信息抽取技术及其发展
2022-01-15肖明,曾莉
肖 明,曾 莉
(1.西南民族大学计算机科学与工程学院,四川 成都 610041;2.西南民族大学数学学院,四川 成都 610041)
随着信息技术的不断发展,网络信息飞速增加,从网络获取信息资源变得更加快捷,传统搜索引擎能帮用户获得海量网页信息,但这还需要进行人工排查和筛选,在成千上万的反馈中去找寻所需的准确信息,犹如大海捞针.因此,信息的精准获取,已是信息处理的一项热点.信息抽取(Information Extraction,IE)的任务就是对海量的信息内容进行自动分类、提取和重构,转换为便于构建知识图谱或者能直接查询的结构化信息[1].由于当前网络信息的绝大多都以文本形式存在,所以当前信息抽取的主要研究范围是文本信息抽取(Text Information Extraction)[2].
从20世纪60年代,国外已有不少学者开始对自动信息抽取技术进行研究,从1987年到1998年,MUC(Message Understanding Conference,消息理解系列会议)[3]连续举办七届,MUC会议以其特有的信息抽取系统评测机制,推动IE技术不断向前发展.特别是在1995年举办的第六届MUC会议中,引入了多语种命名实体识别评测任务,除传统的英文语料外,中文、日文也参与评测.在1998年第七届MUC中,命名实体识别被具体化为人名、地名、机构名等七类实体的识别.从1999年起ACE(Automatic Content Extraction,自动内容抽取评测会议)[4]接力推动信息抽取技术的向前发展,不仅评测内容扩大,包含了实体检测、数值检测、关系检测和事件检测等多项内容,语料来源也从原来MUC的限定领域语料变为内容更为广泛的书面新闻语料,相应语料规模也大幅增加.从2009年开始,ACE被归入TAC(Text Analysis Conference,文本分析评测会议),评测任务纳入了实体链接和属性的抽取.
中文文本信息抽取研究起步相对较晚,20世纪90年代初期,学者们陆续对中文的通用命名实体进行了研究[4,6-8].如:宋柔使用规则来识别人名[4],孙茂松采用统计和概率识别人名[6],刘挺设计了一个基于信息抽取的自动文摘系统[7],而Zhang等人在ACL2000上演示了他们利用记忆学习算法获取规则的中文信息抽取系统[8].
1 信息抽取的任务
信息抽取目前的主要对象还是各类文本信息,其任务有:命名实体识别(Named Entity Recognition,NER)、命名实体消歧(Named Entity Disambiguation)、实体关系抽取(Entity Relation Extraction)和事件抽取(Extracting Events)[9].命名实体(Named Entity,NE)是指信息数据中的固有名称、缩写及其他唯一标识.命名实体识别是自然语言处理中的一项关键技术,是从文本信息句子中找出包括人名、地名、组织名等各类专有名词,并同时标注它们的类型.命名实体消歧根据上下文信息,确定有多个客观实体对应的命名实体,在此处指代的真实世界实体.如,“苹果”一词可以代表日常生活中的一种水果,也可以代表美国的一家高科技公司.命名实体消歧可分为基于聚类和基于实体链接的两类实体消歧方法.基于聚类的实体消歧的基本思想是通过指称项的上下文因素,利用聚类算法进行消歧.如,文本“今天苹果发布了新的手机”,可由其上下文中的“发布”“手机”通过相似度计算确定“苹果”对应到高科技公司.而基于实体链接的实体消歧是指先给定目标实体列表,然后计算指称项与各链接实体候选项的一致性分数,选择得分最高的候选项来实现消歧.实体关系抽取是指确定实体间的语义关系,关系抽取结果可以用三元组来表示,如,从“四川的省会是成都”中可抽取出三元组(四川,省会,成都).事件抽取是指从信息中抽出用户关注的事件,并将其转换为结构化的形式.事件抽取可分为事件识别任务和论元角色分类任务,事件识别任务是一个基于单词的多分类任务,它需识别出句子中的单词归属的事件类型,事件识别又可分为触发词(event trigger)识别、事件类型(event type)分类两项任务;论元角色分类任务是对句子中的触发词对和实体之间的角色关系进行判别,其进一步分为论元(event argument)识别和角色(argument role)分类任务两项任务.
