基于体感识别技术的运动训练辅助系统设计
2022-01-06郑永权张飞云周帅
郑永权,张飞云,周帅
(西安交通大学城市学院,陕西西安 710018)
随着经济水平的提高,人们更加注重身心健康,积极参与运动锻炼[1-2]。随着无线通信和图像处理技术的迅速发展,新型运动装备以智能化的互动方式正改变着人们的运动习惯[3-5]。传统的运动装备只是简单地记录运动者的运动时间、距离等物理信息,并根据简单的统计学计算得出相关运动建议[6]。而以Kinect、VR 为代表的新型运动装备具有捕捉人的运动姿态、丰富运动场景等功能,增强了运动的趣味性。
体感识别是指通过某些装置识别人的肢体动作,从而实现某些功能,其被应用于多种场景,常见的有运动类游戏、手势拍照、人脸支付等[7-9]。迄今为止,业界学者对于体感技术的分类主要基于其实现原理来进行划分,通常分为惯性感测、光学感测、惯性与光学联合感测以及其他方式感测。其中,应用最广泛的体感设备是由日本索尼公司开发的EYE TOY[10-16]。
该文将体感识别技术应用于常规运动训练中,以Kinect V2 为运动数据采集设备,利用分隔策略降低数据量,同时精简骨骼关节个数从而降低动作识别的复杂度,并通过寻找标准化模量的方法来降低绝对数据引发的偏差。采用堆叠模型和VGG 卷积神经网络将二维关节数据转换成人体姿态图,并将其作为模型的训练样本,完成训练和参数优化后,最终得到运动动作识别模型。
1 基于体感识别技术的运动训练辅助系统框架
文中利用Kinect V2 配备的摄像头传感器、计算机、显示设备、云服务器来进行运动训练辅助系统的硬件设计,具体硬件连接如图1 所示。首先,计算机作为整个系统程序的执行中心,负责接收用户的身份认证信息和Kinect V2 摄像头传感器采集的数据,然后将相应数据传送至显示设备和云服务器;Kinect V2 摄像头传感器负责采集用户的肢体动作,并将数据传输至计算机;显示设备负责显示运动训练辅助系统的用户登入界面、训练实时动作识别结果、训练日记等信息;云服务器负责接收用户上传的运动训练数据和系统更新数据包等。

图1 硬件连接示意图
文中所述运动训练辅助系统采用C/S 框架,考虑到用户较多,因此采用多个客户端与一个服务端进行设计。其中,客户端在功能上涉及对用户实时运动动作的识别、动作分析、用户信息采集、数据储存与服务端的通信等;而服务端主要位于云服务器,涉及客户端的系统更新、历史运动训练数据储存等。系统框架如图2 所示。该系统软硬件之间通过USB 3.0 进行数据的传输;客户端与服务端之间的通信采用TCP/IP 通信协议。

