基于数据挖掘技术的白水河滑坡多场信息关联准则分析
2022-01-07范小光吴益平
陈 锐,范小光,吴益平
(1.中国地质大学(武汉)工程学院,湖北 武汉 430074;2.中国电建集团河南省电力勘测设计院有限公司,河南 郑州 450007)
1 研究背景
三峡工程作为世界上最大的水利枢纽工程,在防洪、发电及航运等方面发挥着巨大的作用。自三峡工程建成以来,由库水位变化所引起的地质灾害愈来愈受到人们的重视。其中,滑坡是三峡库区最频发且影响最大的地质灾害,为确保能实时监测滑坡位移变化,滑坡多场监测技术被广泛应用。
随着监测技术的进步与监测周期的增加,滑坡多场监测实时传输,取得了海量的监测数据。近些年数据挖掘技术在滑坡研究领域发展迅速,王树良等[1]结合宝塔滑坡的监测数据,研究了滑坡监测数据挖掘的视角及其泛层次关系;张纯志[2]以万源市太平镇滑坡为研究对象,应用线性回归方程处理滑坡数据,挖掘数据间的联系;徐峰等[3]应用时间序列分析方法分析了三峡库区八字门滑坡,将滑坡位移分解,建立滑坡位移预报模型。但以上两种分析方法在实际的滑坡数据处理应用上还存在着一定局限性,都只考虑单因子条件下的分析和预测,实际滑坡预测分析是一个复杂的系统,受多因子共同影响,同时随着滑坡数据的复杂多样化,常规数据处理方法已无法满足研究需要。近年来,许多新型数据挖掘技术在国内外兴起,并在滑坡领域应用广泛[4-7]。马水山等[8]采用两步聚类等方法,得到滑坡变形同监测数据间的关联规则;段功豪[9]利用Apriori 算法,以降雨量及库水位为主要影响因子,挖掘出树坪滑坡位移变形与影响因子间的关联准则。HUANG 等[10]通过数据挖掘研究了三峡库区滑坡活动同库水位及降雨强度之间的关联准则。孙义杰[11]采用数据挖掘方法中的Apriori 算法,依据马家沟滑坡变形影响因子,确定滑坡变形位移同各因子间的关联准则。TSAI 等[12]利用资料挖掘技术分析地形与植被因子,以验证区域性强降雨所诱发的滑坡,采用决策树和贝叶斯网络等数据挖掘算法,从海量数据间获取有效信息。马俊伟[13]采用两步聚类法、Apriori 算法及决策树C5.0 算法,对马家沟滑坡和朱家店滑坡的信息关联规则及信息阈值进行分析研究。
结合上述数据挖掘方法,本文选取白水河滑坡为例,结合滑坡资料从降雨与库水位角度选取影响因子[14-16],分别为:月累计降雨量、日降雨量月度最大值、库水位月平均值、库水位波动速度、单月最大有效连续降雨、单月库水位日浮动最大值。依据数据挖掘流程,采用两步聚类法使滑坡变形演化定性化,将6 种影响因子由数值型变量转化为离散型变量,随后应用Apriori 算法挖掘出滑坡数据间的关联准则,输入影响因子作为关联准则前项,滑坡位移速度为关联准则后项,生成影响因子与滑坡位移速度的关联准则,选取其中的有效规则,实现滑坡监测数据处理与关联准则挖掘。研究表明,关联准则对于滑坡灾害的变形分析具有重要的意义,数据挖掘技术可较好地应用于三峡库区地质灾害位移预测预报中。
