Deep imitation reinforcement learning for self‐driving by vision
2022-01-12QijieZouKangXiongQiangFangBohanJiang
Qijie Zou | Kang Xiong| Qiang Fang | Bohan Jiang
1College of Intelligence Science and Technology,National University of Defense Technology,
Changsha,China 2Information Engineering Faculty,Dalian University,Dalian, China
Abstract Deep reinforcement learning has achieved some remarkable results in self-driving.There is quite a lot of work to do in the area of autonomous driving with high real-time requirements because of the inefficiency of reinforcement learning in exploring large continuous motion spaces.A deep imitation reinforcement learning(DIRL)framework is presented to learn control policies of self-driving vehicles, which is based on a deep deterministic policy gradient algorithm (DDPG) by vision. The DIRL framework comprises two components, the perception module and the control module, using imitation learning(IL)and DDPG,respectively.The perception module employs the IL network as an encoder which processes an image into a low-dimensional feature vector.This vector is then delivered to the control module which outputs control commands.Meanwhile,the actor network of the DDPG is initialized with the trained IL network to improve exploration efficiency. In addition, a reward function for reinforcement learning is defined to improve the stability of self-driving vehicles, especially on curves. DIRL is verified by the open racing car simulator(TORCS),and the results show that the correct control strategy is learned successfully and has less training time.
1 | INTRODUCTION
With the development of deep neural network (DNN) [1], a method for reinforcement learning using it, that is deep reinforcement learning algorithm (DRL), was proposed in [2].In contrast to imitation learning (IL), which relies on large amounts of labelled data for good performance [3, 4], DRL does not require the manual collection of large amounts of driving data, but acquires performance through interactive learning [5]. The tremendous success of DRL has attracted widespread attention in the field of self-driving, and researchers have proposed a series of self-driving policies based on DRL. DRL has been used to learn automatic braking [6],safe lane-changing [7, 8], high-speed convergence [9], lanekeeping [10, 11], and urban driving tasks [12, 13]. The most critical challenge of deep reinforcement learning in practice is the large scale, and high dimensional continuous action space,which is time-consuming and prone to cause the local optimality in exploration learning. Therefore, there is a need to reduce the scope of feasible action space to help speed up the exploration. So, the authors introduce IL to solve this problem.
A number of existing studies have also explored the learning efficiency of DRL [14-16], mainly using the demo data for preliminary training or modifications to the experience pool.The authors propose a vision-based deep imitation reinforcement learning(DIRL)framework in order to improve learning efficiency by preliminary training and use a deep deterministic policy gradient algorithm(DDPG)[17]that has a great advantage for continuous decision making[18].The control process of DIRL is divided into two parts, perception module and control module, which consist of IL and DDPG, respectively.Furthermore,the IL network is split into a perception network and an action-generating network.The former is used to build image encoders and the latter produces the control signals and shares weights to initialize the actor network of DDPG.
The contributions of authors can be summarized as: (1)propose a novel DIRL framework to integrate imitation learning and reinforcement learning by network-splitting and weight-sharing for vision-based autonomous driving tasks.The combined performance is better than any of them alone; (2)Divide,the driving process into two parts: perception module and control module. Imitation learning is used to build perception module and DDPG to build control module; and(3) Discuss about reward functions, which are used to make smooth driving of cars.
The work of the authors is organized as follows.Section 2 provides the background knowledge related to imitation learning and reinforcement learning. Section 3 presents the framework of DIRL, the main components and the training scheme. Section 4 presents the experimental results of the method in the open racing car simulator(TORCS)[19].Finally,the entire work is summarized in Section 5.
2 | BACKGROUND KNOWLEDGE
In the DIRL framework, a new approach is adopted that combines the advantages of IL and DRL. IL allows the framework to have an initial performance in a short period of time, and DRL can deal with unknown situations and obtain driving strategies. Therefore, the DIRL framework can not only give play to expert driving experience, but also obtain driving strategies beyond expert demonstration.
2.1 | Imitation learning
IL refers to learning from lots of demonstration data provided by a demonstrator. The demonstration data from human experts is described as decision strategies{τ1,τ2,τ3,....,τm},each one containing a sequence of pairs of states and actions τi=<si1,ai1,si2,ai2,...>, and extracting all state-action pairs to construct a new set D={(s1,a1),(s2,a2),(s3,a3),....}. Typically, the state as a feature and the action as a marker can be used to obtain the optimal policy model by learning.
In the simple autopilot task(Figure 1),the state is the first view image otof each time step t during driving, and the actions atare steering angle, throttle, and brakes, which make up the training data pair D={(ot,at)}Nt=1. The imitation learning strategy function is defined as f =(o;θ) and θ is the network parameter.By treating the imitation learning problem as supervised learning, the goal is to optimize the network parameter θ to minimize the loss function L:

where f =(oi;θ) is the predicted action of the network, and the loss function L is used to minimize the gap between the predicted actions of the network and the expert actions.
The advantage of IL is that it allows agents to quickly obtain expert driving strategies from demonstration data through supervised learning, and therefore IL is widely used for all kinds of driving tasks such as off-road driving [20],following the road[21,22,23],and urban driving tasks[24,25].
2.2 | DDPG algorithm
In a standard reinforcement learning process, an agent needs to interact with the environment e at each time step t, and observes the state st.Then it will map a state to a deterministic action ator a probability distribution over the actions according to its policyπ.As a result,it can obtain the appropriate reward r(st,at) from the environment and the next statest+1.The cumulative reward acquired by an agent in a given time step t is defined as:

where γ ∈[0,1] is the discount factor. The goal of the reinforcement learning task is to learn the optimal strategy π*by maximizing the expected cumulative reward E(R) from the initial state. The training process is shown in Figure 2.
The DDPG separates the exploration of action strategies from the updating of action strategy learning. The action exploration still uses stochastic strategies, while the strategies to be learned are deterministic strategies. Secondly, it introduces the actor-critic [26, 27] framework, which separates the policy network from the value network. Finally, it continues the empirical reuse in the deep Q learning (DQN) [2]algorithm to train the network non-strategically in order to minimize the correlation between samples. It also uses the target Q network to train the network to provide consistent targets during time-differentiated backups. Batch normalization is also added to the DDPG algorithm to prevent gradient explosion.

FIGURE 1 Imitation learning training process
The actor network is updated by the following function(3):

where Q(s,a|θQ) is the direction of the maximum value function passed from the critic network, and ∇θμμ(s|θμ) is the action probability.The update of critic network is similar to the DQN algorithm, which uses the difference between the real value and the predicted value to update the parameters by using function (4) and (5).

where si+1is the next state value of the current state, yiis the real value, and Q(si,ai|θQ) is the predicted value.
The DDPG algorithm uses the empirical replay mechanism to break the correlation between the training experiences, and adopts the target network method to provide consistent goals for the training process. These methods stabilize the entire training process. It has a good processing power for continuous actions and therefore is widely used on self-driving tasks[28].

FIGURE 2 Basic framework for reinforcement learning
3 | DEEP IMITATION REINFORCEMENT LEARNING
3.1 | DIRL framework
The proposed DIRL framework combines IL with DRL by sharing the initial weights of the network. The framework has two parts, perception module and control module, which use imitation learning and deep reinforcement learning DDPG,respectively, as shown in Figure 3.
Typical DRL algorithms use raw images as input to the network, so they consume a lot of computing resources [13].Now the input representation is changed and the perception module is trained by IL to transform the high-dimensional images into low-dimensional feature vectors, which greatly reduces the processing burden of DRL and improves the learning efficiency of the whole framework.
Specifically, a nine-layer IL network is built including five convolution layers and four fully connected layers to train the perception module. The structure is given in Figure 5. Better training results obtained with less data, and the DAgger algorithm[29]is utilized to make the agent recover from errors and improve the performance of IL.After the IL network training was completed, it is divided further into the perception network and the action-generation network. The perception network consists of the first five convolutional layers and the subsequent two fully connected layers, and the action-generation network consists of the last two fully connected layers, as shown in Figure 4.
The control module consists of the DDPG algorithm,which is divided into an actor network and a critic network,and its structure is shown in Figures 6 and 7.The role of the actor network is to generate control commands, and the critic network is to generate the corresponding value for the actions of the actor network and combine them with the acquired rewards. The value generated by the critic network is an important parameter for adjusting the weights of the DDPG network. The actor network has the same structure with the action-generating network, and so, we can say that this part is from the IL network and can be initialized using the weights WILof the action-generating network.

