多代表点的加权近邻分类算法①
2022-01-05林高思源
林高思源
(福建师范大学 计算机与网络空间安全学院, 福州 350117)
KNN算法是一种基本的分类方法, 在文本分类、人脸识别[1]、遥感图象识别等各个领域都有着广泛的应用, 特别是当大规模数据集各类别分布区域重叠较多时, 较其他算法有更优良的表现.如戚玉娇等[2]使用KNN算法对大兴安岭地区森林地上碳储量进行遥感估算; 宋飞扬等[3]提出一种空气质量预测模型, 通过结合KNN算法和LSTM模型, 有效提高模型的预测精度; 薛卫等[4]使用AdaBoost算法对KNN算法分类器进行集成, 用于蛋白质的亚细胞定位预测问题.
虽然KNN算法简便易懂, 但亦存在一些缺点.为克服这些缺点, 目前已经有很多学者提出改进的方法,如Guo等提出的KNN Model算法[5,6], 使用代表点集合来建立分类模型, 且能自动确定近邻数k的取值; 陈黎飞等[7]提出一种多代表点的学习算法MEC, 该算法基于结构化风险最小化理论[8]来进行理论分析, 且使用聚类算法生成代表点集合, 以此构建分类模型. 刘继宇[9]等提出一种基于普通粗糙集的加权KNN算法, 对现有的粗糙集值约简算法可能存在的问题进行改进.王邦军等[10]提出基于多协方差和李群结构的李-KNN分类算法, 该算法利用集成的思想, 充分利用各种统计特征的影响, 结合KNN算法和李群结构的优势. 刘发升等[11]提出一种基于变精度粗糙集的加权KNN文本分类算法(VRSW-KNN算法), 通过引入变精度粗糙集结合样本加权的方法来更有效的控制类别的分布区域, 从而有效提高分类的准确率, 然而比较依赖参数的取值.
根据以上研究现状, 本文提出一种基于多代表点的变精度粗糙集加权KNN算法, 并且使用该算法在文本分类领域进行应用. 本算法在VRSW-KNN算法的基础之上, 借鉴该算法的分类过程, 引入多代表点思想生成一系列代表点集合并使用聚类算法构建更加精确的分类模型, 使用结构化风险最小化理论进行理论层面的分析和进一步优化算法, 最终得出一个数目适宜的模型簇集合用于分类. 与VRSW-KNN算法相比, 本文算法不仅能更精确的划分各类别的分布区域, 更好的适应各种情况的数据集, 且能大幅降低分类的时间开销.
本文的组织结构如下: 第1节介绍本文的背景知识与相关工作; 第2节描述本文提出的算法, 并对部分影响因素进行理论层面分析; 第3节给出实验环境, 并对实验结果进行分析; 第4节总结全文, 同时给出未来可能的研究方向.
1 背景知识与相关工作
1.1 基于变精度粗糙集的加权KNN文本分类算法(VRSW-KNN)
Ziarko[12]于1993年利用相对错误分类率提出一种变精度粗糙集模型, 该模型利用精度β把原来经典粗糙集的上、下近似区域推广到任意精度水平, β∈[0,0.5), 使粗糙集的区域变得更加灵活.
由于数据集的类别分布并不一定均衡, 这导致普通KNN算法在判断类别时会更容易把训练集中占比较多的类别给予测试样本, 使分类精确度降低. 为更好的解决该问题, 该算法根据测试样本的K近邻样本分布特征使用式(1)对K个样本分别计算权重, 再使用式(2)计算测试样本向量与K个训练样本向量的相似度, 最后使用式(3)计算各类别最终权重, 并将该向量分配给最终权重最大的类别[11].
样本权重计算公式[11]:

