基于注意力机制的弱监督细粒度图像分类①
2022-01-06李文书王志骁李绅皓
李文书,王志骁,李绅皓,赵 朋
(浙江理工大学 信息学院,杭州 310018)
1 引言
近些年来图像分类技术通过对深度卷积神经网络的运用取得了长足的发展,然而其不足也依然存在.在当下这个智能化要求又不断提高的大环境下,简单的“语义级”的图片分类已经不足以满足用户的需求,因而更加精细化的细粒度图像分类更加值得关注,例如在生态保护场景中识别不同种类的珍稀鸟类,水稻种植生产中识别不同种类的虫害,新零售场景下对同类食品的细分类等等.利用计算机视觉方法识别细粒度类别(如鸟类[1,2]、花卉[3,4]、狗类[5,6]、车型[7]等)的技术已引起研究者们的广泛关注[8-10].其中能够准确定位和表示类别中细微视觉差异的细粒度图像识别技术是非常具有挑战性的.
1.1 细粒度图像分类的研究历史与现状
随着计算机硬件算力的提升,深度学习技术被广泛用于解决复杂图像分类的问题.其中,卷积神经网络(Convolutional Neural Network,CNN)是深度学习解决分类问题的代表性网络之一.2015年,何恺明等提出的残差神经网络(Residual Network,ResNet)[11]采用了更深的网络层数,并且引入了残差处理单元解决网络退化的问题,取得了极佳的效果.2017年,Google团队设计一种具有优良局部拓扑结构的网络Inception-V3[12],即对输入图像并行地执行多个卷积运算及池化操作,并将所有输出结果拼接为一个非常深的特征图,取得了优异的效果.但是经典卷积神经网络聚焦于类间分类的问题,并不能有效解决细粒度图像分类(类内分类)的分类问题.细粒度图像的类别精度更加细致,类间差异更加细微,往往只能借助于微小的局部差异才能区分出不同的类别.
细粒度图像分类发展初期仍依靠人工注释的边界框/部件注释.大量的人工参与使得部分定义和注释变得昂贵且主观,这对于细粒度的识别任务都不是最优的(文献[13,14]表明边界框/部件注释依赖于人的注释,由此带来主观性强和成本昂贵等问题).越来越多的算法倾向于不再依赖人工标注信息,而使用类别标签来完成分类任务.
Lin等提出了一种端到端的双线性网络[15],通过对卷积层输出的特征进行外积操作,能够建模不同通道之间的线性相关,从而增强了卷积网络的表达能力.Ge等基于双线性网络提出一种核化的双线性卷积网络[16],通过使用核函数的方式有效地建模特征图中通道之间的非线性关系,进一步增强卷积网络的表达能力.此模型能够融合不同通道的信息,但是并没有有效地提取出具有鉴别性的局部特征.
一种采用锚框的机制[17,18]可以有效地定位信息区域而无须边界框并挖掘概率较高的含更多的对象特征语义的区域,从而增强整个图像的分类性能,但是对特征全局定位有所欠缺.除了使用锚框定位局部特征,注意力机制也被应用于细粒度图像分类,Fu等[19]提出了一种注意力网络,利用两个任务之间的联系,相互增益彼此的精度,在多尺度上递归地学习区分度大的区域以及多尺度下的特征表达.该方法较好地提取了局部的特征信息,但是对全局信息捕捉较弱.为了进一步在图像中同时产生多个注意位置,基于提取多个局部特征的注意力方法[20,21]相继提出,但有限的注意力个数并不能充分表达图像的特征.
1.2 计算机视觉中注意力机制的研究历史与现状
人类视觉系统中存在一种现象,当人眼在接受外部信息时对每个区域的关注度存在差异,例如人眼在看一幅图像时会聚焦在感兴趣的目标身上而忽略背景图像,这就是人类视觉系统中的注意力机制,这一机制也被应用于计算机视觉中.近几年,计算机视觉中注意力机制发展迅速[22],出现了很多基于注意力机制提出的深度学习网络,其主要实现方式是通过为特征图添加掩码(mask)的形式,即通过为特征图添加权重,将有用的特征标识出来.从注意力域的角度可以将注意力实现方式分为空间域和通道域.
空间域是从特征图的空间位置关系出发,不区分通道带来对分类性能的影响.其中,细粒度图像分类任务中,2020年Yan等[23]提出的网络模型,在细粒度图像分类中,不同空间位置能够获得不同的关注点,不同大小的空间特征图能够获得递进的特征信息,所以作者提出了一种空间转换器,对图像做空间变换将关键信息提取出来.
通道域是对不同通道的加权,不考虑通道中每个像素点的位置差异.在卷积神经网络中,每张图像初始都有RGB 三个通道.卷积层的卷积操作变换图像的通道,其等价于对原图像进行了分解.每个通道都是原图在不同卷积核上的分量.虽然每个通道都是原图的分量,但在具体任务中并不是每个通道都发挥着相同的作用.基于此,Li等[24,25]提出了SKnet网络模型,SKnet通过对每个通道加权的方式标注出对结果贡献较大的通道,具体做法是通过对每个特征图做全局平均池化将H×W×C的特征图挤压到长度为C的一维向量,然后通过激励函数以获得每个通道的权重,最后对原始特征图上的每个像素点加权.
现有的方法着重挖掘图像的细节特征,但是没有将细节特征更好地融合到全局特征.另一方面,如何将注意力网络和双线性网络融合值得关注.本文的贡献如下:
1)通过线性融合不同通道的特征来建模不同通道之间的线性相关,从而增强了卷积网络的表达能力;
2)通过注意力机制提取显著特征中具有鉴别性的细节部分放入网络中训练,进一步挖掘具有鉴别性的特征,以提升细粒度图像的识别能力;
3)通过主网络和注意力网络分合作训练及共享训练参数,在挖掘表征细粒度图像视觉差异的细节特征的同时,兼顾全局特征的学习.
2 基于注意力机制的细粒度图像分类模型
在图像细粒度分类中,如何获取物体整体与局部信息是一个难点.针对这一难点,本文提出了一种基于注意力机制的弱监督细粒度图像分类(ATtention mechanism Convolutional Neural Networks,AT-CNN)的学习方法用以自动定位和学习细粒度图像中语义敏感对象.该方法首先采用经典的卷积网络方法(ResNet[11],Inception-Net[12]等)提取图像的特征图.主网络通过双通道融合网络表达细粒度特征的整体信息; 然后通过弱监督学习的方式,将特征图通道进行排序并筛选显著的特征放入注意力网络中获取对细节特征的表征能力; 最后通过主网络和注意力网络共享网络参数,共同训练,增强网络对细粒度图像中具有代表性特征的表达能力.本文方法不依赖于边界框/零件标注,可以实现对细粒度图像物体位置的追踪及分类,实现了细粒度端到端的弱监督分类任务,总体分类网络结构如图1所示.

