CRYSTAL-KYBER硬件设计优化空间探索
2022-01-04穆嘉楠赵艺璇宋金峰李华伟李晓维
穆嘉楠, 赵艺璇, 严 寒, 宋金峰, 叶 靖, 李华伟, 李晓维
1中国科学院计算技术研究所体系结构国家重点实验室 北京 中国1000942中国科学院大学计算机学院 北京 中国101408
1 引言
公钥密码学为全球数字通信系统的构建发挥了重要作用[1]。当前常用的密钥通信协议主要依赖三个核心密码功能: 公钥加密、密钥交换和数字签名。目前, 这些功能主要通过Diffie-Hellman密钥交换、RSA密码体制和ECC密码体制等密码算法来实现。它的安全性通常取决于其背后的数学问题的计算困难度。
近年来, 量子计算算法[2-3]和量子计算机[4]的研究不断得到推进和进步。1994 年, Peter Shor 证明使用量子计算机可以有效地解决这些密码系统的底层数学问题。Shor给出了一种指数加速算法, 可用于解决经典的困难数论问题, 例如大数分解和离散对数求解问题。而这些问题是现代密码系统安全的数学理论基础。
Grover 搜索算法可以双倍速度求解非结构化搜索问题, 大大提高密钥空间的搜索效率, 加速对称密码和散列加密系统的碰撞破解。虽然它不会完全破坏当前的密码系统, 但这使得我们需要提高密钥大小来抵抗其攻击。
同时, 滑铁卢大学量子计算学院的联合创始人米歇尔·莫斯卡 (Michele Mosca) 表示, 到 2026 年, 量子计算机将有可能可能性攻破 RSA-2048, 而到 2031 年, 莫斯卡认为成功攻击的概率将达到50%[5]。
因此, 量子计算机强大的计算能力对现代加密技术的安全性和隐私性构成的威胁成为亟待考虑和解决的新问题[2]。对于掌握量子计算能力的攻击者, 现有对称密码的安全性将降低一半, 而现有非对称密码将被彻底攻破, 因此我们需要寻找全新的面向量子计算威胁安全的密码算法。
作为密码系统的重要研究方向, 后量子密码学的研究正在快速发展。和基于量子计算机和量子通信环境的量子密码学不同, 后量子密码学基于运行在经典计算机(如非量子计算机)上的密码系统, 足以 抵抗传统计算机和量子计算机的攻击, 从而可以和现有的网络与通信协议交互工作。
美国国家标准技术研究所在全球范围内开展了后量子算法的征集工作, 2019年1月30日, 开展了第二轮征集工作, 选拔出26个后量子密码机制。其中, 关注度较高的算法可以分为以下几类: 基于格、基于编码、基于哈希、基于多变量密码学和基于同源, 这些算法有希望解决后量子加密的问题。上述各种后量子加密算法之间有很大区别: 开发时间不同, 算法结构各有特点, 性能各有优劣。在这些算法中, 基于格的算法在安全性、公钥私钥尺寸和运算速度中达到了较好的权衡, 因此是最有潜力的后量子加密算法之一[1,6]。而且在2020年公布的第三轮征集结果中, 作为一种基于格的密钥封装算法, CRYSTALS- KYBER成功入选[7]。
尽管CRYSTALS-KYBER的安全性得到承认, 但它的性能仍然有待探索[8-9]。本论文根据CRYSTALS-KYBER算法进行了硬件设计的优化空间探索。本论文的主要贡献点如下:
(1) 针对KYBER中的循环设计, 本文在硬件设计中进行了优化。本论文分析了CRYSTALS-KYBER的C语言代码, 探索了整个函数和关键循环的调用关系。
(2) 使用HLS综合算法的C语言代码, 通过循环展开和循环流水进行设计空间探索。同时, 时钟约束的影响也将纳入考虑范围。
(3) 为了方便进行设计空间探索, 本论文设计了tcl-perl脚本程序, 用以自动运行HLS。该程序还可以用于其他后量子算法的设计空间探索。
(4) 密钥生成、封装、解封装的优化均取得了积极效果。在Kyber-512中, 三个模块分别实现了44.2%、55.7% 和50.2%的优化效率。对于封装和解封装模块, 与已发表的最新成果相比, 性能分别达到了75%和55.1%的提升。此外, 本论文还在电路面积和速度之间实现了更好的权衡。
(5) 对于不同的参数集, 优化策略的选择对优化效率的影响大致相同。
