基于反向可达集的影响力最大化算法
2022-01-14邓心惠孙更新
邓心惠,宾 晟,孙更新
(青岛大学数据科学与软件工程学院,山东青岛 266071)
0 概述
随着社交网络的快速发展,用户数量和信息传播规模不断扩大,影响力最大化问题受到越来越多的关注,广泛应用于病毒营销[1-2]、舆情预警、疾病控制等任务中。病毒营销是一种通过用户之间的口碑效应,最大限度扩大品牌知名度的方式,在有限的资源下选择合适的初始传播用户以最大化最终传播效果,成为解决影响力最大化问题的关键。RICHARDSON 等[1]将影响力最大化问题归纳为算法问题,即在某一信息传播模型下,从一个社交网络中选取k个初始种子节点集合,使最终影响传播范围最大化。KEMPE 等[3]基于独立级联(Independed Cascade,IC)[4]模型和线性阈值(Linear Threshold,LT)[5]模型,证明了影响力最大化问题是一个NPhard 问题,并提出一种贪心算法(Greedy Algorithm,GA)。该算法通过迭代的选择边际效应最大的节点加入种子集保证了在范围内接近最优解,但时间复杂度太高,不适用于大规模社交网络。很多研究人员针对贪心算法的低效率问题提出了一些优化算法。LESKOVEC 等[6]提 出CELF(Cost-Effective Lazy Forwards)算法,利用节点间影响传播函数满足子模性的特征将贪心算法的运行速度提高了700 倍。GOYAL 等[7]提出CELF++算法,进一步降低了CELF 算法的时间复杂度。这些算法在一定程度上提升了运行速度,但每次选取节点加入种子集时均要计算节点的影响增加量,运行效率依然很低,难以扩展到大规模社交网络中。
目前,多数研究人员采用启发式算法提高运行效率。CHEN 等[8]在度中心性的基础上提出影响力[9]最大化算法。CHEN 等[10]基于节点间最大影响传播路径提出PMIA 算法。JUNG 等[11]针对IC 模型提出IRIE 启发式算法。WANG 等[12-14]提出基于网络拓扑结构的启发式影响力最大化算法。谢胜男等[15]提出新的启发式算法提高运行效率。曹玖新等[16]提出基于k-核的CCA 算法。但是,这些启发式算法仅重点考虑了网络的拓扑结构特性而缺少一定的理论依据,导致算法得不到最优解。基于以上算法存在的问题,BROGS 等[17]提出一种将理论与实际效率相结合的反向影响抽样(Reverse Influence Sampling,RIS)算法,通过生成一定数量的反向可达(Reverse Reachable,RR)集来选择节点,进而多次计算节点影响力,使得到的时间复杂度接近线性,并具有一定的理论依据。虽然RIS 算法有很多优点,但在选取反向可达集的数量上不够准确稳定,导致算法在实际应用中会产生大量的计算开销。本文提出一种基于反向可达集采样的影响力最大化算法D-RIS,无须提前预设反向可达集生成数量的理论阈值,根据影响力传播函数的单调性和子模性,自动调试生成一定数量的反向可达集。
1 基于反向可达集的社交网络影响力最大化算法
将社会网络抽象为一个具有节点集V(用户)和有向边集E(用户间的关系)的网络图G,其中G=(V,P,E),|V|=n,P∈(0,1),|E|=m。假 设G中每条边e都有传播概率P(E)∈(0,1),那么P(u,v)∈P(u,v∈V)代表节点u激活节点v的概率。为了表述方便,表1 给出了本文常用的符号表示。
