基于遗传算法的虹膜卷缩轮提取方法①
2022-01-05朱立军邓天娇
朱立军, 邓天娇
1(沈阳化工大学 计算机科学与技术学院, 沈阳 110142)
2(辽宁省化工过程工业智能化技术重点实验室, 沈阳 110142)
卷缩轮[1]是位于虹膜肠环周边的一个环状曲线,将虹膜区域分割为瞳孔区和睫状体区两部分. 根据卷缩轮的膨胀或收缩, 可以判断人体的肠道功能是否出现异常[2,3]. 因此, 准确地检测出ANW的边缘是进一步进行病理分析测的及检前提. 另外, 在基于虹膜的计算机辅助诊断[4]系统中, 由于ANW的位置是实现虹膜图谱覆盖的主要依据, 所以卷缩轮边缘的准确检测也是判断计算机辅助诊断系统性能优劣的前提.
目前虹膜卷缩轮的提取方法主要包括: 石勇涛等[5]利用图像纹理元的灰度模式及统计特征完成虹膜图像的卷缩轮分割, 黄静等[6]利用纹理基元统计出纹理变化规律, 通过定义边界模式与非边界模式, 统计每种模式出现的频数, 最后通过频数的变化规律找到包含卷缩轮的窗口提取卷缩轮. 苑玮琦等[7]提出梯度极值法和辛国栋等[8]提出的最大灰度梯度法, 两种方法都是通过在图像中搜索最大灰度梯度来确定卷缩轮边界,利用水平和垂直方向梯度之和来提取卷缩轮. 马琳等[9]和辛国栋等[10]通过利用Snake方法提取虹膜卷缩轮,通过蛇点之间区域的平滑程度来确定内部函数, 根据区域边缘点的密度来确定外部能量函数来得到卷缩轮.但是上述提取方法在对卷缩轮图像进行提取的过程中易受光斑、眼睑、坑洞等因素的影响, 且提取虹膜卷缩轮需要手动定位初始位置, 对于卷缩轮在虹膜中位置分布过大或过小的图像和卷缩轮内部纹理不清晰的图片不能很好的进行定位, 导致卷缩轮的提取效果有时并不理想.
为了解决上述方法中卷缩轮检测结果抗干扰性差、内部纹理不清晰、检测精度不理想等问题, 本文提出一种基于遗传算法的虹膜卷缩轮提取方法, 通过特有的适应度选取和比较交叉选择机制提高优秀父本的选取, 进而提取出较理想的卷缩轮轮廓. 该算法无需利用窗口中心作为卷缩轮的轮廓点, 不容易受到附近坑洞或色素斑纹理的干扰, 对卷缩轮内部纹理不清晰的图像可以准确进行定位, 无需手动定位初始点, 所得到的卷缩轮边缘效果较好, 所提取出的卷缩轮结果较接近于实际的卷缩轮.
1 基于遗传算法的虹膜卷缩轮提取
1.1 虹膜预处理
由于人眼独特的结构特点, 虹膜提取易受到光照,采集角度, 环境等因素的影响, 为了纠正由此造成的弹性变形问题, 消除平移和旋转等对虹膜特征提取造成的影响, 需要对采集到的图像进行预处理操作, 包括虹膜定位和归一化. 具体提取过程如图1所示.

图1 图像预处理过程
本文首先采用文献[11]中的方法对虹膜进行内外边界的定位. 再利用文献[12]中的虹膜归一化方法将环状虹膜进行归一化处理, 归一化的目的是为了使处理的问题简单化, 将环状的虹膜归一化成W×H的矩形, 其中角度方向的采样数W=540, 半径方向的采样数H=150. 归一化后矩形图像的左上角坐标为(0, 0),右下角坐标(539, 149).
将得到的矩形图片进行图像的灰度变换, 把原图像的灰度值变换到新图像中. 原图像中灰度值低于最低亮度值的像素点, 该点在新图像中灰度值被赋值为最低亮度值, 同理, 原图像中灰度值高于最高亮度值的像素点, 该点变换到新图像时其灰度值也被赋值为最高亮度值, 将灰度图像中的亮度值映射到新图像中, 使得图像中的部分数据饱和至最低和最高亮度, 增加输出图像的对比度值. 对图像进行开运算去除孤立的小点、毛刺, 并对图像进行减法运算来降低噪声的影响,求得特征处理后图像e.
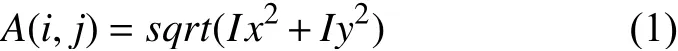
接下来对图像e采用式(1)求得梯度图像A(i,j),式(1)中特征处理后图像e的水平和竖直方向的梯度分别为Ix,Iy.平方根函数为sqrt.