FIGURE 3 The structure of DIRL
Taking advantage of IL, a perception network and an action-generation network can be constructed by collecting a certain amount of driving data. The perception network extracts key information from the images, and the action-generation network initializes the actor-network in the DDPG.This structure allows the perception model and the actor network in the control model to form a complete IL network and has some initial performance, as shown in Figure 3.Reinforcement learning is then used to obtain a better control strategy by introducing exploration noise. This framework saves a lot of exploration time during the initialization process and allows the model to achieve excellent performance in a short period of time.
3.2 | The IL network
The IL network is a convolutional neural network(CNN)that has good processing power for images. With the image convolution processed by CNN,we can directly map the firstperson view of the driving image into the control signals(including steering, throttle, brake) of the self-driving vehicle.The proposed network mainly consists of nine layers of neural networks, including five convolution layers, and four fully connected layers, and the output layer consists of three full-connected networks, corresponding to steering, throttle and brake, respectively. The specific structure is shown in Figure 5.

FIGURE 4 Network splitting and weight sharing in IL

FIGURE 5 The structure of IL
IL can effectively use expert demonstration data to learn driving strategies in a short period of time, and also quickly build image encoder as the perception module. The disadvantages of IL are also obvious, as the performance depends on the quality of the expert data and the generalizability of unknown scenarios is weak. The reinforcement learning can further improve the performance of the model owing to explore unforeseen circumstances.
3.3 | The DDPG network
The DDPG has excellent performance on continuous control tasks and is the controller in the DIRL framework.
The algorithm is divided into an actor network and a critic network. The former receives input from the perception module and generates control commands, while the latter receives control commands from the actor network and the features generated by the perception module to compute Q values for each control signal, and adjust the network weights according to the update functions (3), (4), and (5).
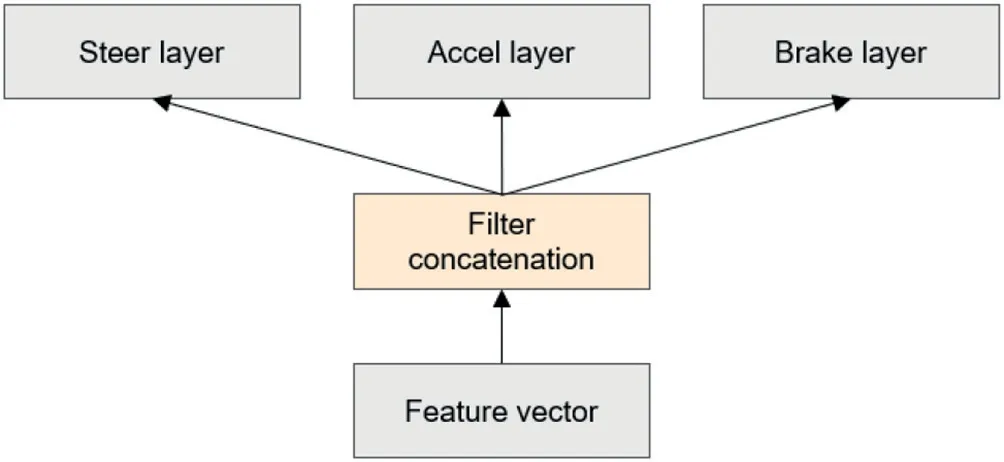
FIGURE 6 The structure of actor network

FIGURE 7 The structure of critic network
In the perception module, we transform the raw images into low-dimensional feature vectors as input to the DDPG network in order to reduce the processing burden of the reinforcement learning network. The actor network is divided into three layers namely an input layer that receives features from the perception module, a hidden layer of a fully connected network to reduce the dimension of the images, and finally an output layer consisting of three fully connected networks corresponding to output steering,throttle,and brakes and this structure is shown in Figure 6.
The critic network consists of a fully connected layer that takes the features from the perception module and the action information from the actor network. Finally, the output layer outputs the values of three actions for the network to learn.The critic network structure is shown in Figure 7.
3.4 | Reward function
Appropriate reward function is the key to learn sufficient policy for reinforcement learning. Most existing reward functions of DRL-based self-driving algorithm generally focused on increasing speed and maintaining lane center [7]. We consider not only the above, but also the stability of the highspeed vehicles.
Firstly,the specific parameters presented in Table 1 are the commonly used reward function and the reward function is shown in Equation (6).

Equation(6)allows the car to drive in the center of the lane by the angle θ between the car and the axial direction of the road, vxis the longitudinal speed of the car, d2measures the extent to which the vehicle remains centrally driven,as defined in Table 1. C is an additional penalty. When a car crashes or derails, additional penalties 200 will be given.
Secondly, the stability of the high-speed vehicles is considered. Human drivers are used to drive a car with the option of accelerating on a straightaway and slowing down on a curve to ensure the stability of the vehicle. Therefore, a new reward function, Equation (7) was defined to encourage the vehicle to learn human habits.

