人工智能算法在5G套餐潜在用户识别中的应用
2022-01-19董莹莹李坤树李子旋
董莹莹 葛 阳 李坤树 李子旋
中国联合网络通信有限公司网络AI中心
0 引言
随着5G网络正式在中国商用,大量的5G终端涌进市场,5G终端占有量日益增长,但其中相当一部分5G终端仍然使用的是非5G套餐,精准预测5G套餐潜在用户对5G业务发展具有重要意义。
本文基于O域信令数据、B域用户出账数据、用户MR位置数据等,先识别出全网的5G终端,然后对半年内5G终端非5G套餐更换为5G套餐的用户进行大数据分析,从用户活跃时长、通话能力、消费能力、终端偏好、网络满意度等方面做特征工程,然后搭建LightGBM分类预测模型,精准预测5G套餐潜在用户更换套餐的概率,将高概率更换套餐的用户清单支撑市场部门进行精准营销,助力5G业务发展。
1 5G终端概况
1.1 5G终端识别
不同网络类型的网络DPI信令数据采集接口不同,在具体的终端识别过程中,可以通过用户终端话单的最高接入网类型接口来判断用户终端类型。2/3/4/5G接入网接口范围可以通过《中国联通移动网络DPI信令采集设备技术规范》进行查看,DPI采集系统在网络中的位置示意图如图1所示。

图1 DPI采集系统在网络中的位置示意图
本文首先在4/5G信令数据中,识别出最高接入网类型为5G的终端,并结合存量的5G终端库,不断补充与修正5G终端配置库;然后基于已识别的5G终端筛选出未开通5G套餐的用户,作为本文的数据采样基础。
1.2 5G终端分析
目前运营商各种类型终端的占比如图2所示。
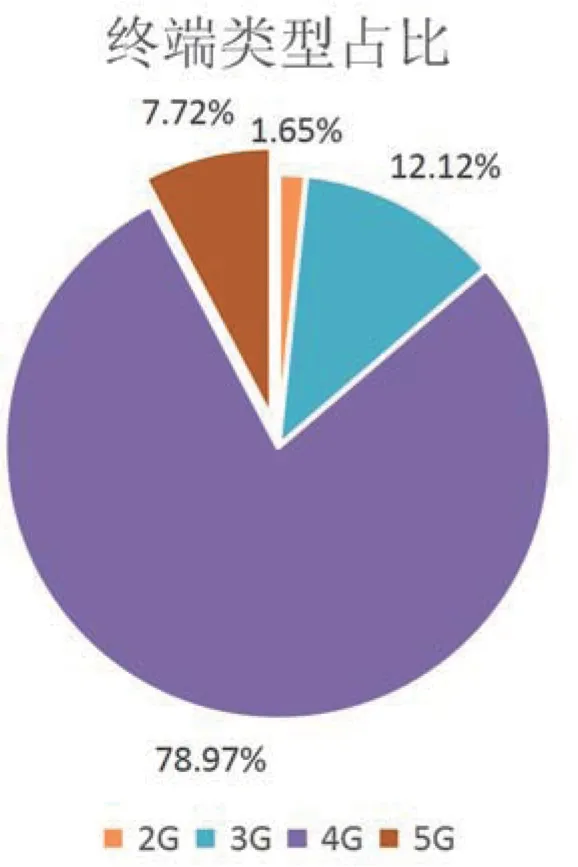
图2 运营商中各网络类型终端占比
从图2中可以发现,目前运营商提供服务的终端中绝大部分依然是4G终端。5G终端的占比甚至不到10%,依然有很大提高的空间。除此之外,图3展示了2021年4月至2021年5月5G终端变化和5G终端非5G套餐用户数占比的变化。
从图3中可以发现,5G终端数量在不断增长。然而,有大量的5G终端用户并没有在运营商开通5G套餐,这体现出5G套餐的用户渗透率较低。为了提升用户的使用体验和运营商的盈利能力,在5G终端非5G套餐用户中筛选出潜在的5G套餐用户将成为运营商需要迫切建立的能力之一。为此,本文将人工智能算法引入5G潜在用过户的识别过程。

图3 5G终端和5G终端非5G套餐用户数占比
