基于LSTM和注意力机制的Minist手写数字识别算法设计
2022-01-17栾迪周广证
栾迪,周广证
(南京理工大学紫金学院 计算机学院,江苏 南京 210046)
0 引言
手写数字识别目前得到了广泛的研究,例如,如果能对学生的日常作业及试卷做出高质量的自动识别,做到线上自动批阅或者判分,将大大提高教师的工作效率和质量。本文将尝试使用LSTM网络(long-short term memory network,长短时记忆网络)结合注意力机制对Minist数据集进行识别。Minist数据集是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集,是NIST数据库的一个子集。每个样本都是一张28×28像素的灰度手写数字图片,且每个样本都对应着一个唯一的标签[1-2]。
LSTM是当前最有效的基于长时记忆的神经网络识别算法。它是对RNN(Recurrent Neural Network,循环神经网络)的改进,LSTM和RNN一般用来处理序列信息,在文本、语音、视频等具有上下文关联的识别和预测场景中识别精度很高。本文将手写数字的图像看作以行为单位的数据,对于特定的数字,各行之间的信息显然具有强相关的联系。LSTM在接收当前行信息时,将之前的所有行信息都传递过来进行识别输出,有效利用了上下文信息[3-4]。但任一行对当前行的影响概率却没有明显差别,这是不合理的。当前行和与当前行联系紧密的行信息显然应该具有更大的权值,注意力机制通过按信息关联的强度分配不同权重的方法,可以解决这个问题。
综上所述,本文设计了基于LSTM和注意力机制的Minist手写数字识别算法。手写数字信息保存为28×28的矩阵,每张图片按行输入LSTM网络,通过注意力机制调节权值来确定输入的所有行信息对当前输出的影响概率。
1 RNN及LSTM
RNN是循环神经网络,简单的RNN结构如图1所示,包含一个输入层、一个隐藏层、一个输出层。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
将图1的循环层按时间步展开的结构如图2所示。图中,Xt为当前时刻的输入,Ot为当前时刻的输出,St为隐藏层的当前值。
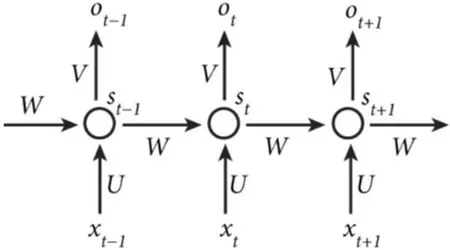
图2 RNN权值
RNN在任意时刻的神经元结构都是相同的。不仅如此,其在不同时刻传递时的对应位置的权值也是共享的,图中不同时刻的权值W、U、V采用的都是同一矩阵,其意义也是显而易见的,即在前面信息中学习到的特征可以移植给后面的网络直接使用。公式如下:
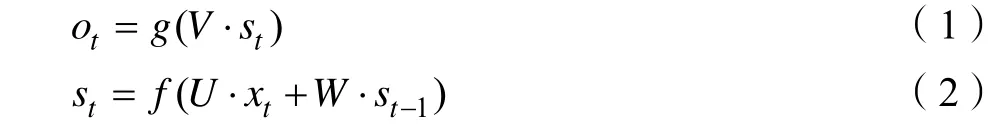
RNN在反向传播时面临着梯度消失和梯度爆炸的问题,而且对于相当长度的前文信息来说,其有效性大大降低。LSTM解决了这几个问题,其结构如图3所示。LSTM由遗忘门、输入门和输出门三个控制门组成。遗忘门控制上一时刻的单元状态Ct-1有多少保留到当前状态Ct,输入门控制当前时刻的网络输入Xt有多少保存到单元状态Ct,输出门控制单元状态Ct有多少输出到LSTM网络的当前输出ht。图中σ表示sigmoid函数,其取值范围是[0-1],决定了门控制器能够通过信息的比例。sigmoid取值为1时,表示所有信息都能通过,完全保留这一分支的记忆,取值为0时,表示没有信息能够通过,即所有信息全部遗忘[5-6]。LSTM网络的主要计算公式如下:


图3 LSTM结构
2 注意力机制
人类的注意力机制能够利用有限的视觉信息处理资源,从大量信息中获取有价值的信息,极大地提高了视觉处理的效率。深度学习中的注意力机制受人类视觉注意力启发,能够从众多信息中抽选出对当前任务目标更为关键的信息。在Bahdanau等首次在机器翻译中引入注意力机制,并取得不错的效果之后,其在CNN(Convolutional Neural Network,卷积神经网络)抽取图像特征、RNN抽取序列信息特征等任务中都有广泛的应用[7-9]。
在深度学习中,注意力机制可以借助重要性权重向量来实现。在预测或推断目标值时,例如文本翻译中词与词之间的联系,可以用注意力向量来判断当前输出词与其他词的关联强度,然后对加权后的向量求和以逼近正确的标签值。简单来说,注意力机制就是分配权重,例如英文句子“She is wearing a red dress.”中,单词“wearing”和“dress”属于强相关关系,“is”和“dress”属于弱相关关系,注意力机制在预测“dress”时,就会给“wearing”赋予较高权重,给“is”赋予较低权重。
3 算法设计及实验结果
本实验的算法设计和实验流程如图4所示。首先下载Minist数据集,将输入数据X保存为28×28的矩阵并做归一化处理,标签数据Y转化为独热编码表示。然后通过Keras搭建LSTM网络,加入注意力机制层,最后将训练集按epoch喂入网络进行参数训练,并通过测试集测试训练效果。
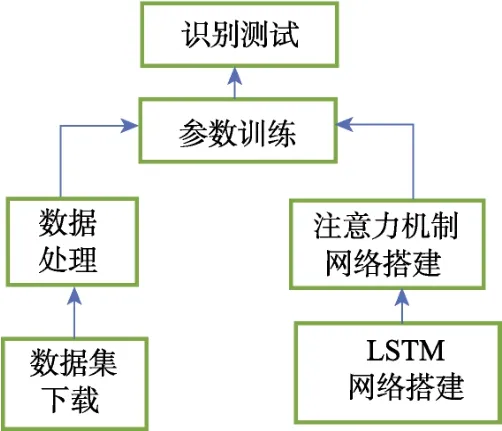
图4 手写数字识别流程图
训练集设置了10个epoch,为防止过拟合,设置了dropout率为0.25,实验最终准确率为0.984,测试集准确率为0.9878。为了对比,将注意力机制层去掉,仅使用LSTM网络进行训练和测试,训练集经过10个epoch后,准确率为0.9599,20个epoch后为0.9719,测试集准确率为0.9789。对比实验结果发现,在损失率和准确率的表现上,注意力机制的作用效果都很明显。两次实验结果如下:

4 结论
LSTM和注意力机制都是当前研究的热点,有广阔的发展前景。相对于传统的深度识别算法,循环神经网络能够处理序列数据信息的上下文关系,LSTM又改进了普通RNN模型的长时依赖以及梯度消失和梯度爆炸问题。在上下文信息的依赖关系上,由注意力机制分配权重以保证最有价值的输入数据影响最终输出结果。实验表明,LSTM结合注意力机制模型的识别率效果非常好。本实验将进一步挖掘该模型的应用领域,在序列信息处理时,例如文本的上下文、视频上下帧的分析和预测等,能够发挥LSTM和注意力机制的强大优势,取得满意的应用效果。