式中,Num(Ci)为 K近邻中属于Ci的 文本数量;Avgnum(Cl)是指K近邻中类别的平均文本数.
相似度计算公式[11]:
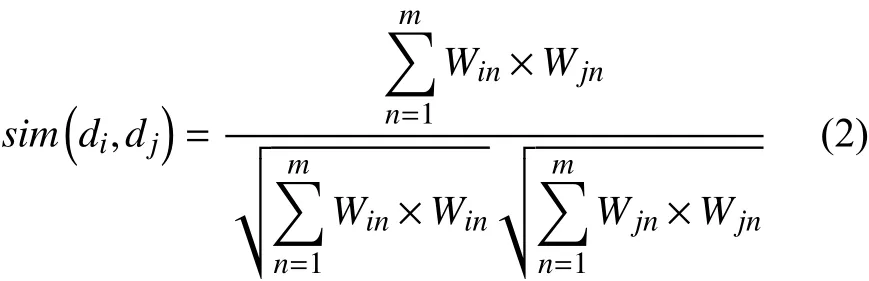
其中, 特征向量dj={Wi1,Wi2,···,Win}T, 而Win代表文件dj的第n维.
VRSW-KNN决策规则为[11]:

VRSW-KNN算法利用变精度粗糙集的上下近似区域来使每个类别都有一个以类别质心作为中心点的近似区域, 以此检测测试样本和各类别分布区域的相对位置. 同时结合文本数量加权的思想, 从而能够在文本分类问题上比普通的KNN算法表现更好. 其计算类Xi的上下近似半径的算法步骤如下[11,13]:
Begin
Step 1. 计算第i类的质心O(Xi).
Step 2. 计算类别中心O(Xi)与同类别样本的相似度, 则第i类别的上近似半径为相似度的最低值.
Step 3. 计算类别中心O(Xi)与训练集中全部样本的相似度, 如果样本相似度超过上近似半径, 则将其按照降序进入队列中.
End
算法中Num(n)表 示前n个样本中不属于类别Xi的样本数目.
VRSW-KNN算法总体步骤如下[11,13]:
Begin
Step 1. 数据预处理, 将文本数据转变为向量空间内的向量di={Wi1,Wi2,···,Win}T.
Step 2. 得出各类别近似半径.
Step 3. 根据式(2)得出测试样本与各类别的相似度, 确定测试样本在数据集整体中的相对位置.
Step 4. 分类阶段应首先得出该样本是否属于某类别的下近似半径范围内, 如成立则为该样本添加这一类别的类别标记, 且算法终止.
Step 5. 如测试样本与一些类别中心的相似度大于类别的上近似半径, 则在这些类别中先使用式(1)计算各类别的权重, 再使用式(3)进行最终决策.
Step 6. 如测试样本与所有类别中心的相似度都小于类别的上近似半径, 则在完整训练集中先使用式(1)计算各类别的权重, 再使用式(3)来进行最终决策.
End
2 多代表点的VRSW-KNN算法
多代表点的VRSW-KNN算法, 全称MVRSWKNN, 简称M-KNN, 该算法利用多代表点思想来让每个类别的代表区域变得更加细致, 从而通过增强分类模型的判断能力, 来解决VRSW-KNN算法在部分情况下表现失常的问题. 本节将先介绍模型簇的形式定义和总体分类模型, 根据结构风险理论[8]来确定算法的优化目标, 再给出算法的总体过程并对此进行分析.
2.1 分类模型
M-KNN算法构建分类模型是为能从给定数据集Tr={(x1,y1),(x2,y2),···,(xn,yn)} 中 得到被优化过的k个类别的模型簇集合 {C1,C2,···,Ck}, 其中的Ci指的是第i类的模型簇集合, 可看作Ci={pi1,pi2,···,pim}, 其中的pij是经过优化过的第i类模型簇集合的第j个模型簇,m为第i类的模型簇总数, 同时可把模型簇pij覆盖区域内的样本点集合称为Xij.
模型簇pij的 代表点是该模型簇范围内所有点的中心, 因此亦可称为中心点, 采用式(4)计算:

分类算法步骤如下:
输入: 模型簇集合 {C1,C2,···,Ck}, 待分类样本xα,参数t, 近邻数k.
输出: 样本数据xα的类别yα.
Begin
Step 1. 根据式(2)计算xα与各模型簇的中心点之间的相似度, 从而确定xα的位置.
Step 2. 首先判断xα是否属于某个模型簇的下近似区域, 如果属于, 则直接将xα归于该模型簇所属的类别,算法终止.
Step 3. 如样本属于某些模型簇的上近似区域, 则在这些模型簇的覆盖区域中选出与xα相似度最大的k个样本后使用式(3)得出xα的类别.
Step 4. 如果样本不属于所有类别的上近似区域,则在所有模型簇的覆盖区域中选出与xα相似度最大的k个样本后使用式(3)得出xα的类别.
End
2.2 结构风险
应用分类算法来对未分类样本进行分类可看作一个k-分类模型[7]的变型, 即:

和基于该分类模型的二类分类判断, 即:

其中,xα为待分类样本.
为提高模型的性能, 基于该文献所提到的k-分类模型来对本节的分类模型基于VC维理论[8]进行结构风险的分析, 可得应用本节算法的分类模型来进行分类亦是一个二类分类过程, 而二类分类模型期望风险的上界[8], 期望风险R(Mk)可表示为:

其中,hk表示Mk的VC维;VC_confidence(hk)表示VC置信度;Remp(Mk)表示经验风险, 为分类模型使用训练集时的平均误差. 而在本节算法中,Mk的经验风险为:

由此可得, 分类的性能与VC置信度和经验风险都密切相关. 其中VC置信度随|Mk|即模型簇数目的增加而出现单调递增的状态. 这点可由研究学习矢量量化(Learning Vector Quantization, LVQ)算法的VC维的文献[14]证明. 根据其定理1的结论可得LVQ的VC维是其“原型”数目的一个单调递增函数, 而本文算法所定义的模型簇可在文献[7]的基础上亦可看作一种LVQ“原型”的扩展. 因此根据VC置信度的定义[8],VC置信度是VC维的递增函数, 可得本文分类模型的VC置信度亦随|Mk|的增加而单调递增.
经验风险亦与|Mk|有关, 这点可从极端情况上观察得出, 当 |Mk|与类别数目相等时, 一个类别仅有一个簇,这种情况下, 多代表点思想就失去作用, 变为VRSWKNN算法, 经验风险在该情况下具有最大值; 而当|Mk|与样本点的数目相等的时候, 每个样本点都构成一个模型簇, 这种情况下, 经验风险降低到0. 结合这两种极端情况, 可以得出结论, 经验风险总体上随着模型簇数目的增加而呈减少趋势. 但并不表明减少的过程是单调递减, 这点从文献[7]中可以得到证明.
综上可得,R(Mk)的上限由VC置信度和经验风险共同决定, 而这两个因素又都与|Mk|值有关, 因此模型训练算法的目的便是得出一个适合的 |Mk|值来尽量使得分类模型的期望风险达到较低值.
模型训练算法:
输入: 训练集Tr, 参数β, 分类模型类别标号k(k=1,2,···,K).
输出: 分类模型Mk.
Begin
Step 1. 构造初始分类模型Mk={pk1}, 设X0={Tr中类别标号为k的样本}, 根据类别标号为k的样本计算出初始模型簇的上下近似区域和中心点, 从而得出pk1的各个值.
Step 2. 计算初始模型的Remp(Mk).
Step 3. 如果Remp(Mk)=0 或者|Mk|等于数据点的个数, 返回Mk, 算法终止.
Step 4. 使用K-means聚类算法[15]对Xl中的样本进行聚类, 划分成|Mk|+1个 集合X1,X2,···,X|Mk|+1.
Step 5. 构造新分类模型Mk′={pki|i=1,2,···,|Mk|+1}并 构造其中的新模型簇
Step 6. 使用式(6)计算Mk′的 经验风险Remp(Mk′).如果Remp(Mk′)≥Remp(Mk), 返回Mk, 算法结束. 否则,Mk=Mk′, 重复Step 3至Step 5.
End
对于每个类别, 训练算法的过程是从1开始, 逐个递增模型簇数目, 直到经验风险Remp(Mk)达到一个局部极小值或为0后, 停止递增并记录目前的该类别模型簇状况. 根据文献[7]提供的策略, 这里的局部极小值指的是第一个经验风险极小值, 这样可以在降低训练阶段耗时的同时, 使VC置信度和经验风险达到一种平衡. 本节算法亦沿用该策略. 最终, 对于每个类别,都有一至多个模型簇表示该类别的分布情况, 从而比VRSW-KNN算法更擅于对样本进行精准分类.
3 实验与分析
实验选择KNN、VRSW-KNN, 这两种基于最近邻思想的分类器作为比对的对象. 实验设备为: CPU为CORE i7-8750H2.20 GHz, 16 GB RAM, Windows 10操作系统的计算机.
3.1 实验数据
实验数据使用复旦大学原计算机信息与技术系国际数据库中心自然语言处理小组的中文语料库[11]中的2400篇作为数据集, 包括艺术, 历史, 计算机, 环境,体育, 农业等共8个类别.
其中的1600篇作为训练样本, 800篇作为测试样本. 在正式实验前, 对数据集进行分词, 去停用词, 特征提取后再使用TF-IDF特征词加权方式将所有文本变为特征向量.
3.2 实验结果与分析
实验的分类性能评价指标采用Micro-F1指标来衡量分类器的分类精度, 同时对3种算法所使用的训练集和测试集均一致, 且实验结果为多次运行后的平均值, 以避免随机因素导致的影响.
本实验中表1为固定t=1.0,k=10, 粗糙集精度β的取值分别为0.05、0.10、0.15时3种算法的F1值, 由于参数t与耗时无关, 因此表2为仅β取不同值时3种算法的耗时对比.

