基于分布式聚类的制造业大数据监测与分析算法
2022-01-06张路
张路
(台州职业技术学院经贸学院,浙江台州 318000)
随着我国制造业发展的不断创新,智能制造的应用逐渐普及。国家综合实力的重要提升手段,即是本国制造业的迅速发展。制造业大数据作为生产过程的重要要素,能在较大程度上推动制造业的升级转型[1]。
大数据分析是评估各种数据集以发现模式、相关性、市场趋势和其他有用信息的技术手段,可以帮助相关部门作出更明智的决策[2]。大数据算法需要与实际数据共同发挥作用,此外,在智能车间使用智能制造对象的RFID 数据的相关研究也较少。为了弥补这些不足,该文针对制造业RFID 大数据使用分布式聚类算法建立了监测与分析的算法架构。
1 大数据监测分析算法架构
RFID 数据来自具有物联网功能的制造车间。当操作人员使用阅读器对标签进行检测或对RFID阅读器进行操作时,系统将记录一条RFID 数据。其数据集定义如表1 所示[3]。
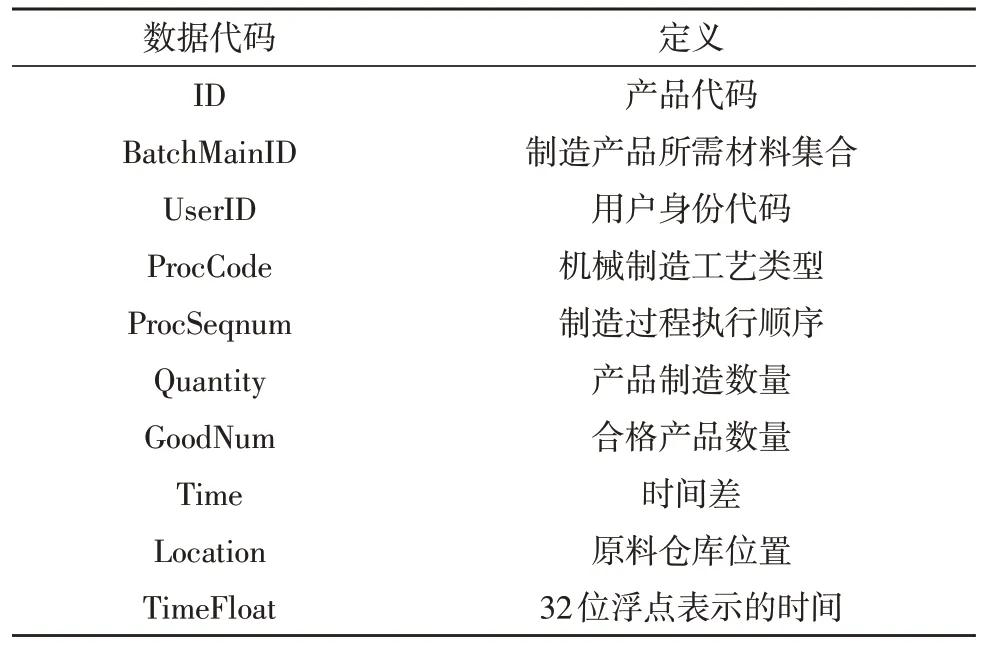
表1 RFID数据集定义
数据记录员通过操作这些数据集可以计算出以下主要变量:一种是在一段时间内跟踪特定的BatchMainID,然后对比批处理所需的时间。一种是UserID 和ProcCode,用于观察操作员在车间的操作效率,最后,通过跟踪每个BatchMainID 以获得完成制造批次所需的操作员数量,对于制造业数据分析也有较为重要的意义。
此次所提出算法方案的工作流程如图1 所示。该体系结构涉及4 个主要过程:数据预处理[4]、分类、模式识别和可视化[5]。从制造车间的大量RFID 数据生成有关制造工厂生产效率的信息可视化视图,这些相互独立的数据集群为预测提供线性或非线性回归数据。
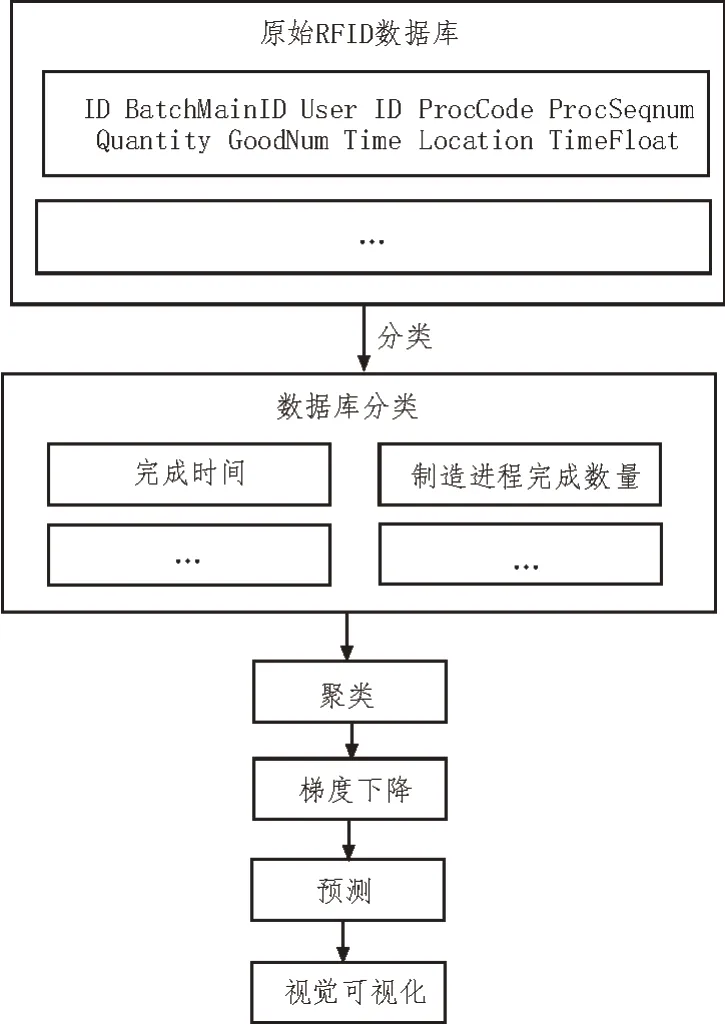
图1 算法流程
1.1 数据预处理