本论文的组织结构如下: 第二部分介绍了后量子加密和CRYSTALS-KYBER, 包括算法功能介绍;第三部分描述并分析了设计空间探索过程; 第四部分展示了优化效果; 第五部分总结全文。
2 PQC与CRYSTAL-KYBER
量子计算机与Shor算法的出现极大地提升了计算机的计算能力[2]。尽管对称加密算法通过扩展密钥大小仍能保证自身的安全性, 但公钥加密算法在很大程度上遭受了不可逆转的损失[1,10]。解决该问题的关键是, 发展一种新的后量子公钥加密体系。
NIST收集的PQC算法主要包含两种类型: 密钥封装算法(也称为密钥封装机制, KEM)和数字签名算法[7,11]。本论文主要关注前一种。 PQC中使用的KEM是一种抵抗量子攻击的有效手段。不同于使用公钥-私钥对直接传输信息, 密钥封装机制在传输过程中添加了一个共享秘密, 使用公钥和私钥可对共享秘密完成封装和解封装。不能被量子计算机攻破的密钥生成函数(例如哈希函数), 将被应用在加密封装和解密封装的进程中。接着被用来完成对消息的加密和解密[12-14]。因此, KEM的主函数包括密钥生成, 密钥封装和密钥解封装[14]:
(1) 密钥生成部分负责生成公钥pk和私钥sk。
(2) 密钥封装部分接收公钥pk, 并通过对pk的加密封装, 输出共享秘密ss以及密文ct。
(3) 密钥解封装部分使用接收得到的私钥sk和密文ct, 恢复出共享秘密ss。
在PQC算法中, 基于格的密钥建立算法相对简单、高效且并行度高, 所以受到了广泛关注和认可[1]。
CRYSTALS-KYBER(或简称Kyber)是一种基于格的IND-CCA2安全KEM算法,其安全性建立在模格中解决learning-with-error问题的困难性上。Kyber有三种参数集, Kyber-512, Kyber-768, Kyber-1024, 分别对应安全等级1, 3, 5[12-14]。在本论文的探索和实验过程中, 三种参数集的实验结果都会被展出。
3 设计空间探索
为提高电路性能, 本论文使用了图1所示的流程探索设计空间。
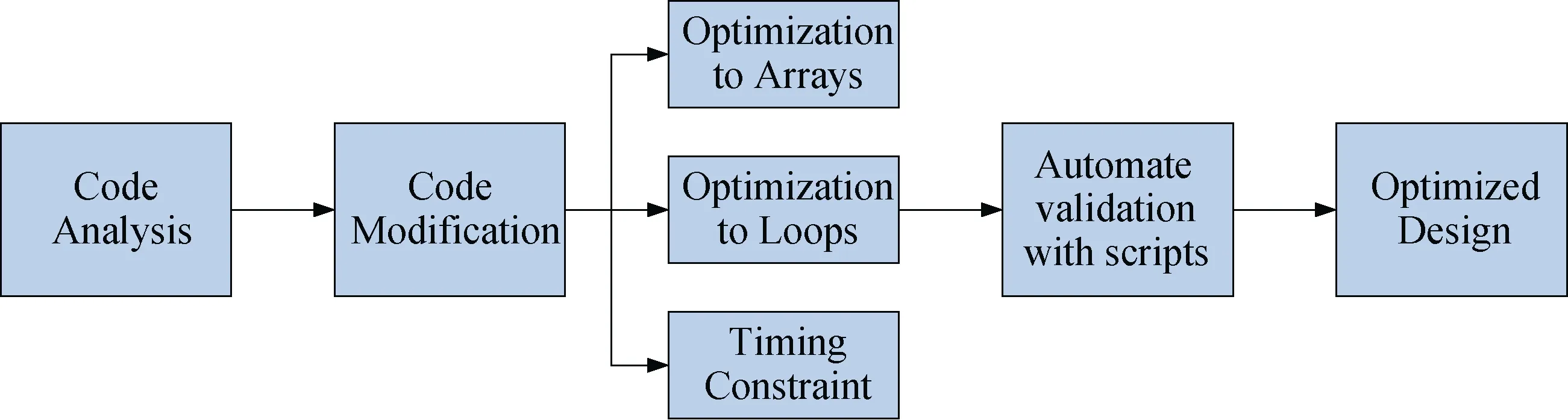
图1 探索设计空间的流程Figure 1 The process of exploring the design space
首先, 本论文对C语言代码的结构进行详细的分析, 寻找可优化的位置。接着, HLS支持RTL综合, 同时可对C语言编写的模块进行验证。并且HLS可以自动生成Verilog代码和IP核。与人工完成C语言代码到Verilog代码的映射相比, HLS为早期阶段的探索提供了一种即方便又快捷的方式。同时这也是一种实现和优化PQC算法硬件设计的良好尝试, 为本文提供了对比分析的基础指标。然而, 一些C语言结构不被HLS支持[15-16], 所以本论文修改了原始的Kyber代码以适应HLS的规则。最后, 依托于基准方案(例, 未进行优化), 本论文考虑了三种不同方式的优化方案。HLS提供对数组(或接口)和循环结构的优化。对不同的循环结构可应用不同的优化策略, 来达到更好的效果。另外, 时序约束条件也是RTL设计中的一个重要因素。本文中也展示出不同时序约束条件下设计方案的探索和对比。基于上述分析, 本论文编写了脚本程序, 自动对得到的结果进行验证, 来获得最终的优化设计方案。
3.1 C语言代码分析
为了完善后续的设计空间探索, Kyber提供的算法[12]和C语言代码需要被分析。其中, 本论文关注循环结构进和接口。
与KEM的主函数一致, Kyber也拥有三个主函数: crypto_kem_keypair, crypto_kem_enc, crypto_ kem_dec。图2~3分别展示了Kyber-512的三个主函数及循环结构的调用图示。其他参数集的Kyber算法, 调用关系基本与Kyber-512一致。红色块代表两个主函数, 黄色块代表函数以及指示它来自哪个文件, 蓝色块代表循环结构。为简化调用关系图, 重复的函数用灰色块表示, 且不再展开。水平箭头指向函数或循环调用的子函数, 垂直箭头代表某函数下的连续循环结构。