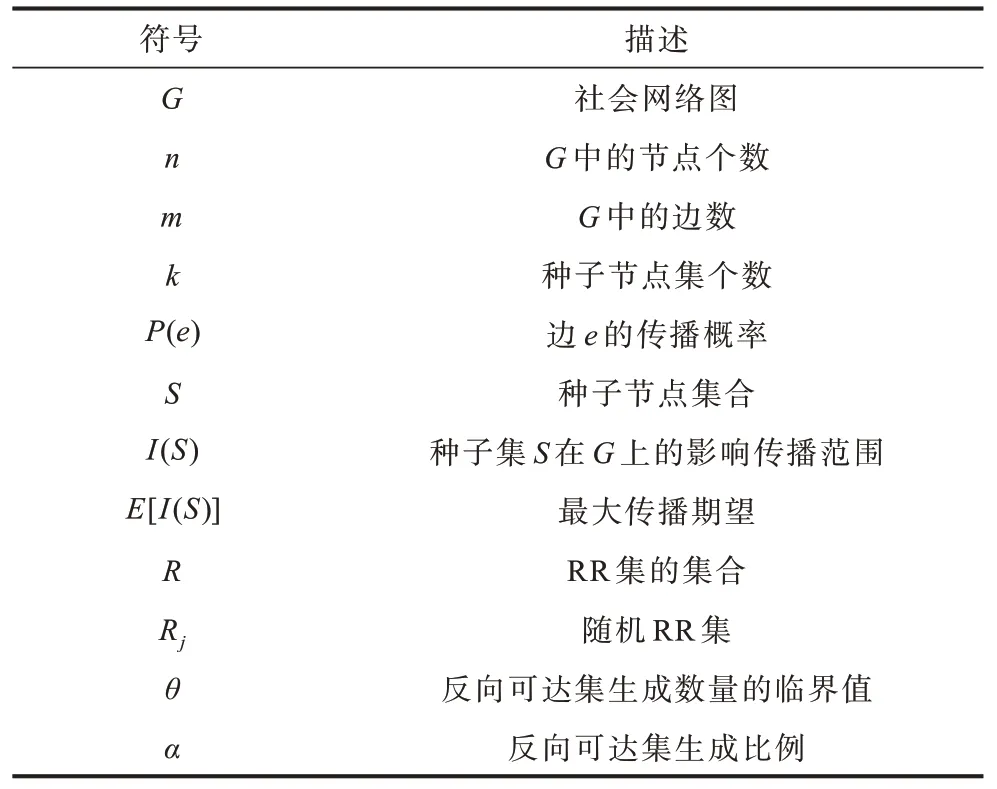
表1 常用符号设置Table 1 Setting of commonly symbolic
1.1 传播模型和问题描述
在社交网络中寻找一组特定的影响力最大的种子节点集时,需要运用一定的传播模型来模拟信息在网络上的传播规律。目前,经典的信息传播模型有IC 模型和LT 模型。
本文实验使用IC 模型模拟用户影响力最大化传播。在该模型中给出一个具有n个节点和m条边的有向加权图G来表示底层网络。边e=(v,u)的权值表示节点v沿着边e传播到节点u的概率P。IC 模型中节点被分为已激活、新激活和未激活3 种状态。每个新激活节点有且仅有一次机会以概率P对未激活的邻居节点尝试激活。P值越高,激活的可能性越大。当G中不存在有影响力的活跃节点时,传播过程结束。在IC 模型上影响力传播模拟是通过从一组种子节点的随机传播开始的。设I(S)为种子节点集S中所有节点的最终影响传播范围,即种子节点集S传播模拟激活的节点个数。期望E[I(S)]是选取的I(S)最优值。该模型模拟传染病模型[18-19]的传播过程,种子节点集S类似于一组受感染的个体,激活其邻居节点的传播模拟过程类似于疾病从一个个体传播到另一个个体。
图1 是由4 个节点组成的一个社交网络初始图,每条边上的权值代表出边节点到入边节点的传播概率Pij。设此社交网络中所有节点的激活概率为0.5,模拟社交网络的信息传播过程。S={a}为初始种子节点集,在T1时刻激活节点a,在T2时刻节点a具有0.2 的概率激活节点c以及0.8 的概率激活节点d,由于Pac=0.5>P=0.2,因此在T2时刻,节点d被激活,S={a,d}。在T3时刻节点c和节点b都具有1 的概率被节点d激活。假设节点d激活节点c而不激活节点b,影响传播过程结束。网络上没有新的节点可以被激活,该传播过程中激活的节点总数为3,即I(S)=3,S={a,d,c}。若 在T3时刻节点b被激活,则I(S)=4,S={a,b,c,d}。由于IC 模型是一种概率模型[20],因此传播过程及最终传播结果都是不一定的。在实验过程中经常采用蒙特卡洛方法[21]来多次运行取平均值,以确保结果具有较高的准确率。
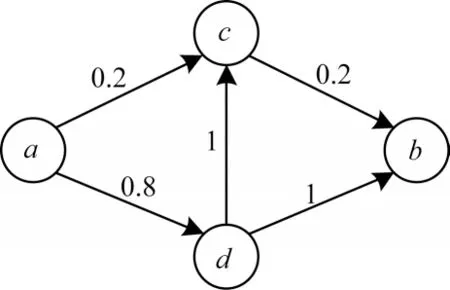
图1 基于独立级联模型种子节点集的影响力传播社交网络初始图Fig.1 Initial diagram of the influence propagation social network based on the seed node set of IC model
在给定社交网络G和常数k的前提下,影响力最大化问题要求在G中寻找一组种子节点集S,使其在IC 传播模型下传播影响范围最大,即找到种子节点集S∈V且|S|=k使得E[I(S)]最大。
1.2 RIS 算法
RIS 算法引入反向可达集采样方法替代蒙特卡洛方法计算节点预期传播的影响力,主要思想是生成尽可能少的反向可达集样本,最终在的范围内获得一个近似最优解。RIS 算法证明了对于任何ε>0,都可以在O(β(m+n)klogan)的时间下运行,时间复杂度是近似线性时间的,其中β为选取反向可达集中运行的步数。
