基于改进YOLOv3的符号型交通标志牌识别算法
2022-01-10王保柱李佳南远松灵李玉倩
王保柱,李佳南,远松灵,李玉倩
(1.河北科技大学 信息科学与工程学院;2.石家庄市京华电子实业有限公司,河北 石家庄 050000)
目前,符号型标志牌的识别方法可分为两种:①机器学习方法,主要通过提取交通标志牌的颜色、形状等显著特征,然后应用训练好的分类器进行目标分类、识别。此方法需要大量的手工计算,且不能适用于大规模数据集;②深度学习的方法,主要利用卷积神经网络的框架,不需要人工定义特征,网络通过不断的学习训练完成目标识别。基于此,文献[1]采用GIST描述符作为特征提取,并结合SVM、k-NN和ELM等分类模型进行分类,其主要目的是降低模型的计算量。YOLO (You Only Look Once)是一种基于单状态的对象检测[2,3]算法。近年来,单级探测器在多尺度检测方面取得了新的进展,对小目标的检测问题得到了广泛的解决。
根据上述讨论,笔者提出基于YOLOv3的符号型交通标志牌识别算法。重点在模型架构方面进行了改进。笔者对YOLOv3模型中结构较复杂的征提取层Darknet-53替换成一种轻量级网络MobileNetv3,基于此,既保证了算法的识别准确率,又减轻了网络架构和计算量。
1 相关工作
1.1 YOLOv3识别算法
YOLOv3是一个全卷积的网络。整个架构可以分为3个主要部分:一个是命名为Darknet-53特征提取器、一个检测器和一个分类器。①图像输入网络,会通过Darknet-53特征提取器,形成不同的尺度来提取图像特征;②将属性映射提交到检测器,以获得有关边界框位置的信息;③由分类器决定所得到的信息属于哪一类。该网络模型中多数为卷积层,后面还包含残差层[4]、上采样层和跳跃连接。网络结构如图1所示。

图1 YOLOv3网络
YOLOv3算法的显著优点是网络只需要完成一次前向传播,就能够得到单一图像中的多目标检测结果。模型能够对输入图像的全部场景和目标进行分析,同时生成多个特征进行预测。此方法相对于滑动窗口需要对单一图像进行多次迭代的方法更高效。
1.2 MobileNetv3网络
随着深度学习被广泛应用于移动终端,轻量级的移动网络不断提升。MobileNetv1[5]借鉴了传统的VGG体系结构,并增加了深度可分离卷积。在此基础上,引入了MobileNetv2[6,7],该网络具有线性瓶颈的倒残差结构。2019年MobileNetv3得到进一步开发,借助NAS和NetAdapt网络搜索进行网络优化,使用hard-swish非线性激活函数代替ReLU,有效改善网络效率和相对精度。MobileNetv3网络结构如图2所示。
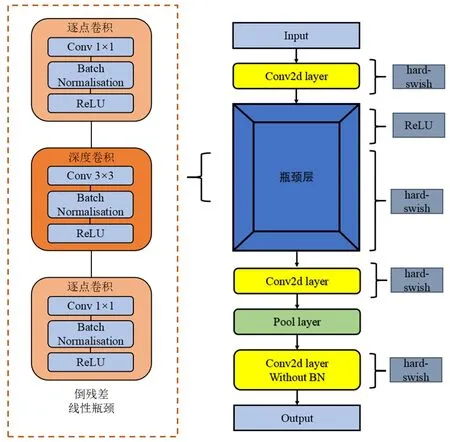
图2 MobileNetv3网络结构
1.2.1 深度可分离卷积。深度可分离卷积与传统卷积每层只需要计算一次不同,深度可分离卷积的计算包含两个步骤:①深度卷积对每个输入通道应用一个卷积滤波器进行滤波;②对所有通道应用逐点卷积来合并深度卷积的输出。此做法能够减少计算成本和提高计算效率。
1.2.2 瓶颈层。MobileNetv2提出了线性瓶颈来降低输入的维数,以减少在高维空间提取特征丢失信息的情况。线性瓶颈是一个带滤波器的卷积层,与线性激活函数相结合。
1.2.3 倒残差。瓶颈层的开始还包含一个扩展层,MobileNetv2在瓶颈之间使用快捷的直接连接的方法有效防止梯度损失和爆炸。
1.2.4 网络架构搜索。MobileNetv3应用网络架构搜索以选择最优的体系结构,这是一种选择神经网络结构的搜索空间,通过强化学习在搜索空间中有效搜索,以达到最佳结构模型。
1.2.5 激活函数。为了获得更高的精度,引入了新的激活函数swish来代替ReLU函数。这个函数被定义为:
swishx=x·σ(x)
但是,swish中的sigmoid函数在移动端会消耗大量的计算成本,因此MobileNetv3使用ReLU6函数来近似swish中的sigmoid函数,称为swish的硬版本(hard-swish)定义为:
1.3 改进后YOLOv3识别算法
由于YOLOv3中的特征提取器Darknet-53,结构较复杂,计算成本大。因此,笔者采用轻量级的MobileNetv3替换YOLOv3的特征提取层,并将两种网络模型相融合。改进后的算法结构如图3所示。

