动态场景下基于深度学习的语义视觉SLAM
2022-01-21阮晓钢郭佩远
阮晓钢, 郭佩远, 黄 静
(1.北京工业大学信息学部, 北京 100124; 2.计算智能与智能系统北京市重点实验室, 北京 100124)
同时定位与地图构建(simultaneous localization and mapping, SLAM)是指机器人在没有环境先验信息的情况下仅通过自身携带的传感器估计自身位姿并构建环境地图的过程[1],它是许多机器人应用的先决条件,例如自主导航[2]、路径规划[3]等. 视觉SLAM是指以视觉传感器为主要数据采集传感器的定位建图方法,它是各种上层应用的必要模块,例如室内服务机器人[4]、室外自动驾驶汽车[5]等. 在过去的几十年里,视觉SLAM问题受到了高度的关注,一些先进的视觉SLAM算法已经取得了令人满意的性能. 例如:基于关键帧的并行跟踪与地图构建(parallel tracking and mapping,PTAM)[6]使用非线性优化方法比滤波方法更高效,它曾被认为是单目SLAM算法的标准算法; ORB-SLAM2[7]是一个集成了单目、双目、深度相机的综合系统,具有追踪、局部建图、闭环检测3个线程,可构建稀疏的点云地图,是视觉SLAM系统中采用特征点法的代表; LSD-SLAM[8]则采用直接法提高位姿估计的准确性并能构建大规模的三维地图.
然而,大多数现有的视觉SLAM算法基于静态环境假设,在动态环境下精度低、鲁棒性差,并且它们建立的地图通常基于几何信息,如基于地标的地图和点云地图,因此,无法提供对周围环境的高级理解. 为了解决这一问题,很多学者提出了面向动态环境的SLAM方法,根据场景中动态特征的检测方法可以将其分成两大类:仅依赖于几何信息的动态特征检测和仅依赖于语义信息的动态特征检测.
在依赖几何信息的方法中,Kundu等[9]通过构造基础矩阵来定义几何约束,如果后续帧中的匹配特征距离极线很远,则被认为是动态的. Zou等[10]通过分析三角测量一致性,将前一帧的特征投影到当前帧,并计算特征跟踪的重投影误差,如果误差很大,则地图点被认为是动态的,从而将每一帧地图点分类为静态或者动态. Wang等[11]通过将深度图像聚类成若干对象,提取当前彩色图像特征,统计每个对象上的特征数量和百分比,并基于统计特征设计了一个运动目标判别模型,如果目标被认为是运动的,则该模型上的所有特征被消除. 这些方法无法建立动态对象的先验语义信息,不能提供对周围环境中动态对象的高级理解,从而导致系统在动态环境中的精度不佳.
在依赖语义信息的方法中,往往根据人的经验和尝试将可以自己移动的对象视为动态物体. Zhong等[12]使用单次多框检测器(single shot multibox detector,SSD)来检测移动对象,将人、猫、狗、汽车等视为潜在移动物体,将属于这些区域的所有特征去除. Zhang等[13]使用YOLO(you only look once)目标检测网络来获取语义信息,去除移动对象上的不稳定特征. 这些方法仅依赖语义信息不能完全去除动态特征点. 一方面,目标检测或语义分割在对象边界附近的分割结果模糊,仍不可避免;另一方面,不能有效去除潜在动态对象上的不稳定特征点. DS-SLAM[14]将SegNet语义分割网络与光流法相结合并构建八叉树语义地图. DynaSLAM[15]将Mask R-CNN[16]实例分割网络与多视图几何相结合并在没有动态对象的情况下完成背景修复. 这些方法没用利用语义信息来辅助对极几何计算,只是简单地组合两者的结果.
本文提出了一种将语义分割技术与运动一致性检测算法相结合的方法,共同利用语义分割的先验信息和几何信息来去除物体动态特征,减小SLAM在位姿估计中产生的误差. 实验结果证明,该方法在动态环境中明显降低了绝对轨迹误差和相对位姿误差,提高了系统位姿估计的准确性和鲁棒性.
1 系统框架
系统在ORB-SLAM2[7]原有框架的基础上,对其中的视觉里程计进行改进,通过增加语义分割线程并在跟踪线程增加运动一致性检测算法进行动态物体检测来减少动态特征点对视觉里程计的干扰. 改进后的系统流程框图如图1所示. 该系统包含4个并行运行线程:跟踪、语义分割、局部地图、闭环检测. 当原始彩色图像抵达后,同时传入语义分割线程和跟踪线程,两者并行地对图像进行处理. 语义分割线程采用Mask R-CNN[16]网络将物体分为动态对象和静态对象,把动态对象的像素级语义标签提供给跟踪线程,并通过几何约束的运动一致性检测算法进一步检测潜在动态特征点异常值,然后剔除动态对象中的特征点并利用相对稳定的静态特征点进行位姿估计.

