基于时序窗口的概念漂移类别检测
2022-01-19郭虎升任巧燕王文剑
郭虎升 任巧燕 王文剑
1(山西大学计算机与信息技术学院 太原 030006)2(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)
目前,在实际应用领域中均涌现出大量动态数据,如网页点击数据[1]、在线欺诈检测[2]、垃圾邮件过滤[3]等,这些数据不同于传统静态数据,而是作为一种持续不断产生、实时性较强的流式数据存在,被称为流数据[4-5].近年来,伴随着流数据的大量产生,在线学习在机器学习领域受到越来越多的关注,其目的是使得学习模型对当前数据做出实时响应[6-7].流数据又可分为稳定数据流与动态数据流,稳定数据流具有独立同分布特点,而动态数据流则不是独立同分布的,其典型特征是由环境等因素变化使得数据中隐含的目标概念发生变化,即发生概念漂移[8].流数据中存在的概念漂移使得已有方法难以满足用户对漂移检测精确度、时空性能等方面的要求,如客户行为模式随时间推移会发生变化,这种变化中隐含着商机,而商家为发现客户行为模式的变化并对销售情况进行预测,会搜集越来越多的实时数据,如销售图表和客户数据,从而动态地调整预测模型,因此在对流数据学习时,检测其存在的概念漂移并实时动态调整模型对准确把握流数据中的关键信息具有重要意义.
针对流数据中存在的概念漂移问题,目前提出的检测方法大体可分为增量学习[9]与集成学习[10-11].这2类方法均是在流数据划分的基础上进行的,而数据划分一般通过在线窗口(本文将其称为时序窗口)技术或思想实现.增量学习方法采用单个分类器对流数据进行学习,通过动态调整模型以达到适应流数据变化的特点,如:基于滑动窗口的概念漂移检测方法通过窗口的不断向前滑动来获得新的样本进行增量学习,并与旧分布数据相比较来检测概念漂移[12-13];自适应的增量贝叶斯方法对流数据中较难分类的历史样本进行单独处理以得到先验概率,并结合主动学习的半监督方法计算当前样本的后验概率以检测概念漂移[14-15].尽管增量学习策略在解决概念漂移检测问题中起到了重要作用,且由于单个分类器的遗忘机制对新概念反应迅速,通常不受旧概念影响,对突变类概念漂移具有较高的适应性,但其仍然存在时序学习过程中复杂度的累积效应、增量样本选择困难、模型不收敛、学习结果不稳定、不适用于渐变类概念漂移检测等多方面问题.
集成学习方法利用历史数据构建一系列子学习器,借助投票加权机制进行集成决策,当概念漂移发生时,根据各学习器在当前数据的学习效果进行权值调整,从而较好地适应流数据中的概念漂移.Soares等人[16]提出了一种基于回归模型的在线加权集成(on-line weighted ensemble, OWE)方法,它能在概念重复出现的情况下保留旧的概念信息;Song等人[17]提出了一种新的集成模型,即动态聚类森林(dynamic clustering forest, DCF),用于文本流分类的概念漂移;在线深度学习将深度学习与集成学习结合在一起,能够从流数据中学习神经网络模型,并对神经网络中不同层次网络进行集成,可获得更高的分类精度并检测流数据中存在的概念漂移[18];文益民等人[19]借助迁移学习思想,将历史概念的学习器与目标领域的学习器进行集成,实现从源领域到目标领域的知识迁移,提高了概念漂移检测的准确率及模型的收敛性能.集成学习方法的模型构建简单,对流数据学习效果较好,但往往由于模型中包含历史数据较多,不能及时对概念漂移做出反应,模型实时性能较差.
目前还有一些研究将二者结合,充分利用各自优点来提升概念漂移检测方法的性能.Lu等人[20]将基于竞争模型的增量学习与在线集成学习方法LEARN++相结合,提出了基于竞争模型的概念漂移检测方法,并从理论上证明了其统计意义下的性能;潘吴斌等人[21]结合增量学习和集成学习,引入当前数据建立的新分类器进行学习器更新,并与旧分类器进行加权集成,解决了网络流量监控中的概念漂移问题.
然而,由于实际应用领域数据流发生的概念漂移具有隐含、未知、易变以及多样等复杂特点,按照概念漂移发生时数据分布的变化情况可大体上分为2类:突变类概念漂移与渐变类概念漂移[22].概念的突然漂移意味着原始数据分布在很短时间内直接改变为新的数据分布,如股票的涨停是在短时间内突然变化的;而概念的逐渐漂移意味着在一段时间内服从旧分布的数据逐渐减少,服从新分布的数据逐渐增多,直到新分布取代旧分布,如工厂中不断磨损的器械会逐渐影响其加工出的零件质量.不同类别概念漂移蕴含的实时信息往往存在差异,因此,如何快速有效地发现不同类别概念漂移的特征,对概念漂移类别进行划分,并依据概念漂移类别提供有针对性的应对策略以加速在线模型收敛是一个有重要意义的研究课题.
现有概念漂移检测方法大多是针对单一类型的概念漂移提出的(即仅检测突变类概念漂移或仅检测渐变类概念漂移),难以同时适应多种漂移特征.针对这个问题,本文提出一种有效检测概念漂移并进行类别判断的方法,主要贡献有2个方面:
1) 给出不同类别概念漂移的特征描述,以此为基础提出流数据概念漂移类别的划分方式;
2) 以不同类别概念漂移为检测目标,提出基于时序窗口机制的概念漂移类别判断方法.
1 概念漂移类别描述及分析
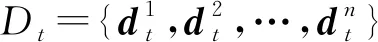
1) 突变类概念漂移(sudden concept drift)[23].假设流数据初始分布为Φ,在时刻t之后到来的数据服从的分布以迅速且不可逆的方式变为另一种分布Φ′,形式化描述为{D1,D2,…,Dt-1}~Φ,{Dt,…}~Φ′,即在时刻t处发生概念漂移,且此类概念漂移具有永久性,一旦发生原始数据分布信息立刻被新的分布信息不可逆转地覆盖掉,如图1(a)所示.
2) 渐变类概念漂移(gradual concept drift)[23].类似地假设流数据初始分布为Φ,在时刻t之后到来的数据服从的分布持续发生变化,经过一段时间间隔后流数据服从新的分布Φ′,描述为:{D1,D2,…,Dt-1}~Φ,{Dt+m,…}~Φ′,而二者之间的m个时间间隔内每个子序列的数据{Dt,…,Dt+m-1}一部分服从Φ,另一部分服从Φ′,且按照先后顺序满足规律:服从旧分布的数据逐渐减少,服从新分布的数据逐渐增多,如图1(b)所示.渐变类概念漂移发生时,样本从一种分布过渡到另一种分布需要经过一段时间,且该段时间内数据分布信息随时间缓慢变化.
