一种基于变分推断的雷达多目标跟踪JPDA算法*
2022-01-04郑丹阳王东峰
郑丹阳,曹 林,王 涛,王东峰,2
(1.北京信息科技大学 信息与通信工程学院,北京100101;2.北京川速微波科技有限公司,北京 100080)
0 引 言
在雷达多目标跟踪尤其是邻近多目标的跟踪中,数据关联是一种必不可少的关键技术,它包括确定出实时接收量测与目标之间正确的对应关系。联合概率数据关联(Joint Probability Data Association,JPDA)技术作为一种经典算法,在目标数量较少以及杂波分布函数已知的情况下,能够产生良好的关联跟踪效果。但是,在实际复杂检测场景下,随着目标数量的增加,算法对应产生的确认矩阵数量激增,甚至出现指数爆炸现象。针对传统JPDA算法存在的不足,文献[1]提出了一种简化联合概率数据算法,根据目标航迹和量测之间的关联规则,引入公共量测影响因子修正关联概率,避开拆分确认矩阵,从根本上解决了组合爆炸问题。针对单传感器联合概率数据互联算法在密集多目标场景中难以跟踪所有目标的问题,文献[2]提出一种基于JPDA量测目标互联概率统计加权并行式和序贯式多传感器数据融合方法,在数据集PETS上对行人取得了较理想的跟踪效果。文献[3]提出了一种JPDA的修正版本——Set JPDA算法,用考虑目标位置来替代对于目标来源的确认。通过结合单目标和多目标跟踪算法,文献[4]提出了一种k近邻联合概率数据关联(k Nearest Neighbor Joint Probability Data Association,kNN-JPDA)算法,实现了kNN和JPDA的优化组合。文献[5]将KL散度(Kullback-Leibler Divergence,KLD)作为代价函数来优化关联事件的后验概率密度函数,解决了杂波环境下的多目标跟踪问题。针对目标跟踪中的多扩展目标跟踪问题,文献[6]对扩展目标进行泊松点过程(Poisson Point Process,PPP)量测建模,提出了一种“多对一”JPDA关联模型。
数据关联算法需要解决的核心问题是计算目标与航迹之间的边缘关联概率,通过寻找到最大后验的联合事件实现目标-量测关联。文献[7-9]第一次将变分推断与数据关联算法结合起来,通过置信传播求解最大后验关联事件,解决了分布式无线传感器网络的目标跟踪问题。作为其中的关键环节,概率图模型通过不同层级的叶子节点来分解表示不同变量之间的概率联系,为变分推断提供了一种框架[10]。
在密集多目标跟踪中,随着密集多目标不断接近,各目标之间相关波门的重叠度增大,拆分确认矩阵的数量指数级增长。经典JPDA中包含两个重要的关联指标:量测关联指标和目标关联指标。为解决拆分确认矩阵数量呈指数级增长的问题,本文引入概率图模型来分解表示关联指标之间的全部假设关联关系,并在此模型上基于变分推断求解最大后验关联事件[11]。
1 联合概率数据关联算法
联合概率数据关联的目的是计算出每一个量测与其所有可能的源目标之间的关联概率,当存在量测落入多个目标的相关波门的重叠区域内时,如图1所示,就需要综合考虑各个目标的来源情况[12]。
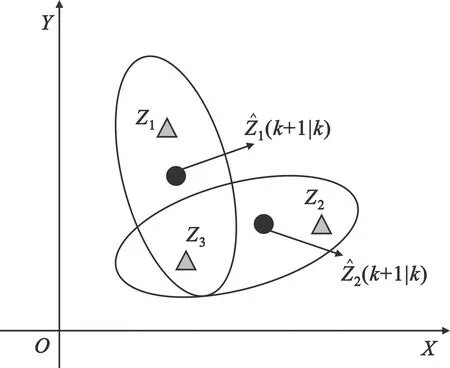
图1 确认矩阵与互联事件形成示意图
设θjt(k)表示量测j来源于目标t(0≤t≤T)的事件,而θj0(k)则表示量测j来源于杂波或虚警。另外,这里需要引入两个二元变量量测互联指示τj和目标检测指示δt:
(1)
表示量测j在联合事件θi(k)中是否和一个真实目标互联,ωjt为一个二进制变量;
(2)
表示任一量测在联合事件θi(k)中是否与目标t互联(目标t是否被检测到)。
设nt[θi(k)]表示在联合事件θi(k)中虚假量测的数量,则
(3)
应用贝叶斯法则,则k时刻联合事件θi(k)的条件概率为
P{θi(k)|Z(k)}=P{θi(k)|Z(k),Z(k-1)}=
(4)
如果θi(k)被确定,那么目标检测指示δt(θi(k))和虚假量测数量nt[θi(k)]也就会确定下来。于是,
P{θi(k)}=P{θi(k),δt[θi(k)],nt[θi(k)]}。
(5)
应用乘法定理,则上式可以表示为
P{θi(k)}=P{θi(k)|δt[θi(k)],nt[θi(k)]}·
P{δt(k),nt[θi(k)]}。
(6)

