基于BERT的唐卡文本分类研究
2022-01-21王昱
王昱
(西北民族大学数学与计算机科学学院,兰州 730030)
0 引言
唐卡(Tang ka)又叫唐喀,是藏语音译过来的词。在《藏汉大辞典》中对唐卡的解释是:“卷轴画,画有图像的布或纸,可用轴卷成一束者。”[1],而在《西藏历史文化词典》中的解释是:“唐卡是指流行于藏区的一种宗教卷轴画,通常绘于布帛与丝绢上,是西藏地方绘画的主要形式之一。”[2]唐卡从起源至今千百年以来,随着历史、宗教的发展而五光十色,其题材内容包含历史、文化、政治等领域,具有庞大的内容体系、独特的艺术价值,不仅是藏民族的百科全书,也是中华民族的骄傲。在唐卡的发展历史中,许多人研究唐卡、描述唐卡,留下大量的唐卡语料。文本分类是自然语言处理的研究热点之一,针对唐卡文本的分类,可以高效地对这些文本进行管理和配置,对后续唐卡知识图谱的构建、唐卡信息检索有积极的意义,因此具有一定的研究价值。
目前中文文本分类技术已经成熟,国内外专家针对文本分类任务的研究主要体现在文本的特征表示方法与分类算法的改进。针对文本的特征表示,文献[3]提出使用TF-IDF算法与Word2vec结合生成词向量,用于短文本的分类,但这一方法存在词与词之间的顺序和位置关系不清晰的问题。文献[4]提出一种统计共现矩阵,这一向量表示方法进行词的向量化表示,能使词的语义和语法信息蕴含在向量之中,这一特征方法被应用到多种自然语言处理任务上。文献[5]运用词向量表示方法ELMo,该模型在训练过程中使用了双向的LSTM考虑了上下文关系,较好地解决了多义词的问题,预训练+微调成为一种新的范式被大量应用在文本分类及其他自然语言处理任务上。文献[6]中提出Transformer结构作为特征提取器,使用Self-Attention,具有强大的特征提取能力。文献[7]基于Transformer的Encoder部分提出了BERT模型,采用了双向编码的方式,利用了每个词的上下文信息,使模型能更好地表达语义信息,问世后便刷新了自然语言处理领域的多项任务指标。文献[8]对于BERT模型进行改进,提出了轻量版本的预训练语言模型ALBERT,这一模型不仅参数量少而且一问世就刷新了自然语言处理的多项任务指标。
另一方面针对分类器的构建上,文献[9]使用卷积神经网络(convolutional neural network)对文本进行句子级别的分类任务,但TextCNN忽略了文本的上下文信息。文献[10]提出使用循环神经网络(recurrent neural network)处理文本分类任务,但循环神经网络对于处理长文本会产生梯度消失或梯度爆炸的问题。文献[11]提出使用双向长短期记忆网络结合Attention机制进行电网领域设备各种文本分类任务,实验结果表明BiLSTM提升了分类效果。文献[12]提出了一种基于卷积神经网络来改进核函数的方法,在法律文本的关系分类有较好的效果。文献[13]提出一种深层金字塔卷积网络(DPCNN),通过加深网络来捕捉文本的长距离依赖关系,相比于传统的TextCNN方法提升了将近2%。
针对唐卡领域文本,本文提出了一种基于BERT(bidirectional encoder from transformers)的唐卡领域文本分类算法。该算法首先用BERT预训练语言模型对唐卡文本进行了特征表示,随后将句子级别的特征表示输入卷积神经网络中再次提取局部语义信息,最后输入分类器中进行分类,在唐卡语料测试集上验证的F1值达到了92.87%,实验结果证明该方法的有效性。