原始RFID 数据没有TimeFloat 数据代码,因此在将数据导入TensorFlow 程序时,需要将其修改为正确的格式。原始RFID 数据时间按照连续的日、月和年格式(DD/ MM/ YYYY)排列,该算法只支持使用数字类型(例如整数或浮点数),因此程序无法直接使用该数值。此外,为了方便计算,闰年的影响忽略不计[6]。
此次实验用的RFID 数据集总共包含413 472 个数据。考虑到BatchMainID 的完成时间,需要对制造业数据的时间信息重点分析。因此为了提高处理速度,所有没有时间条目的数据均被删除[7]。经过初步筛选的数据为376 746 个条目,但这些条目是从制造车间的高集成度传感器中收集的,且信息量不足。通过对数据采用线性回归和质心比较法[8],进一步筛选有用数据至176 746 个。
1.2 批次识别算法实现
此次通过使用BatchMainID 与时间之间的关系进行数据分析,以产生具有统计意义的相关数据,实现对制造数据批次的识别[9]。
图2 显示了匹配的BatchMainID 进程与时间的所有176 746 个样本的绘图。样本数据较集中,因此难以识别隐藏的模式或趋势。另外,整体数据的计算成本较高。因此可以得出结论:数据集聚类分析是算法设计的重难点问题[10]。
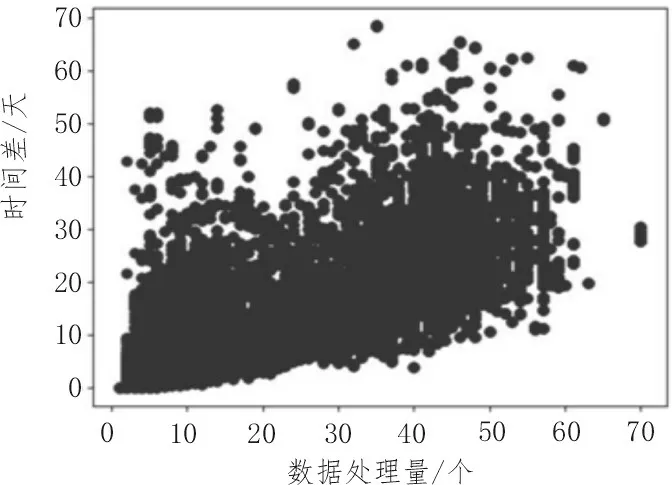
图2 BatchMainID与时间关系图
此次通过跟踪各个BatchMainID 以获取开始时间和结束时间,并计算完成批处理的进程数量[11]。文中使用的分布式机器学习聚类方法是有监督和无监督学习过程的集成,首先使用K-means 聚类(一种无监督的学习方法)将数据分组为多个聚类[12]。然后使用梯度下降优化算法(一种有监督的学习方法)来计算预测值,并减少成本与目标函数的损失[13]。
2 分布式聚类算法设计
K 均值聚类算法核心为分布式思想,该过程从数据集和一组随机聚类中心开始。在每个迭代过程中,将每个元素分配给其最接近的集群[14],这样的设计能够在基于单个处理器的传统计算机上良好地运行。传统的集中式K 均值算法在使用计算机求取聚类结果时,要用到所有需要聚类的数据[15]。在数据量较大的应用场景下,集中式聚类服务器难以达到效能要求,因此提出了分布式的聚类算法。