基于相似性度量的网络流分类模型融合
2022-01-09姚永生董育宁邱晓晖
姚永生,董育宁,邱晓晖
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
随着互联网技术的高速发展,网络视频流在网络通信中所占有的比例越来越高。种类不一样的网络应用对网络服务质量(quality of service,QoS)的要求不一样。视频流业务的细分类是实现端到端QoS的前提。互联网服务提供商为了给不同类型的视频应用分配合理的网络资源,需要将网络流应用进行细分类,更不能把所有网络业务当作同一个类型的类别区分。
近年来,机器学习(machine learning,ML)方法在网络数据流分类与识别中已得到广泛应用[1]。但遗憾的是经典的ML面对下面问题将无法很好地处理:首先,基于流特征的ML方法会随着复杂的网络环境发生变化导致网络流分布动态变化以及不同流特征间的差异引起网络流概念漂移;之前由老数据流量建立的ML模型,由于不同种类的网络流属性漂移情况不一致,使得ML模型的识别准确性下降。其次,互联网技术处在发展变化中,几年前采集的样本可能过时并无法满足现实需要,而再次采集并标注新样本会消耗不必要的成本。因此,该文提出一种基于相似性度量的分类模型来解决上述问题。该模型能够完成只有少量带标签新样本集与大量老样本训练集,以及数据流概念漂移不相同的情况下,更好地实现网络视频流分类。
本研究的基本思路是基于以下事实:通过采集的新老数据流对比发现,某些类别网络流在两个不同数据集上比较相似,而其他类别则有较大的差异。训练好的ML对老数据集可以很好地进行分类,而对于新数据集总体分类效果不理想。迁移学习(transfer learning,TL)可以利用有标注的源领域知识,来辅助目标领域的知识获取和学习。这样TL就能够利用之前学习到的知识,迁移到新数据集中完成差异较大类别的分类。鉴于此,该文的目的是研究何时采用TL,何时采用ML。根据Jensen-Shannon(JS)距离[1]度量源域和目标域之间的相似性,距离越小,两者的相似性越大。通过相似性比较,选择采用何种模型。一方面,TL可以解决数据集样本标注不足的问题,充分利用了源域的相关知识;另一方面,ML模型是之前训练好的网络模型,对于相似性较大的后续流类别较适用,能够提高分类准确率和模型利用率。
特征选择方法在数据预处理阶段至关重要,通过选取出最优特征子集,能够有效降低后端分类算法的计算时间复杂度,同时可以更好地提高模型分类精度[2]。
