基于Transformer的改进短文本匹配模型①
2022-01-05蔡林杰
蔡林杰, 刘 新, 刘 龙, 唐 朝
(湘潭大学 计算机学院·网络空间安全学院, 湘潭 411105)
短文本匹配[1]是自然语言处理(NLP)领域中一项被广泛使用的核心技术, 它旨在分析和判断两个文本之间的语义关系, 广泛应用于信息检索[2]、问答系统[3]、复述识别[4]和自然语言推理[5]等任务. 在信息检索问题中, 用户想找到和给定查询相关的文档. 对于搜索引擎来说, 如何对给定的查询匹配到合适的文档是至关重要的. 文本匹配还能被用来在问答系统中为问题匹配到合适的答案, 这对自动客服机器人非常有帮助, 可以大大降低人工成本. 复述识别用于识别两个自然问句是否语义一致, 而自然语言推理主要关注的问题是能否由前提文本推断出假设文本. 因此, 对短文本匹配的研究有重大意义.
传统的文本匹配算法主要解决词汇层面的匹配问题, 存在着词义局限、结构局限和知识局限等问题. 随着科学技术的飞速发展和深度学习的不断壮大, 深度神经网络模型在自然语言处理领域取得了巨大进展,使用深度神经网络表示文本、学习文本之间的交互模式使得模型能够挖掘出文本之间复杂的语义关系, 关于短文本匹配问题的研究已经逐渐从传统的基于统计的方法转移到深度语义短文本匹配模型. 近年来提出的Word2Vec[6]、GloVe[7]、ELMO[8]、BERT[9]、XLNet[10]等预训练模型很好地解决了文本向量化表示的问题.
目前大多数短文本匹配模型在提取文本特征时只考虑文本内部信息, 忽略了两个文本之间的交互信息,或者仅进行单层次交互, 丧失了文本间丰富的多层次交互信息. 为解决上述问题, 本文提出一种基于Transformer[11]改进的短文本匹配模型ISTM. ISTM模型以DSSM[12]为基本架构, 利用BERT模型对文本进行向量化表示, 解决Word2Vec一词多义的问题, 使用Transformer编码器对文本进行特征提取, 获取文本内部信息, 并考虑两个文本之间的多层次交互信息, 分别得到两个文本最终的语义表示, 经过最大池化后进行拼接操作再通过全连接神经网络分类输出两个文本之间的语义匹配度. 实验表明, 相比经典深度短文本匹配模型, 本文提出的ISTM模型在LCQMC[13]中文数据集上表现出了更好的效果, 证明了该模型的有效性和可行性.
1 背景技术
DSSM是一个非常出名的文本匹配模型, 它首先被应用于Web搜索应用中匹配查询(query)和相关文档(documents). DSSM使用神经网络将查询和文档表示为向量, 两向量之间的距离被视为它们的匹配得分.
Transformer模型于2017年由Google提出, 主要用于自然语言处理领域, 有一个完整的Encoder-Decoder框架, 其主要由注意力(attention)[14-16]机制构成. 其中,每个编码器均由自注意力机制和前馈神经网络两个主要子层组成. Transformer旨在处理顺序数据(例如自然语言), 但不需要按顺序处理顺序数据, 与循环神经网络(RNN)[17]相比, Transformer允许更多的并行化,因此减少了训练时间, 可以对更大的数据集进行训练.自问世以来, Transformer已成为解决NLP中许多问题的首选模型, 取代了旧的循环神经网络模型.
2018年Google 提出了BERT模型, BERT模型主要利用了Transformer的双向编码器结构, 采用的是最原始的Transformer. 与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示, 能够解决一词多义的问题.
2 改进的短文本匹配模型ISTM
现有的短文本匹配方法大多只考虑文本自身的内部信息, 忽略了两个文本之间的交互信息, 或者仅在提取文本特征之后才进行一次交互, 只能获取单层次交互信息, 而丧失了多层次交互信息. 为此, 本文提出了基于Transformer改进的短文本匹配模型ISTM, 该模型以DSSM为基本架构, 利用BERT模型实现文本向量化表示, 将Transformer编码器作为一个特征提取器,同时借助Transformer的多层编码器使得两个文本进行多层次交互, 进而获取多层次交互信息, 最终分别得到两个文本的语义表示, 其中Transformer编码器个数即为文本交互次数. 两个文本的语义表示进入预测层,分别进行最大池化, 而后得到的拼接向量进入全连接层, 最终通过分类器LogSoftmax输出匹配结果. ISTM模型架构如图1所示, 其中N为编码器数量.

图1 ISTM模型架构图
2.1 Transformer编码器
Transformer 编码器有两个子层, 分别是多头自注意力层和前馈神经网络层, 同时每个子层的周围都有一个求和与层归一化[18]步骤, 其结构如图2所示, 其中N为编码器数量.

图2 Transformer编码器结构图
输入矩阵X的维度为S×E, 其中S为最大序列长度,E为嵌入向量的维数, 本文中S为25,E为768.Transformer 编码器的计算过程如下:
(1) 自注意力机制通过输入矩阵X和权重矩阵WQ,WK,WV分别计算查询矩阵Q, 键矩阵K和值矩阵V.

(2) 计算自注意力层的输出矩阵Z, 其中dk为键向量的维数.