分布式聚类服务器通过Internet 网络连接实现通信,各个站点仅计算部分信息。分析数据根据就近原则存储在网络的不同站点上,聚类结果通过网络通信协议相互影响[16]。分布式K 均值聚类算法的关键问题是协调各个站点之间的数据计算,即全局中心计算问题,这与集中式K 均值数据分析方法有本质的区别。该文提出了一种针对解决全局中心计算问题的算法,以实现大数据下分布式K 均值中心算法的设计。下面将详细描述改进的分布式聚类算法的实现过程:
每个处理器Si根据站点的制造业数据,初始化一组任意的聚类中心向量Mi={mk|k=1,2,…,K}。每个站点相互独立地计算数据中心点,在设计的分布式算法的每次迭代步骤中,本地站点Si将计算得出的聚类中心通过UDP 通信协议广播到通信网络中。在本地站点上聚类后,所有聚集的本地数据和估计的中心点矢量均将作用于;而新的中心点矢量将被计算并记录为。在每次迭代产生新聚类中心的过程中,为了避免站点聚类结果出现空集,迭代过程中的估计中心点被添加至聚类数据中。
中心计算是设计的分布式聚类分析算法的最重要特征。为阐述集中式与分布式聚类算法的核心区别,可用式(1)与式(2)说明,集中式K 均值可表达为:
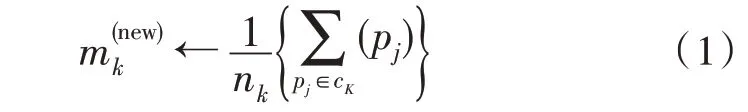
分布式K 均值可表达为:

每次迭代产生的新中心向量以广播方式存储在所有站点上。每个站点Si根据本地数据计算所得的聚类中心值和从其他站点收到的聚类中心值,根据加权平均法得出新的中心值,并替换。分析可知,聚类服务器除去在迭代第一步可能出现空集的情况外,所有站点在所有的迭代步骤中均可确定唯一的聚类中心。通过上述步骤,即可实现聚类中心向量范数稳定,直至聚类结束。
由于数据规模与通信的要求,分布式数据监测与分析对于计算机性能有较大的考验。为了检测算法对于计算机资源的要求,对分布式K 均值算法的复杂度进行分析。对于任何并行和分布式聚类算法,复杂度均有两个方面,即时间复杂度Ttime和通信复杂度Tcomm。在通信过程中,数据、中心向量等相关信息需要从一个站点传输到另一个站点。首先分析一个迭代步骤中分布式聚类算法的复杂度,处理站完成一项聚类后,实际通信时间定义为Tdata;服务站与通信网络建立通信连接所需的时间定义为Tstart。由于数据传输是并行执行的,因此仅传输一个数据,每一步的复杂度为:
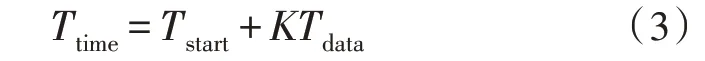
计算距离的复杂度为:

Tdist是处理站计算处理单个制造业数据的时间;设计的分布式分析算法复杂度可由式(5)得出:

式中,T为网络中聚类算法的迭代次数。
忽略处理器间的连接时间,算法复杂度可用以下形式表示:

从上式可以看出,时间复杂度不仅包含TKTdist,且包含本地站所有数据矢量的计算、本地站点元素数量分配、所有本地站点的欧几里德最小二乘误差计算以及通信复杂性。算法复杂度仅呈线性增长,可用于大范围部署。
3 实验验证
为验证该系统的有效性,使用基于RFID 的制造业大数据进行算法验证。
预测算法的结果如表2 所示。输入是一维数组,该数组描述了进程数;输出为这些进程与集中处理器的分配方式。预测百分比表示了分配的准确率,可以看出该方法比计算预测更可靠。
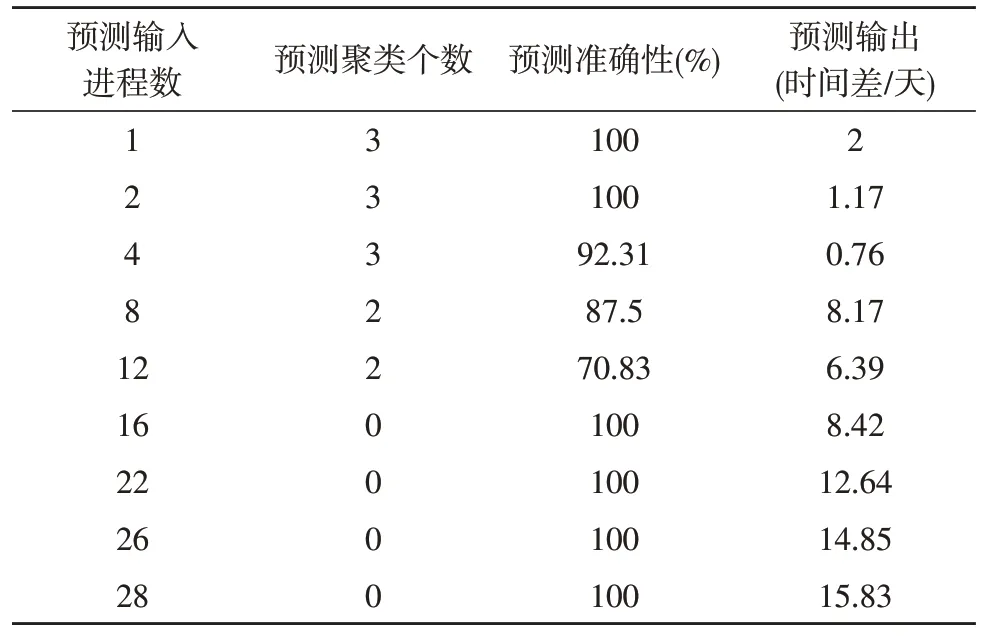
表2 预测结果
通过5 次独立进行的实验操作,取每个样品的平均数作为计算成本来验证实验结果,如图3 所示。
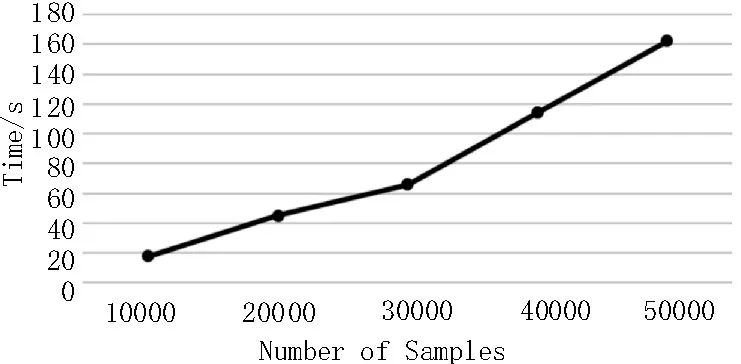
图3 计算成本实验
可以看出,随着样本数量的增加,计算时间成本也在增加。由于该算法进行数据预处理、可视化和优化需要花费时间,因此实验结果是合理的。为排除大数据中的错误并对不确定性数据进行处理,计算成本实验使用了高达10 000 个样本。由于算法内产生的是随机数(例如权重、常数和预测输入值),即使样本数相同,每次运行的计算成本也不同。但从图3 可以看出,综合统计成本下,计算成本与样本数呈线性关系,并未由于数据量的增长而造成成本的显著上升。