Equation (7) is similar to Equation (6) and the reward function consists mainly of the longitudinal speed vxof the car and the angle θ between the car and the lane, d1is used to determine if there is a curve ahead,while C is the penalty term that works the same as function 6. More importantly, the two switches, I1and I2, are designed to limit the speed. When d1≤10 indicates that the car is at a curve and I1,I2=1, the reward function becomes Equation (8). In this case, the car gets a greater penalty if its speed differs from target speedα.The witch I1limits the car to maintain the speed of α on a curve.

In the second case, 10 <d1≤50; it indicates that the vehicle is going to enter a curve. At this moment, the two switches change states, I1=0 and I2=1, and the reward function becomes into Equation (9). I2encourages the car to fine-tune its direction in preparation to steer into the curve.

When d1>50,it means that the car is traveling in a straight line and there is no curve ahead,so I1,I2=0, and the reward function becomes Equation (10). The speed limit is based on the rules of the road and the state of the vehicle, with no additional limits.The car is encouraged to accelerate according to the traffic rule.


TA B L E 1 The vehicle-related parameters
Then we will experimentally test the applicability of the two reward functions in our algorithm. In our experiments, the target speed α of the car at the curve is set to 50 and β to 200,and both can be adjusted according to the results of identifying traffic signs.
3.5 | Training scheme
There are two stages in the training process of the DIRL framework.The first stage is to collect driving data for training the IL network, which is used to train the perceptual model and then further to initialize the DDPG network. The second stage is to explore and learn from the DDPG algorithm, as shown in Table 2.
4 | EXPERIMENTAL RESULTS
Now, the open-source racing simulator TORCS is used to implement our algorithm and compare the performance with existing algorithms.This section describes about the collection of label data, completion of algorithm training, verification of the applicability of the reward function, and comparison with existed algorithms in terms of convergence efficiency and other performance.
4.1 | The open racing car simulator
The TORCS is the competition software for the simulated car racing championship based on the client-server structure [30].Figure 8 presents the TORCS structure, in which the client is the controller of the vehicle and the server is the centre of the game.

TA B L E 2 The framework of the DIRL
In TORCS,a car perceives the racing environment through a number of sensors to get the status data and then it can perform the driving actions, by following a specific control policy. Image sensors in the proposed experiment,are used to obtain a 64x64 pixel first-person view driving image as the inputs of the algorithm, and both speed and radar sensors are used to obtain the values of distance measurement for the reward function parameters. The data obtained by these sensors are shown in Table 1.
Further,our algorithm simulates the controller to solve the mapping from environment-aware data to driving actions.TORCS also can simulate damage models, collisions, tire and wheel characteristics, aerodynamics, and environmental information,and has a wide range of car models and tracks.So it is a suitable platform for researching self-driving car.
4.2 | Experimental setup
Device configuration The computer used is Ubuntu 16.04,16G of running RAM,a GTX1660super GPU,and an R5-3600 CPU.
DDPG Network Parameters Regular DDPG network parameters are used, and Table 3 shows all the parameters of the DDPG network.
Exploration factors IL is used to initialize DDPG's actornetwork before exploration begins, to supply DDPG with some initial performance. To further improve the model performance,appropriate exploration factors are added to prevent falling into a local optimum. Also, OU noise is used in equations like (11).

FIGURE 8 The structure of TORCS

TA B L E 3 DDPG network parameters

where θ implies how quickly the variable reverts to the mean,μ represents the mean, and σ is the degree of fluctuation of the process. The parameter values used are shown in Table. 4.
Data collection The authors collected 3000 sets of data on each map by recording first-view images of the race car and control commands (steering, throttle, and braking) as the expert data,and then trained the IL network.Since the goal is to train a high-performance IL network with less data, the DAgger algorithm is introduced, which enhances the generalizability of IL by boosting the amount of data with each episode of self-exploration.
Training The authors allow a car to collect exploration data from each episode, and the episode ends when the car crashes into an obstacle or runs off the track.
The return value is obtained by the reward function, and the penalty for hitting or running out of the lane is -200 during training.The model receives images and processes them into low-dimensional vectors by the perception module.Furthermore,the low-dimensional vectors are used as inputs to the control module to generate the action.
The action consists of steering, throttle, and braking commands, as detailed in Table 5.
4.3 | Performance analysis
In accordance with the construction process of the DIRL framework, we first need to build a perceptual model using imitation learning.Now 3000 sets of driving data are collected on each of the three maps of TORCS, and furthermore the DAgger algorithm is introduced to allow the agent to recover from errors. Table 6 shows the amount of data collected at each map and the performance with the DAgger algorithm.The data show that with the training of the DAgger algorithm,the agent can complete the three maps under test and obtain good performance using fewer label data.
Now,the applicability of the reward function(6)is tested in the default map CG SN1 of TORCS,compared DIRL with the DDPG algorithm. It is found that the vision-based DIRL algorithm is not competent for dealing with sharp corners when the car is at high speeds, as shown in Figure 9.
We continue to use the reward function (6), but limit the longitudinal speed to 50 (km/h). The total reward of the two algorithms is shown on the top of Figure 10 and the performance after the training is completed as shown on the bottom of Figure 10.