该创新方法如下:
(1)结合JS距离、MultiTrAdaBoost[2]和Random Forest(RF)[1]算法提出了基于相似性度量的分类模型融合方法。该融合模型采用JS距离度量两个领域流分布的相似性,结合ML和TL,可以较好地利用过去的数据,在节省标记新样本数据集成本的同时提高了模型的总体准确率。
(2)探究数据集中类别与模型选择之间的关系,不同种类的数据流特征发生漂移情况不一样。采集新的数据流进行特征提取,通过实验验证上述融合模型的有效性。
1 相关工作
1.1 网络视频流分类方法
Yang等[3]根据不同类型的视频具有不同的下行传输速率变化模型模式,提出了一种基于M值概率分布并使用支持向量机的网络视频流分类算法。Garcia等人[4]采用深度包检测分类流量,在流量到达率非常高的场景中,分类结果较好。Wu等[5]针对种类不一致的网络流分布的差异性,提出一种可以完成存储低、延时小、准确率高的流细分类算法,同时实现了现实网络数据中较高分类识别率的效果。杨凌云等[6]应用短网络流包替代长网络数据包进行网络样本流分类,有效地降低了网络数据流算法时间复杂度并明显地提升了网络数据流分类准确率。
1.2 迁移学习分类方法
王彦等[2]提出了一种基于SAMME[7]和TrAdaBoost[8]的TL分类算法,该算法能够对网络中不同种类的视频数据流进行有效地识别与分类,并有效节约了新数据集标记成本。Wang等[9]阐述了类内迁移的思想,同时指出仅仅一个整体的特征迁移转换学习是不够的,当加入类内之间的相似性,类内特征能够用于类内迁移,从而实现更好的迁移学习。刘振等[10]提出了一种基于多重相似性的多源TL算法,能够从多个不同源域中挖掘更多的知识用于目标域学习,还可以根据域间的相似性有选择地进行迁移。当分布不同时,Cai等人[11]运用TL来实现网络视频流量的两类分类,并改进了算法同时节约了计算时间成本。刘三民等[12]基于TL方法,应用过去老数据集有用知识来帮助目标域新模型知识学习,能够有效缓解新数据集标记样例的缺失。
2 预备知识
2.1 网络流概念漂移

(1)
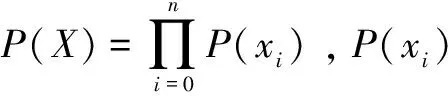
2.2 JS距离
JS距离[1]可以用来描述源域和目标域之间的距离,进而衡量两个数据域之间的差异。该距离公式如下:
(2)
其中,
(3)
N为源域和目标域中特征向量的维数。
2.3 RF算法
RF算法是Bagging方法和决策树方法结合的集成ML算法。RF通过随机建立多个决策树,每个决策树都是一个分类器,并将其合并到一起以投票的方式获得更准确和稳定的预测。
