基于MLWE的格密码高效硬件实现
2022-01-04崔益军倪子颖王成华刘伟强
崔益军, 姚 衎, 倪子颖, 王成华, 刘伟强
南京航空航天大学电子信息工程学院 南京 中国 210000
1 引言
信息安全在是现代信息社会的建设基础及发展保障, 各种应用信息的传输、交换与存储都是在公认足够安全的密码体制保护下进行的。传统的基于公钥加密方案的安全性依赖于一些数学困难问题, 例如基于大整数分解问题的 RSA(Rivest Shamir Adleman)算法和基于离散对数问题的椭圆曲线密码(Elliptic Curve Cryptography, ECC)算法[1], 这些数学困难问题在经典计算机的计算能力下是难以破解的。但是, Peter Shor在1994年提出了著名的量子算法[2], 在强大的量子计算机问世后可以轻松解决传统公钥加密方案的数学困难问题。虽然量子计算机的发展仍处于初级阶段, 但随着量子计算机技术的成熟, 由于底层依赖的数学问题被解决, 现有的设备中所采用的公钥密码算法将被完全攻破。因此, 亟需研究出能够抵抗量子计算机攻击的新一代密码算法。
1.1 后量子密码标准化进程
后量子密码算法(Post-Quantum Cryptography, PQC)也称抗量子密码算法, 美国国家标准技术研究所 (National Institute of Standards and Technology, NIST)早在 2012 年启动了后量子密码的研究工作, 并于 2016 年 2月启动了全球范围内的后量子密码标准征集, 相关时间线如图1所示。NIST在制定后量子密码算法的标准时主要聚焦于公钥加密、密钥交换和数字签名。在NIST第一轮公布的69个初次的候选方案中, 主要包括以下4种数学方法构造的后量子密码算法:

图1 后量子密码标准的发展时间线Figure 1 NIST PQC standardization timeline
1) 基于格的密码(Lattice-based Cryptography, LBC)。其通过格上的数学困难问题, 如发现格上n个线性无关的短向量构造基于格的后量子密码。格密码以其高效率轻量级公钥而闻名, 使得它成为高速网络应用和物联网应用的首选, 也是标准化过程中最有希望成为最终候选方案的后量子密码算法。
2) 基于编码的密码(Code-based Cryptography, CBC)。其通过使用错误纠正码对加入的随机性错误进行纠正和计算, McEliece是一种经典的基于编码的后量子密码, 即使其公钥尺寸过大但凭借非常小的密文, McEliece在后量子密码标准化过程中始终有自己的一席之位。
3) 多变量多项式的密码(Multivariate Polynomial Cryptography, MPC)。其通过在有限域上具有多个变量的二次多项式方程组构造新的密码方案, 提供了快速的签名和验证, 在后量子密码标准化进程中Rainbow作为该类密码方案的代表, 被选为最终标准的数字签名最终候选方案。
4) 基于哈希签名(Hash-based signatures, HBS)的密码。其不依赖于某一个特定的哈希函数构造数字签名, 但考虑到其较其他三类后量子密码密钥过长且成本较大, 在标准化进程中逐渐被淘汰。
在NIST公布的通过第一轮筛选的69项草案中, 基于格的密码方案多达 26 种。在接下来的两年中, NIST根据候选算法的抗侧信道攻击性、实现性能、成本和其他特性对其进行评估。2019年, NIST选择了26种算法进入第二轮进行更深层次的分析, 其中有将近一半为格密码算法。2020年7月, 第三轮后量子密码标准入围名单公布[3], 除了7种最终被考虑标准化的决赛方案, 此外还有8个备选方案也将进入第三轮的考察中。其中在7个最终候选方案入围的公钥加密和密钥交换中, 基于格的协议有NTRU、CRYSTALS-Kyber和SABER ; 入围数字签名的格密码方案有两种分别是DILITHIUM和 FALCON。由后量子密码标准化进程的发展, 可以观察到格密码方案的多样性以及成为最终标准后量子密码方案的潜力性。后量子密码算法的硬件实现性能也是成为最终标准的衡量指标, 格密码能够在硬件平台上的高效实现也是其优势之一, 但是在物联网技术的飞速发展的环境下, 如何实现轻量级高性能的格密码并使其适用于物联网芯片是推动后量子密码标准化进程的研究重点。
1.2 国内外研究现状
在众多的后量子密码方案中, 基于格的方案凭着自身众多优异的特点, 成为了最有潜力的后量子密码方案。2005年, Regev[4]首次提出了基于错误学习问题(Learning With Errors, LWE)的可严格证明理论安全性的格密码方案, 相比较于传统的公钥加密方案, 基于LWE问题的公钥加密方案结构更简单, 运算速度更快, 但随安全系数正比增长的公钥长度限制了实用性。为了解决这个问题, Lyubashevsky 于 2010 年提出了环域上的误差学习(Ring-LWE, RLWE)问题[5], RLWE在实现效率和公钥长度的优越性使其在提出后备受学术界的关注, 也有相关研究人员将其应用到物联网设备中。但是基于RLWE的格密码方案结构化程度最高, 也就意味着其安全性受到了影响, 因此在NIST公布的第三轮后量子密码标准中基于RLWE的格密码方案全部落选。综合LWE和RLWE的特点, Brakerski 和 Langlois 等人[6]在2015年提出了基于模误差学习问题(Module-LWE, MLWE)的格密码方案, MLWE问题相比较于RLWE方案具有更复杂的代数结构和更高的安全性, 同时具备比LWE方案更高的性能。事实上, 在第三轮后量子密码标准中, 公钥加密方案CRYSTALS-Kyber以及数字签名方案DILITHIUM都是基于MLWE, SABER方案也是基于MLWE问题的变体模带舍入学习(Module Learning With Rounding, MLWR)困难问题[7]。由此可见, 基于MLWE的格密码在后量子密码算法中的具备主导地位。本文的主要内容便是探讨基于MLWE的格密码算法的高效硬件实现方案。
随着 NIST 对后量子密码标准化的推进, 关于格密码的硬件实现研究也步入了快速发展的轨道。在 NIST 第三轮 PQC 密码方案公布之前, R-LWE 公钥加密方案是被广泛研究的格密码方案。2012年, 文献[8]中首次采用了快速数论变换(Number theoretic transforms, NTT)对RLWE密码进行了硬件设计, 并与LWE的矩阵运算进行了性能对比。2014年, Sujoy[9]对RLWE加密方案优化提出了最经典的紧凑型设计, 优化 NTT 算法的预处理和后处理时间、数据存储和读取方式以及旋转因子的存储等方面, 在面积、频率和执行时间上都有较大的优势。为了追求更高的性能, 研究者在核心的多项式乘法模块对NTT算法进行了不同的优化设计, 文献[10]中 DU 采用了4个蝶形单元并行, 合理安排存储单元中的存储顺序得到了高速的多项式乘法模块。清华大学李树国教授团队于 2019 年提出了一种多路径且高并行度的NTT 算法[11], 该算法受 Stockham FFT 算法启发, 通过大量蝶形单元并行来提升 NTT 模块的运算速度。这些硬件优化为第三轮格密码候选方案的实现提供了可参考的设计方案, 文献[12]在紧凑型RLWE设计方案的基础上提出了q=7681的MLWE的高效硬件实现, 但该方案不能兼容最新参数。在2021年, Mojtaba[13]提出了将基于K2-RED算法的模3329约减算法无寄存器延迟的硬件单元应用到4个并行计算的NTT蝶形单元从而实现高速设计。文献[14]首次提出了Kyber密钥交换协议的完整硬件实现, 但硬件资源利用率较低, 同时执行的时间周期也较长。Xing[15]在CHES2021提出了一种时序安排紧密, NTT单元采用基于时域和基于频率的结合型蝶形单元, 有关多项式的加减法操作也复用该蝶形单元完成, 该设计相较于文献[14]在面积时间上都具有很大的超越, 实现了轻量级的格密码硬件实现, 但是在频率上还可以进一步优化。总的来说, 如何在满足性能和资源上的不同需求条件下, 选择最适宜的格密码方案硬件实现方案是目前学术界亟待解决的问题。
1.3 本文主要内容和章节安排
目前已提出的格密码硬件结构在性能上存在硬件资源、速度和功耗不均衡, 兼容性和安全性低等问题, 迫切需要在核心多项式乘法模块进行大量深入细致的基础研究。本文在Kyber第一轮参数q=7681的基础上对第二轮和第三轮的q=3329的NTT算法提出了不同的硬件设计, 一是面积成本和执行时间折中的迭代型NTT设计, 二是高性能的多路延时转接的流水线NTT设计, 并且针对于迭代型NTT模块设计了一种整体MLWE硬件实现结构。
本文其他内容安排如下: 第2节介绍了格密码算法理论基础, 分析了新参数的多项式乘法的改变; 第3节详细介绍了本文提出的基于MLWE的格密码公钥加密方案的硬件结构; 第4节给出了本文提出的两种不同的硬件实现方案的实验数据分析和对比;第5节总结了本论文的主要工作。
2 格密码算法理论基础
目前, 基于MLWE问题的后量子密码算法以CRYSTALS-Kyber最具有代表性, 该方案对大多数应用来说, 具有很好的综合性能。本文也将在CRYSTALS-Kyber算法理论基础上对MLWE问题进行硬件上实现的研究。
2.1 MLWE公钥加密方案
MLWE问题集成了LWE问题的矩阵运算和RLWE的多项式乘法运算, 在介绍基于MLWE的公钥加密方案之前, 先简要说明一下MLWE问题的定义。本文涉及的数学符号有Zq表示为模为q的整数环, 在该数域上的数据大小不会超过模q, 多项式环域用Rq=Zq[x] /(xn+ 1)表示,n为多项式的最高次项。单个多项式不作特别标注, 向量多项式粗体小写字母标注, 矩阵多项式粗体大写字母标注。U表示均匀分布,ηβ表示中心二项分布,k表示公钥矩阵的维数, 用xηβ← 表示根据中心二项分布采样得到的数据。那么一组MLWE样本可表示如下:
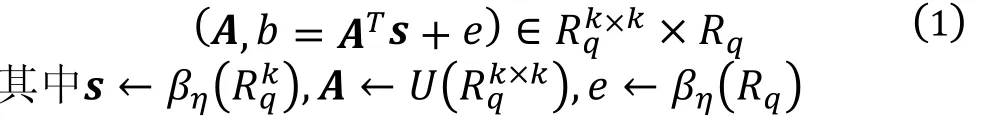
基于MLWE问题构建的公钥加密方案不仅可以具有LWE问题的安全等级也有RLWE问题的高效率, MLWE采用RLWE中的环多项式替换LWE问题矩阵中的整数环参数, 并增加了可变参数k控制公钥多项式矩阵的大小, 在Kyber中, 改变k是将安全性扩展到不同级别的主要机制。
分析NIST官方公布的CRYSTALS-Kyber的密码方案, 可以得到简化版的基于MLWE的格密码公钥加密方案, 其中涉及到的加密和解密过程如算法1所示:
算法1 基于MLWE的公钥加密方案
4. 计算解密中的密文信息c=v-sTu;