2 5G套餐潜在用户识别建模
2.1 数据集生成
2.1.1 获取数据
信令数据存储在分布式hadoop集群上,首先在hive数据库筛选近6个月的数据(5G终端非5G套餐用户)作为模型的采样数据。选取的特征主要包含用户的网络粘性(在网时长、离网时长等),终端属性(终端厂商、终端型号、上市日期、终端制式、价位等),通讯能力(主叫时长、主叫次数、被叫时长、被叫次数等),漫游属性(国漫次数、省漫次数等),位置信息(早忙时常小区、晚忙时常驻小区等),消费能力(出账、ARPU、流量、业务订购等),基本属性(号码、套餐、年龄、性别、网龄、发展渠道、用户群等),基于以上用户属性信息数据,通过初步的数据清洗、特征工程得到初步的样本数据,共计90+字段属性。
2.1.2 筛选正反例
在上述样本数据中,筛选本年内已经更换为5G套餐的用户作为模型的正例样本数据,设置标签label=1。其余未更换5G套餐的用户作为模型反例,设置标签label=0。这样,正反例的选取工作就完成了。
2.1.3 生成训练集与测试集
对于均衡样本来说,可以从全量数据集中按照比例随机抽取样本,将数据集切分成训练集与测试集,但实际生产环境中,往往实际的正负样本是失衡的,这时就要在采样方法上多做一些尝试,才能使模型达到较好的效果,下面介绍几种失衡样本的抽样方法。
(1)过采样类
①随机过采样。它是从样本少的类别中随机抽样,再将抽样得来的样本添加到数据集中,从而达到类别平衡的目的,这种方法操作简单,少量样本被重复选取,无形中加大少量样本的权重,但这样容易出现过拟合的情况。本文尝试了这种方法,效果提升不明显。
②SMOTE过采样。其思想就是在少数类的样本之间,进行插值操作来产生额外的样本。它以每个样本点的k个最近邻样本点为依据,随机的选择N个邻近点进行差值乘上一个[0,1]范围的阈值,从而达到合成数据的目的。该算法的核心是假设特征空间上邻近的点其特征都是相似的。它并不是在数据空间上进行采样,而是在特征空间中进行采样,因此它的准确率会高于传统的采样方式。本文使用SMOTE过采样方法对少量的正例样本进行采样,将正反例比例由1:12提升至1:3,大大提升了模型预测效果。