RIS 算法避免了贪心算法产生高时间复杂度的问题,同时解决了启发式算法缺少理论保障,得不到最优解的问题。但是,RIS 算法不能有效控制随机RR 集的数量。BORGS 等[17]提出一种基于阈值的方法生成随机RR 集,当生成的节点和边的总数达到预定的理论阈值时停止生成随机RR 集。尽管该方法具有近似线性的时间复杂度,但是与生成固定理论阈值的反向可达集之间具有很大的相关性,在实际应用中隐藏的常数较大,导致RIS 算法存在以下问题:1)生成的实际RR 集样本数量大于理论阈值;2)不能保证理论阈值是生成RR 集样本数量的最小值。因此,RIS 算法选取RR 集的样本数量并不准确,不能较好地适用于大规模社交网络。
1.3 基于反向可达集的D-RIS 算法
针对大多数经典影响力最大化算法存在时间复杂度高或得不到最优解的问题,本文基于IC 模型提出D-RIS 算法。D-RIS 算法主要包括以下步骤:
1)生成反向可达集。随机且有放回地选择n个节点,通过在随机图g上进行传播模拟生成θ个节点RR 集的集合R。
2)节点选择。使用最大覆盖方法寻找k个覆盖最多RR 集的节点并返回种子节点集S。
对RIS 算法理论进行分析可以得出:若随机RR集采样数量过少,则会因选取节点不足导致算法得不到最优解;若随机RR 集采样数量过多,则虽然误差减小,但会造成时间复杂度太高。因此,根据种子节点集的准确率判定最终的影响力传播范围和时间效率。D-RIS 算法的研究重点是选取尽可能少的RR集样本数量,使算法在影响力传播范围和运行效率之间取得较好平衡。借鉴文献[17]中采样方法定义统一的反向可达集采样框架,在此基础上提出新的临界值判断方法,能够动态选取尽可能少的RR 集样本数量,并使用最大覆盖方法选取种子节点集。给定网络G=(V,E,P),D-RIS 算法通过生成随机RR 集的集合R来捕捉G中节点的影响传播过程,设Rz为节点v的RR 集的子集,即节点的随机RR 集,图g是在G中以1-P(E)的概率去掉边e后得到的随机图。
定义1(反向可达集)随机图g中可以到达v的节点集,对于RR 集中的节点u,g中都有一条从u到v的有向路径。
采样过程为:1)随机选择一个节点v∈V;2)在网络G上生成样本随机图g;3)返回g中节点v的反向可达集Rz。将采样过程中的节点v称为Rz中的源节点,则Rz中的所有节点都存在一定的概率能够激活源节点v。因此,某一节点出现在更多的RR 集中就意味着能够激活更多的节点,同时该节点具有较大的影响力传播范围。基于同样的推断,如果具有k个节点的节点集S覆盖大量的RR 集,则在网络G中的这k个节点具有很强的传播能力传播至最大范围,即I(S)=nP[SCoversRz]。由于节点集S的影响与S和RR 集相交的概率成正比,因此解决影响力最大化问题就是确定R集的下界。基于反向可达集采样框架,设置一种动态调试方法确定最小R集数量。
通过实例说明在IC 模型下对图1 社交网络G生成反向可达集的过程,设置k=1。图2 是在G上生成的3个随机图g1,g2,g3。对于3个随机选取的源节点c,b,d生成的3 个随机RR 集R1={c,a}、R2={d,a}、R3={b,c,a},因为节点a出现在3 个随机RR 集中,所以节点a是影响力最大的节点,最终返回结果为S={a}。

图2 基于社交网络G 生成的随机图Fig.2 Random graphs generated based on social network G