本文所采用的是轻量级Kyber512的参数, 它的安全等级相当于n=512的RLWE方案。由于所有误差项的相加也是一个多项式向量, 因此误差多项式的乘积在解密过程中不断增加, 为了保证正确的解密率, Kyber降低了噪声参数η, 并在NIST官方文件中给出了详细的证明[3]。在基于MLWE的公钥加密方案中, 涉及的最复杂的最占用硬件资源与计算时间的就是多项式向量和矩阵运算, 如当k=2时计算密文的具体表达式如下:

因此, 要实现高效的MLWE公钥加密方案必须在多项式乘法上进行优化设计。
2.2 环多项式乘法算法分析
对于MLWE密码算法, 所有多项式都是在Rq=Zq[x] /(xn+ 1)条件下, 所以在这样的约束情况下, 多项式乘法公式计算结果要约减去超过最高次项n之后的系数, 具体计算公式为

公式法计算多项式乘法的算法时间复杂度为O(n2), 且在硬件实现时如果采用单个乘法单元实现虽然占用资源较少, 但运算耗时较长[16], 如果采用并行结构, 节省了运算时间相应的消耗的资源又太多[17], 所以在Kyber公布的官方文件中并没有使用传统的公式法计算方式, 而是采用了NTT变换算法, 但是对NTT的具体操作流程进行了新的定义。
在Kyber的NIST第一轮公布的标准中素数模7681是满足q-1=28×30=29×15是有256次和512次原根的, 定义ψ为旋转因子的模平方根 ψ2mod q=ω 以通过常规的NTT算法去加速多项式乘法计算, 时间复杂度仅为O(nlogn), NTT正变换和逆变换定义如下:
NTT正变换:

NTT逆变换:

如果采用该计算公式并不会简化多项式乘法的的计算, 通过旋转因子的消去引理和折半引理可以将原来的n点序列进行奇数偶数拆分, 得到n/2的序列两个新序列, 再依次对新新序列进行分解, 知道分解成成两点之间直接的运算, 称之为蝶形运算, 以8点的的NTT蝶形运算算为例, 可将上述运算过程用3级每级4个个 蝶形运算单元表示, 如图2所示。
图2表示的是基于频率抽取的(Decimation-in- Frequency, DIIF) NTT的蝶形运算单元, 该类型的的NNTT计算不需要对输入序列进行重排序, 只需要在第一级进行前处理后, 先计算加减单元, 再对减法单元乘上相应次方的旋转因子, 采用DDIF NTT算法在在硬件实现上既可以采用迭代型NTT结构也可以利用DIF NTT蝶形运算单元数据地址的规规律采用MDDC流水型NTT结结构。
第三轮Kyber算法中, 将模q的值减小到3329, 该素数只有2556次原根而不存在512次原根, 所以不可以直接采用用公式(4)和(5)计算, 参考NIST的官方文件, 在环多项式域上的X256+1可以分解为128个平 方项多项式式乘积, 分解表达式如下:

用128个1次多项式向量重新定义q=3329时的的NN TT变换,

其中常数项和和一次项系数计算表达式为:

可以观察到新型NTT 变换中奇数项和偶数项计算是符合常规的1228点的NTT变换, 将ψ==17为前处理的的常数,ψ2=2289为新的旋转因子, 将2256点的NTT变换拆分为常规的2个1228点NTT变换, 在得到NTT变换后的数据后, 对相应的多项式经过NTT变换后的2个256个系数不再是点对点相乘, 再进行NTT逆变换, 这种特殊的逐点乘法(Point-Wise Multiplicattion, PWM)是通过下列计计算得到的:

为了在硬件实现时减少乘法单元的消耗, 利用偶数项的乘法结果可以将总共的的乘法的次数从5次减少到到4次:

所以当模q参数更改为3329时, 对于基于NTT的环多项式乘法只需要对多项式的奇偶项分别进行128点的NTT正逆变换, 并对完成变换后的的NTT域上的两个多项式进行特殊的PWM计算, 基于NTT算法的q=3329的多项式乘法算法流程如算法2所示, 其中1128点的NTTT算法采用的是基于DIF 的迭代型NTT算法[18]。

3 基于MLWE 的格密码的硬件实现
不同于其他的的基于格的密码, MLWE中的多项

3.1 流水型NTT硬件结构设计

图3 RR2MDC中蝶形形单元结构 FFigure 3 Buttterfly unit strructure in R2MDC











3.2 迭代型NTT 硬件结构设

较低等问题。因此, 本文提出一种仅使用一块DSP块来实现的NTT结构。
本设计中选用频率抽取DIF的方式, 采用GS(Gentleman-Sande)蝶形变换。这种蝶形变换首先进行数据的加法和减法, 然后对于减法产生的结果与旋转因子ω相乘。因此, 这种方式构建的结构一共包含一个模加器、一个模减器和一个模乘器。此外, 以上结构均使用流水线结构以提高运行频率。
前两个取模操作是在多路复用器的帮助下对模数q进行加减。而模乘器通过DSP块进行12×12位的乘法运算, 并使用巴雷特约减法将24位的乘积减少到12位。
本设计将预处理与NTT算法结合起来, 并利用旋转因子的模平方根ψ来减少ROM的存储量。的平方根ψ来减少ROM中的存储量。频域变换中的NTT需要在NTT计算的最后一级进行比特位翻转, 因此位翻转单元也包含在NTT模块中。反转单元也包括在同一个NTT模块中。在NTT计算结束时进行置换。对于解密过程中的逆NTT(Inverse NTT), 在NTT域中的向量需要转化为常数域中, 然后算法只需要改变旋转因子(将ω变成ω-i)和后运算(第i个系数的乘法 最后将第i个系数乘以n-1ψ-i。为了这个目的, 常数因子被存储在ROM中, 被配置为分布式ROM。
3.3 基于迭代型NTT的MLWE的加密处理器
本小节中将基于上一小节提出的迭代型NTT来设计一种MLWE的硬件实现结构, 该结构选取Kyber第三轮的参数, 即q=3329。提出的结构如图6所示, 一共包含一个二项分布采样、一个迭代型NTT模块和一个控制模块。