2 白水河滑坡概况及数据分析
2.1 滑坡概况
白水河滑坡位于长江主干道南岸,属秭归县沙镇溪镇乐丰村。由滑坡勘察报告得到白水河工程地质平面图及剖面图(图1、图2)。南北长500 m,白水河滑坡东西宽430 m,面积21.5×104m2,滑体平均厚度约30 m,体积645×104m3,主滑方向为15°,属大型顺层土质滑坡。2004年7月,白水河滑坡出现明显变形,根据其变形特征划分出滑坡预警区。预警区东侧以黄土包凹槽为界,西侧以滑体西部山羊沟为界,后缘以高程约297 m 为界,前缘剪出口在长江库水位145 m 水位以下。
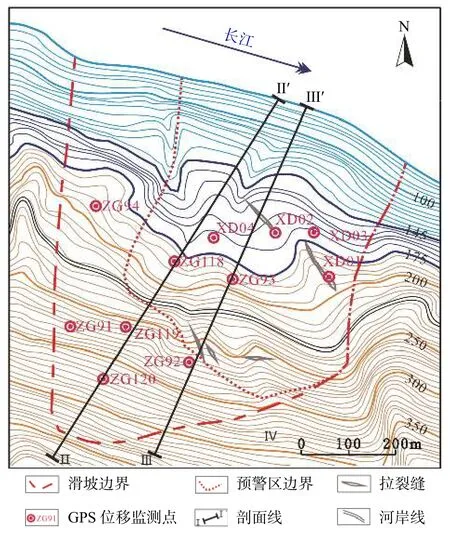
图1 白水河滑坡工程地质平面图Fig.1 Engineering geological plan of Baishuihe Landslide
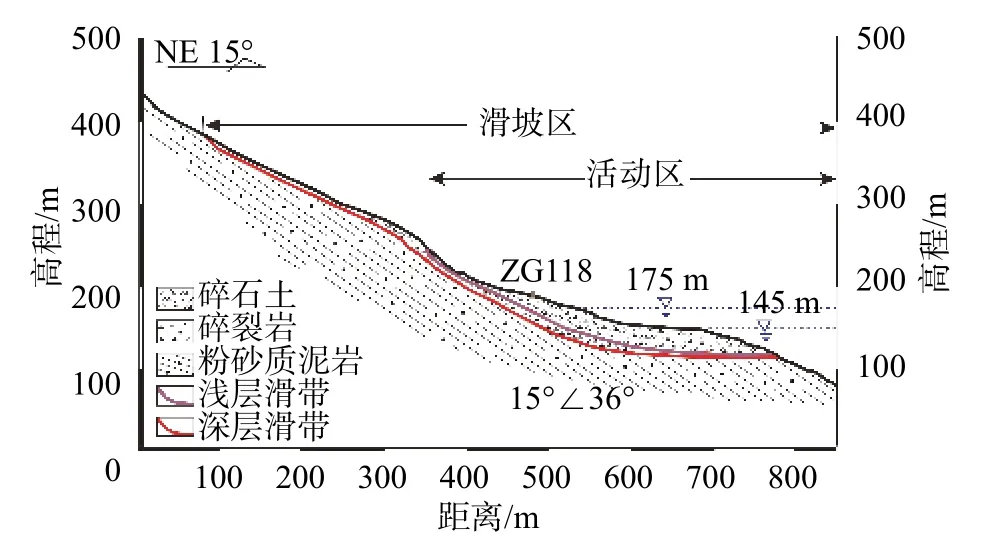
图2 白水河滑坡工程地质剖面图Fig.2 Engineering geological section of Baishuihe Landslide
2.2 白水河滑坡变形特征分析
选取白水河滑坡监测点ZG93 数据进行研究,通过对往年降雨强度及库水位变化数据归纳分析,获得白水河滑坡监测数据曲线图3,将白水河滑坡位移变形特征分为三个阶段。
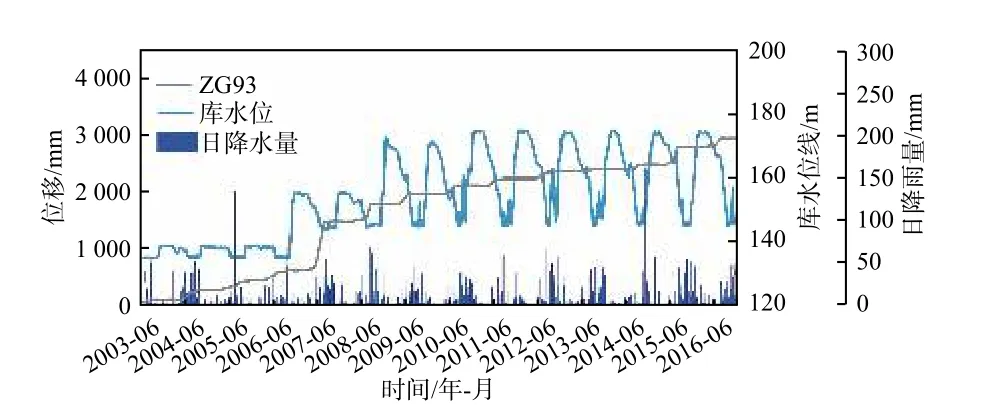
图3 白水河滑坡监测数据曲线Fig.3 Monitoring data curve of Baishuihe landslide
(1)第一阶段:2003年6月—2006年8月,库水位在135~140 m,这一阶段为低水位时期,且库水位波动幅度相对较小,滑坡前缘受库水位影响效果不明显,此时滑坡位移变化特征主要与降雨强度相关,主要表现为滑坡位移变形同降雨强度的增大而增大,随降雨强度的降低而趋于稳定。
(2)第二阶段:2006年8月—2008年8月,库水位抬升至155 并稳定在145~155 m,相对第一阶段而言,库水位抬升同时库水位波动幅度相对增大,滑体内渗流场、应力场及岩土体结构发生改变。当库水位下降时,随降雨强度的增大,滑坡的位移变形同步大幅增大。此时滑坡位移变形特征主要受降雨强度影响,库水位有一定影响。