2.4 MultiTrAdaBoost算法
MultiTrAdaBoost算法[2]继承了TrAdaBoost的迁移思想,并结合SAMME来实现多分类,是一种通过训练多个弱基础学习器,最终生成强分类器的集成学习算法。该算法最终输出的函数为:
(4)
其中,N为循环的最大次数,ht为弱学习器预设函数,βt=γt/(K-1)。∏是一个指示函数,假设ht(x)=k,那么其值为1,否则为0。
2.5 MSGA算法
MSGA[2]是一种基于MultiSURF[15]和GA(genetic algorithm)[16]的混合式特征选择算法。MultiSURF是一种过滤式特征选择方法,可以实现特征尺寸的快速降维;GA可以降低特征的冗余度,两者相结合可以选择出更优的特征子集。
2.6 GA算法
GA算法是一种全局性和自适应性的进化搜索算法,呈现了在自然选择过程中学习知识的不断主动获取和空间知识的不断自动搜索,能够加以对搜索过程的整体性进行有效地自适应调整并求得最佳解。在ML领域中,是一种过滤式的特征提取方法,去除冗余特征,得到最优特征子集。
3 文中方法
3.1 特征提取和选择
在网络流特征集提取过程中,首先依据MultiSURF算法计算出每个属性(例如:下行包大小均值)的权重值,按其权重进行排序,选择前m个属性。其次,用m个属性(特征)随机初始化原始种群(选取的特征数组成原始种群),并计算每一个个体的适应度函数值(选取分类学习算法CART[2]的准确率用作适应度函数)。然后,利用GA算法,对个体进行选择、变异、交叉(选择适应度值较高的个体,交叉即是进行特征的互换,变异在一定程度上增加种群多样性),将新生成的后代加入到种群中,形成新的种群。当个体的适应度函数值不再变化,或算法达到最大的迭代次数,此时输出结果为最佳个体。在进行分类实验之前,使用MSGA特征选择算法从25个原始特征(见表1)筛选出8个特征,如表2所示。

表1 原始数据集25个特征
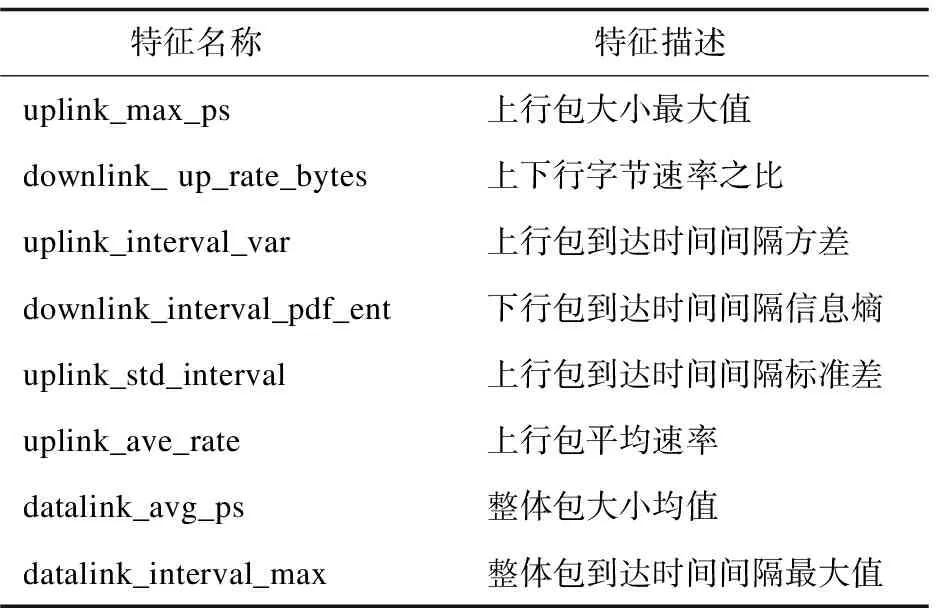
表2 MSGA选出的8个特征
3.2 混合式分类算法
首先利用MSGA算法筛选出8个特征,用老数据训练ML模型,再用老数据集加上一定比例的新数据训练TL模型。在训练TL模型过程中,不同比例的新样本数据的增加,经过每一轮的不断迭代学习,进而将老样本集中获取的有用知识应用到训练TL模型中,进一步提高融合模型分类精度。通过JS距离,衡量新老流特征之间的相似性,相似性越大,说明新老流之间的流属性发生概念漂移较小,采用已训练好的ML模型;反之新老流之间的相似性较小,采用TL模型,利用源域中学习的知识,进行分类预测。采用融合模型的分类准确率较单一TL模型有一定的提高。