2 信息抽取技术的发展
2.1 基于规则的阶段
命名实体识别最早在1995年的第六届MUC会议上被明确提出.实际上,早在20世纪90年代初,针对中文信息处理做分词处理时,由于出现大量的未登录词影响分词效果,国内很多学者就开始对中文专用名进行研究[4,6,8,10].早期的命名实体识别常采用基于规则的方法,一般由语言学专家先根据欲识别实体类型的特点,挑选出能代表某类实体的各类特征,如人名的姓氏用字,职位称呼等,构建有限的规则模板,再通过模式匹配的手段完成命名实体的抽取[4,6,11].这类系统大多依赖语言学专家领域知识,不仅耗时耗力,还不免会有遗漏.由此,也有学者尝试通过算法自动生成规则,Collins等[12]提出的DLCoTrain方法,就是通过对小规模的种子规则集不断迭代训练,滚动生成越来越多的规则.基于规则的方法存在着前期投入大、鲁棒性和移植性差、局限于特定领域的缺点.
最早的关系抽取是基于模式匹配的方法,它是通过定义文本中表达的字符、语法或者语义模式,将模式与文本的匹配作为主要手段,来实现关系实例的抽取.模式的来源可以由专家定义或者算法自动抽取,专家定义的模式质量精良,抽取准确率高,但成本高昂,召回率低.自动抽取模式方式采用滚雪球的方式实现模式抽取和实体抽取的循环迭代,其特点是自动、高效,但准确率不高.
2.2 统计学习阶段
随着机器学习发展,基于统计的机器学习也不断应用于信息抽取.此类方法中将文本中每个词的各类特征(如词法特征、词性标注,词义特征等)表达为一个特征向量,然后通过不同的模型方法对大规模的训练语料进行学习,最后通过学习好的模型来进行实体识别.常见的模型有:HMM(Hidden Markov Mode,隐马尔可夫模型)[13-14]、ME(Maxmium Entropy,最大熵)[15]、SVM(Support Vector Machine,支持向量机)[16-17]和CRF(Conditional Random Fields,条件随机场)[18-21].HMM是基于转换概率的模型,其基本思想是用前面的几个连续状态去预测当前状态.张华平等[14]在隐马尔可夫模型的基础上引入一种角色标注NER的方法,他们首先利用Viterbi算法,根据人名构成和统计信息,对词进行角色标注,然后再用最大模式匹配从训练语料库中自动识别人名,最终综合指标为95.4%.
实体关系抽取的本质是一个多分类问题,因此,各种分类学习方法均可应于实体关系抽取.归纳出来主要有两类,第一类是基于特征向量的方法,第二类是基于核函数的方法.基于特征向量的方法,首先预定义好需要抽取的关系类型,再根据训练语料中实体的词法、句法、实体间文本距离以及语义特征等构造特征向量,最后通过各种不同的机器学习分类模型进行关系抽取.基于核函数的方法不用明确给出计算对象的特征向量,它可以利用多种不同的数据组织形式,综合各方面的知识信息来表示实体关系,通过核函数的映射,在高维空间中完成实体关系的分类.Zelenko最先在文本的浅层解析表示的基础上,定义了一个多项式核函数用于关系抽取[22].刘克彬等人[23]借助知网提供的中文本体知识库构造语义核函数,取得不错的关系抽取效果.
2.3 深度学习阶段
近年来,随着词向量(Word Embedding)的引入,掀起了在自然语言处理中应用深度学习方法的高潮.Word2Vec是词向量的代表,它的基本思想是用具有统一维度的向量来表示模型中的每个词[24].这样不仅解决了高维度向量空间带来的数据稀疏问题,还能将更多语义特征融入其中,同时使异构文本能得到统一维度的向量特征表示.