图2 系统框架示意图
2 运动识别算法与实现
2.1 人体动作数据采集
当人在运动时,通过Kinect V2 摄像头传感器采集到的视频数据通常具有较大的容量,不适合直接进行动作分析;另外,由于人物所处环境较为复杂,滤除背景可提高人物动作的识别精度,因此需要进行数据预处理。
Kinect V2 采用红外发射器投射经过调制后的近红外光,通过解析近红外光经物体反射回来的时间差来得到物体与Kinect V2 摄像头传感器的距离,使用近红外光线可有效降低光线变化对成像质量的影响。另外,在识别人体动作时采用分隔策略将人物从背景中分离出来,并在后续识别过程中只保留人物的图像,以降低人物动作识别计算量。
由此得到的人物深度图中通过机械学习算法可以识别人物的骨骼点,骨骼点的移动表示人物身体各个部分的移动。如图3 所示,将人体简化为18 个关节部位,通过观察这18 个点的位置移动来判断人体的动作。任何运动动作的识别均基于人体肢体的基础动作,这些基础动作包含肢体弯曲、关节扭转等。由于人体身体构造的限制,肢体转动的角度均不超过180°,因此可以选择余弦函数作为肢体转动角度函数。
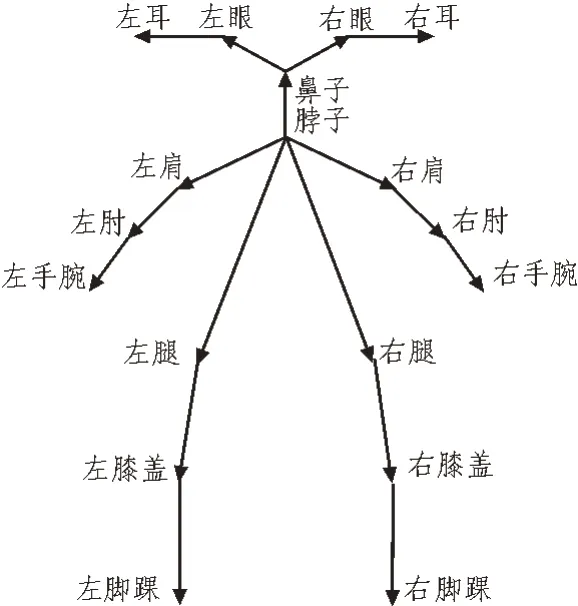
图3 人体关节示意图
2.2 多目标动作追踪
通过摄像头传感器采集人体6 个基础动作的18个关节点的位置信息,这些位置信息将作为基础动作要素。每一个关节点的位置信息均由二维坐标组成,将一段时间的关节点位置信息组成数据集,即可得到诸如跳跃、站立等基础动作的数据模板。当人在做复杂动作时,则需要使用多目标跟踪来捕捉关节点位置数据。其具体流程如图4 所示。

图4 多目标跟踪算法流程图
文中使用Deep Sort 多目标算法进行关节点位置信息的获取。该算法对摄像头采集到的每一帧画面进行目标检测,并将检测结果经有权值的匹配算法处理后与之前运动轨迹相比较,形成关节的运动轨迹。其中,权值的确定需要通过点和运动轨迹的马氏距离来计算,而马氏距离则通过Kalman 滤波函数计算。当前轨迹与之前轨迹是否匹配,需要设定一个阈值来进行比较,该阈值被定义为相邻时刻画面的轨迹匹配成功所用的时间差。当该时间差大于阈值时,表明相邻时刻画面的轨迹长时间匹配不成功,则认为该动作已停止。在匹配过程中可根据不同特征的最大响应数值来分配权重值,具体计算公式为:
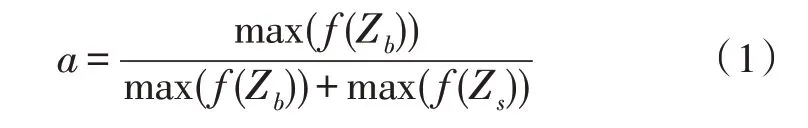
式中,f(Zb)、f(Zs)表示图像边缘特征的梯度角度以及色度饱和度的响应输出向量。
上文提取到的关节骨骼位置数据中包含着大量的噪声数据和无用数据,在进行动作识别前需要进行数据预处理来提高有用数据的比例。文中使用寻找标准化模量的方法,来降低绝对数据引发的偏差。人体固有肢体结构数据所提取的向量因受人体动作变化影响较小,故可作为标准向量。通过调用Open Skeleton Frame()函数,可实现骨骼数据的获取。
2.3 运动训练实时动作识别模型
利用上文获取的多目标骨骼数据,文中以自下而上的顺序对关键关节进行检测,并依据关键关节的分布位置来确定人的姿态。为了实现更精准的人体姿态识别结果,文中将VGG 和卷积神经网络相结合进行关键关节的检测。其具体结构如图5 所示。首先将Kinect V2 摄像头采集到的画面输入至VGG中进行特征向量F的提取;再将特征向量F作为卷积神经网络第一阶段的输入,通过多个阶段的回归得到该图片的关键关节,并在第二阶段利用贪心推理识别各个关键关节的相对位置,形成人体骨骼的姿态。