1.3.1 反向可达集数量确定
通过对RIS 算法中随机RR 集的数量选取分析可知,Rz数量越多(R集越大),选取的种子节点集越准确,但会增加时间成本。因此,本文提出一种在不影响最终影响力传播范围的同时使得生成的R集数量尽可能少的方法。随着随机RR 集数量的增多,影响力传播范围的上升并不是线性的,而是效用递减的。因此,RR集的数量与影响力传播范围函数的关系同时满足单调性和子模性(边际效用递减),具体定义如下:
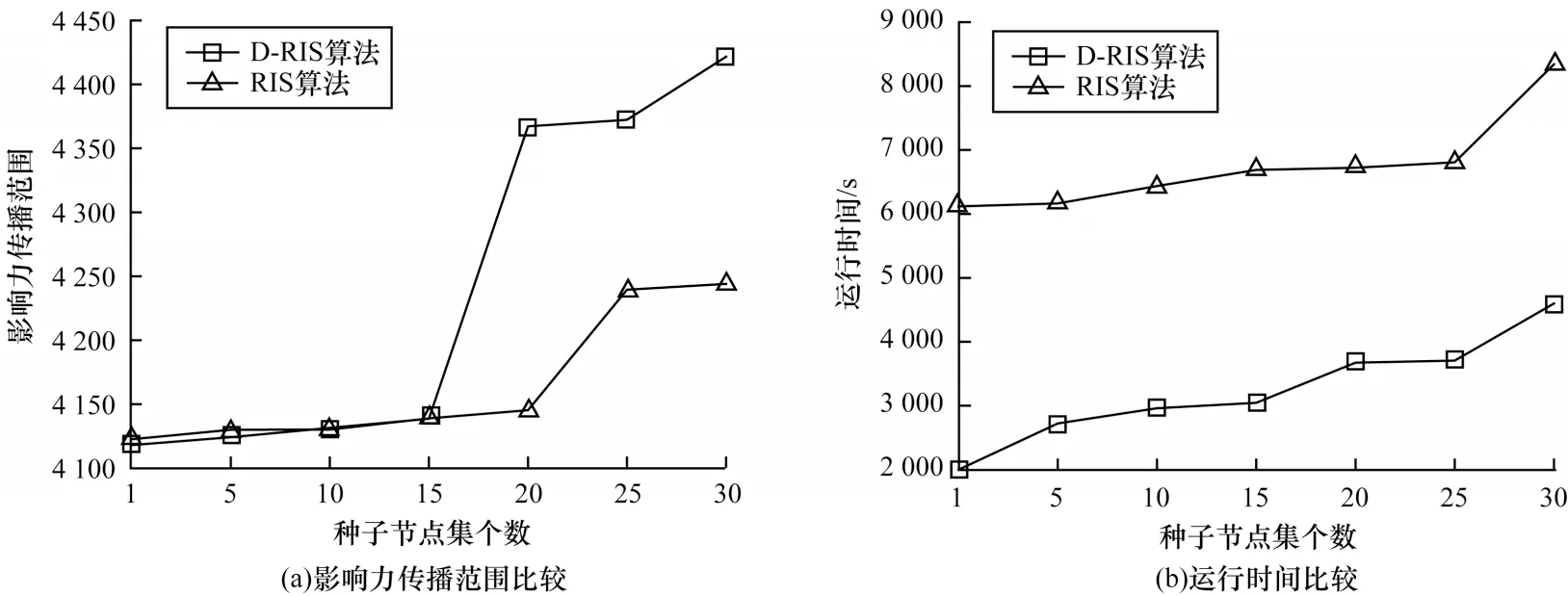
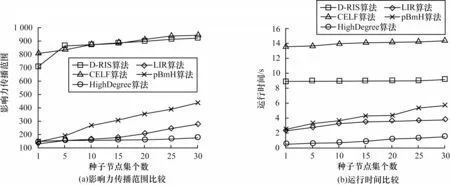
1)单调性。设影响力传播范围函数f,对于任意反向可达集的数量q1 2)子模性。对于图的节点总数t,设影响力传播范围函数f,反向可达集数量q1 基于以上理论,对于给定的G,算法设置一个随机RR 集数量的临界值θ,其中θ=n×α,α为随机RR 集选取比例。当随机RR 集的数量小于θ时,会导致选取随机RR集的数量不足而不能取得最大影响力传播范围。当随机RR 集的数量大于θ时,边际效益递减,影响力传播范围的上升幅度过于缓慢或不再上升,会导致时间成本增加。因此,基于网络中节点当前的传播情况,算法每轮自动加倍生成反向可达集,直至满足算法1 中设置的临界值判断条件3 次,认为算法生成的RR 集数量无限逼近临界值。设本轮次影响力传播范围为fc,上轮次影响力传播范围为fp。算法1 给出了D-RIS 算法反向可达集生成过程的伪代码,主要过程如下: 1)设置初始的反向可达集生成比例为一个极小的值α,例如算法1 将α值取0.001,此时θ=0.001n,从种子节点集S中随机选取节点生成比例为α的随机RR 集并计算影响力传播范围fc(算法1 中的第4~6 行)。 2)每轮将α的值加倍并计算本轮影响力传播范围增加量Ic,即Ic=fc-fp,下面对本轮影响力传播范围增加量进行判断(算法1 中的第7 行),若满足条件,则认定本轮α加倍对影响力增长不起作用,影响力可能已经接近临界值。判断条件为:若IC≤0 或Ic<math.loga(Ip,2),则本轮影响力范围增加量小于等于0 或小于上轮影响力范围增加量开根号的结果。 3)迭代上述步骤,直到连续3 次的α加倍无效,或α的值大于等于1 时停止继续生成反向可达集,此时算法生成的随机RR 集数量逼近临界值。设最终的反向可达集生成比例为α1,此时得到了相对稳定且有效的反向可达集的临界值θ,即θ=n×α1。 算法1反向可达集生成算法 在动态调试确定α值的过程中,α值是跳跃式逐渐上升,直至接近临界值。除了第一轮以外,每轮迭代并不是生成α个反向可达集,而是生成个反向可达集,存储上一轮个反向可达集,从而组合成本轮的α个反向可达集,即在原有反向可达集的基础上生成同样数量的反向可达集,达到加倍的作用。因此,本文算法极大地提升了算法的时间效率。 基于影响力传播函数满足单调性和子模性的特点,根据网络中节点实时传播情况,提出一种确定随机RR 集临界值θ的方法,并遵循反向可达集采样框架,生成θ个反向可达集。 1.3.2 种子节点选择 D-RIS算法使用最大覆盖方法进行种子节点选择。给定G、k和反向可达集的数量θ。将算法1 中生成的θ个随机RR 集插入到集合R中。