P{θi(k)|δt(θi(k)),nt[θi(k)]}=
(7)
另外,
P{δt(θi(k)),nt[θi(k)]}=
(8)

(9)

p{Z(k)|θi(k),Z(k-1)}=
(10)
由此可得联合事件θi(k)的后验概率为

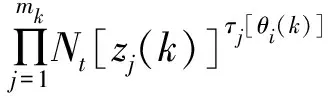
(11)
注意,根据概率函数μF(nt[θi(k)])使用的模型不同,对应的JPDA也有两种不同形式:参数JPDA,μF(nt[θi(k)])服从泊松分布;非参数JPDA,μF(nt[θi(k)])服从均匀分布。
拆分确认矩阵列举出量测与目标之间的所有可行联合事件是JPDA的主要优势,在目标和回波数量适中的情况下,JPDA算法通过计算所有可行联合事件的后验概率,能够达到较高的跟踪精度。然而在回波数量增多的情况下,对应于拆分确认矩阵的可行联合事件数量会出现指数爆炸现象,优势又成为严重影响跟踪实时性的阻碍。接下来,基于拆分确认矩阵的思想引入概率图模型来解决这一问题。
2 基于变分推断的JPDA算法
2.1 概率图模型
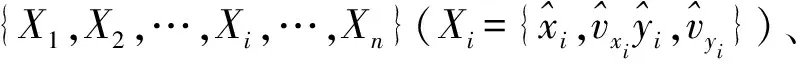
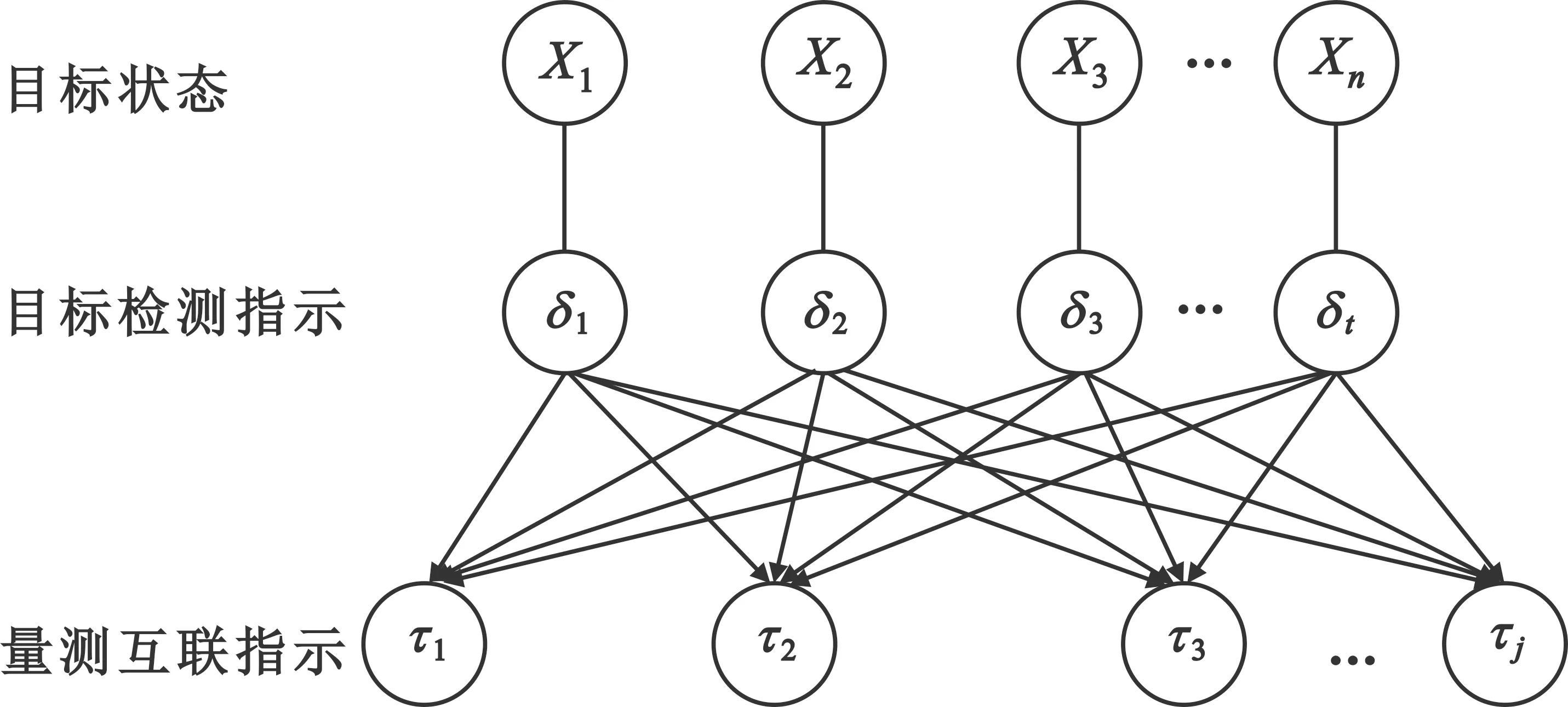
图2 单扫描时刻的概率图模型
在这种树形图中,置信传播是一种进行推断的消息传递算法。其主要思想是,对于马尔科夫随机场中的每一个节点,通过消息传播,把该节点的概率分布状态传递给相邻的节点,从而影响相邻节点的概率分布状态,经过一定次数的迭代,每个节点的概率分布将收敛于一个稳态。在置信传播算法中有两个概念:消息和置信度。
