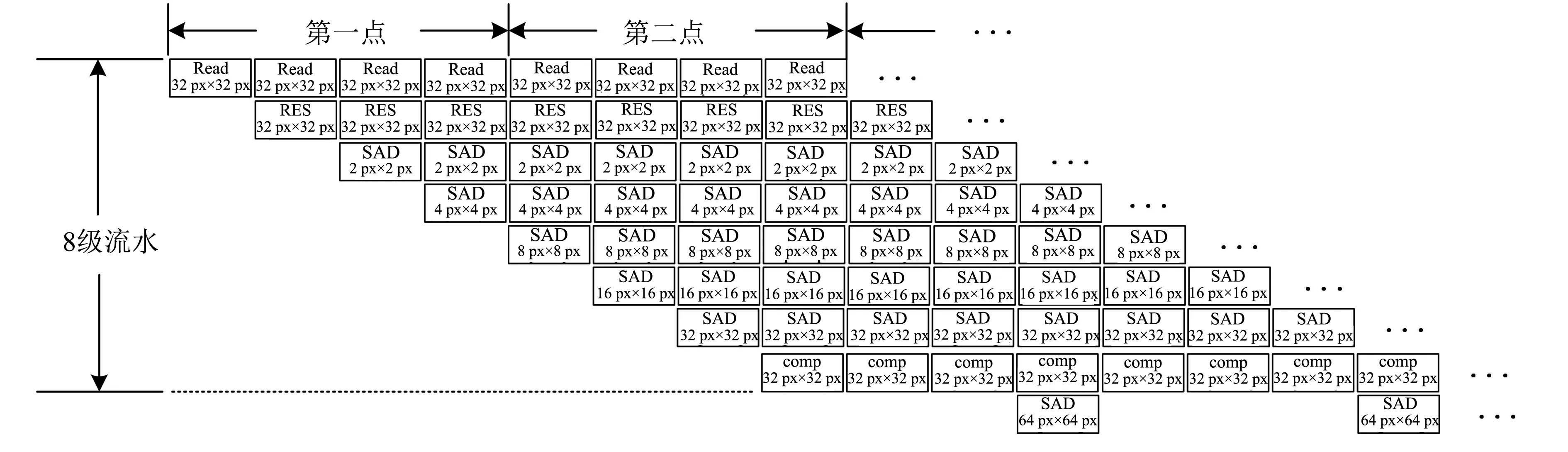
图7 流水线设计框图Fig.7 Block diagram of pipeline design
本研究设计引入提前中止来减少IME的时钟数,因此完整的整像素运动估计周期与视频序列的剧烈程度直接相关,视频内容越剧烈,消耗的时钟数越多.为了能够较为准确地反映IME周期数,对不同序列处理一个CTU的时钟数进行统计,如表2所示,平均时钟数为1 733.4个时钟.

表2 不同序列处理一个CTU的时钟数统计
3 硬件框架综合结果及同其他文献比较
设计采用Verilog语言进行硬件描述,使用Synopsys VCS工具进行功能仿真.提前中止参数配置为n=10,M=2,并将HM的数据结果读入测试文件中,在测试文件中与硬件仿真结果进行比对,验证结果正确性.在XILINX出品的VIVADO 2017开发平台中进行综合,使用Virtex-7系列XC7VX550TFFG1927-1 型号的FPGA器件.最终综合结果表明,完成CTU为64 px×64 px 的IME螺旋搜索,该设计需要35 524个LUT,61 115个触发器(Flip-Flops),memory占用32 kB,最高工作频率为198 MHz.
本研究综合结果与其他IME硬件框架的比较情况如表3所示.文[14]提出的并行聚集树搜索方式是在下采样后的搜索框中进行第一步精度为8 px的搜索,共享所有PU块的搜索过程;而后将具有相同MV的PU块分为同一组,同组PU共享第二步精度为4 px的搜索过程;依次类推,直至得到每个PU块获得精度为1 px的搜索结果.文[14]提出的算法性能上仅比标准HM增加1.9%的BD-Rate,且很大程度并行处理多个PU块,节省了大量的计算周期;但是分层搜索的策略需要等上一步搜索结束后才能进行第二步搜索,不利于流水线设计,且第二步后不同MV的PU块并不能共享搜索过程,这些因素钳制了文[14]周期数的最低值.
文[19]提出一种蛇形搜索方式,按照从左往右以蛇形形态进行搜索;在每个搜索点处利用小块SAD相加获得大块SAD的方式,一次性获取64 px×64 px的 CTU内所有PU块的SAD.蛇形搜索有“上、下、右”三个运动方向,逐点搜索具有很高的数据重复率,文[19]利用移位寄存器每次仅新增一行或是一列数据即可更新完参考像素,硬件上便利了数据的获取.但是,文[19]采用全搜索方式遍历整个搜索框,计算复杂度高,并且其SAD加法树结构未做复用处理,导致硬件资源消耗大.
文[20]是基于文[21]提出的非对称菱形搜索算法,在其基础上进行的硬件实现.文[20]将64 px×64 px分为16个64 px×4 px分片,且16片并行计算;而后将每片得到的16个4 px×4 px的SAD传给加法树结构,在加法树结构中相加合成其他PU块的SAD.但文[20]为了减少周期数,在SAD加法模块运用大量组合逻辑,造成较大的组合延迟,导致主频较低,只有122.5 MHz.
文[22]根据CTU的图像内容特性进行CTU的深度决策,将CTU分为纹理简单和纹理复杂两类,分别进行深度为{0, 1, 2}和{1, 2, 3}的IME;同时将原始参考像素的搜索框进行4∶1和16∶1两种级别的下采样,对于决策深度为{0, 1, 2}的CTU进行16∶1、4∶1和1∶1三级IME,而深度为{1, 2, 3}的CTU仅进行4∶1和1∶1两级IME.文[22]在16∶1级别上进行16路并行的方式进行IME,减少了运动估计的周期数,但同时也使得LUT资源消耗较大,占用高达180 K的LUT资源.

表3 与其他硬件架构比较情况

4 结语
高效视频编码标准HEVC相比H.264能够减少一半的码率,同时也带来了大量的计算复杂度.整像素运动估计是HEVC中复杂度较高的部分,前人大多基于算法层面提出很多方案来减少IME的复杂度,但硬件上却难以实现.本研究从硬件实现的角度出发提出一种基于并行螺旋搜索算法的整像素运动估计算法,并基于水流线设计方案设计了并行螺旋搜索算法的硬件架构,从IME控制模块、代价计算模块和流水线设计等方面进行了详细介绍;最后,将本研究硬件框架和同类型的其他文献进行比较.相比其他文献,本研究在保证算法性能损失较小的基础上,能够很好地平衡硬件资源和工作频率,198 MHz工作时钟下可达到4 K@56.4 f·s-1的吞吐率.
