基于K-means++的驾驶人致因因素倾向性分析
2022-01-14王博文王景升薛曦初
王博文,王景升*,朱 茵,闫 硕,薛曦初
(1.中国人民公安大学交通管理学院,北京 100038;2.中国人民公安大学涉外警务学院,北京 100038)
据中华人民共和国交通事故统计年报数据统计,2019年中国共发生道路交通事故1 247.3万起,造成62 763人死亡,256 101人受伤,直接财产损失达13.5亿元。人为因素、车辆因素是交通事故最主要的两个致因因素,其中机动车驾驶人的不安全行为导致的交通事故约为90%,车辆的不安全状态导致的交通事故约占8%[1]。固有性质的差异,如:年龄、驾驶经验,会使驾驶人倾向于产生不同类别的交通事故致因因素并暴露在不同程度的风险中。研究不同特征的驾驶人群体与交通事故致因因素的关联性在目前来说十分重要。
在研究交通事故风险倾向时,研究人员主要关注驾驶人的特征与人的不安全行为的关联性,较少关注驾驶人的特征与车辆的不安全状态的关联。Mark等[2]研究表明,年龄较小的驾驶人容易因他们的危险驾驶行为发生交通事故。管满泉等[3]通过使用灰色聚类方法,研究了不同年龄、驾驶经验和属地的驾驶人的交通肇事倾向,并分析了驾驶人特征与肇事行为的关联。Hu等[4]研究了不同年龄、驾驶经验、驾驶风格条件下,驾驶人的事故危险倾向,说明了年龄在18~30岁的驾驶人存在较高的事故危险倾向,原因是青少年的攻击性心理较强,容易做出非法驾驶行为,此外,驾驶风险也与驾驶人的驾驶经验及驾驶风格具备一定关联性。
现研究年龄、驾驶经验等驾驶人特征与事故伤亡人数、事故责任、驾驶人的不安全行为值和车辆的不安全状态值的关联性,以中国公安交通管理综合应用平台2020年的机动车交通事故数据为基础,分析肇事驾驶人的特征,并采用K-means++进行聚类分析,将驾驶人群体分为3类,了解不同驾驶人群体与交通事故致因因素的关联性,针对性地开展交通安全教育的有效途径。
1 数据及方法
1.1 数据
研究数据来源于公安交通管理综合应用平台2020年的机动车交通事故数据,基于以下标准进行采样:①车辆类型为机动车;②交通参与角色为驾驶人;③年龄在18岁以上;④驾驶经验在1年以上;⑤详细的事故伤亡人数记录;⑥驾驶人交通事故承担的责任的大小;⑦详细的驾驶人的不安全行为值记录;⑧详细的车辆的不安全状态值记录[5-9]。抽样得到本研究样本总数为3 616个,样本特征依次为:事故伤亡人数、驾驶经验、年龄、事故责任、驾驶人的不安全行为值、车辆的不安全状态值[10]。数据的描述性统计如表1所示。

表1 数据的描述性统计表Table 1 Descriptive statistical tables of data
1.2 方法
1.2.1K-means++算法
为优化K-means算法随机选择初始聚类中心的方法,降低初始聚类中心选择的随机性,提高模型收敛效果及可靠性,K-means++初始化方案使算法生成的初始聚类中心彼此远离,得出了比随机生成初始聚类中心更加可靠的结果。建立K-means++聚类分析模型,主要步骤如下。
步骤1确定n个样本及对应样本的m个特征,构造n×m的矩阵。
步骤2采用轮廓系数作为聚类算法的评价指标,绘制不同簇数下样本的轮廓系数分布图,并选取最佳的簇数划分值K。
步骤3随机抽取K个彼此远离的样本作为最初的聚类中心。
步骤4进入循环:计算每个样本点和聚类中心的距离,将每个样本点分配到离他们最近的聚类中心,生成K个簇。对于每个簇,计算所有被分到该簇的样本点的平均值作为新的聚类中心。
步骤5当聚类中心的位置不再发生变化,迭代停止,聚类完成。
步骤6绘制K个簇的概率密度图并进行分析。
1.2.2 距离度量
每个样本点到聚类中心的距离采用欧几里得距离d进行度量,可表示为