图3 改进后YOLOv3算法结构
改进后的网络首先使用MobileNetv3提取图像特征,特征提取后继续应用类似特征金字塔(FPN)的多尺度检测方法,结合残差网络将图片转化成三个不同尺寸的特征,将提取的特征用于进一步检测每个网格单元中的目标。
2 交通标志牌识别算法实现
2.1 数据集
为了使算法更具实际应用价值,参考公开的GTSRB、GTSDB数据集的基准,采集我国的交通标志牌图像,作为本文的数据集。在数据集创建的过程中,首先通过车载相机拍摄标志牌图像,然后使用LabelImg工具对图像进行标注分类。
2.2 实验过程
改进后的算法在本文创建的交通标志牌数据集的950张图像上进行训练。训练过程中,数据集被划分为训练集70%,测试集20%,验证集10%。设置网络进行500 epoch的训练,batch sizes大小为23。使用Adam优化器并设置初始学习率为0.001。为了避免过拟合,自适应地调整学习率。
2.3 实验结果与分析
网络训练过程中,通过不断迭代获得改进后YOLOv3算法的最优模型。识别结果如图4所示。

(a)小目标识别结果

(b)大目标识别结果
结果显示,符号型交通标志牌可被正确地识别。为了进一步评价文中改进的YOLOv3算法的识别性能,应用同一数据集对传统的YOLOv3算法进行测试,进而对比两种模型的各项指标,实验结果如表1所示。

表1 算法改进前后的试验结果对比
表1中的数据清楚表明,改进前后的网络模型都能够很好的识别符号型交通标志牌。改进后算法的识别精度增加了1.19%,增长幅度不大,但是模型的大小明显得到压缩,从原始的234MB降至35MB,所占内存仅有35MB,使算法能更好地应用于移动设备。基于此,网络的识别速度也从120.35ms减少至40.52ms,大大提高了网络的运行效率。
3 结束语
①笔者基于YOLOv3算法模型进行符号型交通标志牌的识别,并对网络架构进行了优化,该算法的识别结果在保证准确率的必要前提下,识别速度显著提高。 ②将原有YOLOv3算法特征提取层Darknet-53替换为一个轻量级的MobileNetv3网络,通过改变YOLOv3的模型架构,以大大减少算法计算成本,优化识别效率。通过实验证明,此算法可以广泛应用于汽车移动端实时性检测和移动终端嵌入,具有较强的鲁棒性。③由于技术知识有限,数据集的采集条件多为良好的环境,接下来,会进一步增强数据样本的复杂性和实用性。