图2 crypto_kem_keypair的调用关系图示Figure 2 Call Graph ofcrypto_kem_keypair
同时, 对接口的关注也能帮助分析优化方式是否能被采纳。表1展示了Kyber三个主函数的输入、输出和各自的大小。输入与输出的大小由不同的参数集决定。后续的分析与探索将由这些基础展开。
表1 第三轮候选者列表Table 1 The list of third round candidates
3.2 C语言的修改
HLS不支持某些C语言结构, 例如动态内存分配, 对操作系统的系统调用, 递归函数等[10-11]。为确保HLS设计进程正常运行, 本论文对原始代码进行了最小限度的修改。
首先, 本论文修改“randombytes.c”文件。文件中函数randombytes通过调用系统文件生成伪随机数, 这是HLS不支持的操作。本论文将其修改为, 从外部接收输入的伪随机数数种, 之后在代码中进行简单的随机计算进程, 再作为新随机数参与到整个模块的计算中。外部输入的数种, 可以由独立的模块生成。为完成该功能, 本论文为Kyber的两个顶层函数添加了一个32 bytes的外部输入接口。
另外, 表2中列出的接口在原始代码中涉及到动态内存分配, 这也是HLS不支持的操作。幸运的是, 本论文发现输入与输出的大小是固定的, 所以本论文将两个顶层函数的外部接口由指针改变为定长数组。
3.3 数组优化
在Kyber算法代码中, 一次函数调用提供的或返回的变量是指针形式或数组形式。在HLS中, 对于数组, 有多种优化方法[15], 如表3所示。
在Kyber中, 数组的尺寸很大, 所以表3中展示的数组映射不再被考虑。相反地, 数组分割可应用于模块内的数组, 提高数据流的速度。