提出的混合式分类方法JSD-MTAB-RF结合JS距离、MultiTrAdaBoost和RF模型,其分类的计算过程如下:
(1)使用MSGA算法从原始数据集25个特征中筛选出8个特征。包含8个特征子集的数据集划分为老数据集Ta(训练集),a%Tb(0≤a≤100)的新数据集(训练集),(1-a%)Tb的测试集(S)。
(2)用老数据集Ta训练ML模型,Ta+a%Tb训练TL模型。
(3)比较新老流之间JS距离大小。
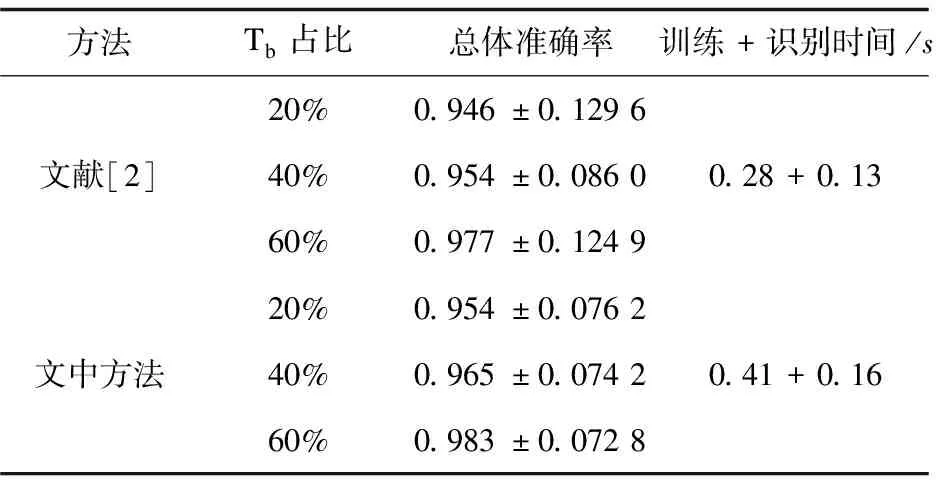
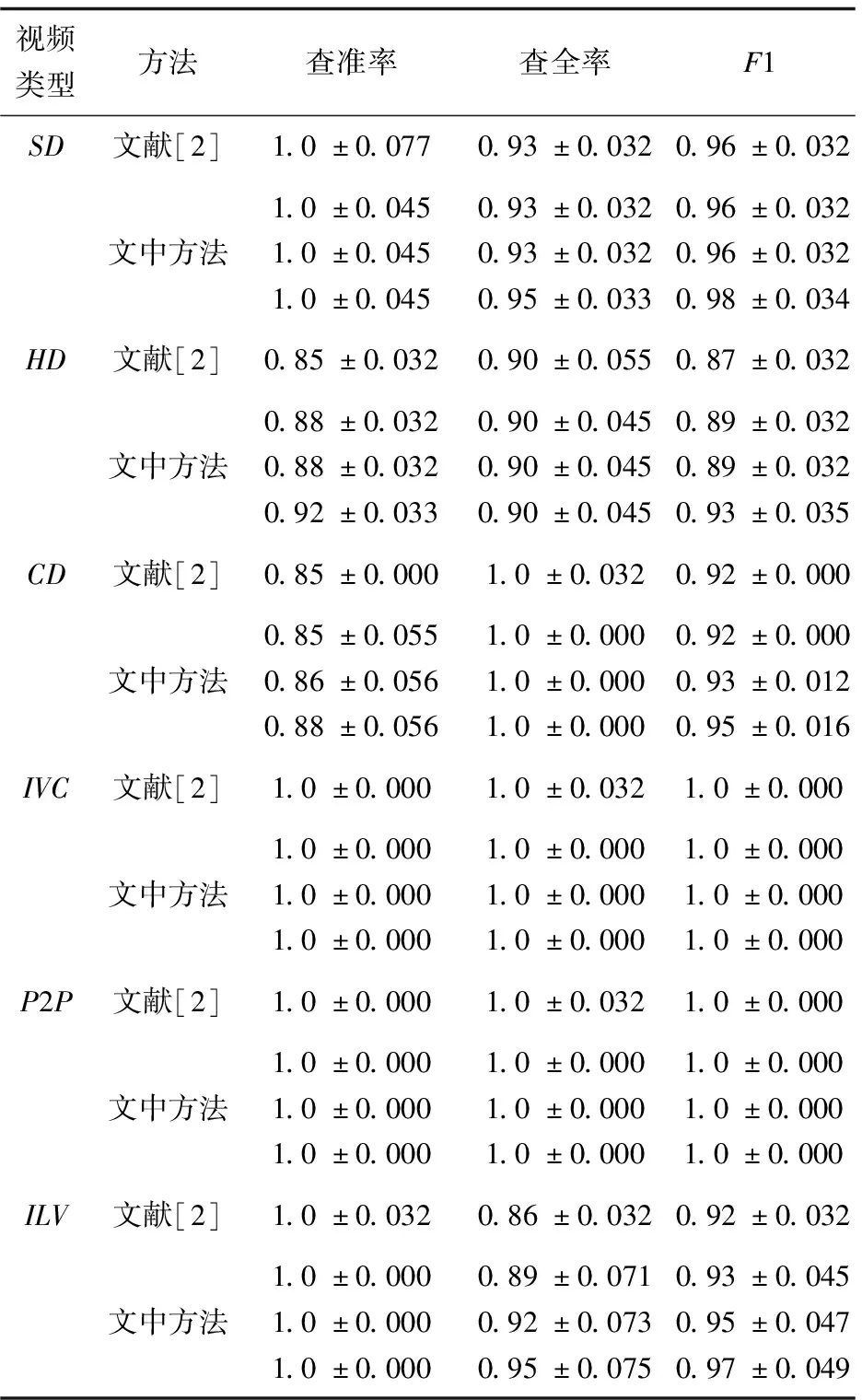
(4)当JS-distance(S,D(Ta)) (5)模型预测输出结果。 算法框图如图1所示。 图1 JSD-MTAB-RF算法流程 具体实现算法的伪程序见算法1。 算法1:JSD-MTAB-RF。 Input:带标签训练样本Ta和Tb和测试集S、应用类型数量K、弱基础分类器、循环次数最大值N和旧模型Rf(x)。 Output:类别预测结果。 2.fort=1,2,…,Ndo 4.使用弱基础分类器,输入组合训练样本T(Ta∪Tb)、权重分布pt和测试集S,获得在测试集S上的弱学习器ht:X→Y。 5.得出ht在Tb上的错误率εt: 6.βt=εt/((1-εt)(K-1)) 8.最终分类器: 9.foriin range(len(S)-1)do 12. if dis(S[i],Avg(Ta)) 13.output=Rf(S[i]) 14.else output=Hg(S[i]) 15.return output 16.end 在本实验中,由Wireshark抓包软件采集两个网络流数据集,实验中所抓取的网络视频流样本的时长均为10分钟。第一个数据集为收集790个样本的老数据集,于2013年6月在南京邮电大学校园网采集。第二个数据集为收集458个样本的新数据集,于2019年9月在南京邮电大学校园网采集。这两个数据集都包含6个视频应用类别:非对称式视频流:点播超高清视频(CD/1080p)、点播高清视频(HD/720p)与点播标清视频(SD/480p);以及对称式视频流:即时通信类视频(IVC)、网络类视频(P2P)和在线直播视频(ILV)。