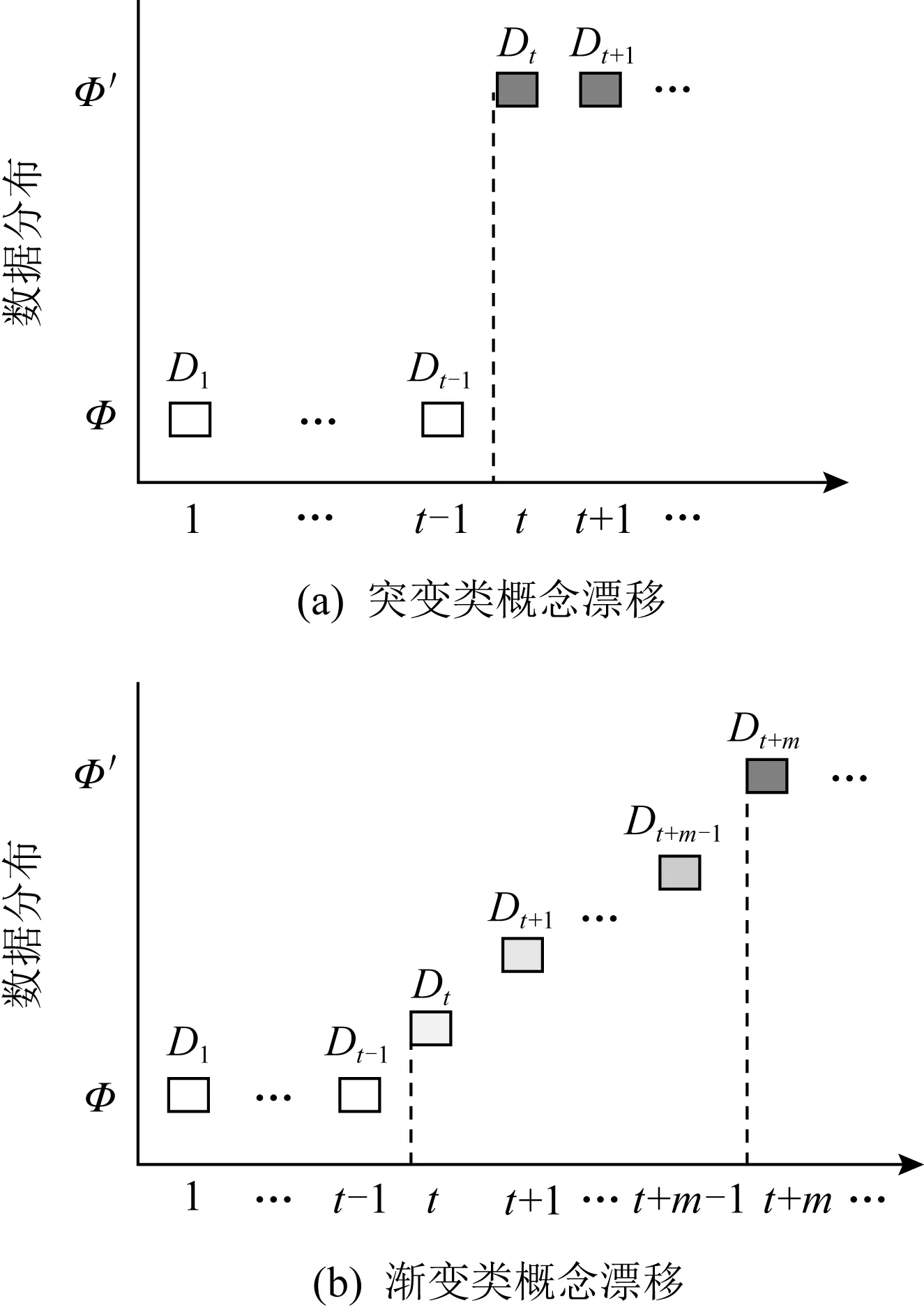
Fig. 1 Concept drift class diagram
在实际的流数据挖掘应用问题中,相同时间间隔内产生的样本规模可能不同,即不同的Dt中n值可能不同,若按时间间隔对流数据进行划分,则得到的不同模型之间可比性较小,因此本文在对数据进行学习时设定学习单元的阈值为ω(即一个学习单元的样本容量),并按照所设阈值对数据流进行划分,划分后的每部分数据称为一个学习单元.若当前时间间隔内未被学习的样本数量大于该阈值,则按照先后顺序取前ω个数据作为一个单元,其余数据自动划分到下一个单元;若当前时间段未被学习的数据小于该阈值,则继续等待新数据,直到数据量达到该阈值时进行新的学习过程.通过对流数据进行等量划分,可将其表示为SD={X1,X2,…,Xh,…},其中Xh表示对样本重新进行划分后的第h个学习单元.
不难看出,突变类概念漂移与渐变类概念漂移的最大区别在于样本分布规律从一种分布过渡到另一种分布所需的时间不同,这个过程为漂移过程.为便于描述,本文利用漂移过程中包含的学习单元数量——漂移跨度(Span),来衡量漂移过程所需时间.对于突变类概念漂移,其漂移跨度为1,而渐变类概念漂移的跨度则大于1.
2 基于时序窗口机制的概念漂移类别检测
针对传统概念漂移检测方法检测目标单一且对于概念漂移分类研究较少的问题,本文提出了一种基于时序窗口机制的概念漂移类别检测(concept drift class detection based on time window, CD-TW)方法.该方法的主要贡献为:
1) 扩展窗口技术,本文在概念漂移节点检测阶段利用节点时序窗口不断加载最新数据,以检测流数据中的概念漂移节点,剔除历史信息干扰,保证高速有效学习;在漂移跨度检测阶段,在不降低算法实时性的基础上,采用向未来“借数据”的思想,创建跨度时序窗口检测漂移跨度,解决增量学习中存在的复杂度累积效应与样本选择困难问题,也解决了集成学习中基学习器敏感性较低的问题.
2) 采用栈和队列的数据结构在学习过程中按照流数据时效性对其进行高效合理的组织,不以舍弃历史数据来提高时效性和敏感度;本文在检测到概念漂移节点后,进一步通过检测跨度实现其类别判断,处理目标不再单一,可以更有针对性地进行在线模型调整.
2.1 概念漂移节点检测
首先,需要定义当前数据缓存区(current data buffer,CD_buffer)和历史数据缓存区(historical data buffer,HD_buffer),分别用于存放新到的未被处理的数据和已经处理过的数据,在CD_buffer中以队列结构存取数据,在HD_buffer中以堆栈结构存取数据.当流数据进入CD_buffer后,首先按照学习单元阈值ω将数据进行等规模划分,可以容纳一个学习单元的窗口称为基础时序窗口.随后创建2个容量相同的基础节点时序窗口w1(参考窗口)和w2(滑动窗口).
概念漂移节点检测的过程包含数据准备和漂移节点检测2个过程:
1) 数据准备
CD_buffer→HD_buffer:队头数据转移;
HD_buffer→w1:栈顶数据复制;
CD_buffer→HD_buffer:队头数据转移;
HD_buffer→w2:栈顶数据复制.
2) 漂移节点检测
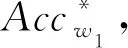
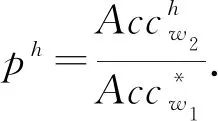
(1)
若ph满足ph<τ(τ为漂移节点探测参数),则将h作为概念漂移节点输出,反之继续通过CD_buffer→HD_buffer的数据转移与HD_buffer→w2的数据复制来完成更新和检测工作,直到找到满足ph<τ的学习单元所在节点时停止概念漂移节点检测过程,如图2所示:
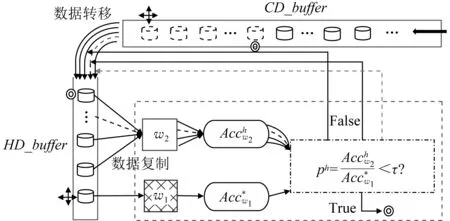
Fig. 2 Concept drift site detection
在每轮概念漂移节点检测过程中,参考窗口w1仅加载初始学习单元,且不进行更新,对于将来的概念漂移而言,其中包含的数据始终代表原始分布,故将其作为本次检测的基准;滑动窗口w2中的数据则随着缓冲区之间的数据流动不断更新,直到第h个学习单元所得到的探测流动比满足漂移探测参数时停止,此时该学习单元内存在概念漂移.图2中十字箭头标注处的学习单元为概念漂移检测的起始节点,本轮检测完成后找到概念漂移节点(同心圆标注位置),在检测过程中逐步将旧数据转移到HD_buffer中.
