汉彝双语应急语言资源智能查询平台的构建与技术实现
2022-01-15马瑞祾王成平沙马拉毅
马瑞祾,王成平,沙马拉毅
(1.西南民族大学中国语言文学学院,四川 成都 610041;2.西南民族大学民族语言文字信息处理重点实验室,四川 成都 610041)
突发公共事件的预防和处置是国家治理体系和治理能力现代化的重要标志.语言在应急和减灾中发挥着不容忽视的作用:第一,语言是信息传递的重要载体,信息是应急决策和抗灾施救的必需基础和核心要素[2].第二,语言是应急必需的社会资源,防治灾害的各阶段、各环节都离不开对语言资源的合理配置.第三,语言是处置灾害的特殊战力,应急语言服务及产品的有效供给能为灾害处置、安全维护和社会治理助力添翼[3].灾害的防治规划、监测预警、应急救援、恢复重建均需要高效率和高质量的应急语言服务撑持.国家、团体、个人在应对和处置公共突发事件时应积极树立“语言减灾”的观念[4-8].
和谐稳定的社会生活有助于促进各民族的交往交流交融,增强各族人民的凝聚力、向心力,铸牢中华民族共同体意识.中国少数民族聚居的西部地区往往呈现出地形特征复杂、灾害疾病频发、公共设施薄弱、语言类型多样的特点.在多次突发公共事件的处置过程中,各民族的语言差异和信息屏障是造成应急救援困难的重要因素.为打破现实窘境,除了坚定不移地在民族地区深化普及国家通用语言文字外,还应为民族同胞提供符合其语言能力和需求的应急语言服务.
在国家2021年颁布的“十四五”规划中明确指出:“强化数字技术在公共卫生、自然灾害、事故灾难、社会安全等突发公共事件应对中的运用,全面提升预警和应急处置能力”[1].随着现代信息技术的不断发展和对人类社会的持续赋能,探索语言技术在民族地区应急管理实践中的应用路径和实施方案具有重要意义.通过构建汉彝双语应急语言资源智能查询平台能为以凉山州为代表的民族地区在应对各类灾害时的医患沟通、信息检索、智能翻译等提供语言技术和资源的支持,助推民族地区提升应对和处置突发公共事件的现代化能力和水平.
1 汉彝双语应急语言资源智能查询平台的构建思路
1.1 需求分析
用户需求分析能明晰平台的搭建目的、服务内容和主体功能.汉彝双语应急语言资源智能查询平台是为满足不同应急主体在处置突发公共事件时产生的双语资源需求.根据突发事件的不同阶段具体需求如下:
第一,“备急”需求:为制定应急语言规划与政策提供参考,特别是为研制《简明汉语(彝语版)》提供语料参考.助力地方政府、学校开展双语防灾知识教育,普及和推广国家通用语言文字,规范公共空间语言景观(应急标识)的语言文字使用.扩容现有双语资源库的语料数据规模,推动彝语言文字信息处理走向精细化、专业化.
第二,“应急”需求:满足地方政府编制应急手册、视频、横幅、挂图等应急产品的翻译需求;为地方的双语媒体报道、语言舆情监测提供语料支撑;解决汉、彝语际沟通障碍造成的医患会话问题;为灾害处置和救援提供一批召之即来、素质过硬的双语志愿者.
第三,“善后”需求:为灾后开展心理诊疗咨询、语言康复训练、救援物资输送等环节中的双语翻译提供技术辅助.
1.2 技术路线
为满足多元的应急语言服务需求,需研发一个具有信息检索、结果可视化、数据下载、智能翻译、动态管理多功能为一体的智能查询平台,并依托Web网络服务端实现应急语言服务资源的发布、检索、管理,提高应急语言资源的共享性和使用率.
查询平台的构建分为七个主要步骤:第一,确定应急语言资源库所需的语言数据类型、规模和获取渠道.第二,从多源异构数据中获取所需的语言资源.第三,通过数据清洗、文本聚类、数据挖掘等方式获取各类应急领域、应急事件的词语、句子、语篇、标识等汉语资源数据.第四,将获取的汉语数据对照翻译为彝语,得到彝语数据,并将二者存储到MySQL数据库中.第五,基于本体建模的方式将资源库中的词汇术语数据生成动态知识图谱,存储到Neo4j数据库中.第六,基于MySQL和Neo4j两个数据库中的语言资源构建智能查询平台.第七,将智能平台的不同功能应用于处置突发公共事件的各类场景中.平台构建的技术路线见图1.