(3) 计算多头自注意力层的输出矩阵Zmul, 其中H为注意力头数,Zi表示第(i+1)个注意力头,Concat函数表示将所有的H个注意力头拼接起来,WO为附加的权重矩阵,Zmul的维度与X相同.
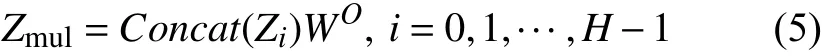
(4) 进行求和与层归一化, 其中LN函数表示层归一化.

(5) 将Zmul传递到前馈神经网络, 之后再次进行求和与层归一化.
2.2 文本向量化表示
文本向量化表示是自然语言处理任务中的一个重要过程. Word2Vec是自然语言处理中最早的预训练模型之一, 过去的工作大多采用Word2Vec实现文本的向量化表示. Word2Vec的优点是简单、速度快、通用性强, 但它受限于语料库, 产生的词表示是静态的, 无法解决一词多义的问题, 它的建模较为简单, 不能体现词的多层特性, 包括语法、语义等.
本文采用BERT模型来处理文本的向量化表示,BERT模型相比以Word2Vec为代表的词嵌入方法, 一个比较突出的进步就是更加动态, 能够解决一词多义的问题. 此外, BERT基于Transformer, 利用了Transformer的双向编码器结构, 能够体现词的多层特性. 本文使用BERT-BASE中文模型, 该模型有12个Transformer Encoder, 每个Transformer Encoder有12个注意力头,隐藏层维数为768. BERT模型实现文本向量化的过程如图3所示.

图3 BERT文本向量化
2.3 交互注意力层
假设文本1的矩阵表示为AS×E, 文本2的矩阵表示为BS×E, MP函数表示最大池化操作, 则两个文本的交互注意力矩阵MS×S的计算如下:

对M的每一行进行最大池化操作, 得到向量rS, 表示B对A中每个字符的注意力权重,rS中的每个元素乘以A中的每一行即可得到交互后的A:

对M的每一列进行最大池化操作, 得到向量cS,表示A对B中每个字符的注意力权重,cS中的每个元素乘以B中的每一行即可得到交互后的B:

如此, 两个文本进行了一次信息交互. 两个文本依据编码器数量可进行多层次信息交互, 获得丰富的上下文信息和交互信息.
2.4 预测层
假设经过编码组件后两个文本的矩阵表示分别为AS×E和BS×E, 将A和B进行最大池化后分别得到两个文本的向量表示v1和v2, 则两个文本的匹配结果的计算如下:

其中,y′表示两个文本的匹配结果的预测值,v1◦v2表示v1和v2对应元素逐个相乘, 强调两个文本之间相同之处, 而|v1-v2|强调两个文本之间不同之处,F函数表示将这4个向量的拼接向量输入到全连接神经网络后再经过LogSoftmax分类器处理输出匹配结果的预测值.
3 实验与分析
3.1 数据集和模型参数
LCQMC数据集由哈工大(深圳)智能计算研究中心提供, 包含来自多个领域的260 068个中文问句对, 相同询问意图的句子对标记为1, 否则为0, 并预先将其切分为了训练集(238 766对)、验证集(8802对)和测试集(12 500对), 其中同义对和非同义对的比例接近1:1.
本次实验设置的主要模型参数如表1所示.

表1 模型参数设置表
3.2 评估指标
本文的ISTM模型所应用的短文本匹配属于二分类范畴, 我们采用F1值和准确率Acc作为评估模型效果的指标, 以F1值为主, 以准确率为辅.F1值由精确率P和召回率R得到, 相关的计算公式如下:

3.3 模型对比实验
为了验证本文模型效果, 基于同一数据集, 选取多个经典的文本匹配模型进行实验对比.
LSTM-DSSM[19]: 针对DSSM不能够很好地捕捉上下文信息的问题, Palangi等提出使用LSTM替换DSSM的深度神经网络, 以捕捉到文本的上下文信息.
Transformer-DSSM[20]: 为了更强的并行计算能力和更好的特征提取能力, 赵梦凡提出使用Transformer编码组件替换DSSM的深度神经网络.
为了增强对比效果, 本文还类似地加入了RNNDSSM、BiRNN-DSSM、GRU-DSSM、BiGRUDSSM和BiLSTM-DSSM作为对比实验. 各模型的实验对比结果如表2所示, 其中模型采用的文本向量化方式默认为BERT, 否则为Word2Vec.

表2 模型对比实验结果
从实验结果可以看出, 本文提出的ISTM模型的F1值可达到86.8%, 准确率可达到86.3%, 优于其他模型. 由实验6和实验7可知, BERT的表现比Word2Vec更加优秀, 以至于实验1至实验5所代表的其他RNN模型的F1值和准确率都大幅领先于实验7. 由实验1至实验8可知, Transformer编码器相对于RNN拥有更好的特征提取能力. 由实验8和实验9可知, ISTM模型的多层次信息交互确实提升了短文本匹配的效果,主要体现在F1值和准确率的提升. ISTM模型取得更好的匹配效果, 其原因在于:
(1)使用BERT模型进行文本向量化, 能够解决一词多义的问题;
(2) Transformer编码器拥有更为优秀的特征提取能力;
(3)多层次信息交互使得两个文本都获得丰富的交互信息, 这对短文本匹配效果有着较好的提升.
4 结束语
针对短文本匹配问题, 本文提出了一种基于Transformer改进的短文本匹配模型ISTM, 该模型利用BERT实现文本向量化表示, 在DSSM模型架构的基础上引入Transformer编码器作为特征提取器, 并增加交互注意力层, 使得模型自身拥有获取多层次交互信息的能力. 从对比实验结果来看, 本文提出的ISTM模型能够有效提升短文本匹配的效果.