数据集中每一个样本均提取25个流特征(见表1)和一个类标签。 对老数据集而言一些特征属性有用信息已过时,将其看作Ta。新数据集可以划分成以下两块:一块用于模型训练的样本集Tb,另一块用于模型的测试样本S,同时两块样本集同分布。实验中,从新数据集中分别提取20%,40%和60%(即a=20、40和60)的数据参与训练集,其余为测试集S。 硬软件平台是具有Inter(R)Core(TM) i7-9750H、2.60 GHz CPU和16.0 GB RAM的PC机,Win10操作系统,运行Python编程语言(Python3.7版本),在集成开发环境Pycharm中编写代码。 文中方法与文献[2]方法进行性能比较,后者将Ta和Tb组合形成训练集。实验采用5折交叉验证方法,测试指标给出均值和标准差。 实验使用四个性能评估指标,分别为准确率 (A)、查准率(P)、查全率(R)和F1-测度(F1)。 (1)准确率:它是分类器准确分类的样本数与样本总数的比率。 (5) (2)查准率:计算全部正确的项目(TP)与全部实际的项目(TP+FP)的比例。 (6) (3)查全率:计算全部正确的样本(TP)与应检索的全部样本(TP+FN)之比。 (7) (4)F1-测度:是查准率和查全率的加权平均值。 (8) 表3给出了文中方法与文献[2]方法的总体准确率比较。以Tb占比20%为例,文中方法的总体准确率为95.4%,而文献[2]方法为94.6%。究其原因,文中方法是利用JS距离度量新老流分布之间的相似性,根据距离的大小,判断相似程度,选择合适的学习模型;相比于文献[2]方法只使用TL模型,提高了总体性能。随着带标签的新数据集Tb在训练集中所占比例的提高,分类总体准确率有所提高。不过由于计算JS距离和模型的加载耗时,文中方法比文献[2]计算量略有增加。其中,训练时间增加0.13 s,识别时间增加0.03 s。因训练阶段只运行一次,主要关注的是识别时间。 表3 两种方法的总体准确率(均值±标准差)和 运行(训练+识别)时间对比 表4显示了文献[2]与文中融合模型JSD-MTAB-RF方法在种类不一样的网络数据流中的预测结果。在新老样本数据中,数据样本差异性大小是影响性能的根本原因。随着时间的变化,新老数据集中流之间的属性会发生概念漂移;不同种类的流漂移的情况不一样,某些流特性漂移波动较大,而某些流特性漂移波动较小;TL对于相似性较小的流类别适用,对于相似性较大的流类别不适用。