基于改进SSD模型的交通标志检测算法
2022-01-11梁正友耿经邦孙宇
梁正友,耿经邦,孙宇
(广西大学计算机与电子信息学院,南宁 530004)
0 引言
目标检测是当前计算机视觉领域一个热门的研究方向。目标检测的主要任务是从图像中找出目标物体,并表示出该物体的位置和大小等信息。随着近年来深度学习技术的迅速发展,相关研究人员也开始从传统的手工特征目标检测算法转向了基于深度学习的目标检测算法的研究。深度学习算法能够避免繁琐的手工特征提取过程,且检测效果在一定程度上超过了传统算法。当前,基于深度学习的目标检测算法主要分成twostage 和one-stage 两种。two-stage 将目标检测任务分成两个阶段。第一个阶段的目标是确定目标物体的候选区域(region proposals),第二个阶段对候选区域进行位置精修和分类。two-stage 的代表算法有RCNN、SPPNet、Fast RCNN、Faster RCNN、RFCN 等。虽然以Faster RCNN 为代表的算法实现了端到端的训练,但是由于网络结构复杂,很难达到实时性要求。one-stage 则不需要确定目标物体的候选区域,而是直接计算出目标物体的类别概率和位置区域坐标。one-stage 的代表算法有YOLO[1]和SSD[2]。YOLO 舍弃了候选区域的建议,简化了网络,提高了检测速度,但是限制了模型对临近物体的目标预测能力,定位准确度有所下降。SSD 结合了Faster RCNN 和YOLO 的优点,并借鉴了RPN(region proposal networks)的思路,在保证检测精度的同时提高了速度。之后,Fu 等人[3]提出了模型DSSD,使用残差神经网络Residual-101 替换原有的VGG16[4],并引入了反卷积模块,虽然改进后的模型提高了检测精度,但速度有所下降。Jeong 等人[5]提出的R-SSD 模型也存在同样的问题。在上述算法中,SSD 的性能相对较好,结合了YOLO 回归思想和anchor 机制,提高了模型的实时性和准确性。
目前很多学者将基于深度学习的目标检测方法应用到交通标志检测中。Zuo 等人[6]采用Faster R-CNN 检测算法对交通标志进行目标检测,取得了较好效果,但是目标检测速度方面有一定局限性。Wang 等人[7]使用YOLOv2 网络对视频中物体进行检测识别。Shan 等人[8]提出了一种改进SSD模型,通过将不同层次的特征信息进行融合,并采用迁移学习的方法对模型进行训练,缩短了模型的训练时间,提高了对小目标的检测能力。鲍敬源等人[9]提出了一种Strong Tiny-YOLOv3 目标检测模型,通过引入FireModule 层进行通道变换,加深网络模型的同时减小了参数,并在FireModule层之间加入了short-cut增强网络的特征提取能力。任坤等人[10]在MobileNet2-SSD 网络的基础上,对多尺度像素特征进行融合,并在检测层引入了通道注意力机制,在保证算法实时性的同时,提高了目标检测准确率。
