Behavior recognition algorithm based on the improved R3D and LSTM network fusion①
2022-01-09WuJinAnYiyuanDaiWeiZhaoBo
Wu Jin(吴 进),An Yiyuan,Dai Wei,Zhao Bo
(School of Electronic and Engineering,Xi’an University of Posts and Telecommunications,Xi’an 710121,P.R.China)
Abstract
Key words:behavior recognition,three-dimensional residual convolutional neural network(R3D),long short-term memory(LSTM),dropout,batch normalization(BN)
0 Introduction
Due to the increasingly high status of video human behavior recognition in the field of artificial intelligence,people’s demand for behavior recognition intelligent system is growing.Therefore,video based behavior recognition is widely used in human-computer interaction,social public security,intelligent security and other fields[1].Currently,the traditional algorithms for human behavior recognition include histogram of optical flow (HOF)[2], dense trajectory(DT)[3],motion history image(MHI)[4]algorithm.Scale invariant feature transform(SIFT)[5],spacetime volume(STV)[6]and dense trajectories(DT)[7]proposed by other scholars are classified after feature extraction.
In recent years,with the increase in the number of videos,the computer performance has improved rapidly,which has brought great help to the development of deep learning,and solved the problems of less data sets and slow computing performance.After Krizhevsky et al.[8]won the champion in Imagenet Challenge Image Classification,a large number of scholars began to imitate the convolutional neural networks(CNN)model,and a large number of excellent network models such as AlexNet[9],VGGNet[10],GoogLeNet[11]were proposed.
In order to enable CNN to achieve end-to-end training,Ref.[12] proposed a long-term recurrent neural network(LRCN)in 2015.This model has obvious advantages in recognition,optimization and other tasks.However,because the number of layers of CNN is too small,it can not fully extract useful feature information.Ref.[13]proposed a 3D-CNN,which can simultaneously extract spatiotemporal features,but 2DCNN is still used in the last few layers of the network.Ref.[14]proposed a C3D network.Experimental results show that the C3D network can extract spatiotemporal feature information better than 2D-CNN.However,as the number of network layers becomes deeper,problems such as network degradation will occur.Ref.[15]proposed a ResNet network,which overcomes the above problems caused by increasing the network depth.
In order to improve the performance of the network,this paper introduces the three-dimensional residual convolutional neural network(R3D),which can not only extract the temporal and spatial features,but also deepen the width of the network.On this basis,R3D network changes the size of the pool layer window,and adds Softplus activation function,batch normalization(BN)layer,dropout layer,convolutional layer and maxpool layer.Later,in order to further extract advanced timing features,the long short-term memory(LSTM)[16]network was introduced into R3D network.Finally,the R3D+LSTM network achieves 91%recognition rate on UCF-101[17]dataset.
1 R3D+LSTM network
1.1 R3D network
The structure of the residual network is to emulate the VGGNet,using a small convolution kernel instead of a large convolution kernel,reducing the amount of parameters.Moreover,through residual connection,the network layers are stacked to 152 layers,which has achieved good results in Imagenet competition.The residual module is shown in Fig.1.
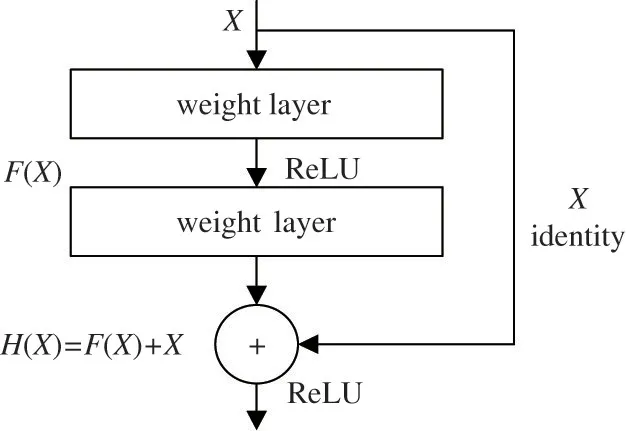
Fig.1 Residual module
The objective functionH(X)=F(X)+X,F(X)is fitted to 0,that is,H(X)=X,which is transformed into the fitting of the network toX,realizing the identity mapping ofX,solving the problem of network degradation.Since the derivative ofXis 1,the derivative value of the function is made greater than 1 in the backpropagation,which avoids the disappearance of the network gradient and makes the weight of the network updated.Because the number of layers of the traditional deep ResNet network is too deep,there are problems such as excessive parameter amount and redundant parameters,which causes the training speed of the network to slow down[18].Moreover,the ResNet network uses 2D convolution layer,which can only extract the spatial features of each image frame,so that the extracted features are not enough.In view of the above problems,this paper adopts R3D network,as shown in Fig.2.