接下来采用置信算法进行优化推断,该算法通过传递相邻节点之间的信息递归计算关联概率。首先定义μt→j(τj)来表示顶点t∈V到顶点j∈V之间传递的信息,并且(t,j)∈e。置信更新方程为
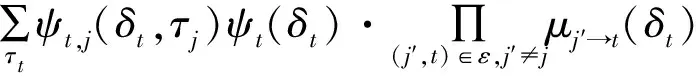
(12)
式(12)也被称为和积算法。当BP算法收敛时,单次扫描中假设每个目标之间独立分布,则任一顶点v的边缘分布为
(13)
接下来,假设在每个扫描时刻,各目标的状态相互独立,同时定义在单次扫描时刻接收的量测为Z={z1,z2,…,zmt}。因此在单扫描周期内,X的先验分布和量测与关联变量之间的联合概率分布分别为
(14)
(15)
(16)
式(15)中:λfa(zi)表示误警率。
后验概率分布为
(17)
p(X,δ,τ|Z)∝
(18)
式中:
(19)
(20)
利用高斯拟合来计算每个目标的边缘分布pi(xi),用这些近似边缘分布的乘积来近似联合分布。
2.2 基于变分推断数据关联
贝叶斯近似是一种用来计算Z(G)的创新方法,Z(G)是一个关于G的配分函数,也是关于G的最小优化解。在本文中,单扫描时刻的变分问题通过优化下面的目标函数来求解:
(21)

0≤qt,j≤1。
(22)
式中:qt,j=q(δt=j)=q(τj=t)是目标t与量测j相关关联的置信。如果j=0,则表示目标t漏检;如果t=0,量测j是误警。公式(22)称为一致性约束,是用来求解有效联合事件的必要条件。文献[15]已经证明了该函数满足凸优化,即该目标函数在约束条件下能够收敛到最优值。