图1 系统流程图Fig.1 System flow diagram
1.1 基于Mask R-CNN的语义分割
针对动态场景中视觉SLAM存在的问题,提出一种先进的深度学习方法来检测动态对象,使用语义分割网络对动态对象进行分割,获得动态对象的像素级语义分割作为语义先验知识. 模型中采用了Mask R-CNN[16],它是对象实例分割的最新技术. Mask R-CNN既可以获得像素级的语义标签,又可以获得实例标签. 本文仅使用像素级语义标签,而实例标签在未来跟踪不同的运动对象工作中是有用的.
Mask R-CNN将Faster R-CNN[17]目标检测框架扩展为实例分割框架. Mask R-CNN将分类预测和掩码预测作为网络的2个分支. 分类预测分支通过扫描图像对感兴趣区域给出预测,并产生类别标签,输出矩形框坐标;掩码预测分支依赖分割预测结果,利用全卷积神经网络对每个感兴趣区域预测二值分割掩膜,生成语义信息. 利用Mask R-CNN网络获取的像素级语义标签,可以得到其运动特征的先验信息. 例如,如果像素的标签是“人”,可以假设这个像素是动态的置信度高,因为按照人们的常识,人倾向于移动;如果标签是“桌子”,则假设这个像素是静态的置信度高;如果标签是“椅子”,则不能假设这个像素是静态的置信度高,因为椅子本身不能移动,但在人的活动下,它是可以移动的,所以认为这种对象上的像素是潜在动态的.
为了对室内环境进行语义分割,本文使用TensorFlow框架下的Mask R-CNN网络,该网络的预训练模型是在MS COCO[18]数据集进行的完全训练,具有很高的识别与分割效果. MS COCO数据集包含80多种不同的物体类别,所需的类别可以分为2种:一种是动态置信度高的移动对象,选择MS COCO数据集中的20个物体类别(人、自行车、汽车、摩托车、飞机、公共汽车、火车、卡车、船、鸟、猫、狗、马、羊、牛、大象、熊、斑马、长颈鹿和飞盘),对于大多数环境,可能出现的动态对象都包含在这个列表中;另一种是可能伴随人一起移动的潜在动态对象,如椅子、书、杯子等. 如果需要其他类别,可以用新的训练数据对网络进行微调. 经过预训练之后的神经网络又采用慕尼黑工业大学(Technical University of Munich,TUM)室内数据集进行第2次训练,可以避免重新训练花费大量的时间、采集大量的图片数据,同时也能够得到更加稳健的效果. 为了减轻网络的权重,基础网络采用Res-Net50结构,因为已经预训练,所以当第2次训练时从第4层对权重进行修改. 实例数量设定为数据集中常见对象或潜在动态对象,共6种,并对它们进行颜色标记. 人、椅子、书、杯子、显示器、键盘分别设置为黑色、黄色、蓝色、绿色、紫色、红色.
在本研究中,Mask R-CNN网络的输入为m×n×3的彩色图像,Mask R-CNN网络的输出为m×n×l的矩阵,其中l为图像中物体的数量. 对于每个输出通道i∈l,将获得一个二进制掩码,矩阵中只有1和0两个数字,数字1对应静态场景,数字0对应动态场景. 通过将所有的输出通道合并成一个通道,可以获得出现在一个场景图像中的所有动态对象的分割.
1.2 运动一致性检测
通过Mask R-CNN网络,大多数动态对象可以被分割. 但是,潜在动态的移动对象的分割效果并不理想,例如人携带的书或者连同人一起运动的椅子. 为了解决这个问题,本文利用对极几何特性的几何约束进一步检查特征是否是动态特征. 如果是动态特征,则会满足对极约束;反之则不然. 其原理如下.
2个连续帧中图像点之间的关系如图2(a)所示.P是空间点,在连续2帧图像I1、I2中分别得到特征点P1、P2.O1和O2分别是I1和I2相机的光学中心,连接O1和O2的线称为基线.基线和点P确定了一个平面π,称为对极平面.平面π与平面I1、I2的相交线l1、l2被称为极线.基线与图像平面的交点E1、E2称为对极点.特征点P1、P2的齐次坐标可以表示为
P1=[u1,v1, 1],P2=[u2,v2, 1]
(1)
式中,ui、vi(i=1,2)为Pi(i=1,2)的横、纵坐标.极线l1可以通过
(2)
计算.式中F为基础矩阵,对极约束描述了从一幅图像中的一个点到另一幅图像中的对应极线的映射,映射关系可以通过
(3)
描述.
在已知I1中的点P1和基础矩阵F的情况下,如果P是静态点,则P2一定满足式(3)约束.但是,由于特征提取和基础矩阵F估计中的不确定性,从而产生位于极线附近具有误差的特征点,空间点映射的2个图像点则不严格满足式(3).如图2(b)所示,点P2并不完全位于极线上,而是非常靠近它.因此,点P2到极线l2之间的距离D可以通过