(3)第三阶段:2008年8月—2016年12月,库水位抬升至175 m 并稳定在145~175 m,这一阶段库水位高度和波动幅度再次增加。在第二阶段中,滑体内渗流场、应力场及岩土体结构发生改变调整后趋于稳定,当库水位下降时,随降雨强度的增大,滑坡位移变形也会增大。相对第二阶段产生的大幅变化而言,这一阶段变形量显著降低。随着库水位规律变化,滑体内渗流场、应力场及岩土体结构进一步趋于稳定,此时滑坡位移变形特征受降雨强度及库水位共同影响。
综上所述,当降雨强度较低,库水位抬升时,滑坡体内的地下水抬升会滞后于库水位的抬升,使得被库水浸没的滑体受到与滑面正交的静水压力作用,此时滑坡整体相对稳定,变形特征不明显。但当降雨强度增大同时库水位下降时,滑坡体内的地下水位下降会明显滞后于库水位的下降,使得滑体在库水位下降后一段时间内仍受到一个与滑面平行且指向坡外的动水压力作用,由于降雨强度大,此时滑坡稳定性会大幅降低,变形特征显著。因此,高强度的降雨及库水位波动幅度是影响白水河滑坡位移变形的主要影响因素。
3 滑坡多场信息关联规则研究
3.1 数据挖掘流程
数据挖掘流程如图4所示,主要由数据采集、数据预处理、数据离散化和关联准则挖掘四步组成。本文主要采用两步聚类算法及Apriori 算法,通过数据挖掘流程处理滑坡监测数据,得到滑坡位移速度同影响因子间的关联准则。
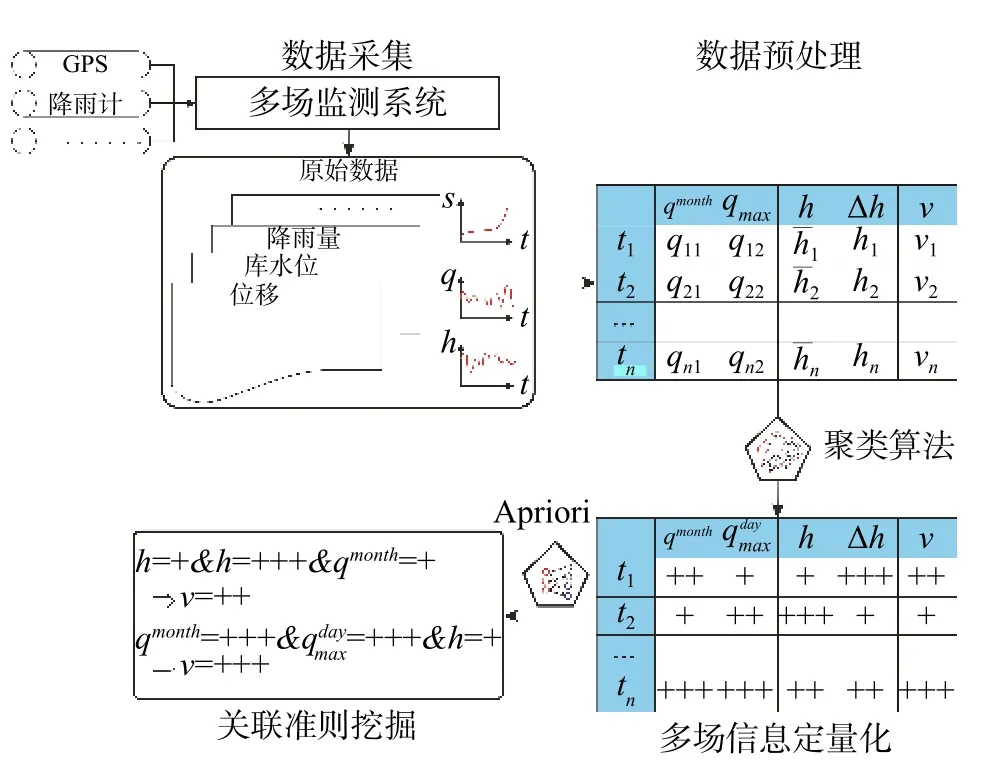
图4 滑坡多维信息时序关联判据数据挖掘流程图Fig.4 Data mining flow chart of multi-dimensional landslide information time series association criterion
(1)数据采集:数据采集是将野外监测数据(包括GPS、降雨数据、位移数据)进行收集归纳,获得数据基础。
(2)数据预处理:数据预处理主要指对已有数据进行审核、筛选、排序等处理措施。
(3)数据离散化:由于Apriori 算法只能处理离散型变量,故采用两步聚类法将监测数据离散化。
(4)关联准则挖掘:应用Apriori 算法对离散后的变量进行关联规则集合选择,生成有效的关联规则。
3.2 两步聚类法
两步聚类法算法是CHIU 等[17]在2001年在提出的一种能处理大规模类型数据的算法,该算法是通过预聚类与聚类两步将数据划分整合,进而完成数据分类,其聚类过程详见图5。
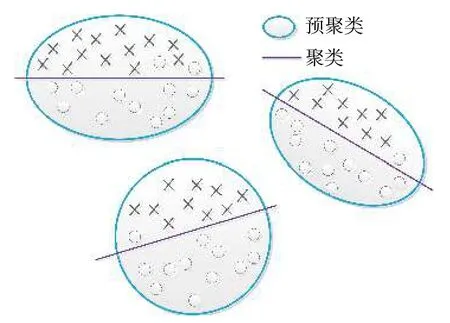
图5 两步聚类法示意图Fig.5 Schematic diagram of two-step clustering method