梯度图像A(i, j)的均值X, 计算如式(2)所示, 式中M为图像的列数,N为图像的行数.

依据式(3)对梯度图像A(i,j)进行二值化处理. 二值化的目的是为了使图片结果更清晰, 可以直接通过点密度的方式进行遗传算法的适应度选取.
1.2 基于遗传算法的虹膜卷缩轮提取
遗传算法(Genetic Algorithm, GA)[13]是模拟达尔文的遗传选择和自然淘汰的生物进化过程的一种计算模型. 遗传算法把问题的参数用基因代表, 把问题的解用染色体代表, 从而得到一个由具有不同染色体的个体组成的群体. 具体提取过程如图2所示.

图2 遗传算法提取过程
本文在预处理得到的图片基础上, 通过使用遗传算法来进行卷缩轮的提取. 具体步骤如下: 首先利用随机算法来生成初始总群, 采取以区域内点密度之比作为适应度挑选出优秀个体进行比较, 将相邻两个体间同一位置基因进行比较, 将点适应度高的基因作为优质基因保持不变, 并在该点附近一定步长选取基因代替另一个体原有点适应度低的基因. 将得到的个体随机选择一定数量的变异点进行变异, 将新生成的个体作为新一代父本, 将上述步骤进行一定次数的循环, 直至找到符合要求的个体.
1.2.1 种群的选择和个体适应度函数的确定
种群的选择包括初始种群的选择和父本的选择,初始种群的选择利用随机算法来生成初始总群, 父本的选择由适应度函数[14]挑选出一定数量的优秀个体并通过选择算子(轮盘赌选择[15])选择最优个体作为新种群. 适应度值越大, 被选择成为优秀个体的几率就越大,通过个体适应度的大小可以确定该个体被选中的几率进而使结果趋近最优解. 常规适应度函数会直接通过采用待求函数进行选取, 本文则采取以区域内点密度之比作为适应度的方法, 结合卷缩轮的实际情况, 个体适应度函数定义如下:

其中, 个体适应度即上下区域的点密度之比用ratio表示, 如式(4)所示. 个体适应度的值越大, 则该个体被选择成为优秀个体的几率就越大. 上部分点密度为a, 如式(5)所示. 下部分点密度为b, 如式(6)所示. 其中, 每条染色体的基因个数为jiyin, 如式(7)所示, 其中, 染色体上相邻基因点间的间隔为len, 本文len=5.H为总半径方向的采样数, 经过多次实验结果对比得到当实际半径方向的采样数H1取总半径H的上2/3时所得结果准确率最高. 直线y上部分符合条件点个数为upwhite,直线y上部分整体点数用up表示, 直线y下部分符合条件点个数为downwhite, 直线y下部分整体点数用down表示.

已知相邻两基因点横坐标及纵坐标, 通过两点式求得直线y, 如式(8)所示. 其中, 染色体前一个基因的横坐标是x1, 如式(9)所示. 染色体后一个基因的横坐标是x2, 如式(10)所示. 基因的个数为j. 自变量和因变量分别为x和y, 第i条染色体上第j个基因的纵坐标为q(i,j), 第i条染色体上第j+1个基因的纵坐标为q(i,j+1). 通过直线y可得到相邻两基因点间横坐标和纵坐标的值.
1.2.2 选择算子的选取
选择操作是指利用选择算子从种群中选择优秀个体, 在交叉变异后遗传给下一代的一种选择机制, 也是遗传过程中使结果趋向最优解的重要一环. 本文通过使用轮盘赌选择来进行父本的选择, 对于种群X有X={x1,x2, …,xn},xi∈X的原有目标函数值为ratio(xi), 因为所得的染色体适应度相差不多, 因此用原有目标函数值减去最小目标函数值来提高选择精度, 如式(12)所示. 新目标函数值用ratio1(xi)表示, 最小目标函数值用minratio(xi)表示. 将所得新目标函数值ratio1(xi)和总新目标函数值比较, 得到p(xi)为选择xi染色体的概率, 如式(11)所示. 再选取一个小于1的随机数, 从随机点出发, 按顺时针方向依次累加, 当累加值刚好大于或等于随机数时输出, 则此个体为此次赌盘的赢家,以这种方式选择所有下一代的个体.

