基于聚类算法的防窃电监测与辨识
2022-01-17袁于程谢晨旸
袁于程,黄 健,谢晨旸
(江苏林洋能源股份有限公司,江苏 启东 226200)
0 引言
随着我国经济实力的不断提高,居民用电量的需求也在逐年增加。在巨大经济利益的诱惑下,一些电力用户不惜触犯用电相关法律与法规进行窃电。窃电行为严重影响计量的准确性,不仅使电力公司蒙受巨大的经济损失,而且直接影响电网的安全与正常运行。同时,随着防窃电技术的不断提升,用户窃电的手段也悄然发生变化,呈现高科技、高隐蔽等特点[1]。
目前,检测用户窃电的方法主要有两种:①根据统计学方法计算线损、电阻以及非技术原因导致的损失;②使用互联网大数据进行检测以及通过智能网络人工智能(aritificial intelligence,AI)学习,如贝叶斯网络、构造决策树等[2-3]。这些方法都存在着一些缺点。第一种方法不能精确推算电网中的拓扑结构,从而不能精准定位窃电用户的位置。第二种方法则需要大量的样本数据作支持,以提升窃电的总体辨识有效率。但在判定模型训练和规则提取中,一般缺乏有效的窃电样本,同时缺少对于窃电用户的划定,因此存在着不足之处。针对上述2种方法的缺点,本文采用模糊C均值(fuzzy C-means,FCM)聚类算法分析用户的用电样本数据,从而寻找疑似窃电用户。
1 基于FCM聚类算法的原理与分类步骤
1.1 基于FCM聚类算法的原理
设数据集X={x1,x2,...,xn}。根据簇类数,将数据集X划分为c个簇,V={v1,v2,...,vc}表示聚类中心[4]。假设X的子集X1含有p个特征点,则可表示成1×p的矩阵,同理X2、X3、...、Xn亦可表示成1×p的矩阵,则X可表示成n×p的矩阵;V1含有p个特征点,则可表示成1×p的矩阵,同理可推得V2、V3、...、Vc亦可表示成1×p的矩阵,则V可表示成c×p的矩阵。
(1)

(2)
聚类中心的计算公式如下:
(3)
隶属度uij的计算公式如下:
(4)
目标函数如式(5)所示:
(5)
1.2 基于FCM聚类算法的分类
①参数初始化因子:模糊加权指数m(m=2)、聚类个数c(最终生成的特征曲线数)、迭代不成立时的阀值、包含随机数初始化的隶属度矩阵U。
②已知Xj、模糊加权指数m以及U,根据式(3)可推导出新的聚类中心V。
③已知Xi、模糊加权指数m和步骤②中获得的聚类中心V,可根据式(4)计算出更新后的隶属度矩阵。
④运算式(5)目标函数Jk(U,D)。其中,Jk表示运算迭代k次数的目标函数。若当前相邻两次目标函数Jk、Jk-1之差的绝对值小于迭代不成立时的阀值,则跳出循环计算公式;若当前相邻两次目标函数Jk、Jk-1之差的绝对值大于等于迭代不成立时的阀值,则跳转到步骤②重复计算。
⑤根据隶属度矩阵对所有样本空间用户数据X进行分类。若当前样本空间用户数据Xi对第k个簇的隶属度最大,则表明用户数据属于第k个簇。
2 用户负荷曲线分类
2.1 用户负荷曲线简介
用户的用电负荷是指用户处于某个特定的时间段内所有用电量的总和。不同类型的用户用电负荷随着时间变化,在某个月、某个季度、某一年都可存在差异,甚至在某一天的某个时段电力负荷变化也比较明显。对一天24 h均匀地划分时间段,标出每个时间段的电力负荷大小,然后将各独立点连接成平滑的曲线。该曲线即可表示为用户负荷曲线[5]。用户负荷曲线按不同方法可分为不同类别。例如:按不同用户类型可分为居民用电、机关、企事业单位、发电厂负荷曲线;按不同时间可分为日、周、月、季度以及年负荷曲线。本文主要研究用户日负荷曲线,尽量减少对用户窃电辨识结果产生干扰的因素。以某天的0时0分为起始,设定采集一次用户数据的周期为15 min,则24 h内共采集96个用户用电负荷记录点。