2.2 概念漂移跨度检测
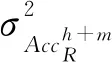
1) 数据准备
CD_buffer→R:队头数据复制.
2) 漂移跨度检测
利用学习器对R所包含的每个基窗口数据进行训练测试得到相应的测试精度,假设分别为AccR1,AccR2,…,AccRk,计算其均值及方差:

Fig. 3 Concept drift span detection
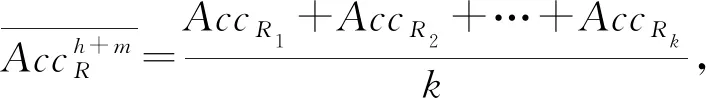
(2)
(3)
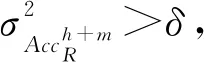
图3中短箭头标注位置为概念漂移节点的下一个节点,即跨度时序窗口检测起点.跨度时序窗口R中的数据直接从CD_buffer队头加载,检测过程需要不断完成CD_buffer队头到HD_buffer栈顶的数据转移和CD_buffer队头到R的数据复制.在得到概念漂移跨度之后,即可根据漂移跨度确定概念漂移类别,若漂移跨度等于1,则对应的概念漂移为突变类,反之则为渐变类.
由于流数据不断产生,因此节点检测和跨度检测2个过程循环进行,每一轮检测只关注当前数据是否存在概念漂移,若存在则计算其跨度,否则继续向前检测概念漂移节点.
2.3 CD-TW方法
本文采用时序窗口机制对流数据进行学习,检测其中的概念漂移节点并对其划分类别.该方法将流数据划分为均等的学习单元,对每个单元进行独立高效学习,通过计算探测流动比来检测概念漂移节点;在此基础上,分析跨度时序窗口中所包含数据的分布稳定性,计算漂移跨度并对概念漂移类别进行划分.该方法流程如图4所示:
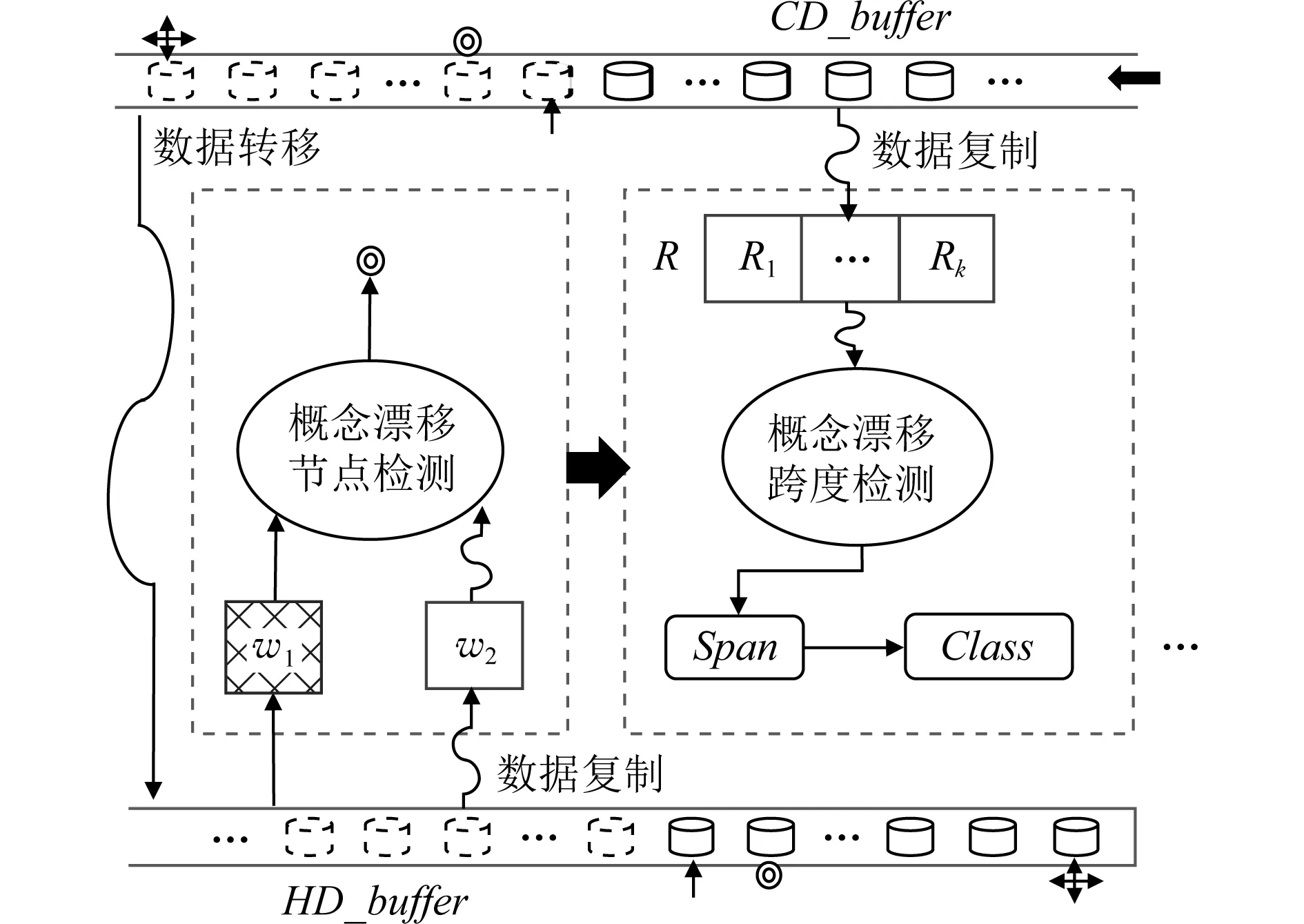
Fig. 4 Concept drift class detection process
算法1展示了基于时序窗口机制的概念漂移类别检测的具体过程.
算法1.基于时序窗口的概念漂移类别检测(CD-TW)算法.
输出:概念漂移节点、跨度及类别(h,m,Class).
① while流数据序列SD未结束
② 加载新到的X子序列到CD_Buffer当中;
③ whileCD_Buffer中数据规模大于等于ω
④ 移动CD_Buffer中队头数据单元到
HD_Buffer栈顶;

⑥h=0初始漂移节点探测流动比p0=1;
⑦ whileph≥τ
⑧h=h+1;
⑨ 移动CD_Buffer中队头数据单元到HD_Buffer栈顶;
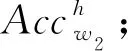
3 实验与性能分析
为验证所提算法在概念漂移检测与类别判断方面的性能,本文分别在7个UCI(University of California Irvine)标准数据集和3个真实数据集上进行实验.实验平台为Windows10,CPU为酷睿i7-3210,内存为8 GB,语言为Matlab2016b.实验中,将本文提出的CD-TW方法与基于单窗口机制的概念漂移检测方法(single-windows-based classifi-cation algorithm for concept drifting data streams, SWCDS)[12]、基于双窗口的概念漂移检测方法(double-windows-based classification algorithm for concept drifting data streams, DWCDS)[12]和基于迁移学习的概念漂移检测方法(concept drift online learning, CDOL)[24]进行对比.由于SVM在小规模样本上具有良好的泛化性能,因此本文选择LIBSVM作为基础分类器来构建模型,由于SVM本身参数选择不是本文的研究重点,其具体选择方法目前已经有较多研究[25-26],本文实验中均取默认值.