TA B L E 4 Parameters of OU noise

TA B L E 5 Description of action parameters

TA B L E 6 Imitation learning training

FIGURE 9 Driving scenarios for sharp corners
The results in Figure 10 show that after limiting the longitudinal speed, the vision-based DIRL has a faster learning speed and better performance in shorter training episodes using the reward function (6).
However, we want agents to learn human-like driving habits that allow them to accelerate on straight roads and slow down during turns to ensure safe and stability of driving. We then verified the feasibility and performance comparison of the reward function (7) in our DIRL algorithm.
In three maps from TORCS, we tested and compared our algorithm with the other two algorithms and collected the average rewards per episode as an evaluation metric for learning efficiency. The red line indicates the proposed algorithm, the black line indicates aggregated multi-deep deterministic policy gradient (AMDDPG) [31], and the green line indicates the traditional DDPG in Fig. 11. AMDDPG is based on DDPG and centralized empirical replay to aggregate multiple sub-policies, which are aggregated to save learning time and ultimately converge to the best strategy.
From the training process and test results,the advantage of AMDDPG is that it takes less time to explore the model in the same number of exploration steps because it uses multiple subpolicies simultaneously. AMDDPG requires a common initial weight,which is why it has performance upfront,but the initial weight is difficult to obtain in reality.
Due to the disadvantage of the CNN model, the learning efficiency of DIRL is limited.Therefore,we used improved IL network generalizability to reduce this effect by using DAgger.After training, the first two maps, the performance of the algorithms and the results are shown in Table 7.

FIGURE 1 0 Comparison of the two algorithms under the speed limit condition: (a) and (b) are the convergence and performance comparisons,respectively
In Table 7,we count the total number of episodes of each algorithm trained on the different maps and test the performance of the final model with the completed training. During the testing, the total number of steps and the total reward obtained is recorded, also including whether the car is able to complete the entire map. It can be concluded that the proposed algorithm can achieve high performance in short training episodes,and has an excellent track completion due to the good control of the curve scene.

FIGURE 1 1 Learning curve of three algorithms in three maps.(a),(b),and(c)are overhead views of the three maps;(d),(e),and(f)are the corresponding learning curves of the three algorithms in the three maps