上述算法在交通标志检测任务中取得了一定成果。但是交通标志采集的环境较为复杂,使得采集到的交通标志样本在图像中所占的比例差异较大,若算法的候选区域与目标物体的尺寸差异较大,则会影响算法的检测效果。此外,在采集到的样本中,部分样本的交通标志在图像中所占的比例较小,导致了算法较难检测到图像中的目标物体。
针对上述问题,本文在SSD 模型的基础上同时引入了FPN(Feature Pyramid Networks)算法[11]和Kmeans 聚类算法[12],提出了基于改进SSD 网络的交通标志检测算法。通过在CCTSDB 交通标志数据集[13]上的实验结果表明,本文提出的聚类多特征SSD模型在交通标志上有较好的目标检测效果。
1 SSD网络
SSD[2]是一种单次多框实时检测深度神经网络模型,具有速度快以及检测准确率高的优势。SSD 是一种基于回归的目标检测算法,实现了端到端的目标检测,并引入了anchor理念。
SSD 主要由两部分构成:一部分是用VGG16当作基础网络的特征提取网络模型,将FC6 和FC7 换为Conv6 和Conv7,去掉FC8;另一部分是末端添加多个级联卷积层Conv8_2、Conv9_2、Conv10_2和Conv11_2。SSD网络模型如图1所示。
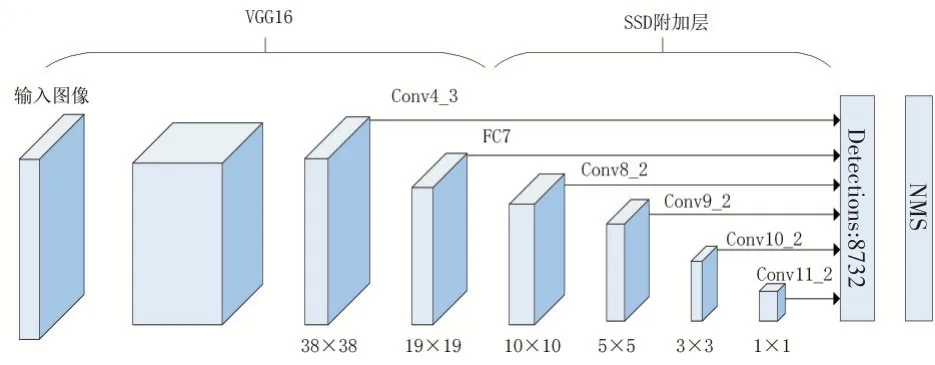
图1 SSD网络模型
在SSD300[2]算法中,首先将输入图片统一处理为38× 38,然后经过基础网络VGG16 和后端一组级联神经网络操作处理后,将其中的六层卷积结果提取出来进行目标预测,这六层分别为Conv4_3层、FC层、Conv8_2、Conv9_2、Conv10_2和Conv11_2。
2 改进的SSD模型
2.1 特征金字塔
SSD 算法针对小目标检测精度不高,易出现误检漏检的情况,因此需要对大小不同的特征图多次预测。这些大小不同的特征图相对孤立,经过特征提取后的信息无法充分使用。文章借鉴特征金字塔的思想,在SSD 网络中引入FPN 算法,将网络深层信息逐层反卷积与前一层网络进行深度拼接,使模型能够融合多个卷积层的多尺度信息来增强特征的表达能力,提高算法对小目标物体的检测准确率。
2.2 Kmeans聚类分析候选框设置
原始SSD采用默认框生成机制进行目标检测,默认框基准大小为sk:


2.3 模型设计
本文将从两个方面对SSD 模型进行改进。①借鉴特征金字塔思想,引入FPN 算法,将高层语义信息和浅层细节信息结合起来,增强特征表达能力。②利用Kmeans聚类算法确定默认框窗口大小,得出较为适合于当前数据集的的比例值,提高模型的检测准确率。本文提出的模型聚类多特征SSD 是在原始SSD 的基础上同时加入特征金字塔FPN算法和Kmeans聚类算法,则将只加入特征金字塔FPN算法的模型称为多特征SSD。