表3 HLS中对于数组的优化方法Table 3 Optimization methods for arrays in HLS
对于模块顶层函数的外部接口(表2), 使用数组分割可以增加端口数量, 但是数组重组可以增加端口的位宽, 从而降低输入输出数据的等待时间。

表2 Kyber-512的输入输出接口及其长度Table 2 Input and output interfaces and their lengths of Kyber-512
3.4 循环优化
延时很大程度上取决于循环的操作时间。如何降低循环每次迭代之间的等待时间是降低延时的关键。HLS提供了两种循环优化策略[15], 如表4所示。

表4 HLS中循环优化策略Table 4 Optimization strategy for loops in HLS

图3 crypto_kem_enc 和 crypto_kem_dec的调用关系图示Figure 3 Call Graph of crypto_kem_enc and crypto_kem_dec
Kyber中有许多循环。为了简化分析, 我们将图2中的循环分为简单循环和复杂循环两类, 展示如表5所示。

表5 Kyber中循环的分类Table 5 Loops in Kyber
在分析代码结构后, 本文发现在函数keccak_ absorb、keccak_squeezeblocks和gen_matrix中有多个复杂循环, 它们之间也有调用关系。因此, 我们将重点关注这一部分的优化策略选择。这些复杂循环也是导致高延迟的重要循环。
循环优化的策略选择是本文的讨论重点。通过对优化策略的解读和循环分析, 我们得到以下优化规则, 并根据这些规则指导实际的优化:
首先, Kyber算法中有很多单层简单循环, 它们的功能是进行简单的算术运算和数组赋值。
对于数组边界小的这些循环, 以及Kyber中频繁调用的函数, 使用循环展开、创造多个独立操作将得到较好的优化效果。虽然会消耗电路面积, 但对这些循环进行完全展开会取得更好的综合效果。例如,store64和load64的循环边界是8, 它们适合使用循环展开来减少延迟。
但是, 我们认为在以下情况中, 流水线会在电路面积和延迟之间实现更好的权衡: 当数组边界增加时, 比如sha3_256函数的边界为64; 或者函数中的循环较少调用, 例如pack_pk和unpack_pk; 或者循环包含非常复杂的算数或赋值运算, 例如KeccakF600_StatePermute。本文认为这些情况更适合使用流水线。
此外, 有一些循环的内部计算过于复杂, 很少被调用。我们认为最好不要优化这种类型的循环。它可能会花费太多不值得的硬件成本。
其次, 对于嵌套的简单循环, 流水线优化对象本质上是外部循环和内部循环或函数。外层的流水线导致内层的展开, 这将大大增加电路面积, 例如cbd函数。因此, 内部循环的流水线优化将消耗更少的硬件资源。外层循环的流水线优化将显著增加需要调度的操作数量, 从而需要更多的硬件资源, 但它将导致延迟方面的性能更高的设计。
复杂循环和其他函数之间有调用关系。和嵌套简单循环相似, 如果对其进行流水线优化, 会出现内部函数完全展开的情况, 造成硬件资源的浪费。同时, 被调用函数内部的循环也可以被优化。
所以如何权衡以获得最佳效果, 是我们的研究重点。我们将在实验部分展示我们的研究结果。
3.5 时序约束
时序约束的设置会影响 HLS 的设计。为了使得电路的频率更高, 往往会付出延迟和面积开销增加的代价。文献[14]分析了 NIST 的7种密钥封装算法和4种签名算法的 HLS 实现。而在文献[14]提出的方案中, Kyber的HLS设计选择了的时钟周期为15 ns。 由于频率与时钟周期有关, 我们在优化中尝试不同的时序约束来分析性能。
3.6 用脚本自动验证
通过以上分析, 我们得到了选择优化策略的基本原则。为确保结果正确, 还需要人工验证和数据比对。这个过程需要大量的操作和分析。由于HLS支持tcl脚本控制, 为了简化其验证过程并扩展到其他PQC算法, 我们编写了tcl-perl协同脚本程序来实现相应的操作。
该程序包含如表6所示的以下功能:

表6 tcl-perl协同脚本程序功能Table 6 The function of tcl-perl collaborative script program
4 结果分析
本文实验使用了 Vivado HLS 2018.2工具, 并以 Virtex-7 VC709 作为目标硬件平台。除讨论时钟周期的影响的实验, 其他设计的时钟均设置为10 ns。
同时, 本文将Kyber-512作为主要分析对象, 对各种优化策略进行单独分析。其他参数集的优化设计将在最后独立给出并进行比较。
对于性能指标, 我们有以下几点考虑: 首先, 对于硬件设计, 我们需要考虑它的性能和硬件资源消耗。时钟拍数可以用来衡量性能, FF和LUT的数量可以用来衡量硬件资源开销。此外, 性能和资源之间的均衡性是一个更有意义的指标。根据已有工作, 我们可以采用时延面积乘积LAP= (FF+LUT)×clock cycles作为一个度量。LAP越小, 性能越好。在循环优化中, 我们加入了不同的时钟约束, 然而clock cycle不能完全确定在不同时钟约束下所需的计算时间。因此本文进一步使用总运行时间与面积乘积TAP=LAP/f_clk(时钟频率)=LAP×clk(时钟周期)的方式对电路性能/资源的均衡性进行度量。
4.1 数组优化
由于三个顶层函数的优化结果有相同的趋势, 在这里以crypto_kem_enc函数为例进行说明。
如图4所示, 对一些被其他函数调用的内部模块的接口进行数组分割。而其他优化策略增加了外部端口的端口数或端口位宽(端口是整个模块的输入和输出), 在图4中, 横坐标展示了不同的优化策略。柱状图的值对应左边的纵坐标, 展示触发器、查找表的数量以及延迟。折线图对应右边的纵坐标, 展示延迟-面积乘积LAP。

图4 Kyber-512接口和端口的优化(时钟周期为10ns)Figure 4 Optimization for interfaces and ports of Kyber-512 with clk=10ns
对于内部模块的局部接口, 数组分割能通过增大硬件资源开销降低延迟, 从而获得正向优化的效果。但是, 这带来的正向优化效果非常小, 只有0.128%。
同时, 如果端口的优化增大硬件资源开销, 却没有相应地降低延迟, 将带来负向影响。这也会导致LAP的增加。其中, 当端口数量增加到6个以上时,LAP增加得最多, 达到67.2%。因此, 端口数量越多,LAP增加越多。
从结果来看, 数组的优化无法达到理想的优化效果。所以, 在最终的优化设计中将不再考虑数组的优化。
4.2 对循环结构的优化
本论文在这里展示循环结构优化后, 三个顶层函数的结果和分析。
首先, 如图5~7所示, 对于时钟周期为10ns条件下的三个函数, 简单循环和复杂循环都获得了正向优化。相较于未优化方案, 密钥生成算法的简单循环和复杂循环优化方案LAP优化效率分别达到41.3%和16.5%。对于封装算法,LAP优化效率分别达到45.5%和26.9%。对于解封装算法,LAP的优化效率分别达到41.8%和19.7%。这意味着, 经过对循环结构进行相关优化, 模块的性能可得到大幅提升。

图5 时钟周期10ns下, 对Kyber-512密钥生成算法的循环结构优化Figure 5 Optimization for loops of key generation algorithm of Kyber-512 with clk=10ns
表7~8展示了对三种循环结构添加循环流水和循环展开的数量。

表7 对简单循环结构添加的循环流水与循环展开的数量Table 7 The number of pipelining and unrolling added to simple loops
其中, 对简单单层循环结构的优化结果符合由代码结构分析得到的规律。
对于简单嵌套的循环结构, 优化规律基本和简单单层循环结构的一致。在对Kyber算法某个特定情况的探索过程中, 本论文发现, 对一个嵌套的简单循环结构中的最外层(Kyber算法的最复杂嵌套结构包含3层)或一个子循环中的循环使用循环流水, 可以获得更好的效果增长, 例如polyvec_compress函数。这种嵌套的循环结构的特征是, 最内层的循环结构通常是一种简单的运算或赋值操作, 同时拥有较小的循环边界。这和本文对简单单层循环的分析一致。

图6 时钟周期10ns下, 对Kyber-512密钥封装算法的循环结构优化Figure 6 Optimization for loops of encapsulation algorithm of Kyber-512 with clk=10ns

图7 时钟周期10ns下, 对Kyber-512密钥解封装算法的循环结构优化Figure 7 Optimization for loops of decapsulation algorithm of Kyber-512 with clk=10ns