图1 智能查询平台构建的技术路线Fig.1 The technical route of the intelligent query platform construction
2 汉彝双语应急语言资源库的设计与构建
2.1 资源库概念结构设计
实现智能化查询需依靠大规模、高质量、广领域的语言资源和语言数据.由此,构建应急语言资源库是先导性、基础性的工作.汉彝双语应急语言资源库的设计遵循概念单一化原则[9].为提升不同语言资源应用的针对性和管理维护工作的便捷性,在设计资源库时根据用户需求和数据类型将不同语言资源分置于五个不同子库中,即“词汇术语库”“诊疗语句库”“政务语篇库”“应急标识库”“双语志愿者服务团库”.
ER模型是最为通用的“实体关系”概念模型,运用ER图(实体关系图)展示资源库与5个子库(实体)间的联系,以及各子库包含的不同键值属性.通过建立资源库的整体概念结构模型,完成资源库结构关系的抽象,模型结构如图2所示.

图2 汉彝双语资源库组织结构ER图Fig.2 ER diagram of the organization structure of the Chinese-Yi bilingual resource database
2.2 资源库数据表结构设计
MySQL相较于大型数据库管理系统,虽数据存储规模有限,但又具有运行速度快、可移植性强、易于学习、接口丰富、共享性高等优势.另外,MySQL不仅提供了多种编程语言的API,且其网络化的特点大大提高了数据在因特网中的共享效率.因此,该资源库的搭建采用MySQL的数据关系管理系统.
数据表(Table)是数据库的基础和核心.数据库表是系列二位数组的集合,是存储数据和操作数据的逻辑结构;表通常由表结构和表内容(记录)两个部分组成,建立存储数据的基本表结构是实现应急汉彝双语资源的数据库化的最终环节.首先,根据“一事一地”的原则确定该资源库中共含7张数据表,即不同表描述不同实体(词汇、句子、语篇、标识、志愿者),且表内只包含与该主题相关的信息,不包含重复信息.其次,根据概念设计确定各表中的相应字段.最后,选定主键和外键字段,建立表与表间的关系.本库不同语料要素的数据类型如表1所示.

表1 资源库语料要素数据表结构Table 1 Table structure of the corpus elements of the resource database
2.3 数据库构建的关键技术
2.3.1 汉语数据获取
应急领域资源库的数据源十分多样,呈现出复杂的多源异构特征.主要包括以下三类:应急领域的已有数据库等结构化数据,应急管理部门官方网站中发布的文件信息等半结构化数据,以及《抗击疫情湖北方言通》《疫情防控外语通》等相关专业书籍、手册等文本类非结构化数据.首先,通过Python语言对应急管理部、国家减灾委办公室、凉山州卫健委等政府部门的官方网站公开发布的信息(标题和正文)进行批量爬取,再将爬取的半结构化数据转换为文本(txt.)格式.其次,通过文字识别的方式将文献、书籍、读物中的文字转换为文本信息,共获取各类语料来源文本2 833篇,含1 678 228字符.最后,将其存储到生语料库中,作为构建资源库的数据源.
2.3.2 数据清洗
对获取的生语料进行预处理:第一,运用Editplus工具对文本进行降噪(Emeditor),删除回车和空格.第二,使用Jieba分词软件对文本进行词语切分,对分词结果进行人工校对.将机构名称、专业术语处理为一个分词单位,如“发热门诊”“传染病”“传染源”等.第三,在分词过程中会出现部分质量低、不准确、不完整的噪声数据,需要剔除数据集中的残缺、重复、无用、冗余、错误数据以及停用词.
2.3.3 文本聚类
文本聚类是将数据集中主题相同或相似的文本分为若干个不相交的子集,各子集是一个簇(cluster).调用CountVectorizer()函数对清洗后的数据进行特征提取,生成词频矩阵X,计算出词汇的TFIDF值,公式如下:
TF-IDF(X)=TF(X)*IDF(X). (1)
公式(1)中,TF(X)指词X在当前文本中的词频,IDF(X)表示词X的逆文档率.应用K-means聚类方法对文本进行主题聚类,在聚类参数上参考文献提出的分类标准[10],首先划分自然灾害和人为灾害两大灾害领域,根据不同致灾因子将自然灾害细分地质、海洋、生物等5种灾害类型;再根据不同灾害源将人为灾害细分为生态环境灾害、公共卫生事件等4种灾害类型,故将聚类簇数n_clusters设为9.最后,对文本进行降维处理,绘制可视化的聚类图形[11].
2.3.4 汉语数据入库
第一,“词汇术语库”的数据处理:基于文本聚类结果,分类统计出各应急事件词语的词频和词次,将各灾类中的前100个高频词导入excel表格,并人工筛选出各灾类中的通用词.如“公共卫生事件”中“病史、处方、病例”等均为该灾类的通用词.根据分类叠合和词频计算,统计出自然、人为灾害均可通用的词汇.最后,将语料按类分装于应急通用词表、自然灾害词表、人为灾害词表3个数据表中,共计收录2 000条应急词汇术语.不同词表中的词条数目情况如表2所示.每个词条均由普通话水平等级为一乙的发音人录制音频文件.