若S∩Rj≠∅,则种子集S覆盖一个随机RR 集Rj,即CoverR(S)=,将I(S)的近似值定义为I(S)=。算法2给出了D-RIS算法的节点选择过程的伪代码,k次迭代过程如下: 1)每次算法在R集中选择一个覆盖最多RR 集数量的节点v。 2)删除R集中节点v所在的所有反向可达集,被删除的反向可达集中的节点都有一条通过节点v能到达的路径。 3)将节点v加入到S集中,更新R集进行下一次迭代。 4)选出节点集S=k,迭代结束。 由于在使用最大覆盖方法选择k个节点集的过程中,利用贪心算法反复选择覆盖最大边际收益的节点加入种子节点集S中,因此可以返回的近似解,并且能得到近似线性的时间复杂度。 算法2节点选择算法 由上文分析可知,D-RIS 算法主要包括两个阶段。在第一阶段中,随机选取n个节点生成θ个反向可达集,其中θ=n×α(α<1),时间复杂度为O(θ)。对于任意随机选取的节点vj,如果基于一定传播模型进行传播模拟生成的反向可达集的时间复杂度为O(EEPV),其中EEPV是随机RR 集的宽度(即随机图g中指向节点vj的有向边数),则D-RIS 算法的第一阶段的时间复杂度为O(θ×EEPV)。在第二阶段中,使用最大覆盖方法选择k个节点运用了贪心算法,可以得到线性的时间复杂度为O(θ×EEPV)。贪心算法的时间复杂度O(kmnr),其中,r代表使用蒙特卡洛采样次数,n和m分别代表网络G中全部的节点个数和边数,在通常情况下n、m、r的数值都很大。D-RIS 算法相比贪心算法时间复杂度更低,相比同样能达到线性时间复杂度的RIS 算法,在反向可达集数量的选取上更加准确合理。根据上述时间复杂度的分析结果可以得出,D-RIS 算法更适用于大规模社交网络。 为更好地验证D-RIS 算法的合理性和时效性,采用两个真实数据集进行实验,如表2 所示。Slashdot 数据集是分享科技资讯网站的朋友数据集,此网站允许用户将彼此标记为朋友或敌人,其中76.7%是朋友关系。为方便不同算法之间的比较,对Slashdot数据集进行处理,在朋友关系中随机选取10 000 个节点,预处理后的这些节点间存在36 338 条边,代表10 000 个用户之间存在的社交关系。Epinions 数据集是一种基于信任的在线社交网络数据集。若节点v到节点u存在一条有向边,则节点v信任节点u,即节点u可以影响节点v,对Epinions 数据集进行了相同的预处理后,保留了信任关系中的10 000 个节点和67 059 条边。Slashdot和Epinions 数据集[22]均可在斯坦福大学大型网络数据集网站上下载得到。 表2 数据集信息Table 2 Datasets information 实验中使用的信息传播模型为IC 模型,传播概率为0.08,运行10 000 次蒙特卡洛[18]模拟信息传播过程,并取平均值作为最终的影响力传播范围。为验证D-RIS 算法的合理性和时效性,选取的对比算法为当前具有代表性的5 种算法,具体如下: 1)CELF 算法。该算法是贪心算法的改进算法,核心思想与贪婪算法基本一致且效率提升明显。 2)HighDegree 算法。该算法是基于节点中心性的经典启发式算法,选择k个度最大的节点作为种子节点集。 3)LIR[13]算法。该算法是基于拓扑结构的启发式算法,选取并排序局部度最大的节点进而选取种子节点集。 4)pBmH[14]算法。