对于样本数据既包括数值型变量又包括分类型变量,两步聚类算法通常采用对数似然函数,若聚成j类,则其定义为:
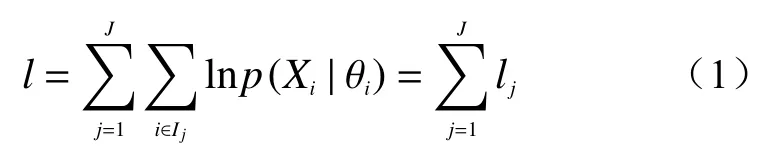
式中:p——似然函数;
Ij——第j类的样本集合;
θj——第j类的参数向量;
J——聚类数目。
针对全部样本,其对数似然聚类是各类对数似然聚类之和。
对于存在的第i类和第j类,两者合并后的类记为i,j,则他们的距离定义为:
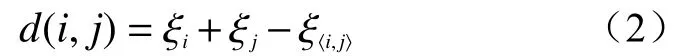
式中:ξi——第i类的对数似然距离;
ξj——第j类的对数似然距离;
ξ〈i,j〉——第i类和第j类合并后的对数似然距离。
ξ——对数似然函数的具体形式,定义为:

其中:
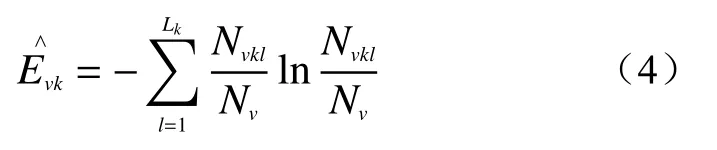
式中:KA——数值型变量的个数;
KB——分类型变量的个数;
Nv——第v类的样本量;
Nvkl——在第v类中第k个分类型变量取第l个类别的样本量;
Lk——第k个分类型变量的类别。
当第i类和第j类合并后,−ξ〈i,j〉大于ξi+ξj,因此d(i,j)小于0。d(i,j)越小,说明第i类和第j类合并将不会引起类内部差异的显著増加。当小于阈值C时,第i类和第j类可以合并;当d(i,j)大于阈值C时,说明合并将会引起聚类簇内部的差异性显著增加,第i类和第j类不能合并。
阈值C的定义为:

其中:
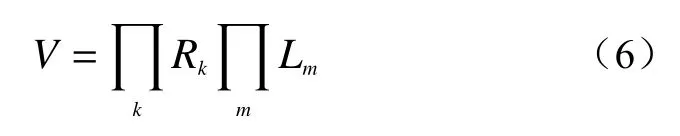
式中:Rk——第k个数值型变量的取值范围;
Lm——第m个分类型变量样本量。
3.3 Apriori 算法
通过两步聚类算法对滑坡监测数据类型进行转化,将分类所得的变量采用Apriori 算法计算,挖掘监测数据的关联准则。
Apriori 算法由AGRAWAL 等[18]提出,该算法首先生成高于最小支持度的频繁项目集,在第一步产生的频繁项目集中生成高于最小可信度的关联准则。
频繁项目集是指对包含项目a的项集T,其支持度大于或等于用户指定的支持度阈值(minsupp),即:
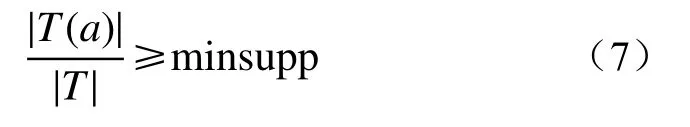
包含k个项目的频繁项目集称为频繁k项集,记为Lk。如图6上层的项目集ab、abc、abcd,当满足最小支持度时均为频繁k项集。
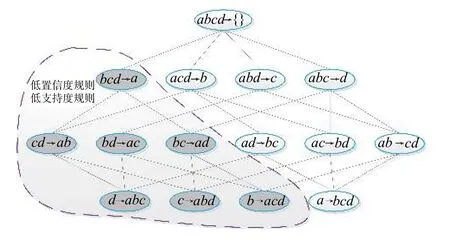
图6 Apriori 算法示意图Fig.6 Schematic diagram of Apriori algorithm
Apriori 算法实现过程详见图6。首先,搜索出产生长度为1 的频繁项集L1,L1又用于产生长度为2 的频繁项目集L2,如此循环,搜索所有的频繁项目集。