表2 应急词汇术语库中的词条分布情况统计Table 2 Distribution of entries in the Emergency Vocabulary Database
第二,“诊疗语句库”的数据处理:确定医患沟通常用话题,如“病情描述”“处方建议”“病情诊断”等,再以《抗击疫情湖北方言通》和《疫情防控外语通》中的语句为参照,从数据集中统计出200句高频医患诊疗会话语句.语句尽量涵盖各类常用的医患交际话题.
第三,“政务语篇库”的数据处理:首先,根据不同主体部门和语篇主题将文本分为“通知公告类”“新闻报道”“健康须知”“知识科普”四类,分类遴选出典型的政务语篇文本.对语篇进行文本简化,简化标准参照《疫情防控“简明汉语”》中的标准和实例,结合《新HSK大纲词汇(1-6级)》,建立“简化词表”和“语句简化规则”.对照词表和规则对语篇中的专业术语和繁难句子进行人工标注和降级处理.过程中调用同义词在线检索平台和电子词典进行词语的等义替换.
第四,“应急标识库”的数据处理:从国家应急广播网中下载应急标识104个,包括“气象预警”44个、“求救信号”7个、“应急避难场所标识”16个、“警示标识”22个和“指令标识”15个,将标识的图片和内容储存到标识库中.
第五,“双语志愿者库”的数据处理:依托高校和地方相关窗口部门、公益组织招募汉彝双语志愿者325名,对志愿者信息(姓名、民族、专业等)进行统计和入库.
2.3.5 彝语语料翻译
彝语语料采用Unicode进行统一编码与处理,使资源库更具平台和应用程序的兼容性和共享性.Unicode突破了传统的字符编码方案的局限,对不同语言的不同字符均设有统一且唯一的二进制编码,较好地实现了跨语言、跨平台的文本信息处理.语料标注采用JSON这种轻量级的数据交换格式.
由于在现有的汉彝双语资源库中收录的应急领域的数据相对匮乏,难以实现机器自动翻译.因此,语料的对照翻译工作由彝语言和彝药专业的研究生按照彝语新词术语规范进行人工标注,再请相关专业的专家教授进行校审.对部分彝语中尚无对应词语的术语采用“暂时空缺”或“新造词语”的方式进行翻译.每条彝语词汇都配有母语者录制的规范彝语音频文件.最后,将标注好的语料导入数据库中,再交由相关专业领域的专家进行最终校审.
3 基于知识图谱的汉彝双语应急词汇术语可视化
3.1 知识图谱概说
知识图谱(Knowledge Graphs)于2012年由Google提出,随着人工智能技术的发展,知识图谱以其强大的语义处理和互联组织能力,广泛应用于搜索引擎、智能问答、个性化推荐等领域.知识图谱的特点是结构化,通常采取符号化(SPO三元组,S:头实体,P:关系,O:尾实体)的知识表示方式,并以有向图的形式进行呈现和存储.因此,知识图谱具有语义丰富、结构友好、易于理解等优点.为更好地存储和利用结构知识,人类分别构建了面向开放领域的通用型知识图谱和面向垂直领域型知识图谱[12].
3.2 汉彝双语应急领域词汇术语知识图谱的构建方式
本文所构建的是用以表示特定领域(应急)的语言知识图谱,需要凭借行业专家知识.因此,主要采用自顶向下的方式来构建知识本体.本体构建是为在获取某一领域的知识时,通过对该领域知识达成的共识来明晰概念间的关系,进而来描述概念的语义.本体模型的构建工具较为多样,本文主要使用斯坦福大学开发的本体编辑工具Protégé.该平台具有安装便捷、操作便利、功能强大的特点,且可以满足不同复杂程度图谱的构建需求.该图谱的节点与关系模型如表3所示,本体的可视化如图3所示.