1 基于BERT的唐卡语料文本分类算法
对于唐卡语料文本分类算法,有唐卡文本的预处理、唐卡文本的特征表示、唐卡文本分类三个步骤。唐卡文本的预处理是指将唐卡文本进行数据清洗,再划分类别。唐卡文本的特征表示是指将唐卡文本转换为模型可以接收的形式,形成特征向量。唐卡文本分类是将特征向量输入到分类器中进行分类。
1.1 唐卡文本收集的预处理
1.1.1 数据的收集
本文搜集了三部分的唐卡语料,一部分是从网络上爬取的唐卡人物解释语料,另一部分是在《图解唐卡系列》书籍上收集的有关唐卡的描述语料描述。最后一部分是在《佛教大辞典》收集的有关唐卡人物语料。最终收集到的数据有8917条数据,根据没句话的特征定义了11种关系。
1.1.2 数据清洗
在唐卡文本中包含大量的特殊字符、空白格、英文字符、繁体字。首先这一步中将特殊字符与空白格删掉。这些特殊字符与空白格会对特征提取产生影响,为了让模型更多地关注文本的语义信息,将这些特殊字符在文本中去掉。再分别将英文字符与繁体字转换为汉文字符与简体字符。英文字符与繁体字符会增加特征表示的复杂程度,转化为汉文字符和简体字符在不会增加特征复杂程度的同时还能表达相同的语义特征。
1.1.3 类别配备
文本采用的是有监督的深度学习的方法,需要对唐卡文本进行类别标注。这一步中先使用规则的方法,将原始文本进行类别配对,减少了一部分的标注量,随后再进行人工类别校对,确保文本与类别能够一一配对。在某些类别中,样本数过于稀少,研究价值不大,所以将样本数稀少的类别删除。
1.2 BERT-base,预训练模型
BERT(bidiectional encoder representations from transforms)模型,是由谷歌在2018年所提出,BERT是由堆叠的Transformer Encoder层组成的网络模型,再辅以词编码和位置编码而成的,其模型结构如图1所示,图中E1,E2,…,Em表示的是字符级的文本输入,其经过双向Transformer Enconder编码得到文本的向量化表示T1,T2,…,Tm。BERT模型主要使用了Transformer模型的Encoder部分。
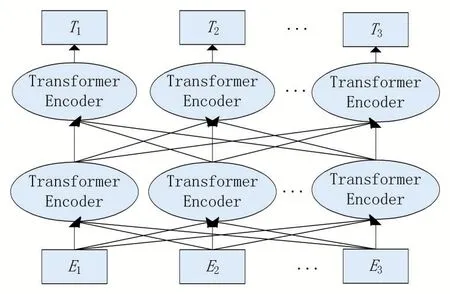
图1 BERT模型结构
1.2.1 Transformer模型的Encoder部分
Transformer是谷歌在2017年提出的结构,用于机器翻译的编码和解码。由于其具有强大的编码能力和并行性被广泛地使用。其编码器部分模型结构如图2所示,Transformer Encoder由两个子层(sub-layers)构成,第一个子层是一个多头的自注意力机制(multi-head self-attention mechanism),第二个子层是一个前馈神经网络(feed forward network),并且在每个子层后面都会加上残差连接(residual connection)和归一化层(layer normalisation)。Transform Encoder的输出会作为下一个Transform Encoder层的输入,多个Transform Encoder不断堆叠最终得出结合上下文的语义表示。而BERT模型便使用了这一结构作为特征提取器。