从频繁项目集中产生简单的关联准则,按置信度大于置信度阈值的条件,选择出有效规则集合。对每个频繁项目集L,计算L所有非空子集L′的置信度,如果CL′→(L−L′)大于用户指定的置信度阈值(minconf),即
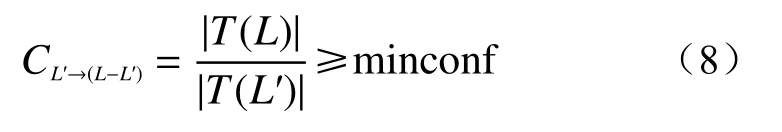
则生成关联准则L′⇒(L−L′)
4 白水河滑坡关联挖掘分析
4.1 影响因子选取
结合以往相关研究的成果[19-20],从降雨和库水位两种角度共选取了6 种影响因子作为关联准则的前项。
(1)降雨:降雨入渗是影响滑坡位移变形的主要影响因素,针对白水河滑坡而言,由于区域内两次降雨的时间间隔较长,且降雨入渗与蒸发作用同时进行,故不考虑降雨时长的作用,将降雨强度划分为3 个影响因子进行分析,分别为:月累计降雨量(∑qmonth)、日降雨量月度最大值()及单月最大有效连续降雨量()。
(2)库水位:根据库水位高度及波动幅度对滑坡位移变形特征影响分析可以得知,当库水位产生变动时,滑体内地下水会出现较明显的滞后效应,对于白水河滑坡而言,滑坡的位移变形受库水位较大影响,此次将库水位划分为3 个影响因子来探究其对滑坡变形的影响,分别为:库水位月平均值()、月库水位波动速度(Δh)、单月库水位日浮动最大值()。
4.2 聚类分析
按照上述介绍的滑坡数据挖掘流程,针对白水河滑坡特定的影响因子进行滑坡信息关联规则挖掘。
月累计降雨量、日降雨量月度最大值、库水位月平均值、库水位波动速度、单月最大有效连续降雨、单月库水位日浮动最大值、月位移速度的定性化成果见表1~表7。
由表1中月累计降雨量的两步聚类结果可知:月度累计降雨量被划分为Heavy_Rainfall、Moderate_Rainfall、Light_Rainfall 三簇,分布表征月累计降雨量为183.5~517.6 mm、69.9~179.8 mm、3.1~66.1 mm。
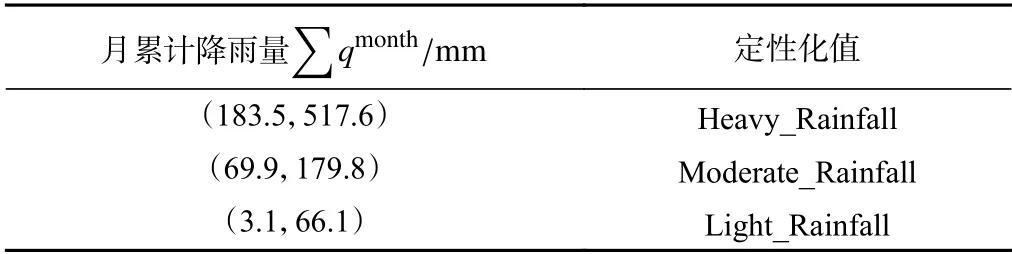
表1 白水河滑坡月累计降雨量定性化成果Table 1 Qualitative results of monthly accumulated rainfall of Baishuihe landslide
由表2日降雨量月度最大值两步聚类结果可知:日降雨量月度最大值按照强度分布被划分为55.9~160.7 mm、26.5~55.2 mm、1.3~25.6 mm 被划分为Heavy_Rain_Shower、Medium_Rain_Shower、Light_Rain_Shower 三簇。