在ILV类别,文中方法的F1测度、查准率、查全率都有所提高,是因为该类新老数据相似性较大,采用了训练好的ML模型,较只采用TL模型性能有所提升。同时,随着带标签的新数据集Tb在模型训练中占比越高(a=40、60)时,文中方法对部分视频类型分类评价指标有所提升。 表4 两种方法对网络视频流的分类性能(均值± 标准差)对比(Tb占比20%、40%、60%) 查看实验数据集中,六种类别的样本分别采用了何种学习模型。统计结果得出,IVL类别样本全部采用了ML模型;因为,该类别的流特性概念漂移较小,新老流之间的相似性较大;而其他五个类别的样本几乎全部采用了TL模型,因为这些类别的流特性概念漂移较大,新老流之间的相似性较小。 为了验证上述结论的正确性,作者于2020年9月采集了100条ILV类别的样本,利用本实验组成员编写的NetFlowAnaLab平台从5元组数据流中提取出25个原始特征和标注类别标签。之后用MSGA算法提取出8个特征(见表2)用于实验。结果得出,对于新采集的100条ILV类别样本,采用ML模型分类准确率为100%,而采用TL模型仅为97.6%。 该文提出了一种结合JS距离、MultiTrAdaBoost和RF的混合式分类方法JSD-MTAB-RF,能够实现多种不同网络应用视频流识别与分类。实验结果表明,在新数据集和老数据集特征分布不完全相同的情况下,即网络流特征属性发生了概念漂移,提出的基于相似性度量的混合模型,相对于现有方法,尽管耗时略有增加,但准确率更高。未来依然有一些地方需进一步实验探讨。下一步的研究工作在具有不同特征空间分布的TL方法,可以通过特征变换,将两域之间的数据特征有效地转换到相同标准的特征空间中去,从而实现基于特征的TL方法。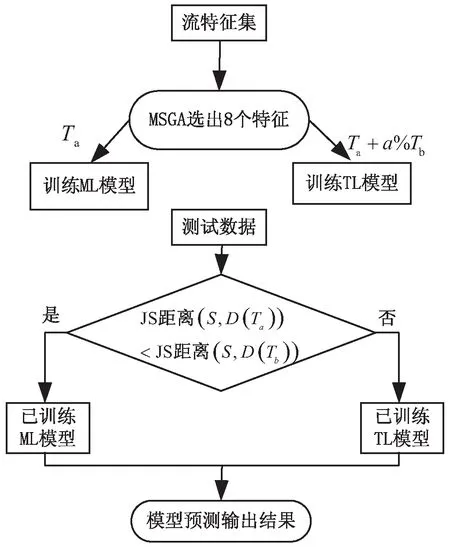
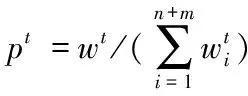
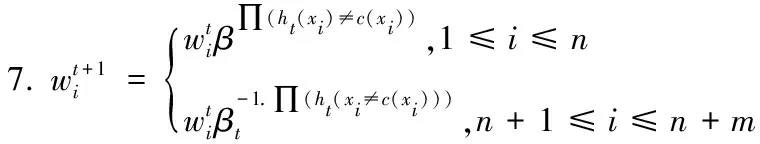
4 实验结果及分析
4.1 数据集简介
4.2 实验设置
4.3 分类评价指标
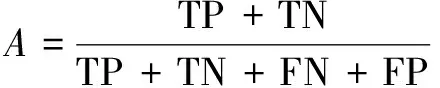
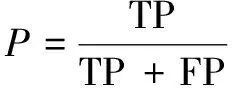
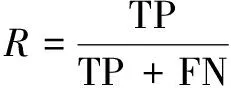
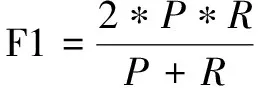
4.4 实验结果
4.5 实验探究与验证
5 结束语