图1 总体分类网络结构
2.1 主网络分支
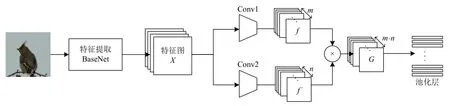
图2 主网络结构
设I表示为输入的训练图片,X表示为卷积网络提取的特征图.则有:

Conv1和Conv2卷积层设计在3.1节详细阐述.通过对f和f′进行外积聚合得到图像的表达,公式如下:
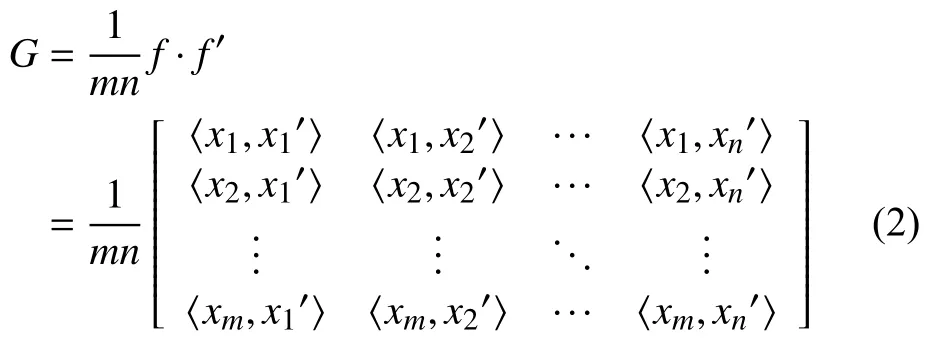
为了使特征矩阵具有较好的分布,需要对特征进行归一化.首先将得到的聚合矩阵展开成向量g,再进行带符号的平方根正则化和归一化,具体公式如下:

最后将特征cmain作为图像的最终表达,送至Softmax中进行端到端的联合训练.
2.2 注意力机制
经典的注意力网络[23,26]可以有效提取图像中关注物体的空间位置,但是细粒度图像分类任务需要定位到具有鉴别性特征的空间位置.为此,本文注意力机制分为注意力特征提取和注意力网络两个步骤.注意力特征提取通过对通道的筛选,提取出关注物体中最显著的局部特征.注意力网络将提取出的局部特征,放入网络中继续训练,提高网络对细粒度对象具有鉴别性特征的表达能力.
2.2.1 注意力特征提取
随着训练次数的增加,输入图像通过卷积得到特征的感受野随网络深度变化而变化,网络可以逐步定位到关注区域的位置.
假设输入图像通过一系列的卷积层及池化层得到大小为C×H×W的特征图,然后特征图上每个C×1×1的跨通道的向量,随着训练次数的增加,能在固定的空间位置上表示原始图像中的对应位置.对应的热力图,如图3所示.基于分类神经网络能够对图像中关注对象的自动聚焦的特性,本文设计的注意力机制网络可以将聚焦的位置信息反馈到最初的图像上.通过类别信息学习到显著特征的位置信息以实现网络的弱监督学习.

图3 训练后卷积网络得到的热力图
特征图的热力图可以随着训练或者物体的整体空间位置.为得到物体细粒度对象的空间位置,需要通过计算特征图不同通道的掩码,对图像通道进一步筛选提取.
首先通过主网络分支可以得到n个特征图p1,p2,···,pn(即n个通道):

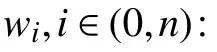
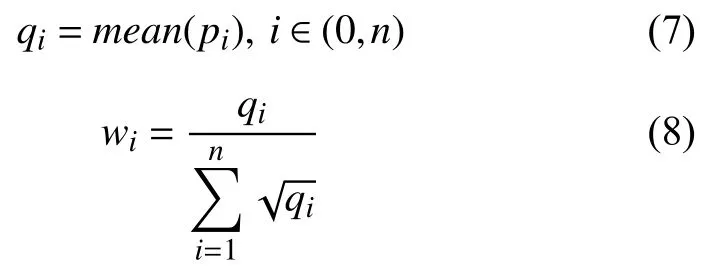
权重wi越大意味着该通道的特征越显著.通过取前m个权重作和得到注意力掩码(mask),从而在显著物体中得到更细粒度的显著特征.特征进一步提取示意图见图4.

图4 特征图通过筛选通道的前后对比图

2.2.2 注意力网络
从特征图中提取到多个最显著特征的位置信息后,通过掩码(mask)操作将前景的物体(较显著特征)在原图中提取出来,记为Iattention.
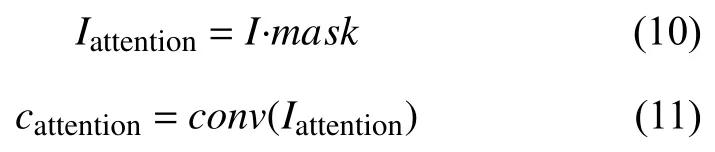
再将提取到的较显著特征放入网络训练,可以得到显著图的特征图cattention,增强神经网络对显著特征的表达能力.注意力网络与主网络共用网络结构,通过共同训练参数,实现网络对整体图像类别和鉴别性的特征都有较好的表达能力.注意力网络如图5所示.
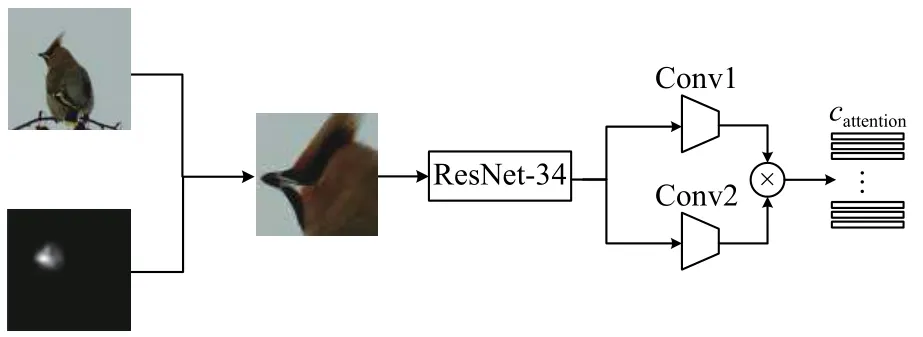
图5 基于注意力机制提取的特征
2.2.3 损失函数
总损失函数结合主网络的损失函数和注意力网络的损失函数,达到合作训练、共同优化.
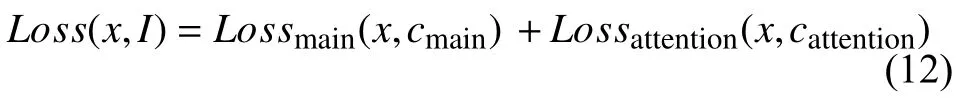
其中,x表示图像类别信息,cmain、cattention分别表示主网络分支,注意力网络分支预测的类型信息.
分类损失使用的是Softmax函数,Loss的计算公式如下:
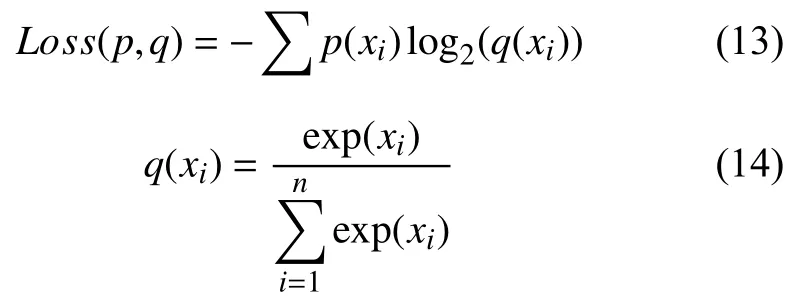
其中,p(xi)为xi的目标值.
模型在梯度下降方法上采用Adam和SGD联合训练的方式.Adam与AdaDelta方法收敛速度更快,但是由于细粒度图像的特征较难学习,导致模型的准确率往往达不到最优解,而SGD的收敛速度较慢,但最终得到的预测效果要优于Adam.因此为了较快收敛同时避免出现局部最优的现象,最终选定先用Adam训练,等准确率不再继续提高的时候,保存网络权重,再采用SGD方法微调.
整体算法总结如算法1.