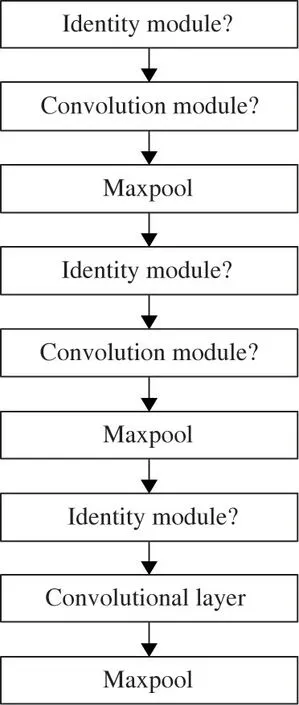
Fig.2 Structure diagram of R3D network
Since the operations and parameters of the 5 identity modulesⅠare the same,one identity moduleⅠis used to represent the 5 identity modulesⅠin the R3D network structure.Four identity modulesⅡand 4 identity modulesⅢare also represented in this way.The identity module uses 3×3×3 convolution kernel,and the convolution module uses 3×3×3 and 1×1×1 convolution kernel.The above convolutional layers all use Softplus to replace the ReLU activation function,because the value of the ReLU function in the negative interval is 0,so that some neurons cannot be activated,and therefore,the corresponding weight parameters cannot be updated.
1.2 LSTM network structure
As an improved version of recurrent neural network(RNN)[19],LSTM has a very good effect on processing video,which has time-dimensional feature.It perfectly solves the problem of long-term dependence of RNN.The key of LSTM is the state of each cell,as shown in Fig.3.
Among them,liis an element in the input sequence{l1,l2,l3,…,ln-1,ln},and the sequence length isn.LSTM,like RNN,needs to calculate the current hidden stateht,the hidden layer state can extract the feature of the sequence data,and then convert them to output.Usehtto represent the hidden layer state ofliat different times.The hidden layer state is related to the previous historical information.
In the human behavior recognition task of video class,each category of video is converted into hundreds of frames.In this paper,the number of consecutive frames input each time is a sequence ofnvideo frames,and the output is the corresponding video category.
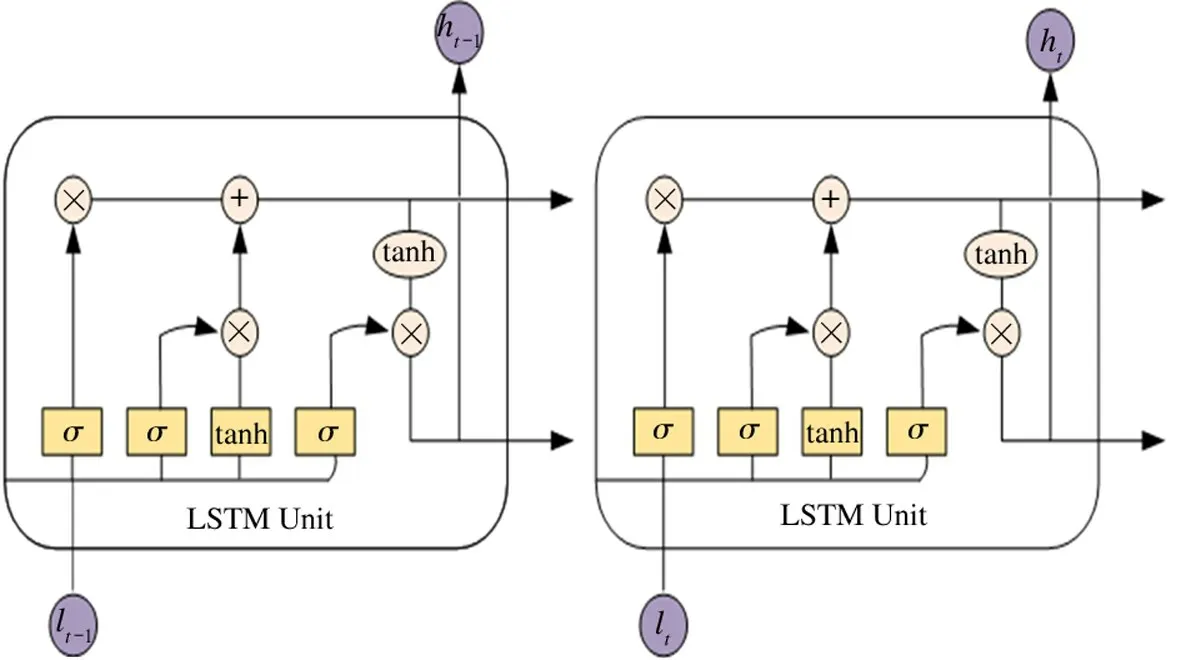
Fig.3 LSTM neuron connection method
Therefore,the last hidden layer statehnis selected as the high-level feature of the entire video frame.The specific calculation formula of time sequence of LSTM network is shown in Eq.(1).