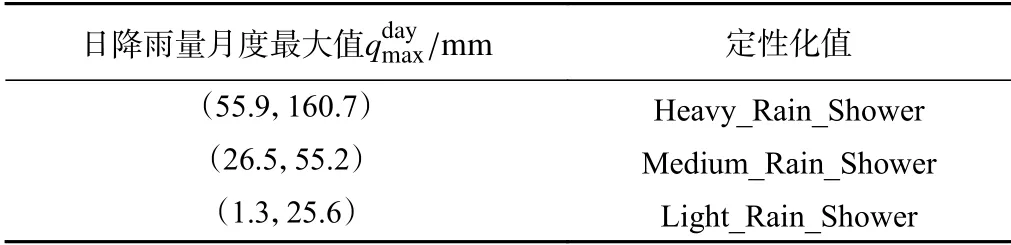
表2 白水河滑坡日降雨量月度最大值定性化成果Table 2 Qualitative results of monthly maximum rainfall of Baishuihe landslide
由表3中库水位月度平均值两步聚类结果可知:库水位月度平均值被划分为High_Water_Level、Medium_Water_Level、Low_Water_Level 三簇,分别表示月累计降雨量为160.14~174.74 m、144.21~158.47 m、135.13~138.95 m。

表3 白水河滑坡库水位月平均值定性化成果Table 3 Qualitative results of monthly average water level of Baishuihe landslide reservoir
由表4月库水位波动速度两步聚类结果可知:月库水位波动速度按照(13.26,17.35)、(7.23,11.36)、(1.57,5.89)、(-1.56,1.31)、(-7.09,-3.41)、(-13.02,-8.59)被划 分 为 Sharply_Rise、Medium_Rise、Slowly_Rise、Smooth Fluctuation、Medium_Drop、Sharply_Drop 六簇。
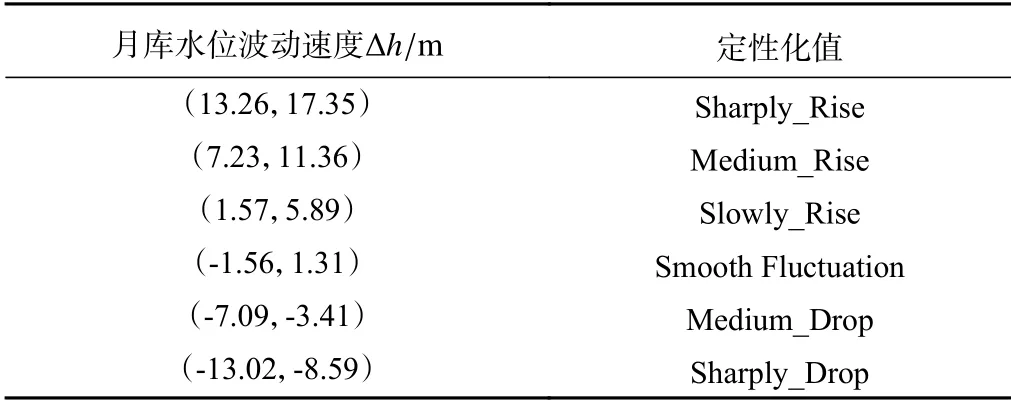
表4 白水河滑坡月库水位波动速度定性化成果Table 4 Qualitative results of water level fluctuation rate of Baishuihe landslide monthly reservoir
由表5中单月最大有效连续降雨量两步聚类结果可知:单月最大有效连续降雨量被划分为High_Effective Rainfall、Medium_Effective Rainfall、Low_Effective Rainfall 三簇,分布单月最大有效连续降雨量为110.5~239.4 mm、36.6~109.8 mm、1.5~36.1 mm。
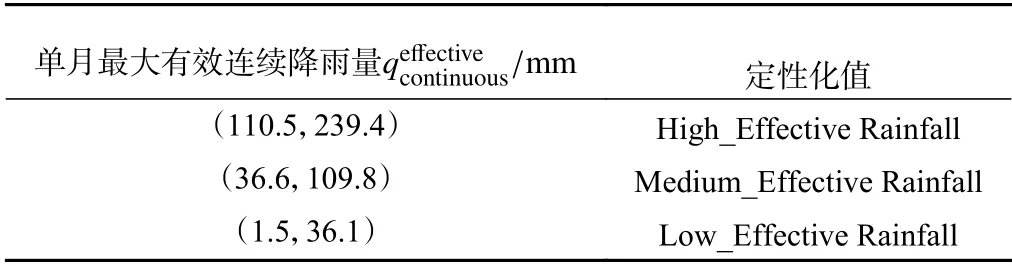
表5 白水河滑坡单月最大有效连续降雨量定性化成果Table 5 Qualitative results of maximum effective continuous rainfall in a single month of Baishuihe landslide