3 实验分析
本文主要通过3个典型细粒度图像数据集(包括CUB-200-2011鸟类数据集,FGVC飞机数据集,斯坦福狗数据集)进行验证,如表1所示.
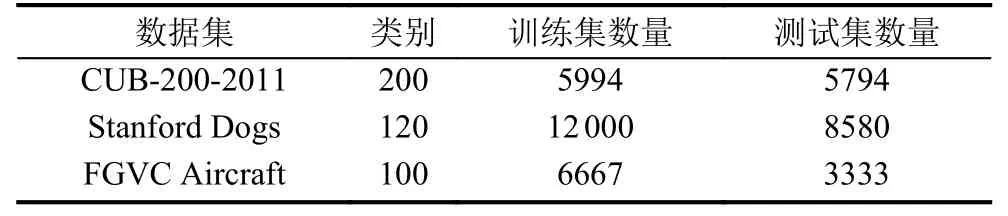
表1 3种常用细粒度分类数据集介绍
实验是在Linux下的Python 3.6.6、TensorFlow 1.12.0和2块16 GB NVIDIA Tesla GPU下进行的.使用Inception-V3预训练模型,训练时batchsize为16,weight decay为0.0001,初始的学习率为0.001,后续采用指数型衰减法,逐步计算学习率.
3.1 线性融合结构设计



图6 不同的特征融合网络结构
通过当网络结构只有主网络分支,分别采用4种不同卷积核在数据集CUB-200-2011上的分类实验,以验证不同卷积核对分类结果的影响.实验结果如表2所示.

表2 不同特征融合网络对分类结果的影响
比较这3种方案对分类结果的影响,可以得出以图6(c)方式在单主网络分支中进行特征融合取得最高的准确率,其能更好地计算特征图在某一区域的响应.
3.2 消融实验
如上所述分类算法由基础网络、线性融合、注意力网络3部分组成.通过在CUB-200-2011数据集中进行实验探索每个组件可以做出的贡献,如表3所示.

表3 不同组件组合对分类结果的影响
通过BaseNet选用Inception-V3作为基线方法,在CUB-200-2011数据集中网络的预测准确率如图7所示.
图7展示了训练次数(epoches)对分类精准度的影响.可以发现随着迭代次数的增加,混合模型准确度有所提高,但当训练次数达到一定值(4万次左右),准确度会保持稳定.