FB(qt(δt),qi,t(xi,δt),qt,j(δt,τj))=
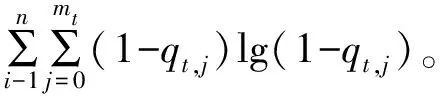
(23)
其约束条件为
qi,t(xi,δt)≥0,qo,j≥0 ,
(24)
(25)
(26)
(27)
(28)
令qt(δt)和qt,j(δt,τj)固定且可解,则公式(23)的解为
(29)
以上就是本文所提算法,该算法试图估计目标状态的边缘分布。当单独考虑每个目标的时候,该算法能够提供出完整的假设信息,例如在确定目标所在位置的置信区域时。在某些跟踪问题中,JPDA算法存在一些特定类型的跟踪不确定性,比如目标临近时出现航迹合并现象。在这种情况下,对于边缘关联分布的估计会给出多种可能组合,这是对各种不确定性的正确归纳。另外,概率图模型中清楚地展示了目标-量测关联假设存在的冗余性,正是这种冗余性确保每个量测至多对应一个目标,而每个目标至多对应一个量测。
2.3 算法流程
Step1 获取观测数据。在接收到雷达的回波信号之后,通过雷达采集的目标数据进行预处理,将处理后的目标数据保存为观测数据。
Step2 对观测数据进行预滤波和聚类处理。本文通过设定速度阈值来进行部分障碍物滤波处理,然后再对多目标观测数据进行聚类分析。
Step3 根据量测数据以及目标的状态建立对应的概率图模型。
Step4 建立公式(23)所示的目标函数。
Step5 通过假定qt(δt)和qt,j(δt,τj)均服从高斯分布来固定qt(δt)和qt,j(δt,τj),则FB是关于qt,j(xi,τj)的函数。
Step6 初始化原始问题的可行解yi,j以及非可行解xi,j(这里yi,j=0,xi,j=0):
xi,j=(ω0,jy0,j+∑i′ωi′,jyi′,j)-(1-γ)×
(ω0,jy0,j+∑i′≠iωi′,jyi′,j)-γ×ek∀i,j,
yi,j=(ωi,0xi,0+∑j′ωi,j′xi,j′)-(1-γ)×
(ωi,0xi,0+∑j′≠jωi,j′xi,j′)-γ×ek∀i,j。
Step7 因该算法对初值的选择不敏感,所以在约束条件(24)~(28)的范围内,线性迭代增加yi,j的值,并始终保持yi,j的可行性;同时增加xi,j的值,直到其成为原问题的可行解。
Step8 循环终止条件:当yi,j改变非常微小时,循环终止,输出结果qi,j=ωi,jyi,jx0,j∀i,j;否则,继续执行Step 7。
Step9 根据Step 8的输出结果qi,j确定出各目标与量测之间的关联概率,滤除与各目标之间关联概率极小的杂波信息,并根据已关联量测更新目标状态,进入下一个扫描时刻。
3 实验结果
本文实验场地为一个长5 m、宽6 m的室内环境,如图3所示,测试数据来自于毫米波雷达,雷达型号为CSR-EC-10近场高精度行为检测雷达,FMCW体制,中心频率77 GHz,距离分辨率10 cm,扫描周期200 ms,扫描范围水平视场角150°。

图3 真实实验场景
3.1 实验1
在检测场景中包含两个目标,两个目标在监测范围内自由行走,并逐渐接近。图4中显示了这两个目标的真实运动轨迹、JPDA、文献[4]以及本文所提算法的关联轨迹。从图中能够直观地发现,这三种算法中,经典JPDA的关联效果最差。图5中展示了这三种算法的关联位置误差(Position Error, PE),其中本文所提算法具备更小的PE值,文献[4]次之,JPDA的PE值最大。

图4 两个目标的数据关联结果

图5 三种算法下两个目标的位置误差比较
另外,在图6中三种算法的累积分布函数(Cumulative Distribution Function,CDF)结果表明,对目标A和B来说,本文所提算法将近60%的PE值在20~25.81 cm之间,同时60%的PE优于另外两种算法,这表明了本文所提算法在同样跟踪场景中具备更高的跟踪精度。

