基于改进的RFM 模型核心网络客户识别研究
2022-01-14王冬菊
王冬菊
安徽师范大学皖江学院,安徽 芜湖 241000
客户细分是企业了解不同客户需求进而进行差异化营销的主要依据[1]。当前,绝大多数电商平台及企业已然关注到不同的网络客户带来的不同收益,且拥有不同的价值意义,数量庞大的网络客户群体也为电商企业带来了众多营销问题[2]。但是所有电商平台及企业的资源都是有限的,为了做到低成本,获取高收益,就要将有限的资源向重点网络客户倾斜,把优良的服务资源供应给高品质消费者。但此类目标实现的前提是需要对如今的网络客户进行细分,并识别出核心网络客户。
1 核心网络客户的识别模型设计
1.1 RFM 模型计算网络客户价值出现的问题
RFM 模型是计算客户价值方法的经典方法之一。美国数据信息研究中心的Hughes 这样表示:近度R(Recency)、频度F(Frequency)、值度M(Momentary)构成了用户消费过程中客户细分的标准[3]。RFM 模型应用是简便充分的,可是在计算网络客户价值时还有一些问题。主要包括三个方面:
1.1.1 网络客户对行业的直接利润
在如今的电商时代下,运用RFM 模型开展用户价值测算时会发现有的用户价值和其现实价值的差距较大。例如有的“睿智”的网络客户一般都会挑选大促或者特价消费甚至每次销售活动都不曾错失,这就给了电商行业一个“忠诚用户”的幻象。然而现实情况是,通过测算这种级别的网络客户对行业的直接利润就不难发现,此类消费者对行业的利润价值实现是非常小的。
1.1.2 关于指标权重
传统RFM 模型中,各个指标的权重相同,与实际各因素对网络用户价值影响有一定的差距。比如,对于指标R 来讲,依据一般的RFM 模型细分原则,被分到R4 范围的网络客户不一定比处在R2 范围的用户价值小。这与实际中用户的消费总金额以及消费习惯都有一定的联系,特别是网络客户,其各自的差别更为突出。
1.1.3 关于细分结果
把R、M、F 各自分成5 个级别,从而获得125个用户群体,这会导致细分报告的用户群体过多,不易对每一用户群体开展精准分析,并且其对核心用户群体的识别也趋于繁复。
1.2 RFMG 模型
针对前文提及的RFM 模型在计算网络客户价值存在的三方面不足,笔者提出RFMG 模型。