Liu等[25]最早用CNN(Convolutional Neural Networks,卷积神经网络)来自动提取特征,它用词向量和词法特征进行对句子进行编码,然后接卷积层、全连接层、softmax层完成分类,它在ACE 2005数据集上比基于kernel的方法F1值提高了9%.Zeng等[26]使用预训练词向量和位置特征,还在CNN层后使用了最大池化层.Nguyen和Grishman[27]完全摈弃词法特征,让CNN自动学习,利用多窗口卷积获得不同尺度的n-gram信息,通过端到端的神经网络取得较好效果.2016年Wang等[28]提出了结合多级注意力机制(Attention)的CNN来实现关系抽取,其第一级Attention在输入层,计算所有词对目标实体的注意力大小,第二级Attention在CNN的输出部分,利用卷积操作将提取到的特征矩阵和目标关系嵌入矩阵,计算对于目标关系的注意力大小,再将计算结果和特征矩阵相乘,最后使用最大池操作得到目标的关系向量.
相比于传统的机器学习的方法,基于CNN的方法取得了不错的成绩,但CNN对于时序特征的抽取能力偏弱.而RNN(recurrent neural network,循环神经网络)模型则适合做时序特征的抽取.Zhang等[29]首次使用BRNN(Bidirectional RNN,双向循环神经网络)来进行关系抽取,BRNN相当于集成了前向和后向两个RNN,其先分别按照正向和逆向将句子中的单词喂输入到两个RNN中,再将这两个RNN的隐含层输出叠加.
Cai等人[30]于2016年提出了一种基于最短依赖路径(Shortest Dependency Path,SDP)的深度学习关系抽取模型:双向递归卷积神经网络模型(BRCNN).论文的主要思想是对两个实体间的词法句法的SDP进行建模,利用双通道的LSTM(Long Short-Term Memory,长短期记忆神经网络)对SDP进行全局信息编码,并利用CNN捕获每个依存关系链接的两个单词的局部特征,增强了实体对之间关系方向分类的能力.
Miwa等人[31]于2016年首次将神经网络方法应用于命名实体识别与实体关系抽取的联合模型.模型基于LSTM-RNN,采用端到端执行方式,模型由三个表示层组成,底层是词嵌入层完成信息编码,在词嵌入层上有两个双向的LSTM-RNN,一个基于词序列结构用于实体识别任务,一个基于依存树结构用于关系抽取,这两部分共享编码信息,并堆叠形成一个整体的模型,前一个的输出和隐含层作为后一个结构输入的一部分,使得实体识别与抽取相互影响.
Katiyar等人[32]在2017年将注意力机制Attention与BiLSTM联合用于命名实体识别和关系抽取.该模型借鉴了Miwa等人[31]的模型,改善了原模型依赖于词性序列、依存树等特征的缺点.模型具有一个词嵌入表示的输入层,两个输出层,一个用于输出识别出的实体,一个使用注意力模型进行关系分类.