由表6单月库水位日浮动最大值聚类结果可知:单月库水位日浮动最大值按(1.66,3.223)、(0.744,1.513)、(0.063,0.63)、(-0.414,0)、(-1.697,-0.49)划分为Sharply_Rise_Water、Medium_Rise_Water、Slowly_Rise_Water、Slowly_Drop_Water、Medium_Drop_Water 五簇。
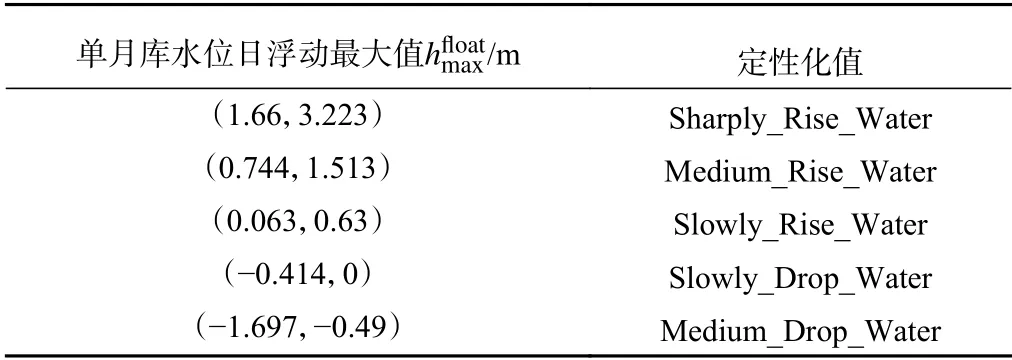
表6 白水河滑坡单月库水位日浮动最大值定性化成果Table 6 Qualitative results of the maximum daily fluctuation of the water level in a single month of Baishuihe landslide
白水河滑坡为较典型的阶跃型滑坡,采用两步聚类法将白水河滑坡的变形演化划分为三个阶段(表7),主要包括:变形起始阶段(Ⅰ)、变形稳定阶段(Ⅱ)和变形加速阶段(Ⅲ)。
白水河滑坡月位移速度定性化结果详见表7。由表可知:变形起始阶段(Ⅰ)表示坡面监测点以-0.195~0.078 mm/mon 的速度变形,此集合占所有集合的42.3%;变形稳定阶段(Ⅱ)表示坡面监测点以0.092~0.939 mm/mon 的速度变形,此集合占所有集合的40.5%;变形加速阶段(Ⅲ)表示坡面监测点以1.042~10.669 mm/mon 速度变形,此集合占所有集合的17.2%。

表7 白水河滑坡月位移速度定性化成果Table 7 Qualitative results of monthly displacement rate of Baishuihe landslide
4.3 关联准则挖掘
采用Apriori 算法将影响因子作为关联前项,滑坡位移速度为关联后项。考虑实际数据的有效性与实用性,设定支持度阈值为5%,置信度阈值为80%,生成白水河滑坡位移同影响因子的关联准则。共生成关联准则87 项,结果显示大多数规则后项处于变形第I、II 阶段——变形起始阶段及变形稳定阶段。这两阶段坡面位移变化较小,仅为-0.195~0.939 mm/mon。考虑实际滑坡变形时主要考虑第III 阶段——变形加速阶段的位移变化。从众多关联结果中选取提升度大于1 的准则,提升度大于1 时表明关联前项对关联后项的出现有促进作用,则此准则具有较好的参考与实际意义。经过筛选后的关联准则成果详见表8。

表8 白水河滑坡多场信息关联准则Table 8 Multi field information association criterion of Baishuihe landslide