3.1 数据集
1) UCI数据集.UCI是用于机器学习的标准数据库,可方便设置概念漂移节点、模拟不同类别概念漂移,以检验算法对不同类别概念漂移的识别能力.实验中利用正反例互换方式来模拟概念漂移中样本分布的变化.实验采用的UCI数据集如表1所示:
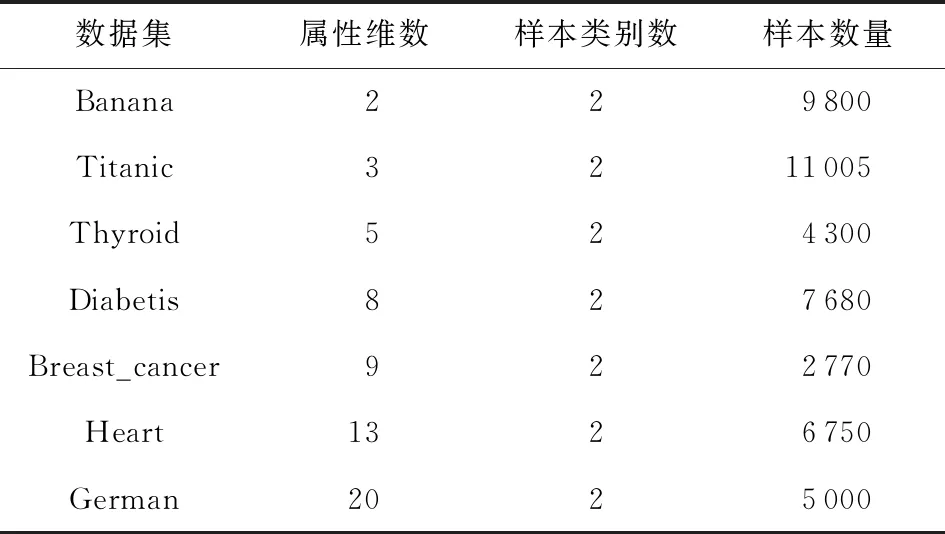
Table 1 UCI Datasets Used in Experiment
2) 真实数据集.实验采用的真实数据集包括KDDCup99[27],USPS[28],MITface[29].其中,KDDCup99是网络入侵检测数据,常用于模拟漂移数据以验证算法有效性;USPS为美国邮政手写数据集;MITface来自MIT的人脸实例库.KDDCup99,USPS,MITface数据集的具体信息如表2所示:
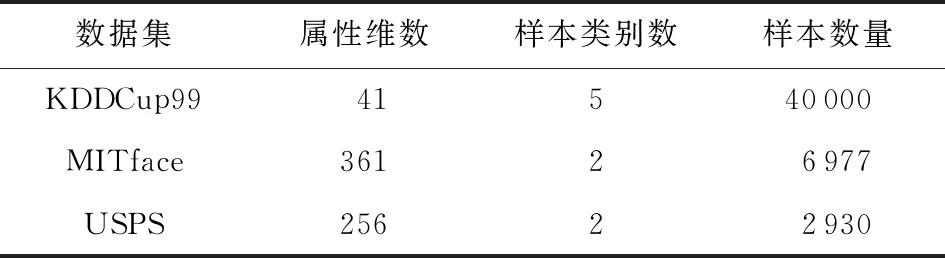
Table 2 Realistic Datasets Used in Experiment
3.2 参数设置及渐变类漂移模拟
1) 参数设置.为充分验证本文所提出的概念漂移类别检测方法的性能,本文采用不同的学习单元规模参数ω、漂移探测参数τ和跨度探测参数δ进行实验.所有数据流均在前、中、后3个阶段分别插入概念漂移节点.
每个数据单元对应一个基窗口,ω太大会降低概念漂移节点检测的敏感性,反之则容易将正常微小波动误检为概念漂移,实验中ω分别取20,40,60,80,100进行检测,漂移探测参数τ分别取0.75,0.8,0.85,0.9,0.95,跨度探测参数δ分别采用 0.001,0.002,0.005,0.008,0.01.实验中展示了在不同ω下的最优参数组合对应的结果(ω=20,τ=0.8,δ=0.01;ω=40,τ=0.85,δ=0.01;ω=60,τ=0.85,δ=0.001;ω=80,τ=0.9,δ=0.001;ω=100,τ=0.9,δ=0.001).实验中伴随窗口包含4个基窗口,即k=4.
2) 渐变类漂移模拟.本文实验中渐变类概念漂移中漂移跨度范围内的旧分布数据以10%的步长递减,新分布的数据以10%的步长递增.
3.3 评测指标
为衡量所提出的CD-TW方法的性能,本文针对概念漂移节点、漂移跨度及漂移类别的检测分别提出不同的评价指标.不同类别概念漂移节点检测情况如图5所示.图5中,TL={tli}为真实插入的概念漂移节点集合,概念漂移tli的跨度内节点构成集合为TLi[O],对于突变类概念漂移,该集合仅包含一个节点,即tli本身;对于渐变类概念漂移,若检测到的漂移起始节点落在TLi[B]内(包含真实插入节点及与其相邻的后3个节点),则视为正确检测且无延时;检测到的漂移结束节点(起始节点经过漂移跨度到达的节点)落在TLi[E]内(包含真实结束节点及与其相邻的前3个节点)视为正确检测.本文定义误检率、漏检率和平均检测延时来评价概念漂移位点检测效果,定义缺失率与溢出率衡量漂移跨度的检测准确度,定义类别准确率观察CD-TW对类别的决策能力.
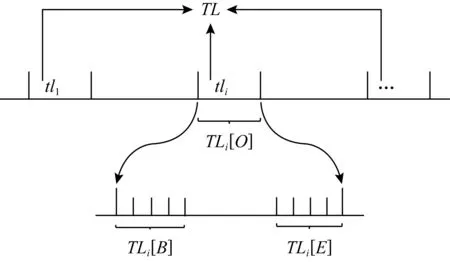
Fig. 5 Standard for determining concept drift position
1) 误检率(error detection rate,EDR).检测到的漂移节点中存在的错误漂移节点比例,可反映模型的抗干扰性能,定义为
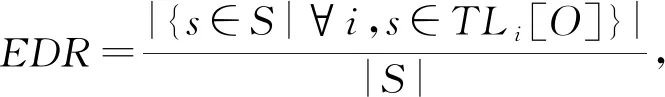
(4)
其中S表示检测到的漂移节点集合.