1.2.3 交叉和点适应度的选取
交叉[16]是遗传算法中生成优秀个体的主要手段,交叉机制的选择直接影响遗传算法的质量, 只有通过合理的交叉机制才能提高算法的搜索能力, 提高结果的准确性. 传统的遗传算法交叉模式是同代交叉即从父代种群中随机选择一部分个体进行交叉生成新种群,通过选择机制选取一定个体代替原有个体. 本文对传统遗传算法交叉模式进行了改进, 即将相邻两染色体间同一位置基因的点适应度进行比较. 返回该点的适应度用density表示, 如式(13)所示. 点适应度的值越大, 则该基因被选择成为优秀基因的几率就越大. 其中z为矩形内部一点纵坐标,c为上部分点密度, 如式(14)所示.d为下部分点密度, 如式(15)所示.upwhite为z上部分符合条件的点个数,up为z上部分整体点个数,downwhite为z下部分符合条件的点个数,down为z下部分整体的点个数.
如果第1条染色体上基因的点适应度高于第2条染色体上基因的点适应度, 则第1条染色体上该基因不变, 并在第1条染色体该基因附近一定距离选择两点进行比较, 将点适应度高的基因作为优质基因, 代替第2条染色体上原有点适应度低的基因. 点适应度选取如下:

具体交叉算法如下:
步骤1. 在种群X={x1,x2, …,xn}中选择个体xi和个体xi+1;
步骤2. 将个体xi和个体xi+1中相同位置基因j进行比较, 选取点适应度高的基因保留, 第i条染色体上第j个基因的点适应度用density(q(i,j))表示, 第i条染色体上第j个基因的纵坐标为q(i, j), 将两基因点进行点适应度比较, 将点适应度高的基因坐标用z1表示,并将点z1赋值给子代q子(i,j), 如式(16)所示:

步骤3. 在子代q子(i,j)附近距离一定步长的位置选取两点作为新的基因并进行比较(若步长超出范围则随机生成新基因), 将点适应度高的基因作为优质基因坐标, 用z2表示, 步长为d, 并将点z2赋值给子代q子(i+ 1,j), 如式(17)所示:

交叉流程如图3所示.
将个体xi和个体xi+1中相同位置基因j进行比较, 当点q父(i,j)的点适应度大于点q父(i+1,j)的点适应度时, 将点q父(i,j)赋值给q子(i,j), 并在点q子(i,j)基因附近距离一定步长(d=2)选取两点, 作为新的基因并进行比较. 其中, 当点q子(i,j)+d的点适应度大于点q子(i,j)-d的点适应度时, 如图3(a)所示. 将个体xi+1中基因j的值q父(i+1,j)替换为点q子(i,j)+d, 如图3(b)所示.

图3 基因交叉流程图
1.2.4 变异
变异是通过改变个体结构和特性而生成新个体的一种模拟生物进化过程中基因突变的现象. 当达到变异条件时, 个体将随机选择一定变异点进行变异形成新的个体, 是一种生成新个体的有效手段. 变异率通常设置较小值, 本文中变异率为0.01.
2 结果
实验所用图库是本研究室自己采集的可见光虹膜图库, 共1918张, 分辨率为800×600. 实验所用计算机处理器为Intel core i7, 内存为8 GB, 其主频2.60 GHz,开发工具为Matlab 2018a.
由实验可得, 步长越小, 则算法对ANW轮廓曲线的变化越不敏感;步长越大, 则算法就会忽略ANW的一些局部细节. 经过反复实验, 最终确定步长取3个像素时, 提取的ANW最接近于真实的ANW. 为了对本文的提取卷缩轮方法进行进一步测试, 选取了图库中一些具有代表性的非理想虹膜图像提取卷缩轮, 结果如图4所示. 由图可知: 针对具有不同干扰和不同特点的卷缩轮的虹膜图像, 本文的算法都可以提取出较理想的卷缩轮轮廓.

图4 本文算法提取各种非理想虹膜ANW结果
为了验证算法的有效性, 本文与snake模型、基元模式方法、梯度极值方法进行了实验效果对比, 结果如图5所示. 由图可知: 在非理想虹膜图像下, snake模型不能有效的体现卷缩轮的局部细节, 提取的卷缩轮平滑且需人工进行初始位置的确定. 基元模式统计的方法和梯度极值都容易受到卷缩轮附近光斑或色素斑等因素的影响, 所以提取出的卷缩轮结果不理想. 本文算法依据卷缩轮内部的纹理密度信息, 通过遗传算法可以很好地克服光斑及色素斑等干扰因素的影响, 由图片可得所提取出的卷缩轮结果较接近于实际的卷缩轮.

图5 不同ANW提取方法对比
3 结论
针对非理想可见光虹膜图像, 本文提出一种基于遗传算法的虹膜卷缩轮提取方法, 该算法可以有效地避免光斑等因素的影响, 无需手动定位初始点. 实验结果表明: 本文提出的方法具有较好的检测效果, 与其他提取ANW的算法相比提取出的ANW更接近于实际的ANW.