结果显示:规则1 为关于坡面监测点处于变形起始阶段且包含库水位月平均值(High_Water_Leve)的关联准则。可解读为:当库水位月均值处于高水位线时(160.14 m≤≤174.74 m),坡面监测点进入变形起始阶段。规则2~3 为关于坡面监测点处于变形起始阶段且包含高强度日降雨量月最大值的关联准则。可解读为:当滑坡区域日降雨量月度最大值为高值时(Light_Rain_Shower),坡面监测点进入变形起始阶段。
规则4~6 为坡面监测点处于变形稳定阶段的关联准则。规则中包含的水文因子主要有中低值的最大有效连续降雨量(Medium_Effective Rainfall、Low_Effective Rainfall)及中低等速度的库水位变化过程(Slowly_Rise、Smooth Fluctuation)。由关联结果可知,中低程度的最大有效连续降雨及中低程度的库水位变化对坡面监测点位移变形不会造成太大影响。
规则7~10 为坡面监测点处于变形加速阶段的关联准则。规则中包含的水文诱发因子主要由强降雨(Heavy_Rainfall)和高强度的最大有效连续降雨(High_Effective Rainfall)组成。由关联结果可知,强降雨和高强度最大有效连续降雨是引起坡面监测点的显著变形的主要因素。
通过关联准则挖掘得到的结论与白水河滑坡实际位移变形影响因子结果进行对比得知,数据挖掘流程得到的关联准则能较好的用于滑坡位移监测预报。
5 结论
通过对完整的数据挖掘流程与关联准则结论进行分析,得到主要的成果与结论如下:
(1)对白水河滑坡ZG93 监测点数据进行分析研究,在6~9月汛期来临之时,白水河滑坡变形位移会受强降雨的影响。库水位对滑坡位移的影响主要表现在2007年6月第一次蓄水引起的较大变形及水库开始蓄水后,当库水位下降时,随降雨强度的增大,滑坡的位移变形同步大幅增大。
(2)分别对六种影响因子进行两步聚类并得到对应因子的定性化成果:月累计降雨量(∑qmonth)定性化成果、日降雨量月度最大值()定性化成果、单月最大有效连续降雨量()定性化成果、库水位月度平均值()定性化成果、月库水位波动速度(Δh)定性化成果、单月库水位日浮动最大值()定性化成果。
(3)结合数据挖掘流程,建立了白水河滑坡多场耦合作用模式下的影响因子与滑坡位移变形关联准则判据。共生成白水河滑坡多场信息关联准则87 项,选取其中关联度强的10 条规则进行分析,关联准则成果显示:强降雨和高强度最大有效连续降雨是引起坡面监测点的显著变形的主要因素。
(4)以白水河滑坡为例,按照数据挖掘流程得到多场信息关联规则,对于滑坡灾害的变形分析具有重要的意义,数据挖掘技术可较好地应用于三峡库区地质灾害位移预测预报中。