图6 三种算法关于两个目标的CDF结果
3.2 实验2
检测场景中包含3个目标,这3个目标在检测范围内自由行走,在整个运动过程中,至少两个目标逐渐接近并从相遇到分离。相比实验1而言,目标数量增加,对应的跟踪复杂度有所增加,实际关联跟踪结果如图7所示。通过实验能够发现,当两个目标距离逐渐邻近并相遇时,JPDA算法对应产生的可能关联事件个数逐渐增加,伴随出现连续多帧的关联错误,而文献[4]和本文所提算法未出现类似情况。同样地,这三种算法的PE值均显示于图8中。图8中的结果同样也表明,JPDA关联结果比起另外两种算法存在短暂的波动。通过对比,本文所提算法具备较小的PE值,表明其具备更高的定位精度。

图7 三种算法下三个目标的数据关联结果

图8 三种算法下三个目标的位置误差比较
图9中展示了实验2中三种算法的CDF结果。从单个目标来看,本文算法产生的位置关联误差中接近58%的PE小于另外两种算法。从整体角度看,本文算法依然比其他两种算法具备更低的PE值,进一步证明本文算法在跟踪精度上的优越性。作为JPDA算法的一种改进,本文算法在原有算法的基础上提升了跟踪精度,同时避免了拆分确认矩阵。
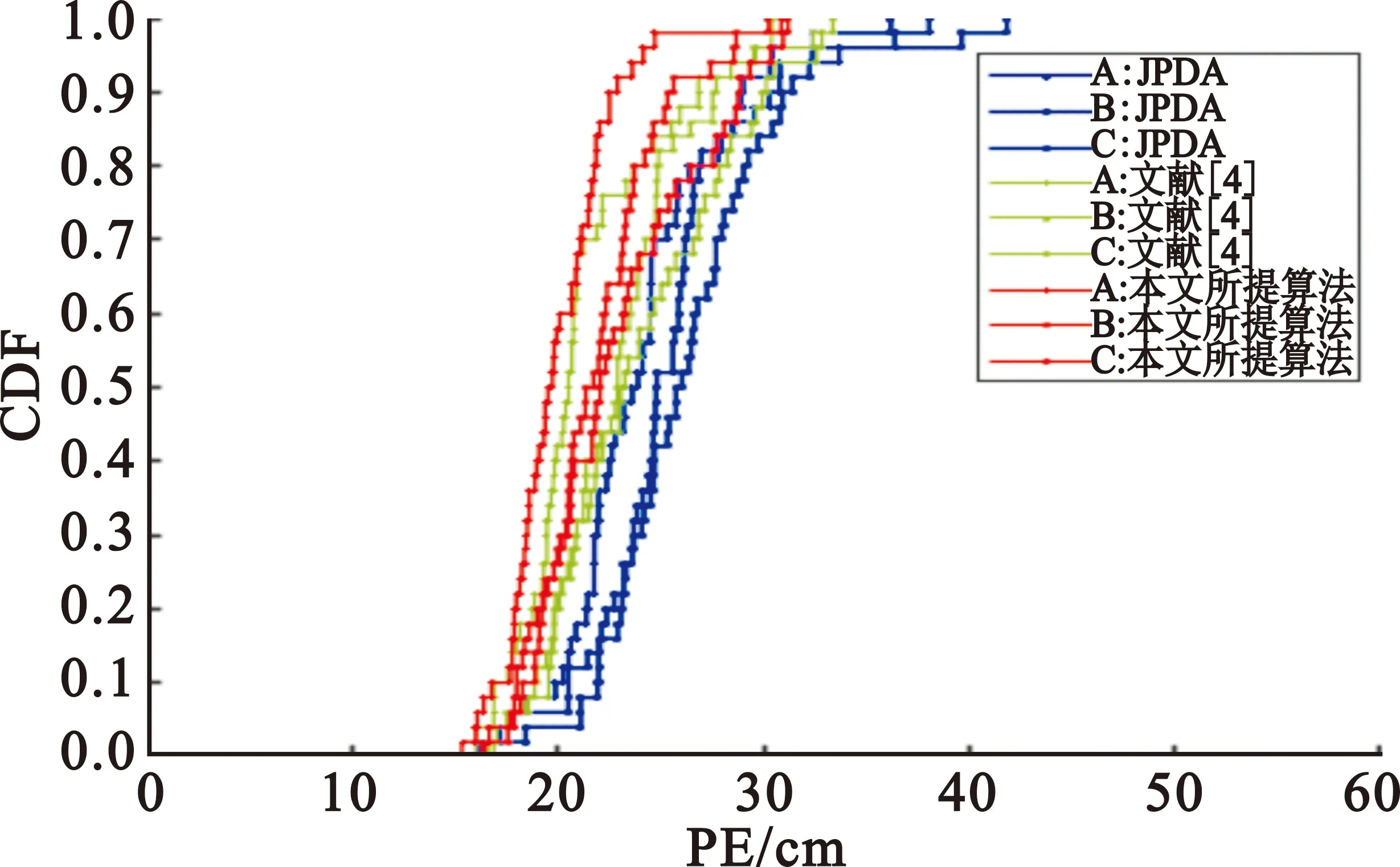
图9 三种算法下三个目标的数据关联结果
3.3 跟踪性能