加入FPN 算法后的多特征SSD 网络结构如图2所示。Conv 1×1表示大小为1×1的卷积操作,使得经过卷积输出和反卷积输出后的特征图具有数据一致性;⊕实现反卷积输出的特征图与侧向连接输出的特征图对应元素的线性叠加;Detections表示预设候选框的目标个数;NMS 表示非极大抑制。多特征SSD 网络由原始SSD 网络实现浅层到深层的特征提取,2×up 实现由深层到浅层的反卷积操作,Conv 1×1 和⊕实现特征金字塔的侧向连接。
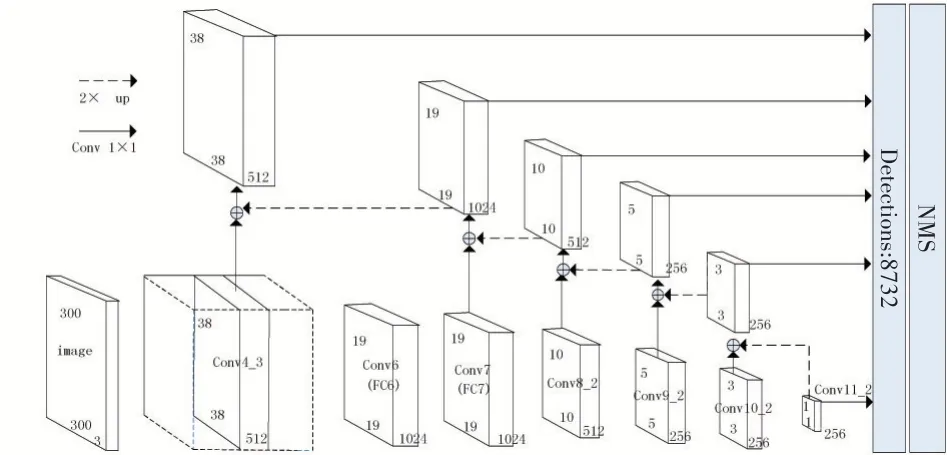
图2 多特征SSD网络结构
3 实验
本次实验的环境如下:实验的操作系统环境为Centos 6.5,利用Keras 2.3.1 完成模型的搭建,编程语言为Python 3.6,模型训练的主要硬件设备为NVIDIA TESLA T4。
3.1 实验数据
本文实验使用的数据集是CCTSDB,CCTSDB数据集共15724 张图像,其中包含原始图像和经过拉伸、调整亮度后的图像。该数据集将交通标志分为指示(mandatory)、警告(warning)和禁令(prohibitory)三类,共15000 多张图片,包括不同环境类型的自然交通场景。
3.2 实验建立
本文实验选用CCTSDB 交通标志数据集进行模型训练。在本文实验,初始学习率设置为0.001,训练总轮数为20000,批次设为32,参数是反复实验决定的。
3.3 评价指标
本文利用检测平均精度均值(mean average precision,mAP)和检测速度两项指标对算法性能进行评估。mAP 主要用于评价算法的检测准确率,计算方法为对三大类交通标志平均检测精度(average precision,AP)求取均值。检测速度主要用于评价算法的实时性能,本文实验选用的速度评价指标是处理每张图片的消耗时间,以秒为单位,用时越少,速度越快。
3.4 实验结果与分析
在CCTSDB 数据集上对改进后的模型聚类多特征SSD 进行训练。表1 展示了在CCTSDB 交通标志数据集上模型聚类多特征SSD 和其他前沿学习方法的性能对比。

表1 CCTSDB数据集上与其他前沿方法实验结果对比
在表2 的对比方法中,Shan 等人[8]提出的改进SSD、鲍敬源等人[9]提出的Strong Tiny-YOLOv3和任坤等人[10]提出的MobileNet2-SSD 网络都是通过对经典目标检测网络进行改进,在交通标志目标检测中取得了一定成果。但是在这些方法在检测前并没有找到一个适合相应数据集的目标窗口尺寸,且在面对小目标检测时仍存在一定局限性,因此检测效果的提升较为有限。而本文通过在原始SSD 网络中引入特征金字塔算法,将网络深层信息逐层反卷积与前一层网络进行深度拼接,使模型能够融合多个卷积层的多尺度信息来增强特征的表达能力,实现了特征增强,并采用Kmeans聚类算法确定默认窗口大小,得出较为适合于当前数据集的的比例值,提高模型的检测准确率。从表中的实验结果可以看出,本文提出的聚类多特征SSD 模型在CCTSDB 交通标志数据集上的mAP达到了93.58%,优于前沿的交通标志检测方法。