③Border-Line SMOTE过采样。这个算法一开始会先将少数类样本分成3类,分别是DANGER:超过一半的k近邻样本属于多数类;SAFE:超过一半的k近邻样本属于少数类;NOISE:所有的k近邻个样本都属于多数类。而Border-line SMOTE算法只会在“DANGER”状态的少数类样本中去随机选择,然后利用SMOTE算法产生新样本。该方法是SMOTE采样方法的一个改进算法,在不均衡样本处理方面具有事半功倍的效果。
(2)欠采样类
①随机欠采样。随机从多数类中删除一些样本,该方法的缺失也很明显,那就是造成部分信息丢失,对模型的分类提升效果不理想。
②EasyEnsemble欠采样。将多数类样本随机划分成n份,每份的数据等于少数类样本的数量,然后对这n份数据分别训练模型,最后集成模型结果。
③BalanceCascade欠采样。这类算法采用了有监督结合boosting的方式,在每一轮中,也是从多数类中抽取子集与少数类结合起来训练模型,然后下一轮中丢弃此轮被正确分类的样本,使得后续的基学习器能够更加关注那些被分类错误的样本。
在数据采样阶段,可以尝试过采样与欠采样结合的方法,调整正反例数据比例,生成相对均衡的正负样本,提升模型分类预测效果。
2.2 数据清洗
2.2.1 空值处理
本文用到的控制处理方法有:(1)直接删除特征;(2)使用指定数据值填充缺失值,如零值、均值、众数或中位数等填充。针对缺失率超过80%的指标特征,直接进行删除。对于像用户年龄、网龄、终端价格等。数值类的数据,通过均值来填充;针对用户的通讯能力、网络粘性相关的特征,直接使用零。
2.2.2 异常值处理
本文使用的异常值处理方法主要有:(1)直接删除异常数据记录;(2)使用零值或均值替换异常数据。针对用户年龄小于0或大于100的数值,这样的样本数据较少,均采用均值替换;对于在枚举值之外的类别字段异常值,直接删除对应的记录。
2.2.3 文本数据处理
对于文本类型的数据,本文有以下三种处理方法:(1)利用one-hot encoding处理字段;(2)使用label encoding处理字段;(3)将字段标注成类别特征直接进行模型训练。一般地,针对举值较少的字段运用one-hot encoding处理,如套餐的top6、终端品牌等;枚举值较多的字段,本文会使用label encoding方法处理,如省份、地市等。
2.3 特征工程
在正反例筛选之后,进一步对数据做特征工程,主要是数据降维,本文用到的数据降维方法主要有下面两种。
2.3.1 主成分分析