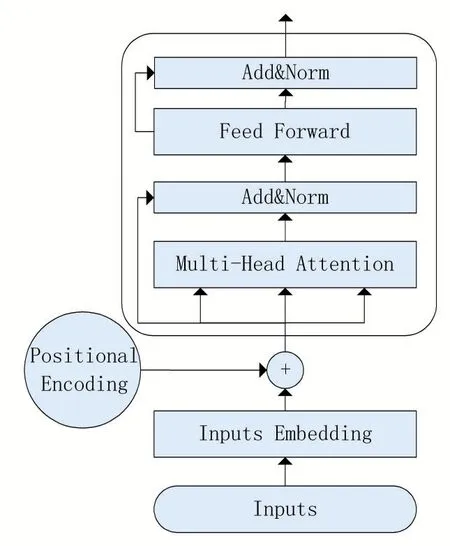
图2 Transformer Encoder模型结构
如图2所示,模型输入经过词嵌入再辅以位置编码,再经过子层一多头的自注意力机制层进行计算,再通过子层二前馈神经网络,最后经过每个子层时都要进行残差连接和归一化层后输出。
1.2.2 输入向量
BERT使用Transformer作为编码器,为了保留文本的位置信息,需要额外地加入位置编码(positional embedding),在同一句话里含有相同的字,字的顺序不一样,整句话的意思就会不大一样,例如:“我去你家”与“你去我家”,这两句话字符一样,但表达的意思完全不同。而分辨这俩句话就需要进行位置编码,在文献[4]中提出了一种基于正弦、余弦的位置编码,在BERT中计算位置向量的公式如下:
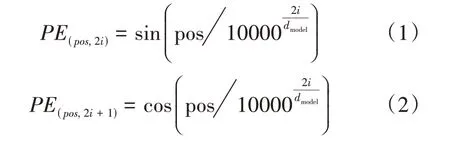
公式(1)、(2)中PE表示进行位置编码后得到的向量,pos代表了词的序号,公式(1)中的2i代表了特征向量的奇数位,公式(2)中的2i+1代表了特征向量的偶数位,dmodel表示特征向量的维数,由此特征向量经过公式(1)、(2)进行位置向量编码得到位置向量,特征向量与位置向量相加作为BERT模型的输入,随后进入下一层Multihead Attention。
1.3 BERT模型的输入、输出
BERT模型会接收单个句子或者句子对作为模型的输入,通过切词,对于每一个最小词单位token,会计算其对应的token embedding、segment embedding和position embedding。token embedding代表了由One-Hot词表映射的编码。segment embedding代表了分割编码,用来区分每个字或词所属的句子。BERT中的Positional embedding是直接对不同的位置随机初始化一个position embedding加到token embedding上。最后三种不同的向量相加作为该token的表示向量输入模型中。BERT模型中使用的segment embedding和position embedding均在预训练的过程中得到。BERT模型输出也为一个向量。设一句话的长度为n,其输入的词向量可以表示为X=(x1,…,xn),经过transformer的编码后输出为向量Z=(z1,…,zn),每个分量zi,都是xi结合了上下文的表示。
1.4 BERT-CNN模型
BERT的训练分两次进行,在使用巨量的文本训练基础模型后,只需要在下游任务中选择特定数据集上微调,就能获得极佳的性能。卷积神经网络一开始用于处理图片数据,即H×W形式的数据,在文本中使用的CNN模型可以提取语义的深层信息,所以本文把CNN模型用于文本分类的下游任务上,进一步提取语义特征,在BERT模型下游接上CNN模型,其结构如图3所示。

图3 BERT-CNN模型结构
BERT提取并整合了单句语义信息的能力和使用分类标签[CLS]捕获句对关系,在文本分类任务中使用句子首标签[CLS]的输出特征作为分类标签,计算分类标签与真实标签的交叉熵,并将其作为优化目标。随后再通过卷积神经网络进行更深层次的特征提取,最后通过Softmax进行归一化处理,输出每句唐卡文本的类别。