为了充分证明本文所提模型聚类多特征SSD的有效性,本文对模型聚类多特征SSD 进行了消融实验,验证模型加入某一模块后对整体的影响。本文提出的模型聚类多特征SSD 是在原始SSD 的基础上同时加入特征金字塔FPN 算法和Kmeans聚类算法,则将只加入特征金字塔FPN 算法的模型称为多特征SSD。由于在原始SSD 的基础上加入新的模块,理论上多特征SSD 和聚类多特征SSD 的模型复杂度会有所增加,对检测时间也会有一定影响,所以除了比较检测精度之外,实验还需要对检测时间进行对比。
图3 展示的是在CCTSDB 交通标志数据集上原始SSD、多特征SSD 和聚类多特征SSD 的模型损失随着迭代次数递增的效果图。随着迭代次数的递增,原始SSD、多特征SSD 和聚类多特征SSD 的损失不断降低,相对而言,聚类多特征SSD 的损失小于原始SSD 和多特征SSD,模型效果更好。
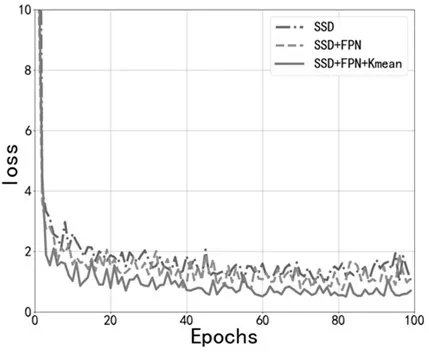
图3 不同模型损失变化
表2 展示的是在CCTSDB 交通标志数据集上原始SSD、多特征SSD 和聚类多特征SSD 的实验结果比较。实验结果表明,多特征SSD 相比原始SSD 的三大类检测精度以及mAP 均有所提高,多特征SSD 的mAP 达到了89.72%,比原始SSD 高了2.84%。聚类多特征SSD 的mAP 达到了93.58%,比多特征SSD 高了3.86%。聚类多特征SSD 相比原始SSD和多特征SSD的检测效果更好。
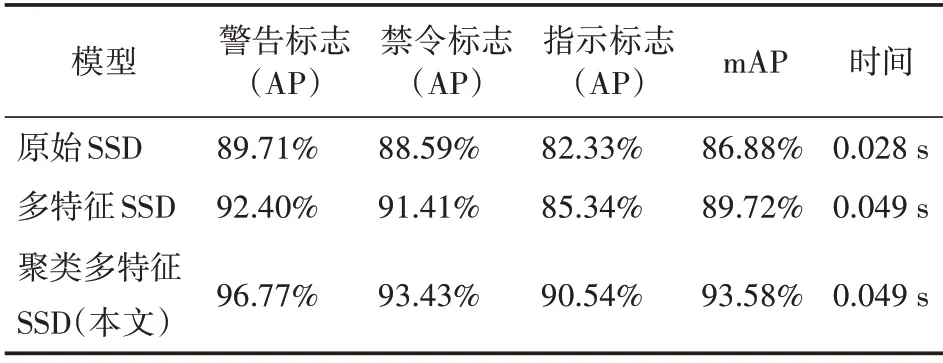
表2 CCTSDB数据集上不同模型实验结果对比
测试时间上,多特征SSD 与原始SSD 相差了0.021s,可能是由于相比原始SSD 使用了多特征融合,增加了模型复杂度,在提升mAP 的同时影响了检测速度。聚类多特征SSD 在多特征SSD 的基础上采用Kmeans 聚类算法确定默认窗口大小,在保持检测时间不变的同时,目标检测精度得到明显提升,充分说明了Kmeans 聚类算法的有效性。
在CCTSDB 交通标志数据集上的实验结果表明,多特征SSD 的性能要优于原始SSD,同时加入了特征金字塔和Kmeans聚类算法的模型聚类多特征SSD 相比多特征SSD 和原始SSD 而言性能上要更好。由于聚类多特征SSD 同时加入了FPN 和Kmeans聚类两个改进方法,且聚类多特征SSD的网络性能又最佳,所以在CCTSDB 交通标志数据集上的对比很好地达到了消融实验的效果。
4 结语
为了进一步提高交通标志检测准确率,本文在SSD网络基础上引入了FPN算法和Kmeans聚类算法,以提高网络对交通标志的目标检测能力。改进后的网络模型检测准确率有了明显提高。虽然提升了模型的检测准确率,但是增加了模型复杂度,实时性方面有一定局限性。因此,如何在保证检测准确率的前提下,降低模型复杂度,减小算法所需时间和计算资源,更好地满足实时性应用和需求,将是下一步的研究方向。