该算法是基于拓扑结构的启发式算法,考虑了节点受多重邻居节点的影响,避免了富人俱乐部现象。 5)RIS[17]算法。该算法是反向影响抽样算法,通过生成一定理论阈值数量的反向可达集进而选取种子节点集。 设置以下3 种仿真实验: 1)D-RIS 算法传播规律合理性验证。使用Slashdot 数据集对RIS 算法中影响力传播函数满足单调性和子模性进行分析与验证。 2)D-RIS 算法与RIS 算法的性能比较。在Slashdot 和Epinions 数据集上,设置不同的反向可达集生成比例的RIS 算法的反向可达集数量,与D-RIS算法分别进行影响力传播范围和运行时间比较。 3)D-RIS算法与经典算法的性能比较。对D-RIS算法与CELF 算法、HighDegree 算法、LIR 算法和pBmH算法在两个真实数据集上进行影响力传播范围和运行时间比较,以验证D-RIS 算法的时效性更优。 2.2.1 D-RIS 算法传播规律合理性验证 设置k=5,RIS 算法从α=0.001 开始迭代,每轮加倍反向可达集生成比例直到连续3 次加倍无效或α≥1 时停止。 由图3 可知,随着反向可达集生成比例的增加,曲线呈上升趋势,即影响力传播范围不断增大,表明算法影响力传播范围函数具有单调性。RIS 算法的反向可达集生成比例大于0.01 后,随着反向可达集生成比例的上升,影响力传播范围曲线趋于平缓,这是由于影响力传播范围函数满足子模性导致边际效益递减,从而呈现影响力传播范围曲线扩大趋势逐渐减缓。当反向可达集生成比例为0.03 时,曲线有稍微下降的趋势,符合实际情况。理论上,算法的影响力传播范围具有单调性,但由于采用的传播模型为概率模型,因此在实验中具有一定的波动性。 图3 RIS 算法和D-RIS 算法在Slashdot 数据集中反向可达集生成比例与影响力传播范围的关系Fig.3 Relation between reverse reachable set generation ratio and influence propagation range of the RIS algorithm and the D-RIS algorithm on the Slashdot dataset 由图3 中RIS 算法的曲线趋势可以看出,影响力传播函数由于满足单调性和子模性,因此出现递增后逐渐减缓的情况。同时,对D-RIS 算法进行验证,结果表明随着反向可达集数量的增加曲线上升趋势先增大后趋于平缓。RIS 算法需要提前预设反向可达集生成比例,若选取不合理则导致算法达不到最优影响传播范围或增加时间成本。D-RIS 算法只需给定一个较小的反向可达集生成比例,就可自动加倍调试反向可达集生成比例直到满足条件时停止。因此,该实验证明了D-RIS 算法传播规律的合理性和实用性。 2.2.2 D-RIS 算法与RIS 算法的性能比较 将RIS 算法反向可达集生成比例分别设置为0.001、0.2、0.5,在两个数据集上与D-RIS 算法进行影响力传播范围和运行时间的比较。 1)设置RIS 算法反向可达集生成比例为0.001。由图4、图5 可知,当RIS 算法的反向可达集生成比例为0.001 时,相较D-RIS 算法,RIS 算法运行速度更快,但影响力传播范围过小。特别地,当种子节点数量k较低时,两者的影响力传播范围存在成倍的差距。这是由于RIS 算法中的反向可达集生成比例过小导致选取种子节点数量不够精准,影响算法的最终传播范围。 