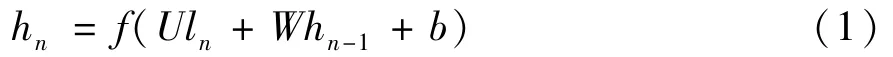
Among them,the bias value is represented byb,and the weight value is represented byWandU.
1.3 R3D+LSTM network structure
Ref.[8]used the CNN+LSTM method to design the network model to further improve the network classification effect,but with the increase in the number of network layers,gradient dispersion will occur,so this paper proposes the R3D+LSTM network.The network convergence architecture diagram is shown in Fig.4.
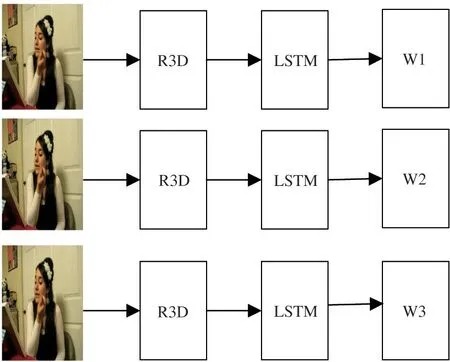
Fig.4 Structure diagram of R3D+LSTM network
Firstly,R3D network compresses and extracts time domain features.Global average pooling(GAP)network layer further compresses model parameters to avoid over fitting of network and speed up training speed,but it can not process time domain features well.Secondly,the depth of R3D+LSTM network is not enough,which leads to a small improvement in recognition rate.Thirdly,the maxpool layer will lose a lot of useful sequence information after downsampling.Therefore,in view of these three problems,the R3D network is modified as follows.
(1)Since the GAPnetwork is affected by the size of the feature map,the network can not be further deepened,and larger features will lead to smaller receptive field of convolution layer.Therefore,on the basis of the R3D network,convolutional layer and maxpool layer are added to deepen the depth of the network,improve the generalization ability of the network,enlarge the receptive field of convolution layer,and extract features.
(2)Rewrite all the sampling windows of the maxpool layer of the R3D network from(2×2×2)to(1×2×2)to maintain the features extracted by the shallow network and keep the time-domain sequence features intact.It avoids the loss of useful feature information when the pooling layer is down sampling.
In the dimension of input data,the feature map is expanded into one dimension,and all information features are directly input into LSTM network for feature screening,which can retain important features.
1.4 Overall network structure design
R3D+LSTM network uses identity module,convolution module,BN,Dropout and LSTM algorithm.The network has 34 convolutional layers,of which the identity module has 26 convolutional layers and the convolutional module has 6 layers.The following details the network layer structure.
Identity module I uses two 3D convolution layers to extract features,which are conv3d _2,conv3d_3,as shown in Fig.5.Each convolution layer contains 128 convolution cores with a size of 3×3×3.After that,BN layer and softplus layer are added after the convolution layer.The BN layer only normalizes the input data in batches,and the softplus function only performs nonlinear processing.Therefore,the size of the output feature graph is 16×128×128.The final output result is addition of the outputs of two convolution layers and the input of identity module I to obtain.None×16×128×128×128,which also reflects the meaning of R3D network residual module.