2018年,Devlin等人[33]提出了BERT(Bidirecttional Encoder Representations from Transformers)模型,BERT属于预训练语言模型,所谓预训练模型,就是先用大量的自由文本进行预训练,使模型学习得到通用的语言知识,再根据下游任务进行Fine-tuning阶段训练,让模型参数按具体任务要求和领域知识进行微调.
3 基于BERT的实体和关系联合抽取模型
基于BERT的强大能力,本文设计了一个基于BERT的实体和关系联合抽取模型,本模型将实体和关系的联合抽取转换为序列标注问题,模型总体分为4个部分:嵌入层、BERT层、BiLST层和CRF层.模型结构如图1所示:
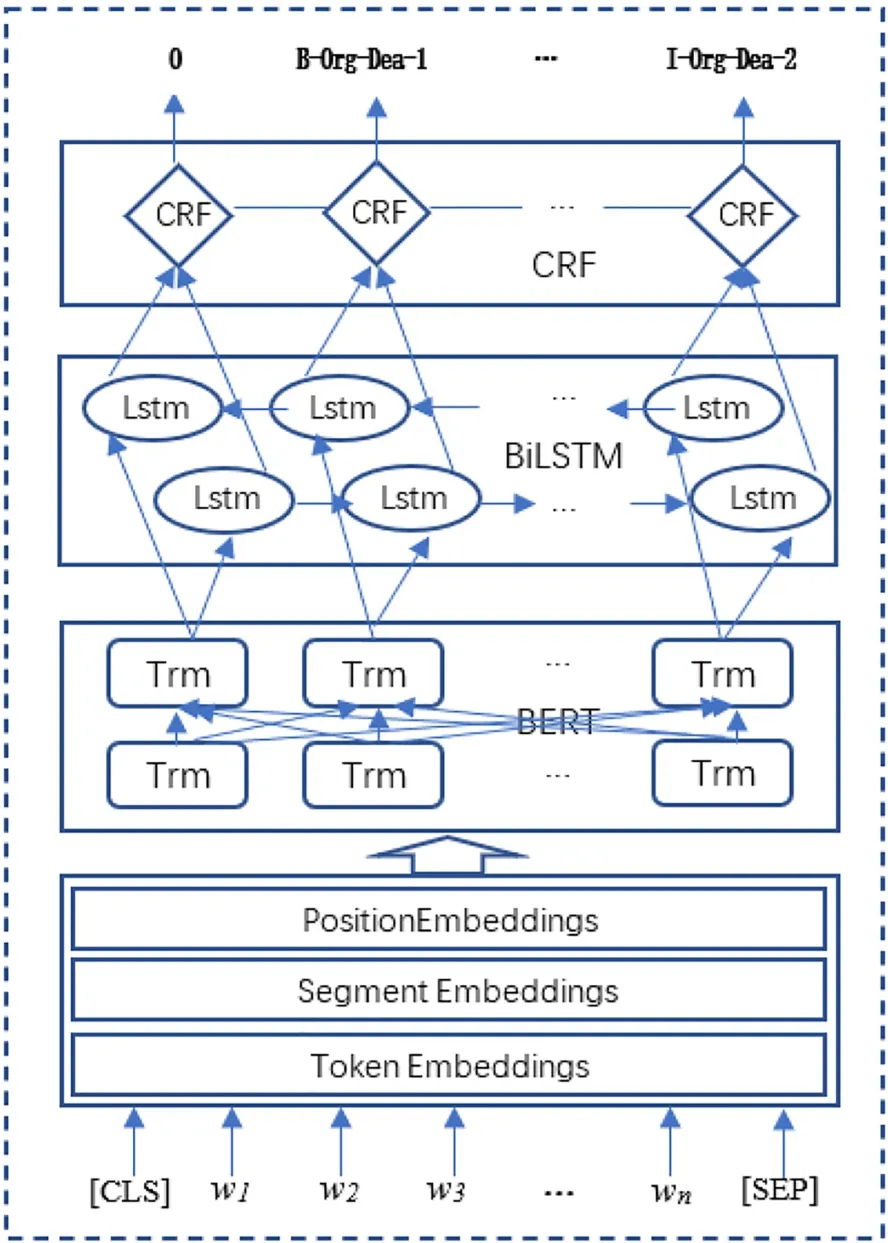
图1 基于BERT的实体和关系联合抽取模型Fig.1 Joint Extraction Model of Entity Relationship Based on BERT
3.1 文本预处理
预处理过程中先对数据源进行清洗和筛选,过滤掉一些无关的文本或数值.再对训练文本序列进行标注,标注时每个文字都标注一个标签,标签内容最多有4部分,分别是实体边界、实体类型、关系类别和关系角色.实体边界标签采用“BIO”方式,字母“B”表示实体的头部,字母“I”表示在实体中部或实体尾部,字母“O”表示非实体部分.实体类型标签由实体类型确定,如“Per”表人名、“Org”表示公司名.实体关系标签由关系类别来确定,如在金融领域中我们处理五种实体关系,分别用“Coo”“Dea”“Pun”“Mem”“Sto”表示合作、交易、处罚、成员和股权关系.关系角色用1、2、3分别表示关系主体、关系客体和重叠关系.标注过程如图2所示.

图2 输入句子标注过程Fig.2 Input sentence tagging process
3.2 嵌入层
BERT模型的输入表示由Token Embedding,Segment Embedding和Position Embedding三部分相加组合而成.Token Embedding部分首先是[CLS]标志,然后是文字序列内容,[SEP]标志句子的结束,可用于分开输入句子,在这里每个Token都表示为一个768维的向量.Segment Embedding部分用于训练句子的相互关系,区分每一个Token属于句子A还是句子B,如果只有一个句子就只使用A.Position Embedding嵌入部分对文字出现位置进行编码,在BERT模型中位置向量的值由正余弦函数生成,具体公式如下:

其中,pos指当前Token在句子中的位置,d_model表示位置向量中每个值的维度.三向量相加后,进行归一化和Dropout处理后送入BERT层进行特征提取.