表1综合分析了三种算法在上述两个跟踪场景中的跟踪性能,同时在计算平均PE的基础上计算了两个实验中三种算法的平均耗时。结果表明,本文算法较JPDA的PE分别平均提升了11.05%和14.51%,而较文献[4]的算法,跟踪性能分别提升了8.84%和5.23%。由此说明,本文算法所迭代计算的目标-量测边缘关联概率具备更高的关联置信。相比JPDA算法,本文算法避免了拆分确认矩阵来产生可能关联事件这一步骤,通过将目标和量测两个关联指标引入概率图模型中,迭代计算出最高置信的关联概率。这种方法保证了在多目标邻近时,算法能够避免多帧关联错误的现象。
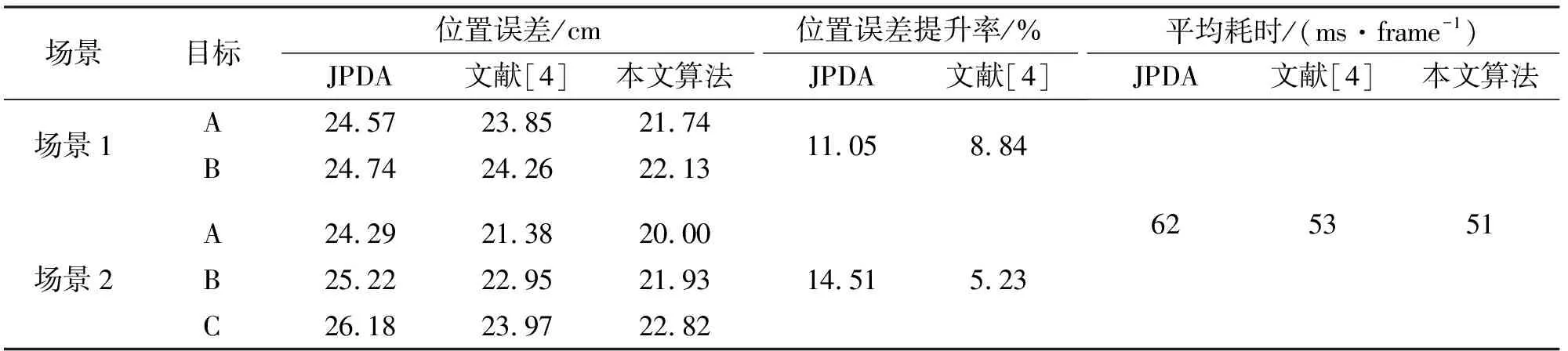
表1 关联算法性能比较
另外在表1中,本文算法的平均耗时较JPDA算法有所提升,且与文献[4]算法耗时接近。结果同样表明,本文算法能够在一定时间内迭代收敛到一个最优边缘关联概率,有效避免了因关联事件个数激增而引起的指数爆炸现象。此外,本文算法在列举目标-量测关联假设时存在冗余性,正是这种关联冗余性在保证关联假设无漏缺的同时又能避免拆分确认矩阵。
4 结束语
由于经典JPDA算法在密集多目标跟踪中会出现确认事件呈指数级增长的现象,本文提出了一种基于变分推断的JPDA算法,通过将目标关联指示和量测关联指示引入概率图模型中,避免了拆分确认矩阵。通过将该算法应用在两个雷达室内目标跟踪场景中,并与JPDA和文献[4]中的算法进行对比,结果表明本文算法的跟踪目标位置误差最小,具备更高的关联精度。在后续的研究中,将继续改进本算法以适应更加复杂的雷达多目标跟踪场景。
