基于NER和TF/IDF算法的涉密文件的脱密鉴别方法研究
2022-01-10李云亚
王 雷,李云亚
(江苏金盾检测技术有限公司,江苏 南京 210042)
1 网络泄密的典型案例
以文字、图表、音像及其他记录形式记载商业、军事、国家秘密内容的资料被称为涉密文件,国家安全利益、企业商业利益直接与这类文件存放是否得当相关联[1]。随着网络以及各类应用的发展,涉密材料往往在网络渠道传播、流传过程中,由于其中一人疏忽,造成整个安全屏障的破坏而引发泄密事件。
案例二:2018年4月,某市机要部门通知某局涉密文件专管员周某紧急取涉密文件。由于周某临时有手头工作,便找来刚刚入职的司机赵某代领。接受“重要任务”的赵某受宠若惊,取件返回途中,将3份机密文件打开,拍照后,上传至微信群,造成泄密。
这些案例都是网络泄密的典型例子,而且往往是涉密材料已经传播一定的范围之后,才能引起相关部门的注意并采取相应的措施。在公开网络产生泄密事件处理过程中,最重要的因素是在泄密材料出现于公开网络并广泛传播之前,发现并确定传播材料是否涉密、可能的来源以及相应的密级。因此,涉密文件的鉴别与响应速度是关键的要素。但是,涉密文件在传播前经常往往会被刻意地去除保密标记、密级以及相关的信息,使得涉密文件鉴别较为困难。同时又因为涉密文件来源众多,确定文件的来源不易,进一步造成涉密文件鉴别的难度。因此,有必要构建一个统一的涉密文件快速鉴别与响应平台。通过统一的平台实现可以随时监控在公开网络中出现的各类电子文件与相关材料,并快速予以鉴别。对于可能的涉密文件发出预警信息。
本文提出一种基于NER和TF/IDF算法的涉密文件的脱密鉴别方法,利用NER和TF/IDF算法识别涉密文件中的命名实体,构成矩阵,经过HASH脱密,发送统一中心平台存储。鉴别时,取出文件中各命名实体对应的TF/IDF值乘以出现的次数并求和,其值跟预先设定的阈值比较,以此来确定是否为涉密文件,从而进一步判断涉密文件的来源。
2 数据脱密的相关研究
在网络环境的高度开放性面前,涉密文件保密工作显得十分被动,面临严峻考验,如何避免重要文件信息遭到泄漏和窃取成为关乎各单位生存发展的重要课题[2]。在公开网络产生泄密事件处理过程中,在涉密文件广泛传播之前鉴别出材料为涉密文件是关键的要素。由于鉴别文件之前需要对涉密文件进行脱密处理,所以脱密技术成为鉴别的关键。脱密是国内外普遍采用的地理信息安全保密技术手段,目前已有很多关于脱密技术的研究。
部分学者对数据脱密展开了研究,具体如下:李安波等[3]为实现精度可控矢量地理数据脱密处理,提出基于Logistic混沌系统的干扰脱密方法和基于辅助点的精密控制方法。闫娜[4]实现了以数据拓扑结构不改变为前提,以密钥为依据对DOM数据进行脱密,同时可用密钥进行恢复。谢年[5]分别对每个网格内要素的节点和相对坐标进行偏移,改变了每个要素节点的绝对坐标和相对坐标,脱密程度较高,且不可逆。
TF/IDF算法和NER也是本文提出方法的重要基础。赵晓平等[6]针对海量短文本,传统文本聚类算法存在聚类性能差的问题,融合TF-IDF方法和词向量,提出一种新的短文本聚类算法。李昆仑等[7]为了提高推荐系统的精度,提出了一种基于注意力机制与改进TF-IDF(AMITI)的推荐算法,通过注意力机制和AMITI算法分配权重,加强模型的特征挖掘能力,从而提高推荐精度。Bikel[8]于1999年提出基于隐马尔科夫模型的IdentiFinderTM系统,识别和分类名称、日期、时间和数值等实体,是最早的命名实体识别。Yamada等[9]针对日文提出一个基于SVM的命名识别系统,此系统为Kudo的分块系统的扩展。之后随着深度学习的兴起,NER结合深度学习方法称为该领域研究的重点。