(1)
式(1)中:x为一个簇中的一个样本点;μ为该簇的聚类中心;n为特征个数;i为组成点x的每个特征;xi为样本点x的第i个特征;μi为簇的聚类中心的第i个特征。
1.2.3 轮廓系数
对没有真实标签的数据进行聚类时,可以使用轮廓系数作为评价指标。轮廓系数反映了聚类结果的簇内稠密程度和簇间离散程度,单个样本的轮廓系数计算公式为
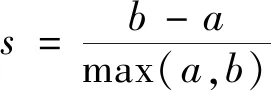
(2)
式(2)中:s为单个样本的轮廓系数;a为样本与同一簇中所有其他点之间的平均距离;b为样本与下一个最近的簇中的所有点之间的平均距离。
轮廓系数可以同时衡量:样本与其自身所在的簇中的其他样本的相似度a以及样本与其他簇中的样本的相似度b。式(1)可被解析为
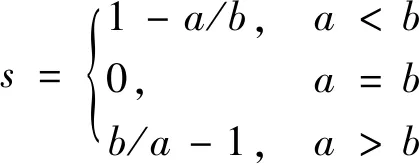
(3)
由式(3)得单个样本的轮廓系数取值范围为(-1,1),当s越接近于1时,该样本与其所在的簇中的样本相似度越高,同时与其他簇中的样本相似度越低;当s=0时,该样本与其所在簇及相邻簇中的样本相似度一致;当s越接近于-1时,该样本与其所在的簇中的样本相似度越低,同时与其他簇中的样本相似度越高。
2 驾驶人基本情况分析
2.1 事故伤亡人频率分布情况
通过采样获得的3 616个交通事故样本中,伤亡人数共4 105人,不同伤亡人数的交通事故的频率如图1所示。

图1 不同伤亡人数的交通事故的频率Fig.1 The frequency of traffic accidents with different casualties
由图1可知,伤亡人数为2人的交通事故频率最高,伤亡人数大于2时,事故频率呈现依次下降的趋势,重特大事故占事故总数的7.27%。
2.2 年龄及驾驶经验分析
交通事故的严重程度与人的不安全行为及车辆的不安全状态相关,年龄、驾龄是影响人的不安全行为及车辆的不安全状态相关因素。研究人员将驾驶人分为5个年龄组:18~30、31~40、41~50、51~60、61~83岁,不同年龄段的驾驶员发生交通事故的次数与伤亡人数如图2所示。

图2 不同年龄段的驾驶员发生交通事故的次数与伤亡人数Fig.2 The number of accidents and casualties of drivers of different age groups
由图2可知,30~40岁的驾驶人发生交通事故的频率最高,60~83岁驾驶人发生交通事故的频率最低。伤亡人数的趋势与事故发生频率的趋势相同。
研究人员依据驾驶经验将驾驶人分为5组:0~2、2~5、5~10、10~20、20~50年,不同驾驶经验的驾驶员发生交通事故的次数与伤亡人数如图3所示。