2.2 基于FCM聚类算法的用户负荷曲线分类
用户负荷曲线的分类是将具有相同或类似用电习惯的用户放置到相同的类别中。负荷曲线常用分类算法主要包括K-means算法、FCM算法、自组织神经网络映射算法[6-7]等。其中,FCM算法的优点是在实时性、稳定度、准确性等方面均较为出色。
用户用电负荷曲线的分类过程包括聚类算法的选定与聚类参数的确定、聚类的操作和结果分析。基于FCM聚类算法的负荷曲线分类的流程如图1所示。
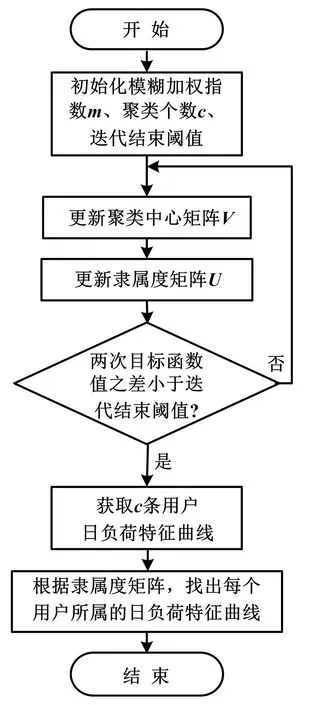
图1 基于FCM聚类算法的负荷曲线分类的流程图Fig.1 Flowchart of load curve classification based on FCM clustering methods
操作步骤如下。
①参数初始化因子典型值。一般m取值为2,使用FCM聚类算法和其他相关有效性指标,最终确定当前用户负荷曲线所需的最佳聚类数c为3,阀值T取值为0.01以及隶属度矩阵U的随机初始化。
②实例化用户曲线X以及用户特征曲线V。根据上述参数模糊加权指数m,聚类个数c,隶属度矩阵U。已知用户日负荷曲线X以及式(3),可更新聚类中心V。其中:X={X1,X2,...,Xn},任意子集Xk都包含96个用户用电负荷记录点;V={V1,V2,...,Vc},任意子集Vl都包含96个特征点。
③根据式(4)产生新的隶属度矩阵U。
④根据式(5)计算新的目标函数J(U,D)。若当前相邻两次目标函数Jk、Jk-1之差的绝对值小于迭代结束的阀值T,则跳出循环;否则,跳转到步骤③重复计算。
⑤一旦满足步骤④中的两次目标函数的绝对值小于迭代结束,可获取c条特征曲线。根据隶属度矩阵U,每条用户曲线Xi对应于c条特征曲线的隶属度之和为1。其中,隶属度最大的为用户曲线Xi对应的特征曲线。
3 窃电检测模型
3.1 基于相关系数的相似性考量
设当前用户用电的日负荷曲线表示为X=(x1,x2,...,x96),用户用电日负荷特征曲线表示为v=(v1,v2,...,v96),则用户日负荷特征曲线相关系数r可表示为:
(6)
其中:
(7)
相关系数r重点在于考量用户用电的日负荷曲线的形状和变化趋势,以免造成仅通过欧几里得距离判断用户用电负荷曲线的相似性而无法正确辨别可疑窃电用户的问题[8]。
3.2 基于欧几里得距离的相似性考量
用户用电的日负荷曲线与用电日负荷特征曲线间的欧几里得距离为:
(8)
3.3 疑似窃电用户筛选
窃电检测模型如图2所示。
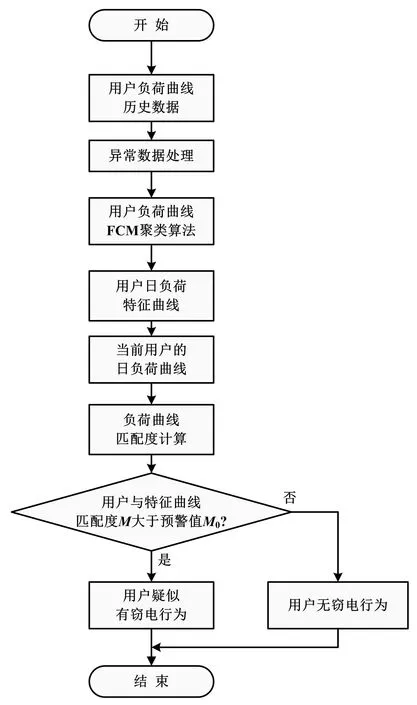
图2 窃电检测模型Fig.2 Detection model of electric larceny
从数据库系统中检索相应时段的用户用电负荷数据,并进行异常处理。其主要目的是提前过滤掉一些无意义并且对试验结果产生不良影响的数据。提取足够样本数的用户日负荷曲线以及通过上述FCM聚类算法,便可提取用户日负荷特征曲线。