3 涉密文件的脱密鉴别方法
由于涉密文件的特殊性,显然不可能将所有的涉密文件明文统一集中存储并予以比对,因为会造成机密集中存储的风险,因此本文提出采用一种基于NER与TF/IDF算法实现对涉密文件的鉴别。
不少人把“一个角色59个演员”当成笑话看,对何翔一家给予各种调侃。据称,原本何翔在学校各方面都很优秀,这次却因为这部电影遭到了同学们的嘲笑,变得闷闷不乐。看到网友评论,估计一家人更会着急。
3.1 基于NER的涉密文件处理
命名实体识别(Named Entity Recognition,简称NER)是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。命名实体识别旨在从属于预定义语义类型(如人、位置、组织等)的文本中识别刚性指示符。NER不仅是信息提取的独立工具,而且在文本理解、信息检索、自动文本摘要、问答、机器翻译以及知识库建设等方面多有运用。
NER中应用的技术,主要有4种:(1)基于规则的方法,由于依赖手工规则,不需要注释数据。(2)无监督学习方法,它依赖无监督算法,没有手工标记的训练例子。(3)基于特征的监督学习方法,它依赖于经过仔细特征工程的监督学习算法。(4)基于深度学习的方法,以端到端方式从原始输入中自动发现分类或检测所需的表示。
命名实体是一个单词或短语,从一组具有类似属性的其他项中清楚地标识一个项。命名实体的例子有一般领域中的组织名称、个人名称、地点名称;生物医学领域的基因、蛋白质、药物和疾病名称。NER是将文本中的命名实体定位和分类为预定义实体类别的过程,其应用类型如图1所示。
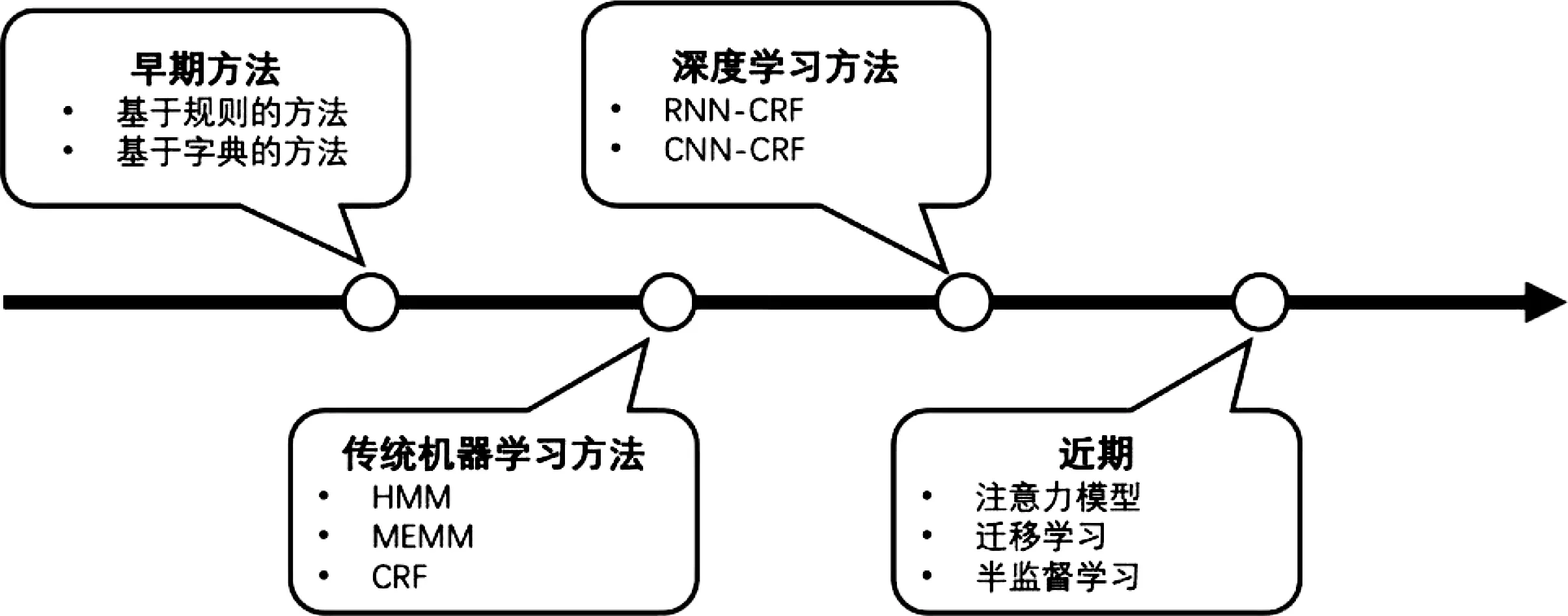
图1 NER应用类型
基于NER的涉密文件处理的基本思想就是将各涉密单位的涉密文件库中的涉密文件取出,通过NER识别文件中的实体,统计每篇文件中各实体出现的次数与值对,然后构建矩阵,再将矩阵按行进行归一化,即第i各列除以第i行各列总和。基于NER的涉密文件处理流程如图2所示。加,但同时会随着它在语料库中出现的频率成反比下降。TFIDF算法的思想就是一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章,这也就是TF-IDF的含义。

图2 基于NER的涉密文件处理流程
TF-IDF分为词频(Term Frequency,TF)和逆文件频率(Inverse Document Frequency,IDF)两个概念。
3.2.1 TF
TF表示词条在文本中出现的频率,这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。TF用公式表示如下:

3.2 基于TF/IDF算法的涉密文件脱密鉴别
其中,ni,j表示词条在文档中出现的次数,TFi,j就是表示词条在文档中出现的频率。但是,需要注意,一些通用的词语对于主题并没有太大的作用,反倒是一些出现频率较少的词才能够表达文章的主题,所以单纯使用TF是不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。