图3 应急领域词汇术语知识图谱本体的可视化Fig.3 Visualization of the knowledge graph ontology of vocabulary terms in the emergency field

表3 词汇知识实体、关系模型Table 3 Vocabulary knowledge entity and relationship model
上图仅展示了部分词条(节点)的本体模型.图中蓝色(实线)线段表示Subclass(包含关系)的对象属性,黄色(虚线)线段表示Translate(翻译关系).
3.3 汉彝双语应急领域词汇术语关系的自动构建
通过Python实现(灾害领域,包括,灾害类型),(灾害类型,包括,汉语词汇),(汉语词汇,翻译,彝语词汇)三元组的自动构建系.以汉语实体和彝语实体为例,其自动构建的核心代码如下所示:


4 汉彝双语应急语言资源智能查询平台的应用
在完成对资源库的实验调试后,可将资源库投放至网络平台,分类向政府部门、公益组织、学术团体、个人志愿者等不同用户开放,功能系统如图4所示.
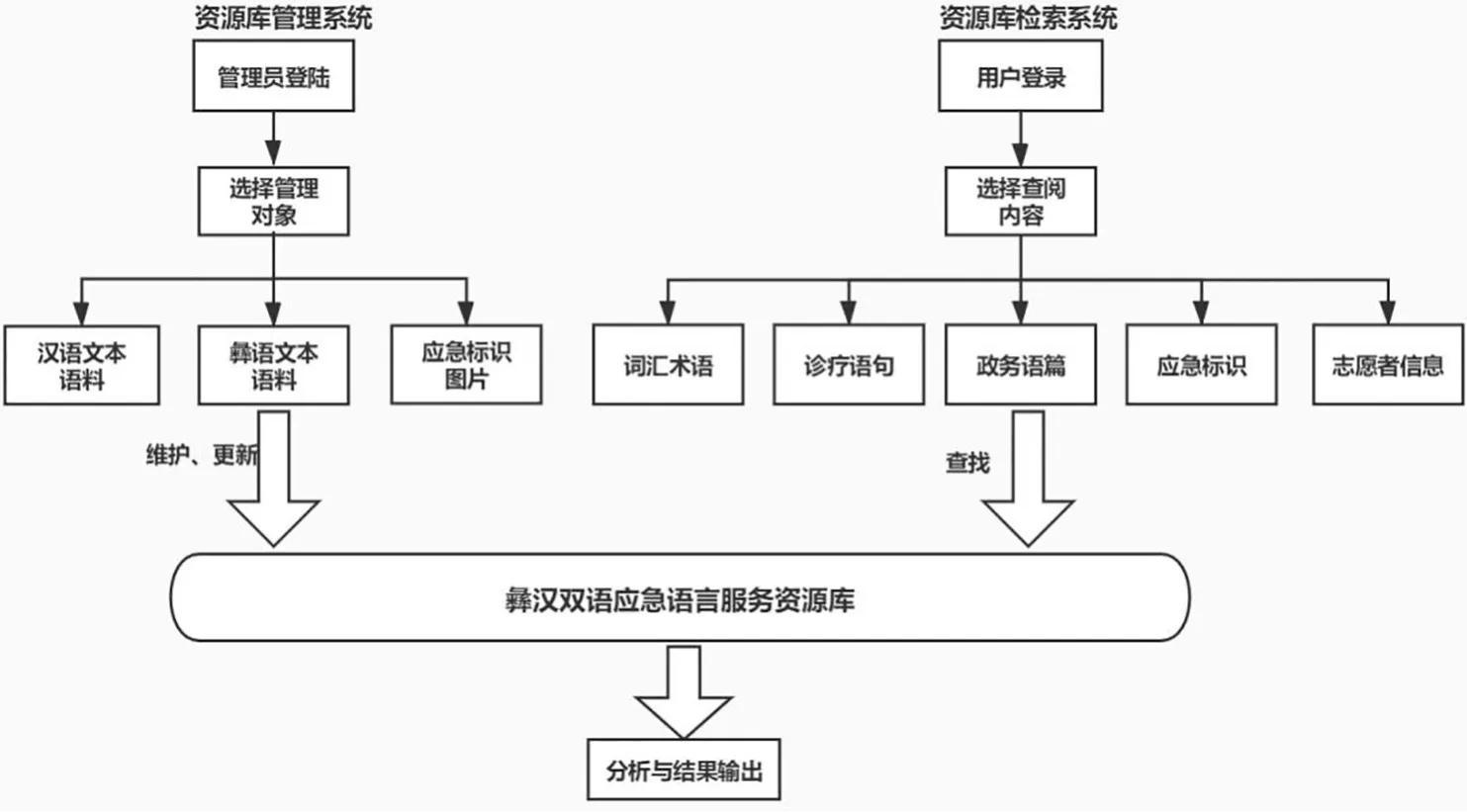
图4 应急语言资源查询平台的多功能系统Fig.4 Multifunctional system of bilingual emergency language resource database
4.1 智能信息检索
平台为用户提供了三种适需的智能检索路径:第一,用户可通过Web前端常用的交互方式对1至4子库中的文本数据(汉彝对照)进行检索.在查询平台的功能栏目中选中信息检索,输入“地震”,单击“查询”按钮,即可获得与该词条相关的标注信息和图谱(见图5).第二,用户可根据具体的灾害类型和服务内容,按需对深度加工的音频、图像、视频数据进行检索.第三,为保护志愿者的个人隐私,在子库5中添加隐藏项目设置,仅对政府相关部门的工作人员开放,并与政府部门签订保密协议.