图5 人体姿态估计算法结构图
为了实现实时连续动作的识别,需要对每一个画面的人体姿态进行综合分析。该文利用上文得到人体姿态图,通过搭建堆叠模型来实现实时运动动作的识别。具体过程如下:
1)将每一帧的人体姿态图进行预处理,得到数字图像特征,并用one-hot encoding 进行编码;
2)将线性堆叠模型和VGG 卷积神经网络联合训练,使用Relu 作为激活函数,Soft max 作为分类函数;
3)使用Compile 对模型参数进行设置,并在样本数据训练时进行参数调优;
4)使用测试数据,验证模型对训练动作识别的准确度。
在上述堆叠模型中融入Batch Nor maization,该函数可将数据归一化,使得每个数字图像特征的分布均值为0、方差为1。由于实时采集的图像数据较多,为了增强实时识别效率,利用数据的规范化和线性变换来实现VGG 卷积神经网络中不同层之间的解耦,最终实现整个人体运动动作识别模型的学习速度。
堆叠模型在规范化数据时,具体表达式为:

对于动作识别的精度,分类器的选择尤为重要。文中将Softmax 作为动作识别分类器,该函数的表达式为:

该函数将VGG 卷积神经网络的神经元输出映射为(0,1)之间的实数,且总和为1。式(4)中Vi表示Softmax 分类器前级神经元的输出,i表示动作的类别,C为动作类别的总数,Si表示当前动作分类的概率值与所有动作分类概率和的比值。
3 测试与验证
为了验证该文所述方案的有效性和可行性,文中使用挥手、踢腿、弯腰和蹲4 个动作进行验证。测试过程中使用Intel(R)Core(TM)i7-3470 CPU@3.2 GHz,16 GB 的计算机;代码编辑器使用Sublime Text。首先选择5 名男生、5 名女生作为志愿者,为了保证较高的模型识别精准度,该10 名志愿者应具有不同的身高、体重等外形。分别让这10 名志愿者做100 组上述4 种动作,并按照8∶2 的比例划分为样本训练数据和验证数据。由于动作识别数据多分类问题,需要对上述动作进行编码,即将挥手、踢腿、弯腰和蹲分别使用0、1、2、3 表示。图6 给出了训练数据和验证数据的训练精度结果对比。从图中可以看出,通过增加训练次数,训练数据和验证数据的精度曲线逐渐重合并趋向于0.86,这表明该文所述方案具有较好的稳定性和鲁棒性。

图6 训练数据与验证数据的训练精度对比结果
另外,为了验证该文所述方案的实用性,使用LSTM 动作识别算法作为对照组进行对比试验,对照组与实验组使用相同的软件、硬件设备和训练数据。表1 给出了实验组和对比组的4 种动作识别准确率结果。由表可知,文中所述方案比LSTM 动作识别算法具有更高的识别准确率,这表明该文所述方案具有一定的可行性和实用性。值得注意的是,两种动作识别算法对弯腰和蹲的识别准确率均较低。这主要是由于做这两种动作时,关节存在重叠现象,仅靠一个摄像头采集的数据难以有较高的区分度。

表1 实验组和对比组的4种动作识别准确率结果
4 结束语
该文将体感识别技术与机器学习中的VGG 卷积神经网络应用于运动训练辅助系统的设计中,以提高对人体实时动作的识别准确率。该运动训练辅助系统将采集到的实时画面进行人物与背景分离,并采用18 个关键关节的数据使用VGG 卷积神经网络来构建人体姿态图,并利用堆叠模型实现实时连续动作的识别。通过验证实验,证明了文中所述方案具有一定的鲁棒性和可行性。