3.3 BERT层
BERT采用双向Transformer做特征抽取器,在预训练时通过遮蔽语言模型(Masked Language Model,MLM),按照完形填空的思想,在输入中随机选择15%的Token屏蔽掉,再根据其上下文来预测被屏蔽的Token.为了和后期Fine-tuning匹配,被选择的Token只有80%的直接用[Mask]屏蔽,另外10%的随机选择别的Token代替,10%的使用原Token.此外,BERT还引入了下一句预测(Next Sentence Prediction,NSP)任务,采用自监督学习方式,学习文本对的表示.通过对海量自由文本的学习,BERT能自动学习得到文本中潜在的语言知识,并将这些知识以网络参数的方式存储起来,供后期具体任务的Fine-tuning使用.在做Fine-tuning任务时,BERT结构无需改变,只需使用标注的数据对网络进行训练微调.
BERT中用到的是Transformer的Encoder单元,每个Encoder单元的结构如图3所示,其中包含两个子层,第一子层由多头自注意力层(Mulit-Head Attention)和规范化层(Add&Norm)以及一个残差(Residual)连接;第二子层包括一个前馈全连接层(Feed Forward)和规范化层以及一个残差连接.自注意力机制使用三元组(Query,Key,Value)表示,当Encoder对某个Token编码时,用当前Token的Query表示向量Q,与其他所有Token的Key表示向量T做点积,再将点积结果归一化后用softmax函数处理,然后与当前Token的Value表示向量V做乘法,即可得到最终的表示结果.自注意力机制能表达输入序列的各部分(包括自己)与当前Token之间的联系度,具体计算方法如下:
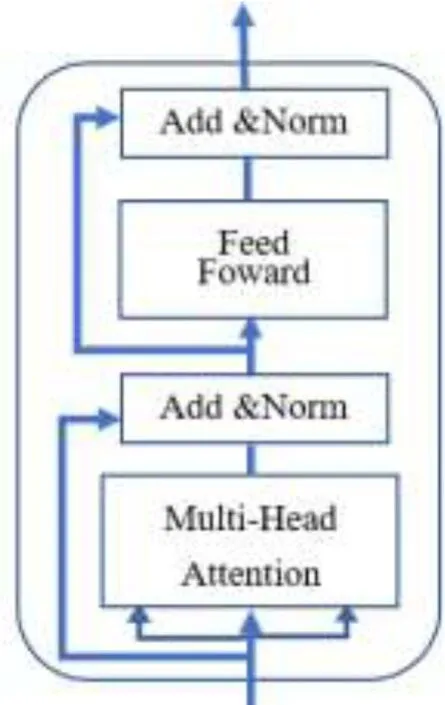
图3 Transformer Encoder单元Fig.3 Transformer Encoder Unit
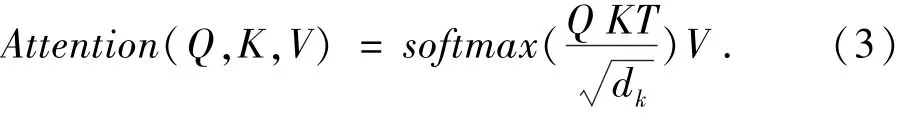
多头(Multi-Head)机制,则是通过随机初始化多组Q,K和V,经过训练后,得到多个不同权重的结果表示,再将这些结果通过乘法连接,多头注意力机制增加了模型表达词汇的多种特征的能力,从而均衡单一注意力机制可能产生的偏差,使多词义词能有多元表达.
在进行了Attention操作之后,Encoder还使用一个前馈全连接层,对每个Token向量进行两次线性变换和一次ReLU激活输出.在多头自注意力层和前馈全连接层后都有一个规范化层,其主要作用是进行数值的规范化,防止经过多层计算后输出开始出现过大或过小情况,使其特征值保持在合理范围内.
本文采用BERT-base模型,其中模型深度L=12层,隐藏层向量大小H=768维,多头注意力机制A=12头,模型参数总数是12*768*12=110 M.