图4 RIS 算法和D-RIS 算法在Slashdot 数据集上的实验结果比较(反向可达集生成比例为0.001)Fig.4 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Slashdot dataset(reverse reachable set generation ratio is 0.001) 图5 RIS 算法和D-RIS 算法在Epinions 数据集上的实验结果比较(反向可达集生成比例为0.001)Fig.5 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Epinions dataset(reverse reachable set generation ratio is 0.001) 2)设置RIS 算法反向可达集生成比例为0.2。如图6、图7 可知,当RIS 算法的反向可达集生成比例为0.2 时,在Slashdot 数据集中,两种算法的影响力传播范围接近,但D-RIS 算法的运行效率高于RIS 算法。在Epinions 数据集中,D-RIS 算法在获得较大影响力传播范围的情况下,大幅降低了运行时间,且选取的种子节点集个数越多,在运行效率方面优势越明显。 图6 RIS 算法和D-RIS 算法在Slashdot 数据集上的实验结果比较(反向可达集生成比例为0.2)Fig.6 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Slashdot dataset(reverse reachable set generation ratio is 0.2) 图7 RIS 算法和D-RIS 算法在Epinions 数据集上的实验结果比较(反向可达集生成比例为0.2)Fig.7 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Epinions dataset(reverse reachable set generation ratio is 0.2) 3)设置RIS 算法反向可达集生成比例为0.5。由图8、图9 可知,当RIS 算法的反向可达集生成比例设置为0.5 时,在两个数据集上,D-RIS 算法有较大的影响力传播范围,且运行效率远高于RIS算法。由此可以看出,过大的反向可达集生成比例会增加算法最终的时间成本。对于Slashdot 数据集,RIS 算法的运行时间是D-RIS 算法的2 倍多。对于Epinions 数据集,RIS 算法的运行时间是D-RIS 算法的7 倍多,因此D-RIS 算法具有更高的运行效率。 图8 RIS 算法和D-RIS 算法在Slashdot 数据集上的实验结果比较(反向可达集生成比例为0.5)Fig.8 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Slashdot dataset(reverse reachable set generation ratio is 0.5) 图9 RIS 算法和D-RIS 算法在Epinions 数据集上的实验结果比较(反向可达集生成比例为0.5)Fig.9 Comparison of the experimental