2) 漏检率(miss detection rate,MDR).真实插入的漂移节点中没被检测到的比例,可反映模型的漂移检测敏感性,定义为
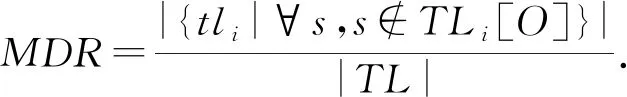
(5)
3) 平均检测延时(average detection delay,ADD).检测到的漂移节点相对于真实漂移节点的延迟程度,用于衡量渐变类概念漂移节点检测的时效性,定义为
(6)
4) 缺失率(loss rate,LR).检测到的概念漂移跨度缺失部分占真实跨度的比例,定义为
(7)
其中:
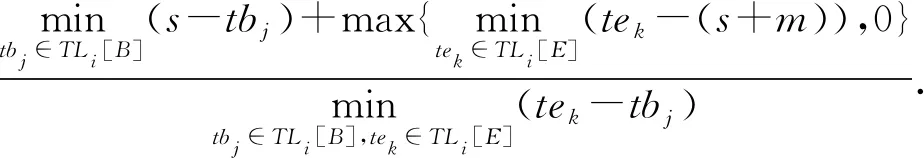
5) 溢出率(flow rate,FR).检测到的概念漂移跨度溢出部分占检测跨度的比例,定义为
(8)
其中:
6) 类别准确率(accuracy,Acc).概念漂移类别判断正确的比例,定义为
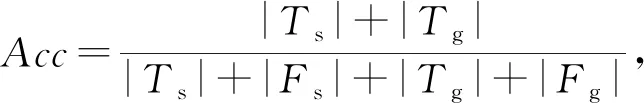
(9)
其中,|Ts|为检测到的突变类概念漂移被正确分类的数量,|Fs|代表检测到的突变类概念漂移被错误分类的数量,|Tg|表示检测到的渐变类概念漂移被正确分类的数量,|Fg|代表检测到的渐变类概念漂移被错误分类的数量.
3.4 实验结果与分析
为有效衡量本文提出的CD-TW方法在概念漂移检测及其类别检测的不同阶段所得结果的性能,实验中分别对概念漂移节点检测的情况(包括误检率、漏检率、平均检测延时)、概念漂移跨度检测(包括缺失率、溢出率)及漂移类别检测结果分别进行测试分析.
3.4.1 概念漂移节点检测
实验中采用EDR,MDR,ADD这3个指标来评测不同方法在流数据中的概念漂移节点检测性能.图6和图7分别为突变类概念漂移节点检测得到的EDR和MDR值.从实验结果可以看出,除数据集USPS(w=40)外,本文提出的CD-TW方法在突变类概念漂移检测的实验中得到的EDR和MDR值优于其他概念漂移检测方法,这说明本文所提出的算法在检测突变类概念漂移时的误检与漏检均较低,表现出了良好的概念漂移节点检测效果,同时反映出本文在小样本学习中占有绝对性优势,而SWCDS和DWCDS方法无法有效区分小样本学习与突变类概念漂移带来的波动.
图8和图9分别为渐变类概念漂移节点检测得到的EDR和MDR值.从实验结果可以看出,CD-TW方法对渐变类概念漂移的识别能力也明显优于其他方法,在标准数据集中所有不同基窗口容量下检测到的结果均为最优,即EDR与MDR的取值同时达到最小甚至接近0.在真实数据集上,CD-TW方法除在极少数特定基窗口容量下性能与其他方法相同或略逊色之外(如在数据集USPS上,当ω=40时,本文提出的CD-TW方法要比SWCDS和DWCDS差),整体检测效果依然具有较为明显的优势,这充分说明本文方法可以更精准地捕捉到数据分布的缓慢变化,具有较强的渐变类概念漂移检测能力,在小样本学习中具有明显优势.

Fig. 6 EDR of sudden concept drift

Fig. 7 MDR of sudden concept drift
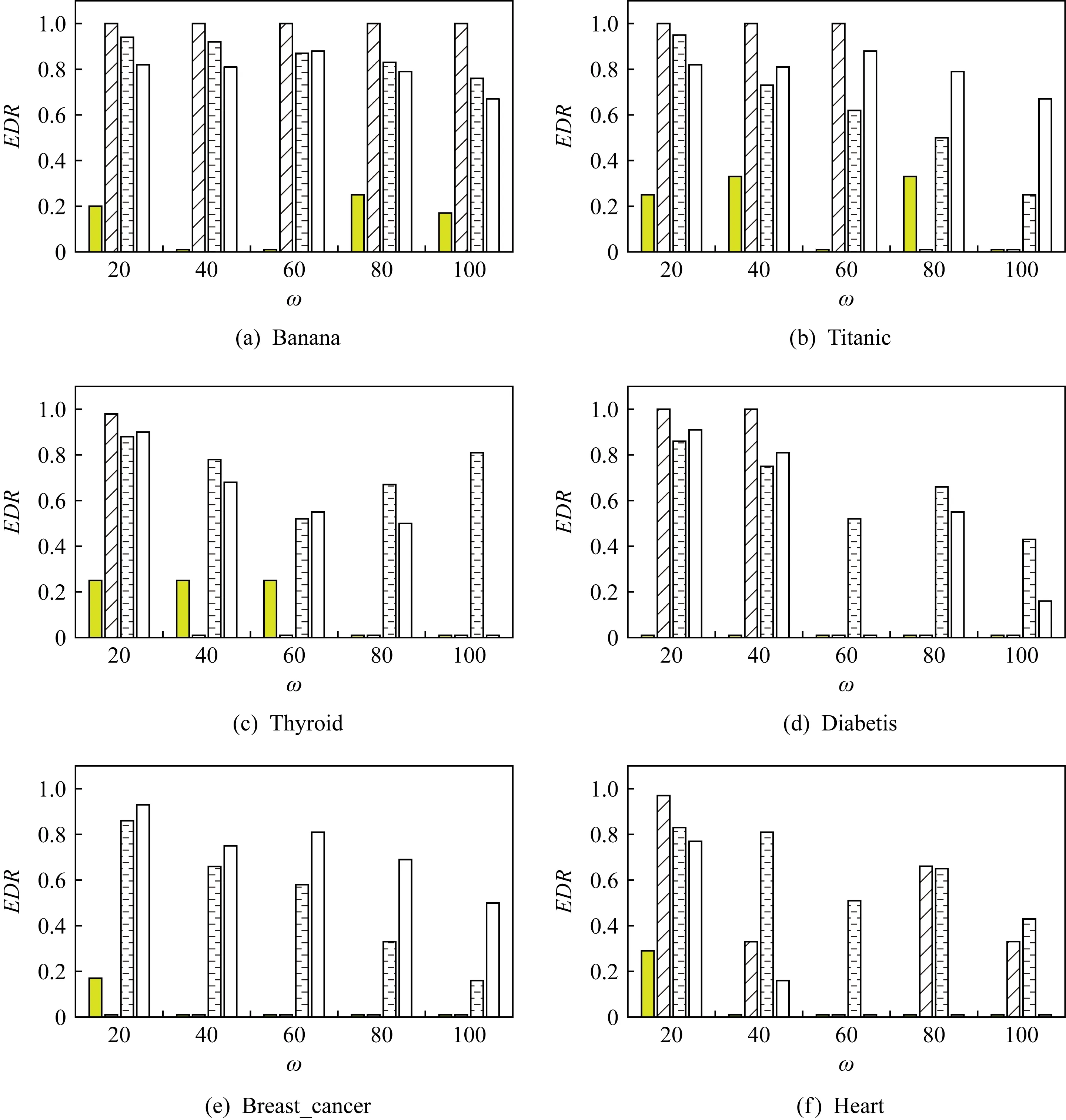
Fig. 8 EDR of gradual concept drift