图2 对极几何约束Fig.2 Epipolar geometry
(4)
计算.如果D小于预定阈值,则点P被认为是静态的,否则被认为是动态的.
运动一致性检测算法流程如图3所示.使用对极几何约束检测动态特征,首先根据前一帧特征点集合L1,利用光流法计算当前帧中匹配的特征点集合L2.如果匹配对太靠近图像的边缘,或者匹配对中心的3×3图像块的像素差太大,则匹配对将被丢弃.然后,可以用至少5对特征估计基础矩阵F,通常使用经典的八点法,再使用基础矩阵F计算当前帧中的极线.最后,通过计算P2到P1对应极线的距离与预定阈值的关系来判断特征点是否移动.

图3 运动一致性检测算法Fig.3 Moving consistency check algorithm
2 实验结果
本文进行2个实验:第1个实验利用Mask R-CNN网络对相邻2帧图像的动态对象进行语义分割,获取像素级语义标签,在动态对象上覆盖掩膜以达到剔除动态特征点的目的;第2个实验在TUM公共数据集上运行改进后的系统,并与传统ORB-SLAM2系统和DS-SLAM系统进行比较,通过评估系统的误差以验证本文系统的位姿估计具有更好的准确性和鲁棒性.
为评价系统的综合能力,采用TUM[19]公开数据集对系统进行实验. TUM数据集由39个序列所组成,这些序列由微软公司的Kinect传感器以30 Hz频率记录在不同的室内场景中,包含彩色图像、深度图像和位姿真值,并且包含纹理丰富的办公室动态场景的高动态序列和低动态序列,满足在动态场景下评估系统综合能力的条件.
同时,该数据集还提供了2种用于评估SLAM系统跟踪结果的标准,分别为绝对轨迹误差和相对位姿误差[20]. 绝对轨迹误差直接计算相机位姿的真实值与SLAM系统的估计值之间的差,该标准可以非常直观地反映算法精度和轨迹全局一致性,第i帧的绝对轨迹误差定义为
(5)
式中:Ti为第i帧的算法估计位姿;Qi为第i帧的真实位姿;S为从估计位姿到真实位姿的转换矩阵.相对位姿误差则是计算真实位姿与估计位姿每隔一段相同时间Δ内位姿变化量的差,该标准有利于评估平移和旋转漂移,第i帧的相对位姿误差定义为
(6)
本实验在上述数据集分别运行传统的ORB-SLAM2和改进后的系统,实验的电脑配置为CPU i5- 4200H,GPU GTX 960M 4G.
2.1 实验1
本实验在数据集中随机选取相邻2帧图像,图像中包含动态对象“人”,图4(a)(b)(c)显示了传统的ORB-SLAM2系统会提取动态对象“人”身上的特征点,并利用这些动态特征点进行特征匹配和位姿估计,从而造成该系统在动态场景下鲁棒性差、位姿估计准确率低. 图4(d)(e)(f)显示了利用Mask R-CNN获取像素的语义标签“人”,并在动态对象“人”上覆盖掩膜,改进后的系统将掩膜上的动态特征点有效地剔除,在之后的位姿估计过程中忽略了这些动态特征点,达到了剔除目的.

图4 传统ORB-SLAM2系统和改进后的系统中特征提取和匹配结果Fig.4 Feature extraction and matching results in traditional ORB-SLAM2 system and improved system
2.2 实验2
本实验将本文系统与ORB-SLAM2系统和DS-SLAM系统进行对比,采用绝对轨迹误差和相对位姿误差进行定量评估. 本实验主要采用TUM数据集中的行走序列,因为有人在行走序列中来回移动,序列中的人可以被视为高动态对象. 本实验也对坐姿序列进行了测试,序列中的人坐在椅子上只稍微移动从而被视为低动态对象. xyz、static、rpy和half代表4种类型的摄像机自运动. 本文给出了均方根误差(root mean square error,RMSE)、均值误差、中值误差、标准差、最大值误差和最小值误差,其中RMSE和标准差能够更好地反映系统的稳定性和鲁棒性. 误差的改进值通过
(7)
计算.式中:η为改进值;o为ORB-SLAM2系统的运行结果;r为本文提出方法的运行结果.
图5、6分别显示了在高动态序列fr3_walking_xyz中从ORB-SLAM2和本文系统中选择的相对位姿误差图和绝对轨迹误差图. 可以看出,本文系统的绝对轨迹误差和相对位姿误差均显著小于ORB-SLAM2,从而验证了本文基于Mask R-CNN的语义分割和运动一致性检测算法去除动态对象的语义视觉SLAM在动态场景下较传统基于静态环境假设的ORB-SLAM2拥有更好的性能.