图5 查询平台“地震”一词的检索结果展示Fig.5 Display of the search results of the word"earthquake"on the query platform
此外,该平台支持多种检索方式,包括字符串检索、标注检索、通配符检索、正则表达式检索、汉语语音输入检索、应急标识图片识别检索6种方式.多样化的方式为用户提供了较大的检索便利和良好的用户体验.
4.2 结果可视化
有别于传统的搜索引擎,用户使用平台检索不同灾害领域、类型汉彝双语词汇术语时能够生成相应的知识图谱.以“公共卫生”类灾害中的“传染病”领域的词条为例,其知识图谱如图6.查询结果可视化是将查询结果生成为相应词条的知识卡片,以“鼠疫”一词为例,知识卡片见图7.

图7 “鼠疫”一词的知识卡片Fig.7 Knowledge card of the"Plague"node
4.3 资料下载
为提升资源库中数据的适需性,根据用户的不同身份和需求对语料数据进行分类、分级拆分.根据与数据对应的不同用户类别,对5个子库定义不同的视图,视图里只有用户所在权限内的语料数据;子库1至4面向一般检索用户查询和下载,而子库5仅面向政府有特殊需求的政府窗口部门开放.对查询子库5信息的用户进行不同的管理与授权,用户需先通过身份认证,才能按相应的检索方式从后台数据库中调用相关信息.面向不同身份用户的数据下载方案如图8所示:

图8 面向不同用户视图的语料数据下载方案Fig.8 Corpus data download scheme for different user views
4.4 智能双语翻译
相较于文本词典和在线翻译软件,该平台是基于一定规模的词语、句子、篇章对齐的语料资源库,能够较好地实现汉语和彝语的机器翻译.此外,随着深度学习和知识图谱的普及,大规模的知识库是实现人机交互、智能翻译、智能问答的基础.该平台通过调用外部接口,实现汉语语音和图片的输入识别;并首次尝试将知识图谱概念引入彝文信息处理领域,为基于词向量和语义信息的智能化机器翻译奠定基础.
4.5 数据动态管理
为适配不断迭变的应急服务需求,该资源库采用动态管理的方式实现数据的存储和更新;当新的疾病名称术语出现或新的信息发布时,需要对资源库中的语料进行及时更新,其实现路径有两种:一是管理员定期进行维护,以人工的方式增删或修改语料数据;二是调用SQL Server 2019管理中的触发器功能,对各子库的数据表定义插入、删除和更新的触发器并预先设定事件,实现记录的自动更新或过滤.资源库的动态管理可以确保库中数据的时效性和真实性,提高双语应急语言资源库的实际价值.
5 总结与展望
在应对和处置突发公共事件时应急语言服务不能缺位,需得到充分地重视[13].语言技术是国家语言能力的重要衡量指标,语言技术的储备和语言资源的建设是应急语言服务的必需内容[14-16].未来,我们将进一步研发以国家通用语言文字为主体,多民族语言对照的“多语种应急语言资源库及智能查询平台”,并建立和完善资源库构建及管理规范,发挥语言智能技术在提升我国民族地区灾害防治能力的现代化、数字化水平的积极作用,维护国家安全、社会稳定,推进构筑中华民族共有精神家园,铸牢中华民族共同体意识.