TA B L E 7 Comparison of performancesof three algorithms

FIGURE 1 2 Comparison of performances of DIRL and IL
After IL and DIRL training were completed, the total return obtained after running the model for 300 steps is to observe the performance improvement,as shown in Figure 12.The results show that in the three maps, DIRL improves the performance by 40%, 30% and 60% compared to IL, respectively. Figure 13 shows the driving trajectories of the car, the red indicates the DIRL algorithm, and the green is the IL algorithm.The DIRL algorithm trained the car to drive closer to the center of the lane.From the experimental results,it can be seen that our proposed vision-based DIRL algorithm is able to make the car learn to drive safely faster by inputting only the first-view image.
4.4 | Experimental analysis
During the experiment, the performance of the IL model has an impact on the learning rate of DIRL. Although we only collected a small amount of data to train the IL,it still showed the excellent learning speed and performance of DIRL.
Traditional DRL has the large search space,which causes it to converge slowly and limits its application. We adopt a new way to resolve this problem. The DIRL organizes IL, the supervised learning, with the unsupervised DRL, to improve the learning efficiency. The specific summary is as follows:
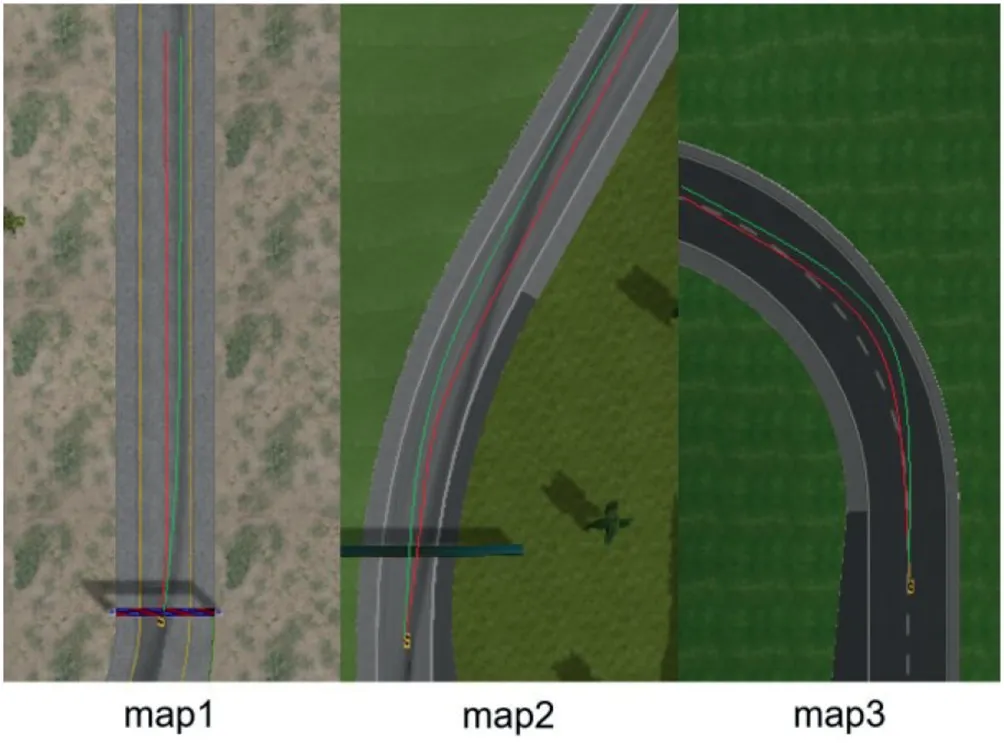
FIGURE 1 3 Car driving track in three maps
(1) Compared with DRL,the DIRL initialized by IL,keeps the car driving in the centre of the lane with an average performance improvement of 50%.
(2) The DIRL algorithm has a faster learning efficiency than the traditional DDPG and AMDDPG algorithms,and can achieve higher performance through short episode training, boasting an average 50% efficiency gain on the training episode.
(3) The applicability of the new reward function,Formula 7,is verified closer to human driving habits than Formula 6.Our trajectory is smoother.
(4) The other conclusion shows that the DAgger algorithm has a very positive impact on DIRL performance,so as to the DIRL could gain the excellent learning speed and performance by a small amount of data. In our experiments we collected only 3000 sets of experimental data in each map to achieve excellent performance.
5 | CONCLUSIONS
The authors proposed a vision-based DIRL framework.DIRL combines IL with reinforcement learning in a new way. The self-driving control is divided into a perception module and a control module,while the perception model was trained by IL,and control model was based on DDPG. We validate and compare the feasibility and performance of the proposed algorithm in TORCS.From the results,it can be concluded that the proposed algorithm is more efficient in learning and can drive safely by relying only on the first view image.
However, there are still some limitations to our approach.The predicted oscillations of the CNN network make it difficult for the control model to output the correct control commands, which limit the performance of the model. The solution to this problem is to increase the training data of the IL to make it more generalized; the second is to replace CNN with a sequential model that predicts smaller oscillations. In the future, some new data would be added as an adjunct to the image data to further enhance the scope of the algorithm's use.
ACKNOWLEDGEMENTS
This research was supported by the Liaoning Provincial Natural Science Foundation project, No.: 2019-zd-0578; Research on Abnormal Driving Behavior recognition and Cooperative control Mechanism for intelligent Driving System.
ORCID
Kang Xiong https://orcid.org/0000-0002-8716-6809
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- An efficient hybrid recommendation model based on collaborative filtering recommender systems
- Design and analysis of recurrent neural network models with non‐linear activation functions for solving time‐varying quadratic programming problems
- Different hybrid machine intelligence techniques for handling IoT‐based imbalanced data
- Steganography based on quotient value differencing and pixel value correlation
- D‐BERT:Incorporating dependency‐based attention into BERT for relation extraction
- Modified branch-and-bound algorithm for unravelling optimal PMU placement problem for power grid observability:A comparative analysis