图5 相对位姿误差Fig.5 Relative pose error
表1、2显示了误差的定量评估,可以看出,DS-SLAM在绝大多数误差指标上均大于本文系统,这是由于DS-SLAM没用利用语义信息来辅助对极几何计算,只是简单地组合两者的结果,而本文系统共同利用语义分割的先验信息和几何信息来去除物体动态特征,以减小SLAM在位姿估计中产生的误差,故本文系统较ORB-SLAM2和DS-SLAM的鲁棒性和稳定性显著提升.

图6 绝对轨迹误差Fig.6 Absolute trajectory error

表1 相对位姿误差的代表值

表2 绝对轨迹误差的代表值
表3~5面向更多动态序列均显示出显著改进. 在高动态序列中,例如fr3_walking_static序列,RMSE和标准差误差的改进值可分别达到96.93%和98.16%,很好地反映了本文系统的稳定性和鲁棒性有了显著提升. 然而,fr3_walking_rpy序列性能改善欠佳,这是由于该序列中相机的运动形式为在翻滚、俯仰和偏航轴上转动,系统运行过程中容易发生跟踪丢失的情况,在相机重定位的过程中产生较大误差. 同样,在低动态序列中,例如fr3_sitting_static序列,性能的改善并不明显. 这是由于传统的ORB-SLAM2系统能够轻松处理低动态场景并获得良好的性能,因此,可以提升的空间有限.

表3 平移漂移结果

表4 旋转漂移结果
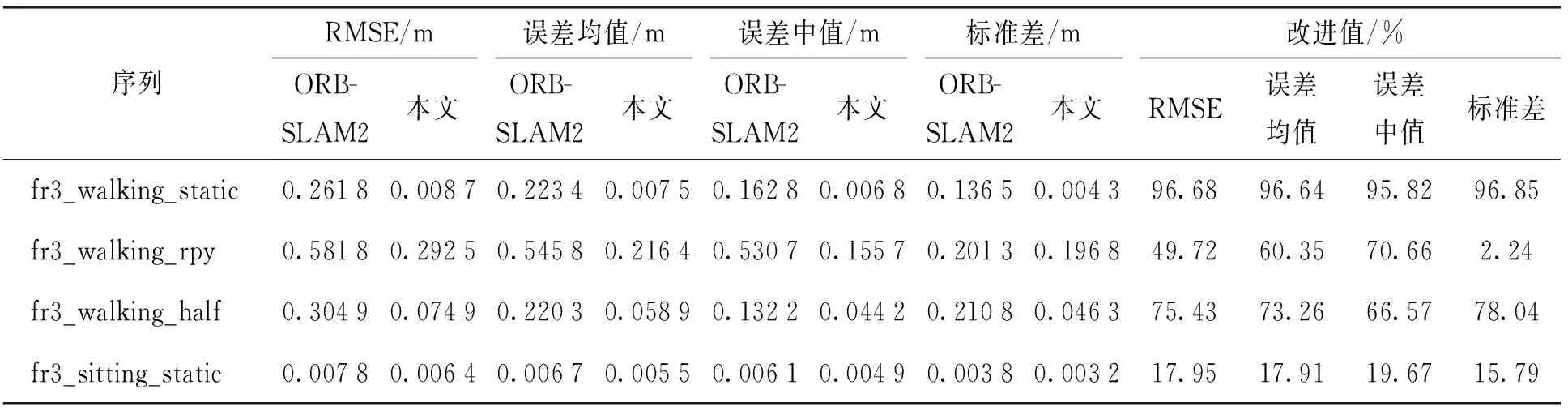
表5 绝对轨迹误差结果
3 结论
1) 相对于传统ORB-SLAM2视觉SLAM系统,通过引入Mask R-CNN网络检测潜在动态对象,获取语义先验知识以提供对环境的高级理解.
2) 将运动一致性检测算法与语义分割算法相结合,使得改进的系统较传统ORB-SLAM2和动态环境下的DS-SLAM在绝对轨迹误差和相对位姿误差方面显著减少,提升了系统位姿估计的准确性和鲁棒性.
3) 未来工作中,将更好地结合Mask R-CNN获得的实例标签来跟踪不同的运动对象,并通过优化运动一致性检测算法来提高系统性能.