PCA是最常用的无监督线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此降低数据维度。
设样本为m行n维的数据,PCA的一般步骤如下:
(1)将原始数据按列组成n行m列的矩阵X;
(2)计算矩阵X中每个特征属性(n维)的平均向量M(平均值);
(3)将X的每行(代表一个属性字段)进行零均值化,即减去M;
(4)按照公式C=1/m XXT求出协方差矩阵;
(5)求出协方差矩阵的特征值及对应的特征向量;
(6)将特征向量按对应特征值从大到小按行排列成矩阵,取前k(k<n)行组成基向量;
(7)通过Y=PX计算降维到k维后的样本特征。
2.3.2 线性判别分析
对于给定的训练集,设法将样本投影到一条直线上,使得同类的投影点尽可能接近,异类样本的投影点尽可能远离(类内方差最小,类间方差最大);在对新样本进行分类时,将其投影到这条直线上,再根据投影点的位置来确定新样本的类别。
其一般步骤是:
(1)计算数据集中每个类别下所有样本的均值向量;
(2)通过均值向量,计算类间散布矩阵SB和类内散布矩阵式SW;
(3)依据公式;
(4)按照特征值排序,选择前k个特征向量构成投影矩阵U;
(5)通过的特征值矩阵将所有样本转换到新的子空间中。
2.4 模型介绍
2.4.1 模型选择
本文讲述的5G套餐潜在用户识别模型是一个典型的二分类模型。在模型选择时,需要综合考虑模型的调参收敛效率,以及模型的准确率与鲁棒性,本论文主要采用是树模型,分别用LightGBM与随机森林搭建融合AI模型,将两个模型的预测结果按照既定权重(专家经验与试点迭代)树综合评判目标用户的推荐概率。
LightGBM与RandomForest分类算法,都是以决策树为基学习器,构建n个并行学习器,并结合所有的学习器输出结果。本课题实际的正反例样本数据是失衡的,正反例约1:7,且数据量大,样本数据约为1200万,考虑到数据集体量大和服务器性能一般的现状,上述两个算法对内存的消耗不高,收敛效果也不错,故采用LightGBM与RandomForest算法模型比较合适。在实现本模型时,本文对样本集进行了抽样,对反例进行欠采样,将训练集数量控制在500万,模型维度为90+,针对n_estimator参数设置为[100,500],subsample参数取值设置在[0.7-0.9]等,根据运营商数据特殊的业务场景,对分类算法涉及的若干参数的取值范围都进行了缩放,此处也是对两种AI分类算法的一个改进。