表8 对复杂循环结构添加的循环流水与循环展开的数量Table 8 The number of pipelining and unrolling added to complex loop
因此, 对大多数简单循环, 从过往分析中得到的规律是能够适用的。根据Kyber算法的特征, 多数循环结构都适合使用循环流水。循环流水与循环展开的应用比例为2:1。对简单循环的优化可带来良好效果。
通过对复杂循环的探索, 本论文发现其优化策略的选择大致上与简单循环的选择一致。对于操作简单的内层调用函数, 外层复杂循环可以根据简单循环的分析选择合适的优化, 叠加对内部函数的优化。然而, 如果内层调用函数和其循环结构是复杂的, 例如KeccakF600_StatePermute, 或者内层函数与其他函数也有复杂的后续调用关系, 例如polyvec_ pointwise_acc_montgomery, 此时不推荐对外层循环进行优化。例如, 对于keccak_absorb的循环2和循环3, 循环2不做优化, 循环3使用循环流水才能达到最佳效果。
因此, 对于复杂循环, 因其复杂的结构, HLS对它们的调度和安排能力有限, 可选优化策略的范围很小。正如之前提到的gen_matrix函数的优化, HLS不能提供恰当的调度策略, 因为keccak_absorb函数和keccak_squeezeblocks函数包含大量的复杂循环和后续调用。所以对gen_matrix函数不做优化是最好的选择。
同时, 与简单循环的优化相比, 循环展开的比例增加了。因为循环流水将展开所有低于当前循环级别的函数和循环。随着低级函数或循环数量的增加, 硬件资源会大量消耗。虽然可以优化的复杂循环数量很少, 但优化的部分都提供了显着的性能改进。硬件资源和延时都低于基准方案。
此外, 通过组合所有优化, 即完全优化,LAP达到最低值。与基准方案相比,LAP的优化效率可分别达到44.2%、55.7%和50.2%。硬件资源消耗略有上下波动, 但延时明显降低。
4.3 时序约束的影响
此外, 本论文还考虑了时钟的影响。文献[14]同样使用 Virtex-7 作为目标硬件平台, 它提供了在时钟周期为 15ns 时封装算法和解封装算法的基准数据, 对封装算法采用流水线策略优化和展开策略优化的数据, 以及对解封装算法采用展开策略优化的数据。在我们的实验中, 本论文尝试了不同的时序约束, 时钟周期设置包括 10ns 和 7.16ns两种。

图9 不同时钟周期下密钥封装算法的优化Figure 9 Optimization for encapsulation algorithm with different clock

图10 不同时钟周期下密钥解封算法的优化Figure 10 Optimization for decapsulation algorithm with different clock
如图 8~10 所示, 随着时钟拍数的减少, 硬件消耗和时钟周期都有不同幅度的增加, 从而导致LAP增加。但是, 模块计算所需的总时间面积乘积TAP大大减少。对于密钥生成算法, 与 时钟周期为10ns 的基准实现相比, 时钟周期为7.16ns 的基准实现的TAP降低了 17.9%。而对于封装和解封装算法, 分别下降了 15.3% 和 12.2%。此外, 与时钟周期为 10ns相比, 三种算法的时钟周期设置为7.16ns, 且采用全部优化的实现,TAP分别降低了17.2%、17.0%和 12.3%。因此, 在时序约束中降低时钟周期可以进一步优化设计。在这个设计中它最低可以降至7.16ns。 与文献[14]相比, 无论采用哪种时钟周期和优化策略设置, 本论文的实验结果都有更明显的优势。对于封装算法, 文献[14]中的LAP和TAP最优结果对应的是基准设计。与文献[14]的最优结果相比, 当时钟周期为15ns 时, 我们无优化的设计LAP降低了 7.7%。在时钟周期为15ns的设置下, 采用全面优化策略的设计,LAP降低了 59.7%。当时钟周期为7.16ns 时, 完全优化的设计TAP降低了75%。对于 解封装算法, 文献[14]的最优结果也对应基准设计。而在本论文中对时钟周期为15ns 的全面优化中,LAP降低了 34.5%。当时钟周期为7.16ns 时, 完全优化的TAP降低了 55.1%。可以看到, 我们的优化取得了显着的提高。