Fig.5 Structure diagram of identity module I
The convolution module I structure contains 3 convolution layers,which are conv3d_12,conv3d_13 and conv3d_14.The size of the conv3d_12 and conv3d_13 convolution kernels is the same as that of the identity module I,and the number of convolution core is twice that of identification module I,so more image features can be obtained.The difference between convolution module I and identity module I is that the input data has to be processed by conv3d_14 convolution operation.If adding by add,the premise is that the input feature map size and the number of channels are the same.Since the stride size of conv3d_12 is 2,the size of the output feature map becomes 1/2 of the original size,which is 8×64×64.At the same time,the stride size of conv3d_13 is 1,so the feature map size remains unchanged.While the conv3d_14 convolution kernel size is 1×1×1,and the stride size is 2,which reduces the amount of parameter calculation,as shown in Fig.6.
Each convolution module is connected with the maxpool layer to remove the lower value of the activation function response in the local neighborhood,which can reduce the dimension.
Because the GAPnetwork is affected by the size of the characteristic graph,the network can not be further deepened,so GAPlayer is removed and a layer of convolution layer and maxpool layer are added to deepen the network depth.Then,in order to further improve the network performance,LSTM network is introduced into R3D network,as shown in Fig.7.

Fig.6 Structure diagram of convolution module I

Fig.7 Converged network structure diagram
2 Experiment and analysis
2.1 Experimental environment
The experimental environment of R3D+LSTM network is listed in Table 1.
2.2 UCF-101 dataset
The dataset used in this paper is UCF-101.This dataset contains 13 320 human behavior videos(each video is 5-10 s long),including 101 categories,as shown in Fig.8.

Table 1 Experimental environment

Fig.8 All categories of UCF101 dataset
2.3 Experimental data preprocessing
Since it is not advisable to input video directly into the network,it is necessary to convert the video into a sequence of picture frames,which can speed up the training of the network.First,13 320 videos in the UCF-101 dataset are converted,and then the naming of each converted image sequence is determined by the sequence in the video.After that,because the total number of images is too much,if all the images are input into the network at one time,the network calculation will be too large.Therefore,this paper uses the sequence with length of 16 as the input data,selects the sequence with the length ofR,and then randomly generatesLbetween(0,R-16),which is used as the starting frame,and then the ending frame is selected in(L,L+16).This not only prevents data from being missed,but also avoids repeating training of the same data.
2.4 Analysis of experimental results
In order to improve the training speed of the network,this paper uses an initial learning rate of 0.001.When each cycle is 24 000 times,the learning rate is reduced to 1/2 of the original,cycle 10 times,a total of 240 000 times.The hyper-parameters of the network are shown in Table 2.
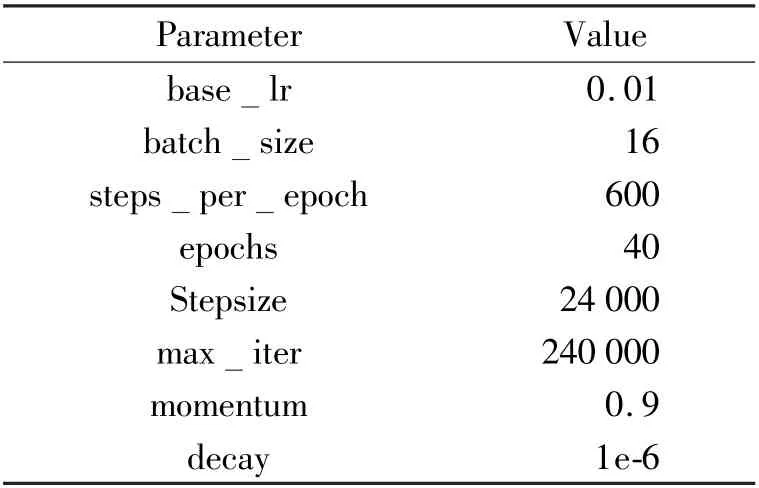
Table 2 SE-R3D network hyper-parameters
There are 400 epochs in the network,and each epoch iterates600 times.At the 250th epoch,the convergence speed of the network begins to slow down.At the 300th epoch,the network has basically converged.At this time,the number of iterations is 180 000.Finally,R3D+LSTM network achieves 91%accuracy,as shown in Fig.9.