实验使用的处理服务器为2.50 GHz 的Intel®Core™i7-6500U CPU。测试可知,若该算法在NVIDIA GPU 支持下进行数据分析,则可降低计算成本,因为TensorFlow 程序在GPU 上的速度明显快于CPU 处理速度。
为了测试该算法的多平台运算能力,在CPU(Intel i7-6700)的计算平台上,采用3 种具有不同功率水平的GPU 和基于DSP 的处理器(Intel Movidius)进行了聚类算法测试,实验结果如图4 所示。使用的GPU 是NVIDIA Jetson TX2 的Max-Q 与Max-P,分别标记为GPU#1和GPU#2,GPU#3为NVIDIA Tesla V100。显然,GPU#3 在处理速度上优过其他类型的处理器,而其相应的最大功耗明显大于其他处理器。

图4 跨平台测试实验
在验证算法分析准确率与成本的基础上,通过引入不同类型的样本数据以进一步评估算法的表现。由于计算量大,仅将前10 000个样本生成的模型与最终选择的样本进行比较。根据经验可知,分析超过10 000 个数据大小会产生较高的计算成本。同样,绘制的数据越多,可见性的质量就越差。
图5 为10 000 个样本的分类散点图,其描述了最近10 000 个样本的聚类结果。分析图5 可以看出,该算法对于生产数据可以精确地分为不同的类型,准确率可达98.9%以上,算法对预处理的制造业大数据聚类时间仅为13.2 s,具有较好的实时性。
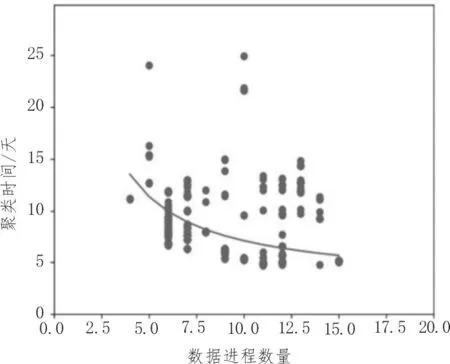
图5 样本分类散点图
4 结论
该文设计了一种大数据分析方法,用于检测与分析来自制造业的大量RFID 数据。该方法包括了数据的处理和可视化,并对其进行了综合验证和评估,得到结论如下:1)可以直接对从制造现场获取的大数据进行分析,以作出预测并提高效率;2)提出了梯度下降和聚类方法的组合。当使用大量样本对算法进行测试时,将损失降至合理的水平。
今后的工作重点将放在如何在移动终端中实现分析的可视化,以便于用户访问。此外,算法商业化则需要考虑软件设计原理,以提高所提出方法的可读性、可扩展性、有效性和数据处理效率。