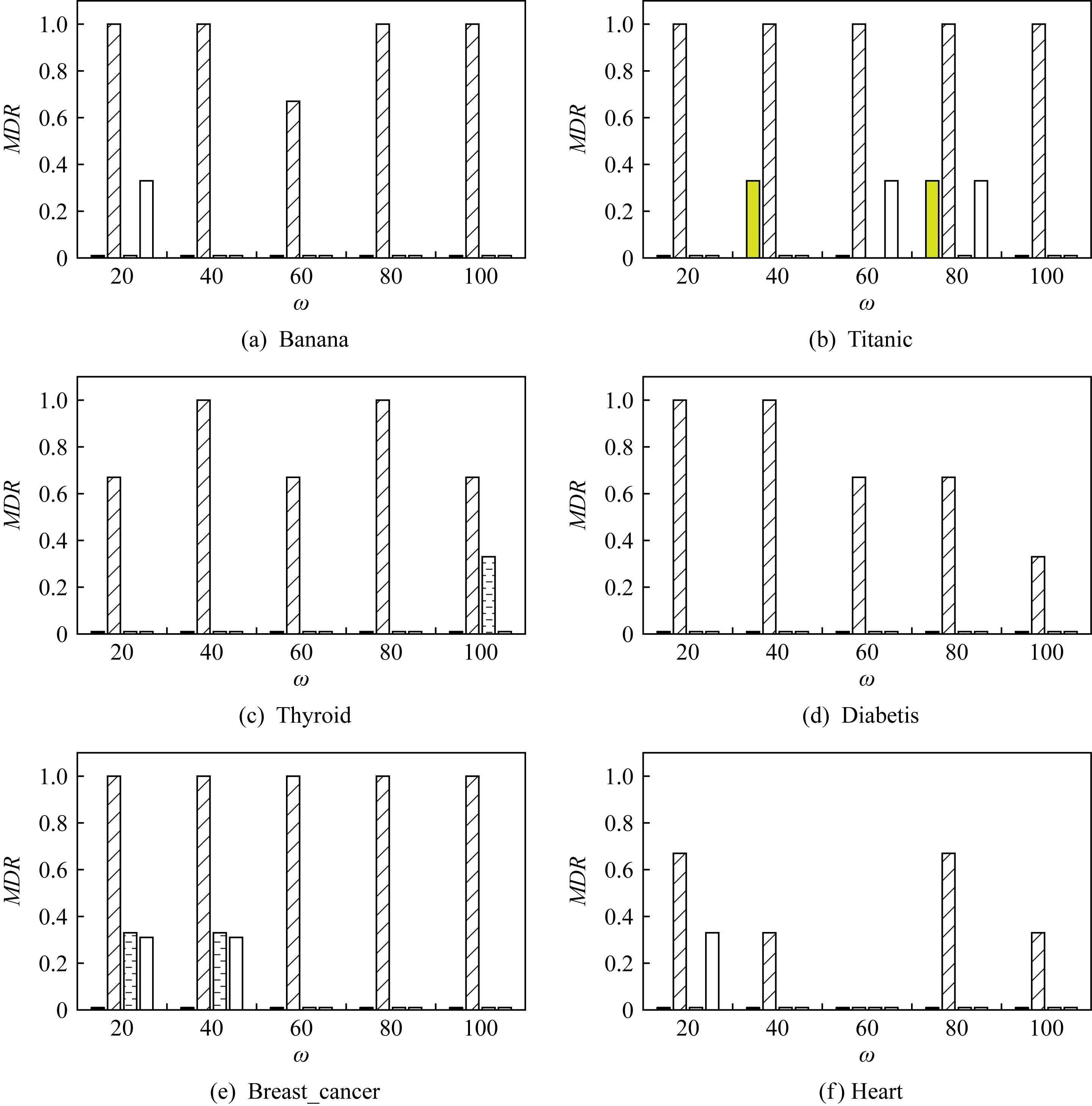
Fig. 9 MDR of gradual concept drift
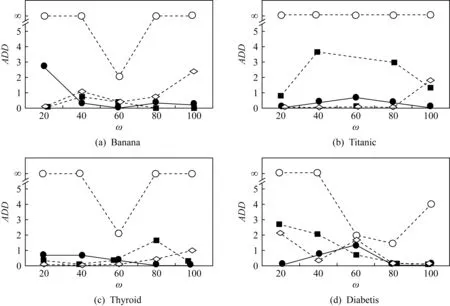
Fig. 10 ADD of gradual concept drift
图10为渐变类概念漂移节点检测的平均检测延时结果,所有正确检测到的渐变类概念漂移节点延时均不超过5,因此用“∞”表示没有检测到概念漂移.从图10中可以看出每个方法在检测渐变类概念漂移节点时都存在不同程度的延时,这是由于在漂移开始时刻大部分实例仍然服从旧分布,模型不能及时检测到数据流所发生的微小分布变化.CD-TW方法在标准数据集上的概念漂移节点平均延时在0~2之间,在真实数据集KDDCup99上,CD-TW对应的平均检测延时较大,这是由于此数据集服从旧分布的数据对于构建模型的影响可能更大,因此对新分布的检测比较迟缓,而在真实数据集USPS上,当ω=20时,没有准确检测到渐变类概念漂移.而SWCDS方法没有检测到渐变类概念漂移的情况很多,且检测到时所对应的平均延时也较大,说明该方法不适用于检测渐变类概念漂移,且在小样本学习背景下的检测效果很差;DWCDS方法检测到渐变类概念漂移节点的平均延时集中于0~3之间,在数据集USPS上则未检测到,因此其检测结果的实时性不好,且受数据流本身特性的影响较大;CDOL方法在大部分数据集上节点的延时集中于0~2之间,但其在KDDCup99数据集上全部未检测到.综上实验结果可以看出,本文提出的CD-TW方法对于渐变类漂移的检测更为有效准确.
3.4.2 概念漂移跨度检测
由于目前的漂移检测方法大多针对突变类概念漂移,因此几乎不涉及概念漂移跨度的检测,本文认为在渐变类概念漂移下,跨度蕴含数据分布的重要信息,因此实验中仅采用文中定义的指标对CD-TW方法进行漂移跨度检测分析,即采用缺失率(LR)和溢出率(FR)进行评估,如表3和表4所示.
从表3和表4中可以看出,突变类概念漂移不存在漂移跨度的任何缺失,这是由于本文所提出的CD-TW方法对于突变类概念漂移,只有在真实的概念漂移插入节点处检测到概念漂移才视为正确检测,而突变类概念漂移的跨度为1,因此不可能存在缺失,故仅包含检测到和检测不到这2种情况,但在个别数据集上存在跨度溢出,即检测到的概念漂移跨度大于1,这是由于小样本学习产生的波动被错误地当作数据分布的波动,但这种情形仅在少量数据集上存在.从整体上看,本文所提出的CD-TW方法对突变类概念漂移的跨度检测是较为准确的.对于渐变类概念漂移,几乎所有检测结果中都存在不同程度的漂移跨度缺失,但跨度溢出的情况则相对较少,这是由于在整个渐变类概念漂移跨度范围内,接近漂移起始节点处服从原始分布的数据占绝大多数,而接近漂移结束节点处时的大部分数据则服从新的分布,因此渐变类概念漂移的起始节点检测容易发生延迟,而结束节点检测则容易提前,即渐变类概念漂移跨度检测比较困难.此外,在多数数据集上,随着基窗口尺寸的增大,小样本学习对模型精度产生的波动强度逐渐减弱,故渐变类概念漂移跨度检测准确率呈现上升趋势,但当窗口增大到一定程度后,漂移跨度检测准确率几乎不再受到这种波动的干扰,因此准确率保持在一个稳定的水平.