图8 不同时钟周期下密钥生成算法的优化Figure 8 Optimization for key generation algorithm with different clock
4.4 不同参数集的优化设计
图 11~13 展示了不同参数集的设计和优化结果。此处设置的时序约束为: 时钟周期取7.16ns 以获得最佳结果。从结果可以看出, 不同参数集下的算法基本使用相同的模块, 因此每个参数集之间的硬件资源消耗差异不大。但是, 由于要计算的数据量不同, 这导致总的时钟拍数变化显著, 时钟拍数与表2所展示的输入和输出长度呈线性增长趋势。

图11 不同参数集的密钥生成算法设计Figure 11 Design for key generation algorithm with different parameter sets

图12 不同参数集的密钥封装算法设计Figure 12 Design for encapsulation algorithm with different parameter sets

图13 不同参数集的密钥解封装算法设计Figure 13 Design for decapsulation algorithm with different parameter sets
对于优化后的设计, 三个参数集采用了大致相同的优化策略。在极少数模块中, 由于处理的数据量不同, 实验中需要扩大循环边界或扩大计算规模, 从而影响优化策略的选择。最终, 对于 Kyber-512, 三种算法的优化效率分别为 43.7%、56.6% 和 50.3%。 Kyber-768 的优化效率分别达到了 44.1%、56.3% 和 46.1%。而对于 Kyber-1024, 优化效率分别达到了 42.9%、52.8% 和 46.8%。
4.5 与已有工作的对比
表9展示了本文与在不同平台上实现的Kyber512的运行时钟周期数的对比。实验结果显示: 本文的HLS实现与硬件设计[17]相比, 性能相近; 而本文的HLS实现与软件实现[18-19]相比, 具有明显的性能优势。

表9 在不同平台上实现的Kyber512的运行时钟周期对比Table 9 Clock cycles of Kyber512 implemented on different platforms
表10~11展示了对于Kyber512的密钥封装模块和密钥解封装模块的HLS实现对比。表10~11中的本文数据为采取完全优化策略且时钟周期clk选取7.16ns的数据。实验结果显示, 相比已有HLS实现[14], 本文具有更小的硬件开销, 更短的运行时间。

表10 Kyber512 密钥封装模块HLS实现硬件资源开销及性能对比Table 10 Comparison of hardware resource overhead and performance of Kyber512 Encapsulation module

表11 Kyber512 密钥解封装模块HLS实现硬件资源开销及性能对比Table 11 Comparison of hardware resource overhead and performance of Kyber512 Decapsulation module
5 总结
目前, PQC算法的硬件实现是一个崭新的、具有重大意义的研究领域。HLS为探索 PQC 算法的硬件设计提供了方便快捷的工具。为了对PQC KEM算法CRYSTALS-KYBER进行研究, 本文对其硬件设计的优化空间进行了探索。本文对 Kyber 的软件架构进行了详细分析。此外, 本文编写了 tcl-perl 协同脚本以使得探索过程能够自动化。本文使用 Virtex-7 VC709 作为目标硬件平台。实验结果表明, 循环流水或循环展开的方法可以提高 Kyber 中循环的性能, 并且能够帮助实现硬件资源和速度之间的有效均衡。实验结果表明不同的循环适用不同的优化策略。其中, 在Kyber-512中, 三个算法模块的最优化设计的优化效率分别可以达到44.2%、55.7%和50.2%。与已有工作[14]相比, 本文的优化取得了积极的效果。封装模块的运行总时间与面积乘积TAP降低了75%。解封装模块的运行总时间与面积乘积TAP减少了55.1%。实验结果显示对于 Kyber 的不同参数集, 最优优化策略基本一致, 优化效率保持在同一水平。在未来的工作中, 一方面计划进一步探索后量子加密算法的硬件实现, 并针对其中一些关键模块提出具体的硬件优化方案, 以实现效率更高的后量子加密算法专用电路; 另一方面, 对于后量子密码算法实现, 是否能够抵抗侧信道攻击也是一个重要的研究问题, 计划将对 Kyber算法实现的侧信道攻防问题展开研究。
致 谢本文得到了国家自然科学基金(NSFC)区域创新发展联合基金(No. U20A20202)的支持。通讯作者为叶靖。