图7 模型在数据集CUB-200-2011的准确率图
3.3 与先进分类方法的比较
为了验证模型的有效性,我们分别在CUB-200-2011、FGVC-Aircraft和Stanford-Dogs三个细粒度经典数据集上进行实验,结果如表4、表5和表6所示.
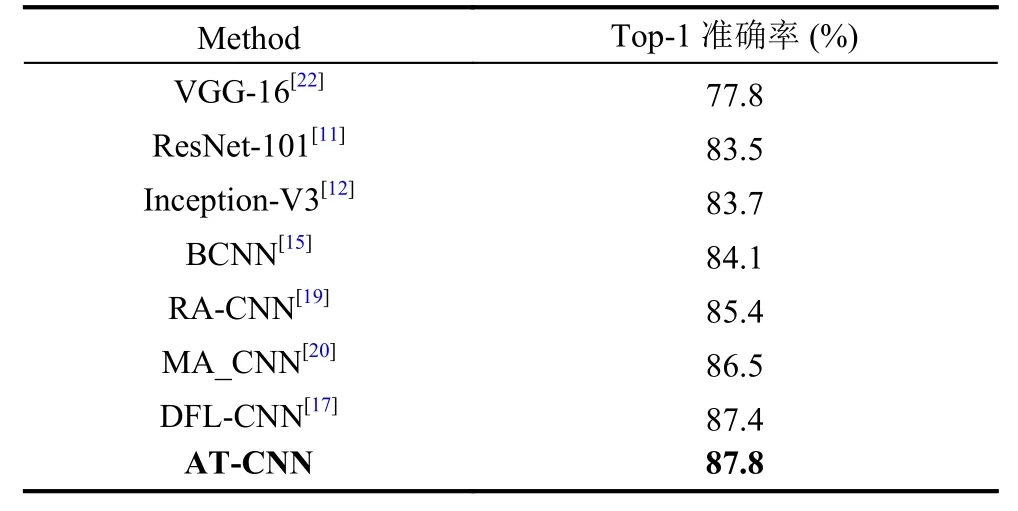
表4 相关分类方法在CUB 200-2011的准确度
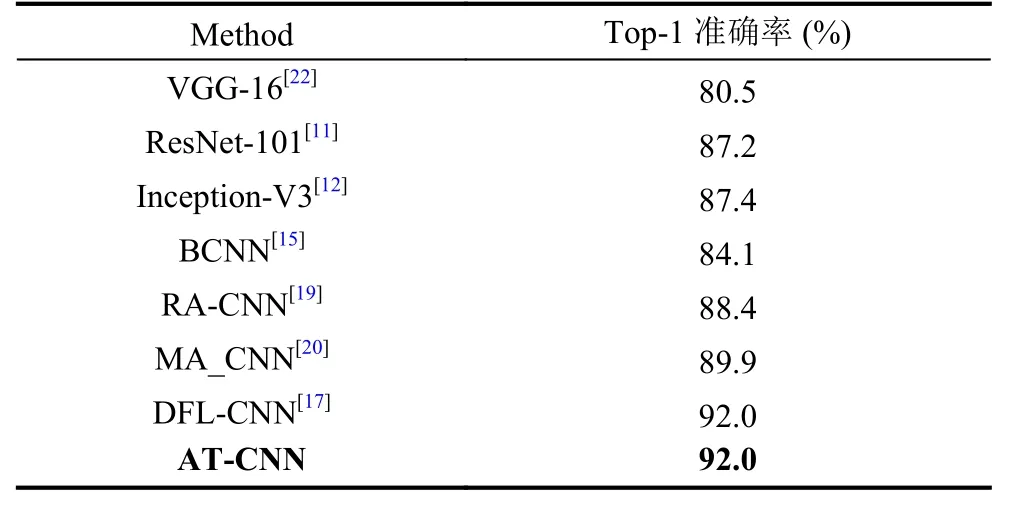
表5 相关分类方法在FGVC-Aircraft的准确度

表6 相关分类方法在Stanford Dogs的准确度
由实验结果可知,本文方法在3个细粒度图像识别数据库上均优于基线方法(BCNN,Inception),如在CUB-200-2011数据上比Inception-V3高出4%,比BCNN高出3.7%.并在3个细粒度数据库上与先进分类方法相比,均取得了领先的水平.
4 结论与展望
本文提出了一种基于注意力机制的弱监督细粒度图像分类.该算法针对细粒度图像类别中细微的视觉差异,设计了基于线性融合网络、注意力网络同步训练的网络模型用于提取细粒度图像中鉴别性强的特征.经实验论证,所提方案可行且有效,进一步提升了细粒度分类的准确性.
细粒度图像分类任务为了识别图中具有鉴别性的对象并对其进行有效的学习,往往模块较多且网络层次较深,这导致模型较大难以部署.下一步,我们关注如何在保证精准度的情况下压缩网络模型,满足移动端的性能要求.