The typical category accuracy rate of R3D+LSTM network on UCF-101 dataset is shown in Fig.10.The algorithm achieves more than 90% on Cleanandjerk and Cliffdiving,more than 80% on Skydiving and Throwdiscus,while the recognition rate in the category of Blowdryhair is low,60%.Therefore,it can be found that the accuracy of single action is usually higher than that of a complex action.
The accuracy of R3D+LSTM network is compared with other networks on UCF-101 dataset,as shown in Table 3.
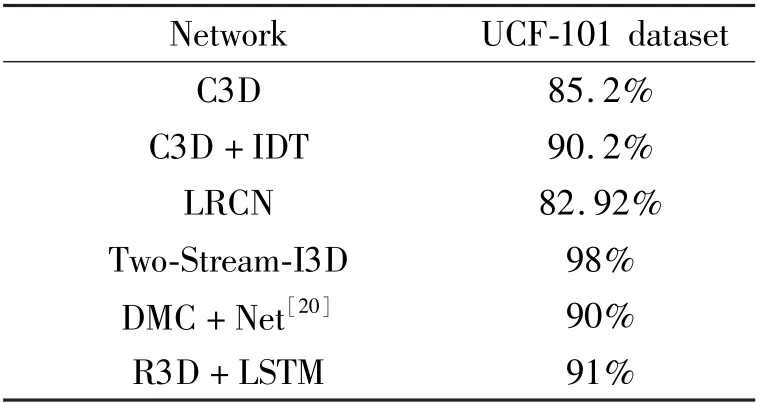
Table 3 Comparison of accuracy
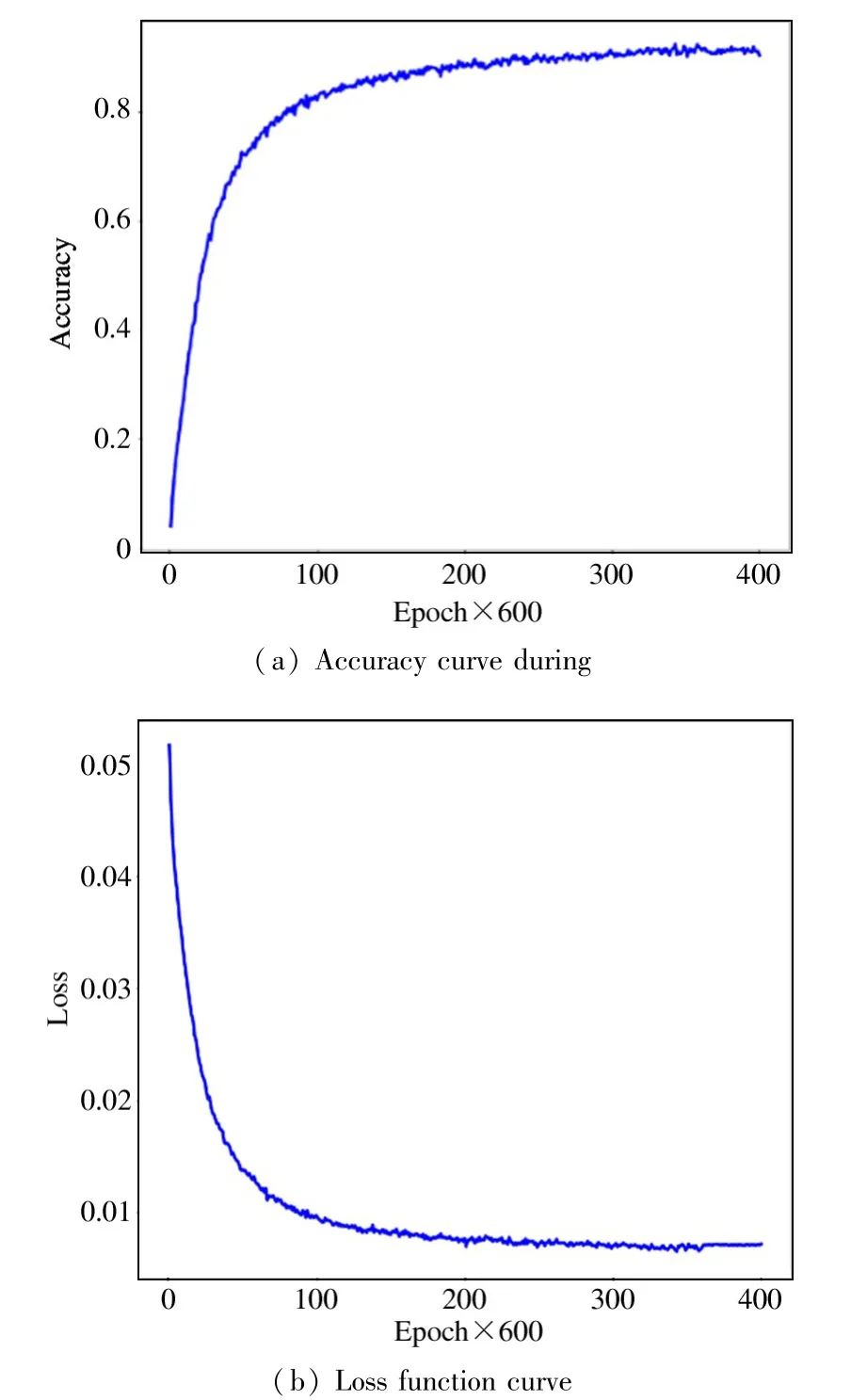
Fig.9 R3D+LSTM training process
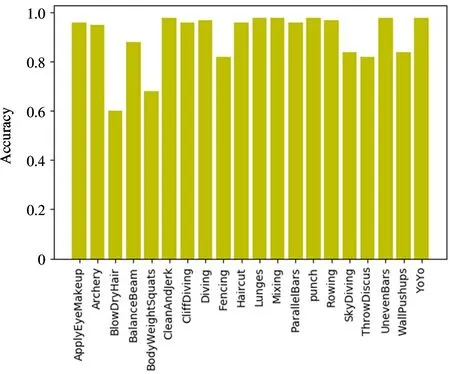
Fig.10 Test accuracy curve
It can be seen from Table 3 that the Two-Stream-I3D model has achieved a 98%recognition rate on the UCF-101 dataset.Although the accuracy of the network designed in this paper is not as high as Two-Stream-I3D.However,compared with the popular C3D and C3D+IDT networks in the past two years,R3D+LSTM has a greater improvement in the recognition rate,and at the same time,the recognition rate is 1%higher than that of the DMC-Net network.Secondly,the recognition rate of R3D+LSTM network is much better than that of the LRCN network,which shows that the combination of the three-dimensional residual network and the LSTM network is feasible in the field of behavior recognition.
3 Conclusions
Automatic recognition of behavior in video is a long-term goal of computer vision and artificial intelligence.In order to improve the network performance,this paper designs R3D+LSTM network.First,the R3D network is modified,the ReLU activation function with Softplus is replaced,and a convolutional layer and maxpool layer