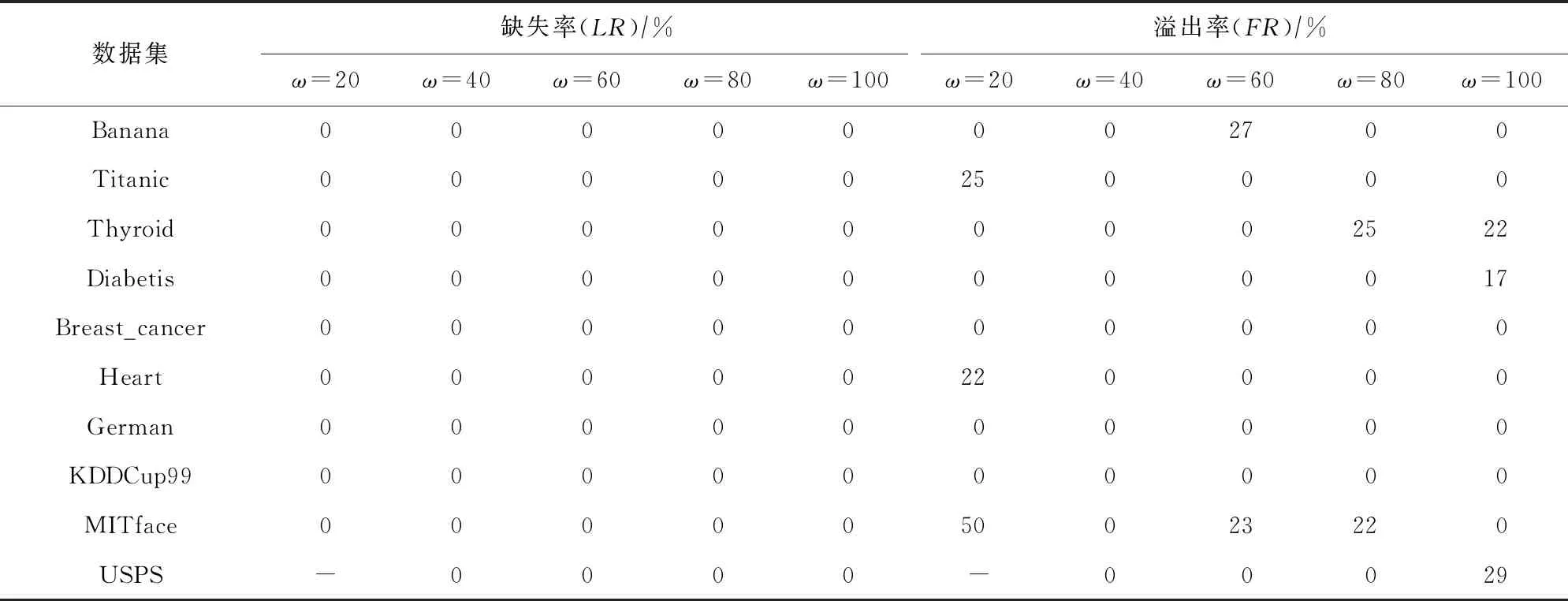
Table 3 LR and FR in Span Detection of Sudden Concept Drift
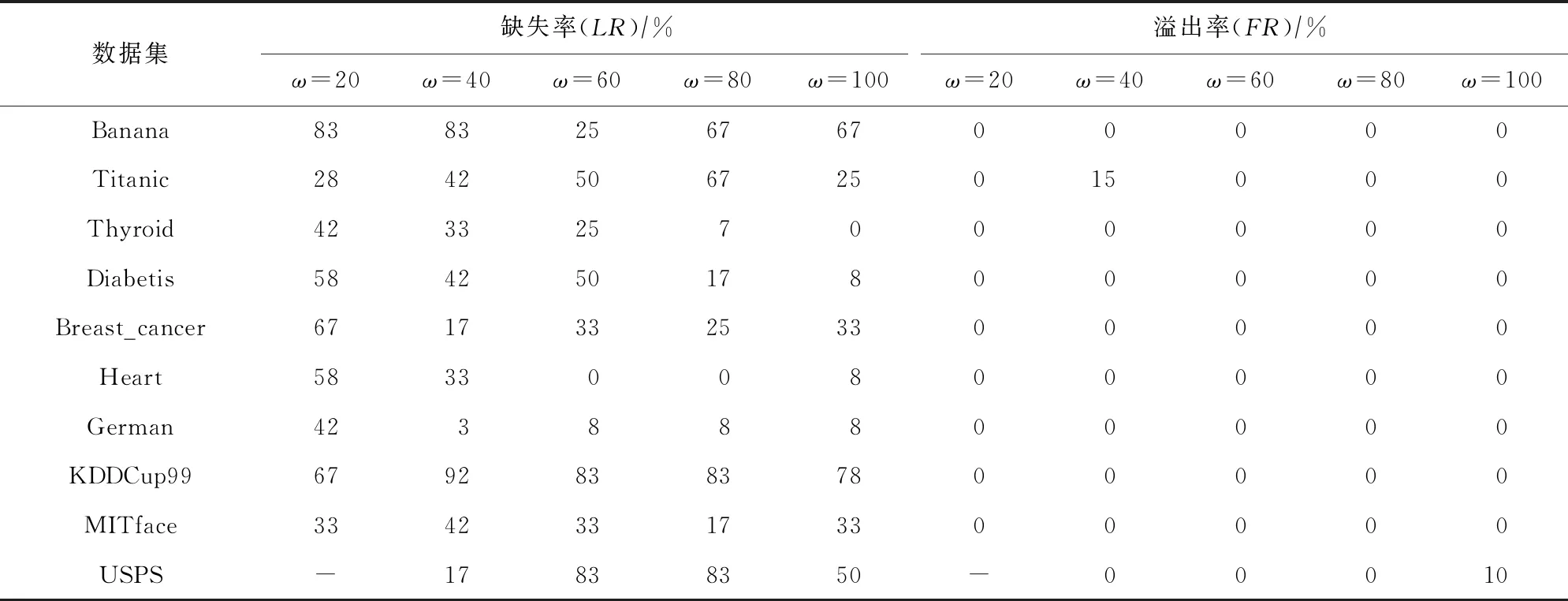
Table 4 LR and FR in Span Detection of Gradual Concept Drift
3.4.3 概念漂移类别检测
由于目前对概念漂移类别检测的研究较少,这里对本文提出的CD-TW方法在概念漂移类别检测结果的性能进行评估,表5为概念漂移类别检测结果.表5中Accs表示突变类概念漂移类别检测的准确率,Accg表示渐变类概念漂移类别检测的准确率.由于不同类别的概念漂移都是在流数据的前期、中期、后期节点处分别插入一个漂移节点进行模拟,因此每种类别的概念漂移类别检测的准确率就只有0,0.333,0.667,1这4种取值.