2.4.2 参数调优
本文采用网格搜索和随机搜索的方式进行参数调优。
2.4.3 模型评价
采用F1-score对模型进行评估。相关评价指标定义:TP(True Positive):真 实 为1,预 测 也 为1;FN(False Negative):真实为0,预测为1;FP(False Positive): 真实为1,预测为0;TN(True Negative):真实为0,预测也为0。

最终模型的F1-score为0.82。模型的整体训练预测示意图如图4所示。
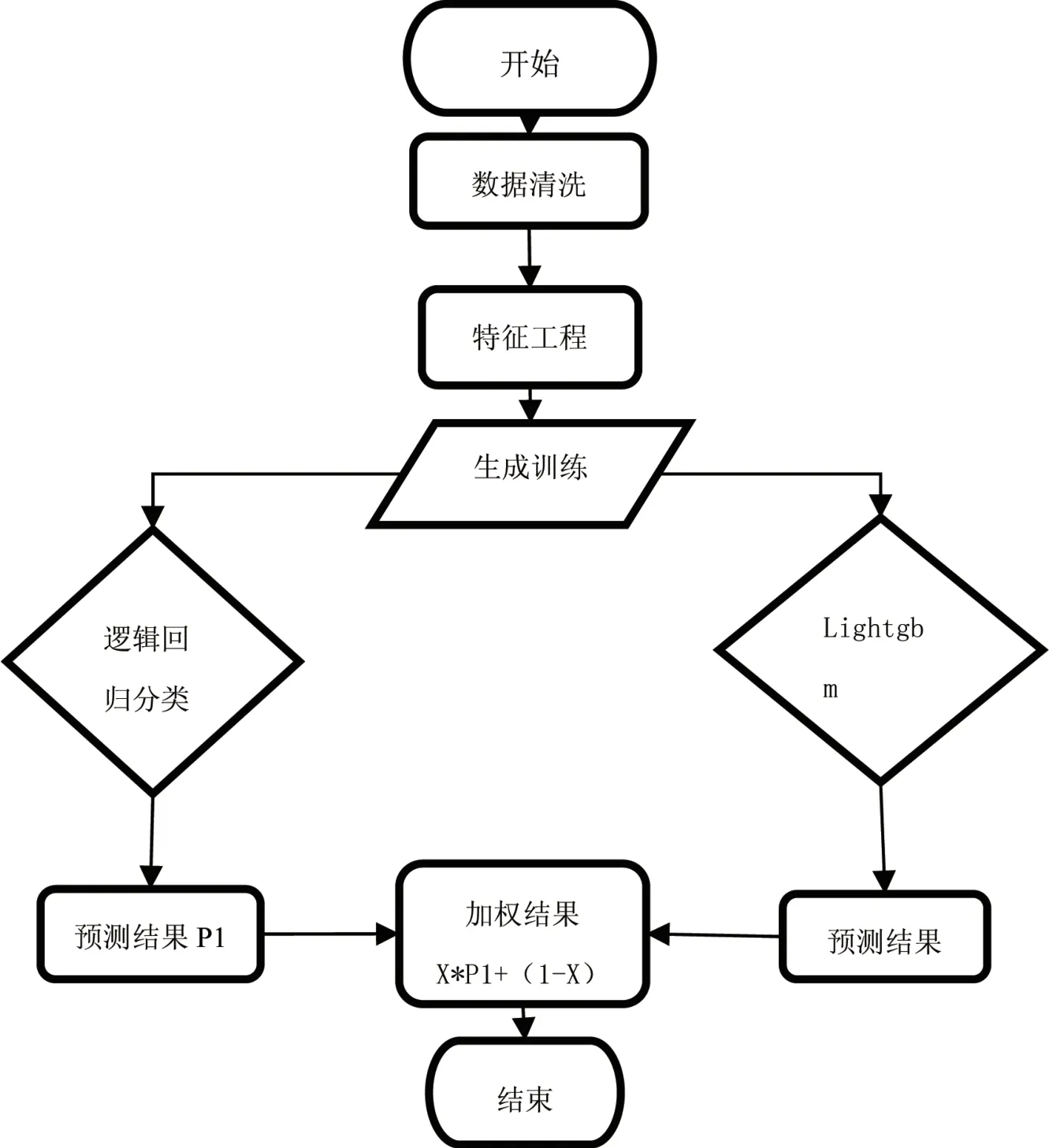
图4 模型工作示意图
3 市场应用分析
3.1 应用方案设计
为了验证模型实际应用效果,本文对模型验证设计了一套实际应用方案,具体如下:
(1)数据发布。利用训练好的融合AI模型对全网5G终端非5G套餐的用户进行预测打标,筛选更换5G套餐概率大于0.7的用户,再将用户详单数据发布至能力开放平台供各省订阅。数据开放样例数据如表1所示。
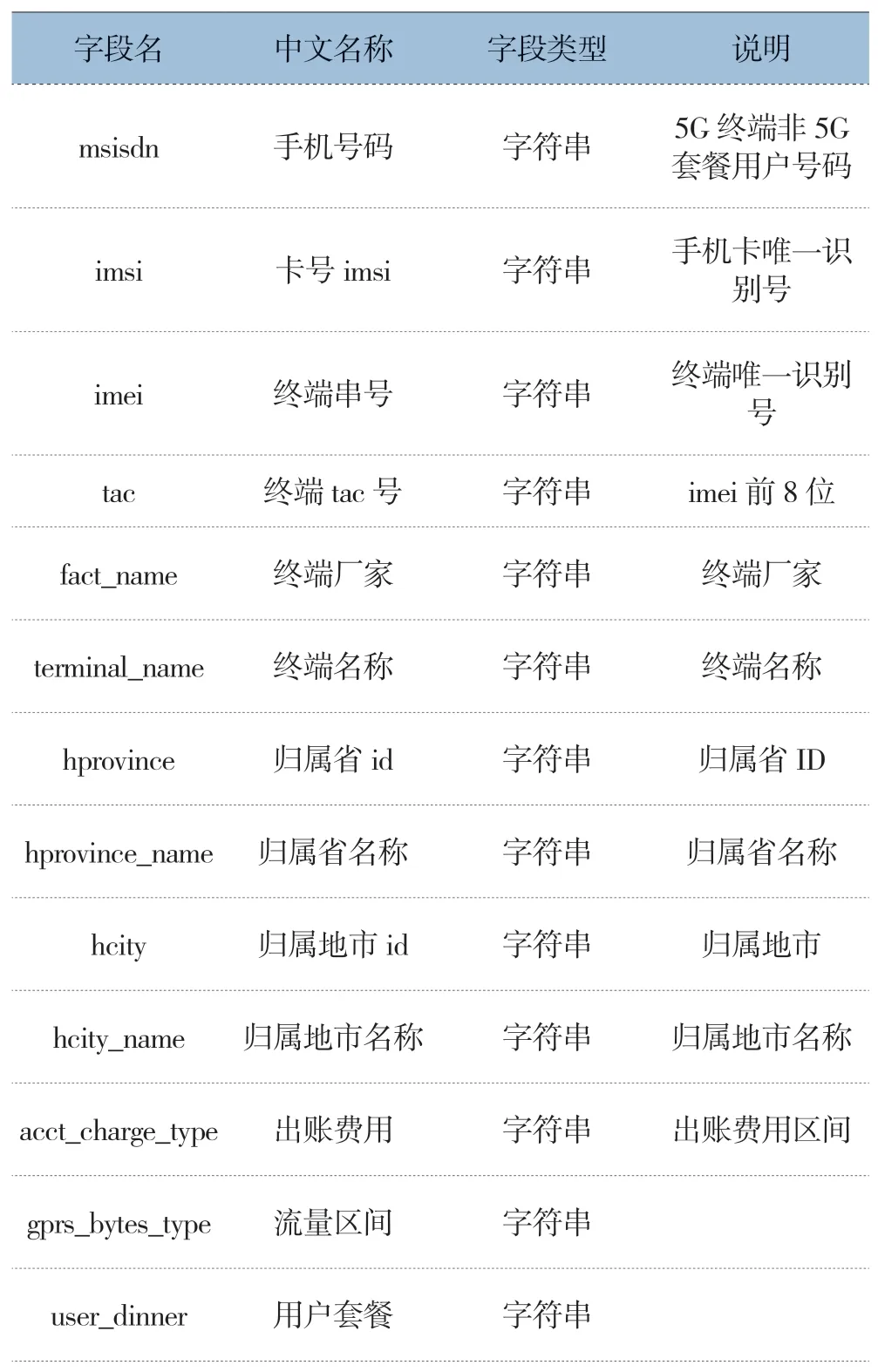
表1 2G终端数据开放样例

?
(2)省分订阅目标用户详单数据,选定一个省某一地市某一个营业厅A,进行外呼营销,记录实际营销过程中存在的问题。
(3)模型迭代优化。根据试点营业厅A提出的问题进行模型优化迭代。
(4)优化模型验证。选取其他多个试点营业厅,试点营业厅根据所提供的数据做外呼营销,测试优化模型效果。
3.2 应用结果分析
第一阶段:选取江苏省某地市营业厅A试点,共提供500户目标用户,外呼成功318户,成功更换5G套餐用户9户,外呼成功转化率2.8%。
第二阶段:选取江苏省某地市4个营业厅进行试点,共提供1000个号码,接通759户,成功办理62户,成功率8.2%,较第一版本营销成功率提升5.4个百分点。
4 结束语
本文提出了一种基于信令数据与融合AI算法的5G套餐潜在用户识别方法,实现了人工智能算法在5G套餐迁转营销中的应用,解决了推荐5G套餐目标性差及推荐效率低的问题。在实际的市场应用中展现模型的高精准度,5G套餐推荐转化率由自然转化的1%提升至8.4%,实现了人工智能赋能5G套餐业务发展,对提升5G套餐市场占有率有重大意义。