2 实验结果与分析
2.1 实验数据
本文实验使用的数据集是收集来的唐卡数据集,共包含8937条有标签的数据,标签的类别有11种,类型分别为别称、合称、藏文拉丁转写、梵文拉丁转写、化身、身相、头戴、坐骑、坐具、持物、手印。各个文本的数据样例如表1所示。

表1 唐卡数据样例
唐卡将唐卡数据按照8∶1∶1的比例划分为训练集、验证集、测试集。使用THUCNews短文本开源数据集作为对比数据集。
2.2 评价指标
分类问题常用的评价指标包括:准确率(precision)、召回率(recall)、F1值(H-mean值)分类结果的混淆矩阵[11]如表1所示。

表2 分类结果的混淆矩阵
(1)P指标是指在模型预测是Positive的所有结果中,模型预测对的比重即分类器模型预测为正且预测正确的样本占所有预测为正的样本比例,计算公式如下:
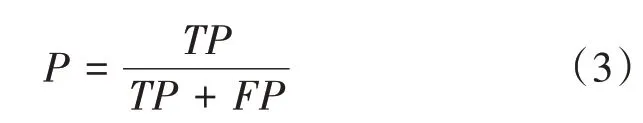
(2)R指标是指模型预测对的比重即分类器预测为正且预测正确的样本占所有真实为正的样本的比例,计算公式如下:

(3)F1值是为了评价模型输出的优劣,综合了Precision和Recall指标,进行加权调和平均,计算公式如下:
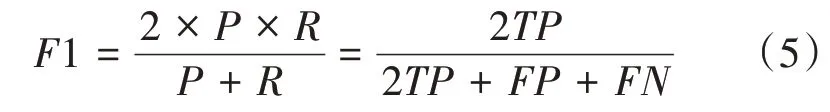
F1值的取值范围[0,1]。从公式中可以看出当P=R=1时,F1值达到最大值1,然而在实际情况中很难实现,在使用F1值作为评价指标时其值越接近1,说明分类器性能越好。
2.3 实验过程
本文使用TextCNN、BiLSTM、BERT、BERTBiLSTM模型作为对照实验,其中TextCNN模型与BiLSTM模型中利用中文分词工具Jieba进行分词,词嵌入采用了Word2vec,训练时参数设置如表3所示。

表3 TextCNN模型训练参数设置
BERT-CNN的模型参数设置如表4所示:

表4 BERT-CNN模型训练参数设置
2.4 实验结果
本文在唐卡数据集上进行实验,分别使用了TextCNN、BERT、BERT-CNN,BERT-BiLSTM作为对照实验,最终实验结果如表5所示。
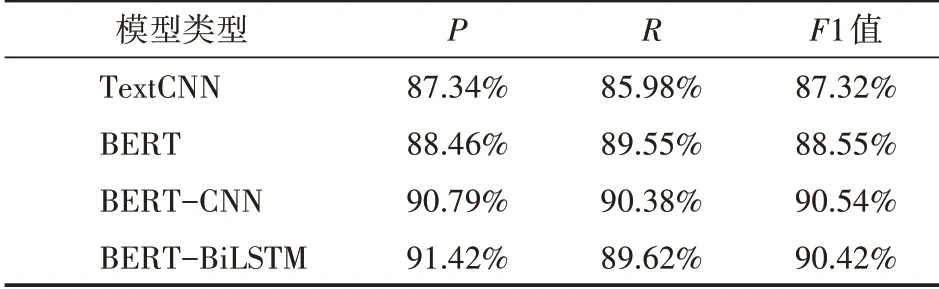
表5 模型实验结果
表5为各个模型在唐卡数据集数据集上面的评价指标对比,可以看出在不使用预训练语言模型,仅仅使用文本卷积模型的分类效果F1值达到了87.32%,使用了预训练语言模型不进一步提取语义特征,BERT的分类效果F1值达到88.55%相比于卷积神经网络提升1.23%,而将这俩个模型优点结合的BERT-CNN模型F1值效果最好,达到了90.54%,相比于TextCNN和BERT模型F1值分别提升了3.22%和1.99%,证明了BERT-CNN模型的有效性。
3 结语
本文在解决唐卡文本分类问题时,使用BERT预训练模型代替传统的Word2vec模型进行唐卡文本特征表示,并在BERT模型后加入CNN再次提取语句的局部特征,进行唐卡文本分类,最终在测试集上的整体F1值达到90.54%。证明了该算法的有效性。由于在某些唐卡语料中一句话过长和存在多种类别,后续将进一步研究长句子分类与多标签问题。