results of the RIS algorithm and the D-RIS algorithm on the Epinions dataset(reverse reachable set generation ratio is 0.5) 在两个真实数据集上的实验结果表明:1)当RIS算法的反向可达集生成比例的理论阈值设置太小时影响力传播范围较小,当理论阈值设置太大时运行效率太差,D-RIS 算法在达到较优的影响力传播范围的同时运行效率更高;2)与RIS 算法相比,D-RIS 算法避免了反向可达集生成比例的理论阈值设置不准确,导致达不到最优影响力传播范围或增加时间成本的问题。对于目前复杂的社交网络,D-RIS 算法无需重复计算,可自动调试生成一定比例的反向可达集,因此更适用于后续拓扑结构变化的社交网络。 2.2.3 D-RIS 算法与经典算法的性能比较 在两个不同数据集上,将D-RIS算法与CELF、LIR、pBmH 和HighDegree 算法进行影响力传播范围和运行时间的比较,如图10、图11 所示。 图10 5 种算法分别在Slashdot 数据集上的影响力传播范围与运行时间比较Fig.10 Comparison of the influence propagation range and running time of five algorithms on the Slashdot dataset 图11 5 种算法在Epinions 数据集上的影响力传播范围与运行时间比较Fig.11 Comparison of the influence propagation range and running time of five algorithms on the Epinions dataset 由于5 种算法的运行时间相差较大,因此运行时间设置为T=2y,其中y表示纵坐标数值。根据图10、图11实验结果分析可知: 2)相比LIR、pBmH 和HighDegree 启发式算法,D-RIS 算法虽在运行速度方面表现较差,但影响力传播范围明显更优。在Epinions 数据集中,启发式算法的影响力传播范围仅有D-RIS 算法的50%左右。在Slashdot 数据集中,D-RIS 算法的影响力传播范围优势更为明显。可见,启发式算法虽有极高的运行效率,但未考虑到复杂网络后续结构变化导致选取的种子节点不够准确,影响力传播范围较小且得不到最优解,同时在不同数据集中启发式算法的稳定性不佳。 通过以上算法的对比实验分析可知:D-RIS 算法在影响力传播范围和运行时间两方面取得了较好的平衡,且表现出较好的通用性和稳定性,更适用于拓扑结构变化和规模较大的社交网络。 本文基于独立级联模型,结合反向可达集采样提出一种改进的影响力最大化算法D-RIS,根据影响力传播函数的单调性和子模性,设置随机生成反向可达集数量临界值的判断条件,自动调试生成一定数量的反向可达集。实验结果表明,D-RIS 算法可在获得较大影响力传播范围的同时避免增加时间成本,并且能较好地应用于拓扑结构变化和规模较大的社交网络。下一步可将D-RIS 算法扩展到多关系社交网络的影响力传播模型中,解决社交网络中多条信息同时传播情况下的影响力最大化问题。

2 实验与结果分析
2.1 实验数据集

2.2 结果分析







3 结束语