图3 不同驾驶经验的驾驶员发生交通事故的次数与伤亡人数Fig.3 Number of traffic accidents and casualties among drivers with different driving experience
由图3得,10~20年驾驶经验组驾驶员事故数量最多,5~10年驾驶经验组次之,0~2年驾驶经验组事故数量最少。伤亡人数的趋势与事故发生频率的趋势相同。
驾驶员的反应速度、判断能力、操作熟练程度等因素会随着年龄和驾驶经验的变化而产生变化,因此年龄及驾驶经验会对驾驶员的事故危险倾向造成影响。
3 驾驶人致因因素倾向性分析
使用K-means++算法,对事故伤亡人数、年龄、驾驶经验、事故责任、驾驶人的不安全行为值、车辆的不安全状态值进行聚类分析,识别出不同驾驶人群体的致因因素倾向性。
绘制聚类簇数K为2~7时的轮廓系数分布如图4所示。当K为2~7时的轮廓系数数值变化如图5所示。由图4、图5可知,平均轮廓系数随着K的增加而减小,即聚类效果随着K的增大而下降,当聚类簇数为2时,平均轮廓系数为0.58,当K为3时,平均轮廓系数为0.52,结合对驾驶人合理划分的需求,选择K=3。
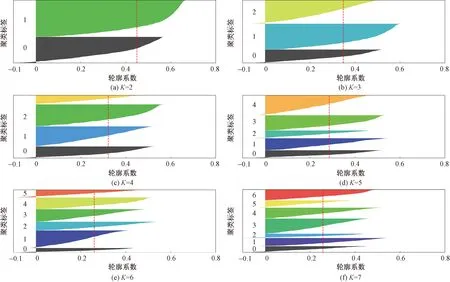
图4 K为2~7时的轮廓系数分布情况Fig.4 The silhouette coefficient distribution when K is from 2 to 7

图5 K为2~7时的轮廓系数数值变化情况Fig.5 When K is from 2 to 7,the silhouette coefficient value changes
使用K-means++算法将样本分为三类,并绘制3个驾驶人群体的概率密度分布曲线如图6所示。

图6 概率密度分布曲线Fig.6 Probability density distribution curve
聚类中心对应类别下的样本数目如表2所示。

表2 聚类中心对应类别下的样本数目Table 2 The number of samples under the corresponding category in the cluster center
由图6及表2可知,驾驶员群体存在一定特征:群体0在Z0、Z1、Z2、Z5属性上最大,占比27.56%;群体1在Z0、Z3、Z4属性上最小,占比34.07%;群体2在Z1、Z2、Z5属性上最小,在Z3、Z4属性上最大,占比38.16%。将驾驶人群体分为3个类型,具体如下。
(1)针对群体0进行分析,驾驶经验(Z1)或年龄(Z2)较高,事故责任(Z3)较高的驾驶人群体往往存在较高的车辆的不安全状态值(Z5),较高的伤亡人数(Z0)。驾驶经验较多或年龄较大的驾驶人群体往往具备良好的驾驶技能,可以较好地对危险状况做出判断和处理。这类驾驶人对自己的驾驶能力有盲目的自信,以至于忽视了车辆的不安全状态对驾驶风险的影响,在汽车处于制动不良、照明及信号装置失效等状态下仍选择上路行驶。年龄的影响也使这类群体有着更高的伤亡率。对于此类群体,可以开展车辆使用方面的安全状态教育,减少对车辆安全状态的忽视带来的安全隐患。
(2)针对群体1进行分析,事故责任(Z3)较低的驾驶人群体,往往不安全行为值(Z4)与车辆的不安全状态值(Z5)均较低。此类事故多为事故对方承担责任,对此类群体应按照自愿接受交通安全教育的原则,适度对其进行安全出行引导。
(3)针对群体2进行分析,驾驶经验(Z1)或年龄(Z2)较低,事故责任(Z3)较高的驾驶人群体往往存在较高的不安全行为值(Z4)。驾驶经验较少或年龄较小的驾驶人群体,在驾驶机动车时存在侥幸心理,因此不安全行为较为严重,如醉酒驾驶、逆向行驶、违法信号灯通行等。此类群体发生交通事故的频率最高,风险性最大。对于此类驾驶人群体,可以开展交通安全行为教育,减少不良驾驶行为带来的安全隐患。
5 结论
以中国公安交通管理综合应用平台2020年的机动车交通事故数据为基础,使用K-means++算法对肇事驾驶人的特征进行聚类分析,将驾驶人群体分为3个类别,得出了不同驾驶人群体与交通事故致因因素的关联性,为针对性地开展交通安全教育提供有效途径。