is added to increase the depth of the network.Then,the pooling window of all maxpool layers is changed to(1,2,2)to maintain the features extracted by the shallow network,and BN layer and Dropout layer are added to improve the convergence speed of the network and effectively restrain over fitting.Later,in order to extract the high-level temporal features,LSTM network is introduced.Finally,the R3D+LSTM network achieves 91%recognition rate on the UCF-101 dataset.
Although the R3D+LSTM network designed in this paper has achieved good performance in recognition rate,compared with some perfect algorithms in this field,there is still room for improvement.The future work and prospects are as follows.
(1)Optimization of the model.The designed network model can be further optimized to obtain a higher recognition rate,and more datasets will be used to test the performance of the model.
(2)The datasets used are preprocessed,but in actual scene,the behavior will become more complex and the resolution of the video will be reduced.Therefore,further research needs to be done to identify the human behavior categories accurately and efficiently.
杂志排行

High Technology Letters的其它文章
- On the performance of full-duplex non-orthonogal multiple access with energy harvesting over Nakagami-m fading channels①
- Research on optimization of virtual machine memory access based on NUMA architecture①
- Online prediction of EEG based on KRLST algorithm①
- Reconfigurable implementation ARP based on depth threshold in 3D-HEVC①
- Positive unlabeled named entity recognition with multi-granularity linguistic information①
- Performance analysis of blockchain for civil aviation business data based on M/G/1 queuing theory①