由表5可以看出,本文提出的CD-TW方法在标准数据集上对于概念漂移类别检测的准确率较高,其中突变环境下类别检测更为准确,而渐变环境下的类别检测准确率略低于突变类.在真实数据集上,类别划分精度平均精度约为62%,且对突变类概念漂移的类别检测情况整体上也略优于渐变类概念漂移.这是由于渐变类漂移跨度检测是通过跟踪数据分布的波动来实现的,而本文充分考虑小样本学习带来的波动并极力减小这种影响,故存在削弱数据概念波动的情形,因此会降低渐变类判断的准确度,从实验结果整体来看,本文提出的CD -TW方法可以在准确定位概念漂移节点的基础上,通过检测概念漂移的跨度,得到概念漂移的类别.
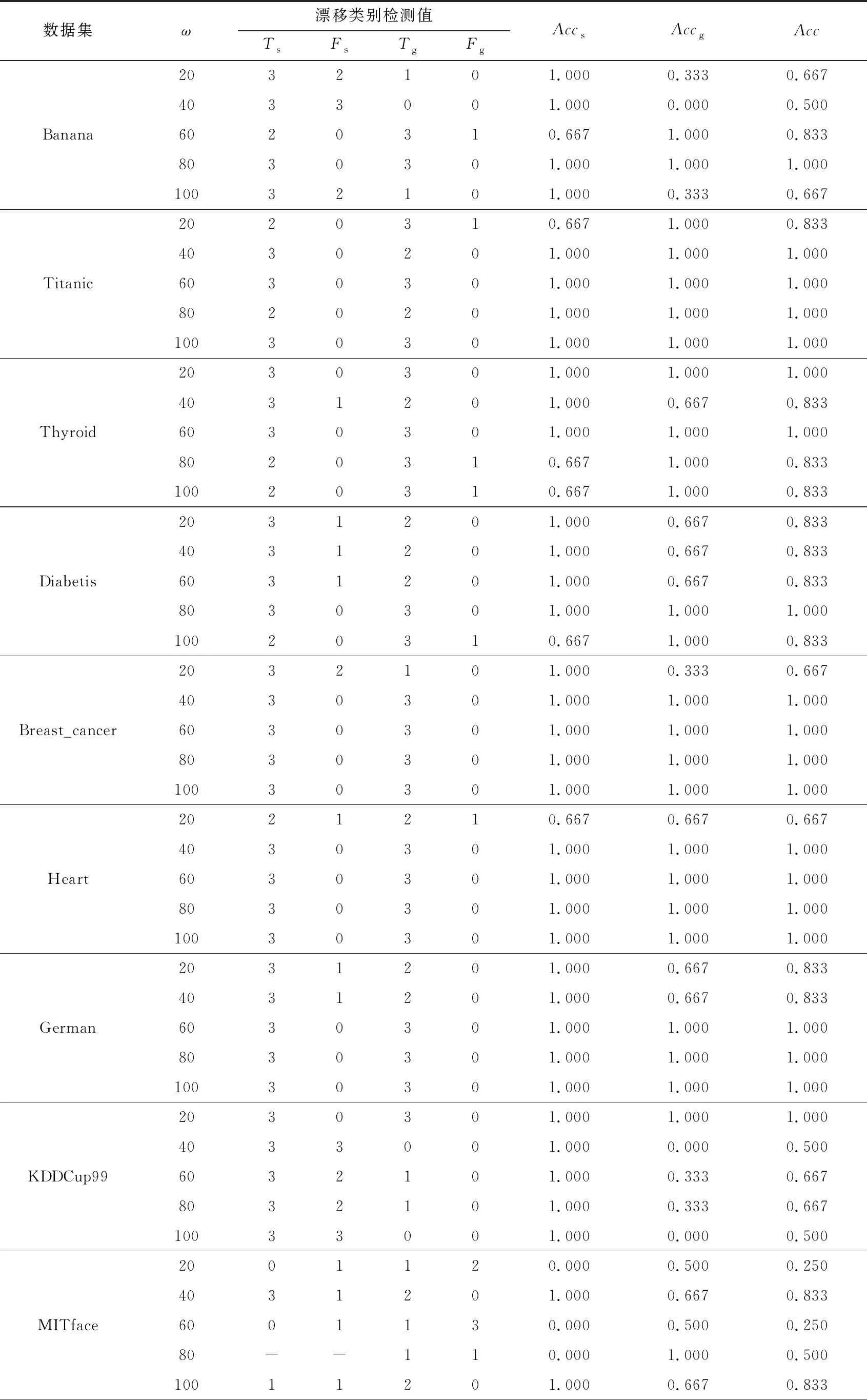
Table 5 Results of Concept Drift Class Judgment
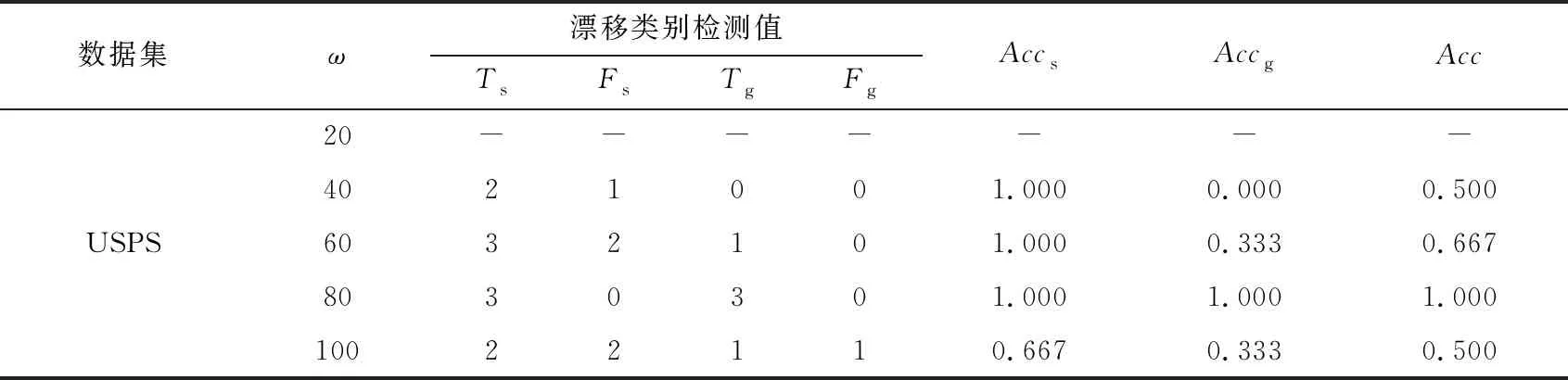
续表5
4 结束语
由于流数据中可能存在类别不同的概念漂移且不同类别概念漂移可能蕴含情况不等的重要信息,本文提出了一种基于时序窗口机制的概念漂移类别检测方法.首先通过将流数据划分时序单元,利用静态的参考基础节点时序窗口和滑动的基础节点时序窗口加载最新数据进行探测,实时检测概念漂移节点;然后利用跨度时序窗口加载概念漂移节点之后的数据,分析其分布情况的稳定性以得到概念漂移跨度;最后利用漂移跨度来检测概念漂移类别.本文所提方法可以较准确地检测流数据中的概念漂移节点,同时对不同类别概念漂移具有较强的识别能力,可为流数据的精准分析挖掘提供有意义的指导.
作者贡献声明:郭虎升负责思想提出、方法设计、代码实现、初稿写作及论文修改;任巧燕负责代码实现、数据测试及初稿写作;王文剑负责思想设计、写作指导、修改审定及基金资助.