3.4 BiLSTM层
LSTM属于RNN的一种,它巧妙运用门控概念,实现了长距离依赖信息的学习.BiLSTM则是将两个不同方向的LSTM进行叠加,从而能获取全局信息.在BERT的顶层上套接一个BiLSTM是为了使整个模型能针对实体和关系联合抽取任务快速学习到训练参数,适应性更强.LSTM神经单元中有遗忘门、记忆门和输出门结构,可以根据细胞状态和输入值确定信息遗忘更新还是继续传递,从而使有用信息能长期保存,而无用信息被丢弃.
3.5 CRF层
通过BiLSTM层能得到输入序列中每个文字对应各标注标签的得分,但并不是直接按分值高低标注就是最优结果,例如,每个序列的第一个标签的实体边界就只能是O或者B,不可能是I,以及I只能出现B或者I之后等.由此,在BiLSTM层上引入CRF层,能在预测标签时充分考虑上下文关联,学习得到各标签的转移矩阵,更好的契合实体与关系的联合抽取任务.
设输入的序列x=(x1,x2,…,xn),经过BERT和BiLSTM模块后的输出为矩阵P(n,k),k是标签的个数,Pi,j表示xi被标记为第j个标签的概率.标签序列为y=(y1,y2,…,yn),定义路径得分公式为:

其中,A为概率转移矩阵,Ai,j表示第i个标签转移到第j个标签的概率.
3.6 实体及关系的输出
根据CRF输出的序列标注结果,即可按照抽取算法,进行实体和关系的抽取.抽取算法如下:
算法1:由CRF输出标注序列(y1,y2,…,yn),抽取实体及关系.
输入:模型输入文字序列(x1,x2,…,xn),CRF输出标注序列(y1,y2,…,yn).
输出:实体集合N1,N2,…,Nk(k为实体类型数),关系集合R1,R2,…,Rm(m为关系种类数).
步骤1:位序标记i=1,实体全体置为空,关系集合全体置为空,临时实体名na置为空串,未匹配实体集Nn置为空.
步骤2:如果i>n,则转到步骤5执行;否则做下一步.
步骤3:如果标注yi代表O,则i++,再转到第二步执行;否则,如果标注yi代表B,则将其对应输入文字xi存入na,同时保存yi的实体属性、关系属性、角色属性,i++,再转到下一步执行.
步骤4:如果标注yi代表I,且yi与yi-1的其余属性一致,则将其对应输入文字xi接在na的后面,i++,再重复执行步骤4;否则做下一步.
步骤5:根据实体属性将na存入对应实体集合Nj(j为对应实体类型下标)中,并在未匹配实体集Nn中查找是否有与na关系属性和角色属性均匹配的实体,匹配时关系属性应相同,角色属性1与2、3匹配、2与1、3匹配、3与1、2匹配,若能找到,则将其取出并与na合成关系三元组,再存入相应类型的关系集合Rt(t为对应关系类型下标)中;若不能找到,则将na及其所有属性存入未匹配实体集Nn中.如果i>n,转到步骤6执行;否则,i++,再转到步骤2执行.
步骤6:输出实体集合N1,N2,…,Nk,关系集合R1,R2,…,Rm,算法结束.
4 数据集与评测情况
4.1 数据集介绍
在信息抽取领域常用的数据集有MUC数据集、ACE数据集和SemEval数据集等.
MUC数据集是MUC会议的数据库语料,其主要来源于新闻语料,MUC-6包含来自《华尔街日报》的318篇文章;MUC-7有来自纽约时报新闻的约158 000篇文章,语料范围限定在海军军事情报、恐怖袭击、人事职位变动等方面[3].
ACE数据集相比MUC数据集不仅评测内容扩大,语料来源也从原来MUC的限定领域语料变为内容更为广泛的书面新闻语料,应用较广是ACE-2004和ACE-2005.其中ACE-2004语料数据来源于LDC(linguistic data consortium,语言数据联盟),分成广播新闻和新闻专线两部分,总共包括451和文档和5 702个关系实例.ACE-2005对ACE-2004进行了扩充和完善,包括有英文、阿拉伯语和中文三个语种的资源,内容涵盖广播新闻、广播对话、新闻专线、微博和网络新闻等[4].