用户用电负荷曲线与时间存在紧密联系,可使用基于时间的相似性来计算两条负荷曲线的匹配度。通过式(6)、式(7)和式(8),可分别计算相关系数r以及欧几里得距离d。相关系数r侧重于考量用户用电日负荷特征曲线的形状与变化趋势,避免仅通过欧几里得距离误判负荷曲线相似性从而无法正确辨别可疑用户;欧几里得距离的重点在于考量值的相似性。计算用户用电负荷曲线与用电负荷特征曲线的匹配度:
m=w1r+w2e-d
(9)
式中:w1和w2分别为权重因子,w1+w2=1。
通过不断地调整w1和w2的取值,最终可得到一个匹配度典型值M0。
在已知某一个用户的用户日负荷曲线和用户日负荷特征曲线的前提下,可计算当前用户日负荷曲线与特征曲线的匹配度M。若匹配度M小于等于预警值M0,则判断用户用电正常,无窃电行为;若匹配度M大于预警值M0,则判定当前用户疑似有窃电行为[9-10]。
4 MATLAB仿真验证结果
MATLAB仿真在模糊加权指数m=2、聚类个数c=3、迭代结束阀值T=10-2的初始化条件下进行。其中,隶属度矩阵U使用随机数初始化。选取三类具有典型特征的用户日负荷曲线各4条。隶属度矩阵U的随机初始化值和终值如表1所示。
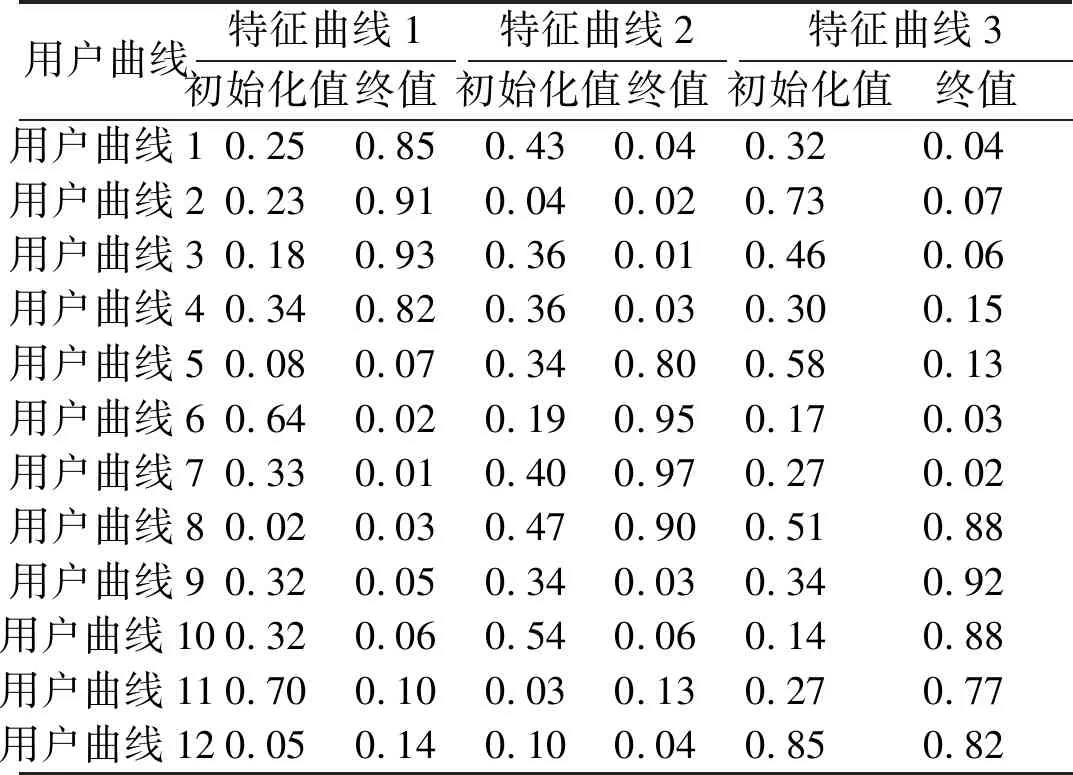
表1 隶属度矩阵U的随机初始化值和终值Tab.1 Random initialization value and final value of membership matrix U
用户曲线1~4表示第一类用户日负荷曲线,其特点为早上8点~晚上9点处于用电高峰;用户曲线5~8表示第二类用户日负荷曲线,其特点为早、中、晚三段时间处于用电高峰并且单位时间内用电量波动较大,存在用电尖峰;用户曲线9~12表示第三类用户日负荷曲线,即早、中、晚三段时间处于用电高峰并且单位时间内用电量波动较小,不存在用电尖峰。
由表1可推导出某一条用户日负荷曲线Xi隶属于日负荷特征曲线V的隶属度之和为1。若Xi属于某条日负荷特征曲线Vk隶属度的值最大,则Xi属于该条日负荷特征曲线Vk。由聚类算法获得的日负荷特征曲线如图3所示。其中,用户曲线1~4属于日负荷特征曲线1,用户曲线5~8属于日负荷特征曲线2,用户曲线9~12属于日负荷特征曲线3。

图3 由聚类算法获得的日负荷特征曲线Fig.3 Daily load characteristic curves based on clustering methods
特征曲线到用户曲线的欧几里得距离之和如图4所示。由图4可推出:随着迭代次数的增加,所有特征曲线到各用户曲线的欧几里得距离之和最终稳定在一个固定值。

图4 特征曲线到用户负荷曲线的欧几里得距离之和Fig.4 Sum of Euclidean distance from characteristic curve to customer curve
5 结论
本文首先使用FCM聚类算法完成不同类型用户用电负荷曲线的分类,以得到不同类型用户的负荷特征曲线,为判定疑似有窃电行为的用户提供依据。其次,运算匹配当前用户负荷曲线隶属于哪条负荷特征曲线,筛选出疑似存在窃电行为的用户。当然,本文研究仍需要不断优化。例如:可进一步细化由FCM聚类算法得到不同类别的用户负荷特征曲线,按照时间变化、行业变化、地理位置差异化等因素进行详细分类;需要进一步完善窃电特征曲线库,优化用户窃电的检测模型以及充分考虑用户类别、时间、地理位置差异化等因素影响,不定期对用户窃电的检测模型进行动态更新。