词频-逆向文件频率算法(Term Frequency-Inverse Document Frequency,TF/IDF)是一种用于资讯检索与资讯探勘的常用加权技术。文件的重要程度对涉密文件来说是十分重要的信息,可以通过 TF-IDF这种统计方法来评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增
3.2.2 IDF
如果包含词条i的文档dj越少,IDF越大,则说明该词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
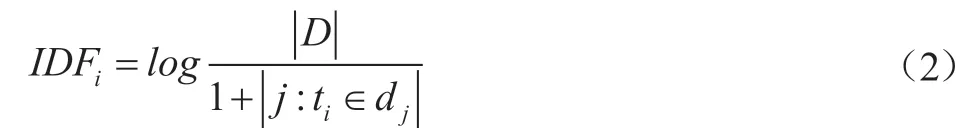
其中,∣D∣表示所有文档数量,∣j∶ti∈dj∣表示包含词条ti的文档数量,这里的加1主要是防止包含词条ti的数量为0从而导致运算出错的现象发生。
4 基于NER和TF/IDF算法的涉密文件的脱密与建模
鉴于上面介绍的两种方法,本文提出一种基于NER和TF/IDF算法的涉密文件的脱密鉴别方法,利用NER和TF/IDF算法识别涉密文件中的命名实体,构成矩阵,经过HASH脱密,发送至统一中心平台存储。鉴别时,取出文件中各命名实体对应的TF/IDF值乘以出现的次数并求和,其值跟预先设定的阈值比较,以此来确定是否为涉密文件,从而进一步判断涉密文件的来源。基于NER和TF/IDF算法的涉密文件的脱密鉴别框架如图3所示。

图3 基于NER和TF/IDF算法的涉密文件的脱密鉴别框架
整个涉密文件的脱密流程分为两个大部分:(1)对涉密文件的处理。(2)对文件的脱密鉴别。
4.1 涉密文件具体步骤
(1)将各涉密单位的涉密文件库中的文件依次取出,并通过NER识别文件中的实体,统计每篇文件中各实体出现的次数与值对<E,C>,其中E是实体命名,C为实体在该文件中出现的次数。
(2)构建矩阵,其中每行i代表一篇文件,各列j为涉密文件库中所有实体命名,<i,j>为该实体命名实体j在文件i中的出现次数,按行进行归一化,即第i各列除以第i行各列总和。
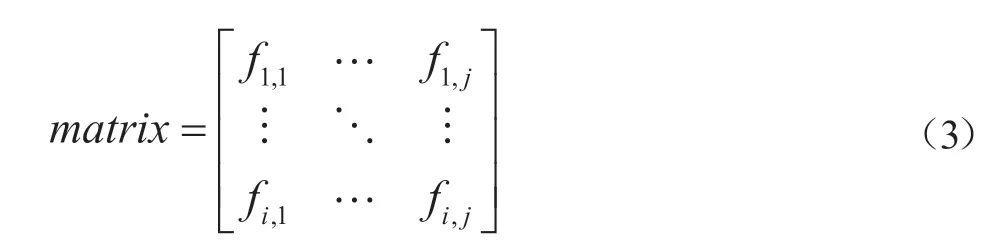
(3)根据上述的统计结果,调用TF/IDF算法云计算该单位的涉密文件中各命名实体的TF/IDF值并对命名实体进行HASH脱密。
(4)将构建完成的矩阵与各值对序列发送到统一中心平台存储。
4.2 文件的脱密鉴别具体步骤
(1)通过NER算法对待鉴别的文件材料进行处理,提取出其中的命名实体以及各命名实体出现的次数,通过查找,按来源单位依次取出各命名实体对应的TF/IDF值乘以出现次数并求和。
(2)若求和的值大于一定的阈值,则可能为涉密材料,进一步判断涉密材料的来源。
(3)对于文件材料中命名实体及出现的次数进行归一化,形成一个向量V,查询存储在库中的各单位涉密文件的脱密矩阵,进行投影操作,取出待鉴定材料中命名实体组成的子矩阵,遍历子矩阵中每一行向量,通过余弦相似度判断待鉴别材料与各行向量代表的涉密文件的相似度。

(4)按相似度选出前N个行向量,按各行向量对应的文档来源进行分类,来源分类中包含行向量数越多的,待鉴定材料来源可能性越高。
5 结语
本文针对涉密文件泄露时无法快速集中地鉴别涉密文件,判别涉密文件来源,以防止涉密文件进一步散播的现状,提出一种基于NER和TF-IDF算法的涉密文件集中脱密鉴别方法。该方法简单快速,能有效预防涉密文件的泄露或者能有效鉴别出已泄露的涉密文件,从源头切断,防止进一步散播。该方法构建一个统一的涉密文件快速鉴别与响应平台,通过统一的平台实现随时监控在公开网络中出现的各类电子文件与相关材料,快速鉴别并对于可能的涉密文件发出预警信息。