表1 β取不同值时3种算法的Micro-F1值对比

表2 β取不同值时3种算法的耗时对比
由表1可知, 当粗糙集精度β从0.05逐渐增加到0.15时, 对于VRSW-KNN算法, 模型簇的下近似区域覆盖范围逐渐变大, 导致在分类时模型簇的F1值逐渐降低. 但对于M-KNN算法, 虽下近似区域覆盖范围发生相同变化, 但由于在训练模型时, 每个类别分布区域由多个模型簇组成, 导致虽粗糙集精度β发生较大变化, 但对各类别的覆盖区域影响较小, 不会导致F1值的大幅降低. 因此可知使用多代表点思想后, 生成的模型簇的表现与VRSW-KNN算法相比不仅准确率略有上升, 且在参数的选取上更加容易接近较优良的结果.
由表2可知, 普通的KNN算法耗时最长, M-KNN算法在耗时上较VRSW-KNN算法大幅缩短. 原因是虽然VRSW-KNN算法使用变精度粗糙集的思想, 然而只简单的设定一个类别只有一个簇, 导致并没有充分的利用该分类模型, 其分类时间随着样本数的增加而急剧增长. 很多数据点仍需要多个类别甚至全部类别的模型簇内样本寻找K近邻, 但M-KNN算法结合多代表点的思想, 将每个类别分布区域划分成多个模型簇, 虽然导致训练分类模型的时长大幅增加, 但在分类阶段则获得各类别更精确的分布区域, 让很多数据点能够在分类算法的前两步就获得较准确的标记, 从而大幅降低数据分类的耗时, 导致在本节算法中, 大部分耗时是训练分类模型的耗时. 因此, 在更大规模的文本数据集中, 本节算法的分类性能会远好于VRSWKNN算法和普通的KNN算法.
综上所述, 本文算法能更加有效的提升分类的效率和准确率.
4 结束语
本文提出一种较高效的基于多代表点思想的变精度粗糙集加权KNN算法, 并使用该算法在文本分类领域中进行实验. 实验结果不仅成功验证期望风险的理论分析的正确性, 更表明该算法的实际可行性, 进一步解决VRSW-KNN算法在刻画各个类别分布情况的不足, 从而在大幅降低时间开销的同时提高分类的准确率. 下一步的工作重点是围绕训练模型的各个影响因素, 探索在保证分类准确率且能降低训练期间时间开销的相关方法.