SemEval数据集是国际语义评测大会SemEval(International Workshop on Semantic Evaluation)的评测竞赛数据集,SemEval由国际计算语言学协会(Association for Computational Linguistics,ACL)主办,是目前规模最大、参赛人数最多、权威性最高的语义评测竞赛.其中,SemEval-2010 Task 8数据集是2010年SemEval语义评测的子任务,用于语义关系的分类,共包含10 717条数据,训练集8 000条,测试集2 717条,分别属于9种不相容关系[34].
4.2 典型论文的评测情况
在信息抽取中常用的评测基本指标有三项,分别为:正确率(Precision)、召回率(Recall)和F值(Fmeasure).准确率反映系统正确抽取信息的能力,召回率反映系统在信息抽取时查全所有实体和关系的能力,而F值是综合准确率和召回率指标的评估指标,用于综合反映整体的指标,是目前使用最为广泛的评测标准.表1是典型论文的数据集及其评测情况.
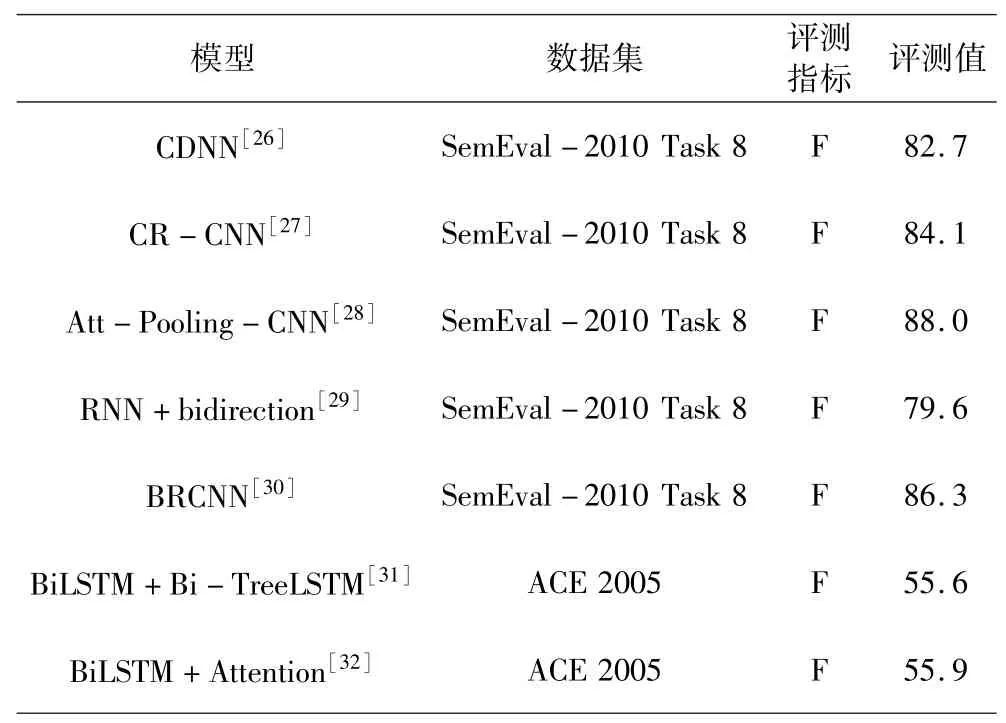
表1 典型论文的数据集及其评测情况Table 1 Data sets of typical papers and their evaluation
5 信息抽取展望
目前基于深度学习的信息抽取方法已取得很好发展,但仍有很多方面值得深入研究.首先,深度学习模型擅于处理单句语义信息,但在实际应用中,很多实体关系是由多个语句共同来表达,这就需要模型对文档中的多个语句进行综合理解、记忆和推理,进行文档级关系抽取.其次,目前信息抽取的研究多集中预设好的抽取任务集上,但今后的应用将是面向开放领域的信息抽取,因此,还需要不断探索如何在开放领域中自动发现新的实体关系及其事实.最后,当前研究往往限于单语种的文本信息,而人类在接受信息时,可以多种信息综合处理,因此,需要探索如何综合利用多语言的文本、声音和视频信息进行关系抽取.总之,信息抽取的研究要面向实际需求,适应开放关系和复杂的信息语境,以建立稳定和高效的实用信息抽取系统.