其次对各指标权重进行设定,设R、F、M、G 的权重分别为,且。具体权重数据会因各类行业、各类企业的详细状况而异,确定方法可运用德尔菲法[4]。
最后,有关网络客户价值V 的测算,可以运用各指标加权求和的形式:
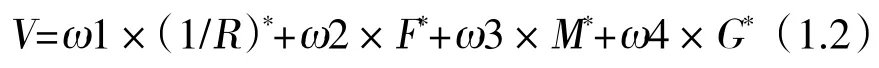
1.3 数据挖掘技术
数据挖掘(Data Mining)指的是从多数的、不全面的、有噪声的、不清晰的、任意的现实应用信息中,获取潜在的、目前不可知的、但又有用的资讯和内容的一个复杂流程[5]。从行业角度来看,信息挖掘是利用对大量业务信息开展提取、转化、识别和其他模型化处置,获取辅助行业决策的重要信息,并提供总结性的分析,从中发掘出潜在的价值,为行业上层供应决策支撑,协助行业的决策者及时调节市场计划,做出准确的判断[6,7]。
2 核心网络客户识别模型
基于上一节的设计思路,可构建如下核心网络客户识别模型,如图1 所示。
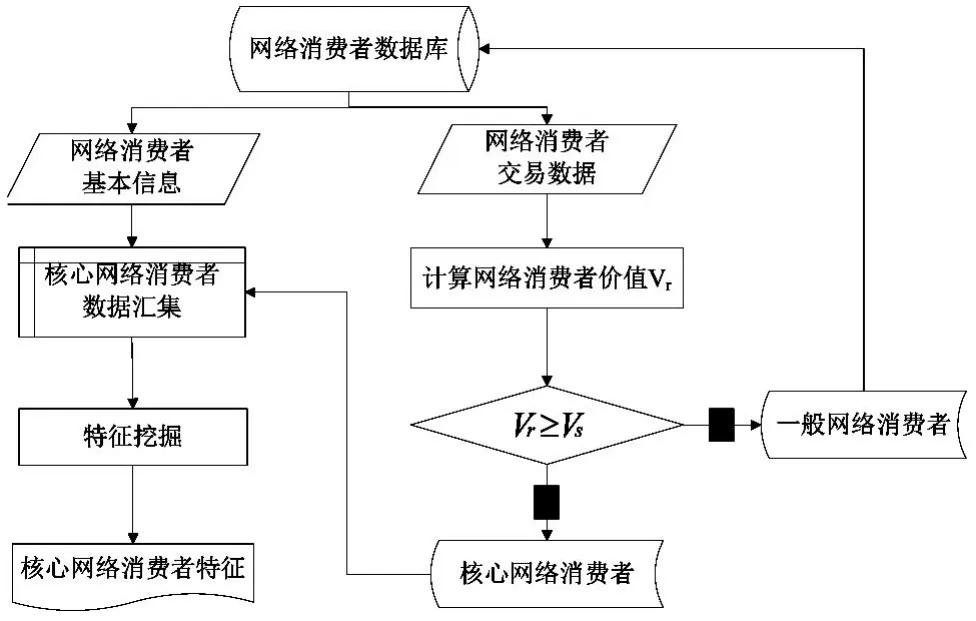
图1 核心网络客户识别模型
核心网络客户识别模型的组建主要涵盖了以下几个流程,即信息收集及预处置、确定指标权重、测算网络客户价值、辨别核心网络客户、发掘核心网络客户特质。
2.1 数据收集及预处理
2.1.1 数据收集
对当今时代下的电商行业来讲,网络客户普遍特质及与行业交易的活动特质有关的标准信息是极易搜集、测算的,并且是易量化的。核心网络客户识别模型中涉及到的数据主要包括两类:
(1)网络客户人群统计特质需要有关字段资讯,例如:性别、年纪、岗位、家庭住址、联系电话等主要信息。
(2)交易记录信息,如某网络客户订单的订单日期、具体金额、订单产品类型、订单商品数量、订单商品售价和成本价等;依此可测算近度R、频度F、值度M,毛利率G。
针对第一种信息中群体统计特质字段及第二种信息中订单产品类型等字段的整合,其主要是为此模型的最后两个环节打好基础。
2.1.2 数据预处理
在本模型中,为了排除特殊变量对测算成果的干扰,笔者运用了Min-max 标准化办法对各指标变量展开了标准化测算,比如:针对指标F:

其中Fmax、Fmin分别指统计期间内最多消费次数和最少消费次数。
2.2 RFMG 指标权重的确定
利用德尔菲法计算RFMG 模型中R、F、M、G 各指标的权重系数,其中打分专家组成员的确定要恰当合适,尽量选择从事电子商务行业工作,具有一定实际经验并了解电商消费者行为特点的专家。
2.3 网络客户价值的计算
将第一步标准化后每个要素数值与第二步中决定的要素权重系数代入式(1.2),运算获得样本整体所有电商消费者价值。依据各个企业标准决定核心消费者所占比重,并找出网络客户价值中位于第位的。
2.4 核心网络客户的识别
在对所有网络客户比较完成后,整个网络客户群体被细分为两个部分,即核心网络客户和一般网络客户。
2.5 核心网络客户的特征挖掘
单一地辨别核心网络客户并不是企业确定高效的营销计划的理论根据,企业更要熟悉掌握的是核心网络客户的行为特点,而数据挖掘技术中的决策树就是辨别同种事务共同特点的有效方法之一。
3 D 天猫店铺实证分析
D 天猫店铺是某品牌男士内裤企业在天猫平台上经营的专营店。该企业通过长时间的线下运营与经验积攒,已经具备比较成熟的线下分销途径。
3.1 数据收集及预处理
以某年1 月1 日至当年10 月31 日为时间段,从D 天猫店铺的客户信息库获得期间内一切消费者基本数据与历史交易信息,基本数据包含性别、生日、城市、手机号、邮箱等,历史交易信息包含订单日期、订单金额、商品货号、商品数量、商品价格、商品成本、面料种类、款式(分为三角和平角)、颜色等。其中共包含了3 794 名用户信息,7 051 条历史交易记录信息。
第一步,依据计算网络客户价值要求,先对信息开展预处理,依照下列规则运算R、F、M、G 值。
1.以周为单位,计算这个时间段内每名消费者最后一次购买时间到当年10 月31 日的时间差,记为R,并运算出1/R。
2.统计该时间段内每个消费者累计购买次数,记为F。
3.统计该时间段内每名消费者订单总共金额,记为M。
4.统计该时间段内每名消费者一切订单商品累计价格与成本,算出毛利率=×100%,记为G。
此外,为达成对核心网络客户特点的发掘,在整体考量了消费者的每种影响力及信息的可获得性,并且顾及信息的可量化准则,除去上述R、F、M、G 指标信息,此研究还选择了下列信息字段:
1.消费者的自然属性:用户ID、联系方式、邮箱地址;2.消费者的订单属性:订单号、商品货号、售价、件数;3.货物的属性:货物货号、样式、颜色、材质、成本。
3.2 指标权重系数的确定
针对此案例的德尔菲咨询,共邀请了20 位业内资深专家参与,各专家都具备丰富的电子商务实际经验。其中15 位是淘宝网1 金冠以上店铺或具备1 万以上用户资源的天猫店铺管理负责人,其他5 位专家分别来自于京东、卓越亚马逊网、拼多多等国内知名电子商务网站。
通过两回合专家咨询评价,第二轮专家意见统一系数为0.8172,代表各专家意见已经几乎趋于一致,无需开展第三回合的评定。参与此次评价打分的专家对指标元素的掌握程度都在0.8 以上,并对元素给出结果的根据都大于0.4,说明专家组权威程度较高。第二回合专家评价数值被记录在表1 中。
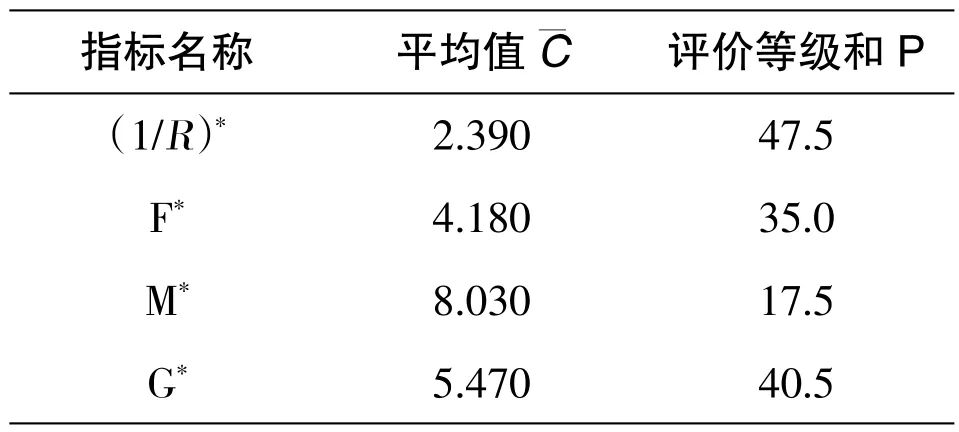
表1 第二轮专家咨询打分统计结果
3.3 网络客户价值的计算

在以上例子中,以Customer_id 为002635 的客户为例,运算获得其网络客户价值是0.319901。
3.3.1 核心网络客户的识别
3.3.2 核心网络客户特征发掘
接下来运用SPSS 公司Clementin11.1 内的C5.0Tree 节点来构建模型,对659 位核心网络客户开展特点辨识,模型为图2 所示。

图2 核心网络客户特征识别模型
经过上述模型构建后获得如图3 表示的规律。在此只要对标识属性是Material 的核心网络客户特征展开研究,注重查阅Rules for Material 该规则的实际特征。从获得的规律集内能够很轻易的得到核心网络客户的行为特点,其中规律“Rule 14 for Material=1”最具代表性(如图4)。贴合规则“Rule 14 for Material=1”共计403 位核心网络客户,且可信度为0.992。所以能够依据其进行以下推断:倘若消费者选择的平角款、最近一次购入时间不长于10周、订单共计金额在134 元以上,且订单毛利率高于0.56,那么就能够断定该消费者偏向于平角款。当消费者下次在店铺内咨询时,客服人员就能够直接向他推荐平角款。

图3 C5.0 算法生成的规则集

图4 Rules for Material=1
4 结语
本文不仅从理论上对网络客户的细分与核心网络客户的特点辨识展开了详明地阐述,并且结合D 天猫店铺开展实证研究。因此,本研究将有利于电子商务企业辨别高端以及核心用户,进而有针对性地进行推荐,高效地维持企业的重要利润来源渠道,进而达成企业与消费者二者的“共赢”。