图6 基于MLWE方案的硬件结构Figure 6 The proposed structure of MLWE scheme
3.3.1 二项分布采样
本设计中没有使用离散高斯作为噪声分布, 而是使用η=2或η=3的居中二项分布。CRYSTALS- Kyber采用二项分布是因为实现高斯采样器的方法比较复杂, 而且可能容易受到时间攻击。而二项式取样器只涉及一个步骤, 具有更好的安全性, 在Newhope[19]的案例中已经证明了其安全性。
一个遵循二项分布的样本可以通过比较两个随机数的汉明距离序列来得到。本设计使用轻量级流密码Trivium来生成随机数[20]。产生随机数的数学公式如下:

伪随机数发生器(Pseudo Random Number Generator, PRNG)被用来在每个时钟周期产生一个噪声样本, 因此一共需要256×k个周期来产生一个噪声矢量多项式, 然后将其发送到汉明权重序列比较器, 以获得二项式分布数据。
3.3.2 MLWE方案总体硬件结构
MLWE的整体实现方案包括密钥产生、加密和解密。在开始加密和解密之前, 假设公钥和私钥是在NTT域中产生的, 并且存储在块存储器(Block RAM, BRAM)中。加密阶段, 使用二项分布采样器产生向量多项式误差e1,r和多项式误差e2, 并且写入不同的BRAM中: 18Kb BRAM配置为真双端口RAM模式, 深度和宽度分别为512和12(在Kyber512的情况下)。NTT模块每个周期从BRAM_error中读取两个系数作为蝶形单元的输入。NTT_signal控制NTT模块的启动和结束。
e1和r的系数需要进行4次NTT变换, 因此当之前的系数处理完成后, 首次读取数据的两个端口地址分别扩展为256和384。BRAM_tmp单元负责在内循环和外循环中临时存储数据。在所有的向量被转换到NTT域之后。乘法-累加(Multiply- Accumulate, MAC)单元执行算法2中的PWM0和PWM1操作。本设计利用三个并行DSP计算h2i和h2i+1中的乘法操作来减少运算周期, 其中ψ2i+1存储在分布式ROM中并在加法器和乘法器之间插入流水线寄存器来提高频率和连续数据的处理速度。
NTT域中的密文u和v被传送到解密部分, 与密钥s参与计算得到解密中的密文c。解密时不需要产生错误值, 并且只需要一个两次128点的逆NTT变换, 因此节省很多周期。MAC单元将经过处理后的输入信息m提供给解码器。
4 实验结果分析和对比
本节将以上的设计使用Vivado软件进行仿真综合实现, 并且使用FPGA 运行。在对比方面, 首先将设计的流水型NTT和迭代型NTT设计与目前最先进的NTT设计进行, 之后将由迭代型NTT构建的MLWE方案与其他完整加密方案实现结果进行对比。
4.1 NTT实现对比
表1展示的是本文提出的流水线NTT结构在硬件综合实现后, 资源与时间和目前最先进的结构的对比。本文的流水型结构和对比的结果均使用参数n=256,q=3329。表1以LUT、FF、DSP、18Kb BRAM 为评估面积资源消耗、频率和周期表示硬件设计的计算速度和时间, 展示了本文提出的设计的实现结果。其中频率的单位为MHz, 时间的单位为μs。

表1 不同NTT架构FPGA实现资源消耗对比Table 1 Implementation Results for Different NTT Implementation on FPGA
表1中对比的两个设计和本文提出的设计均采用Artix-7 FPGA实现。在频率上, 本文的设计略低于文献[13]中的设计, 但在周期上, 本文的流水型NTT结构首次启动时间为104个周期, 之后的64个周期中输出第一组128个点的结果, 接着输出第二组的128个点的结果, 同样消耗64个周期, 因此一次完整的256点NTT只需要232个周期, 这远低于其他结构。由于周期上的优势, 本文的流水型NTT运行时间仅为1.29μs, 在下一次的NTT变换中则仅仅需要0.64μs, 相较于文献[13]提升56.16%。
在资源上, 由于流水型NTT除了最后一级以外, 每级包含一个DSP块, 并且预计算包含两个DSP块, 一共使用了8个DSP块。流水型NTT在DSP块上明显多于其他设计, 但是在BRAM资源上, 由于本设计大部分使用了分布式ROM, 进一步减少了BRAM资源的使用, 在BRAM资源上的优化也是流水型NTT相比于文献[21]和[22]的主要优势, 文献[22]对NTT结构采用了1个蝶形单元计算但是采用了5个18Kb BRAM寄存中间数据, 其综合出的面积是大于本文中迭代型NTT设计, 而当文献[22]采用4个蝶形单元计算时, 周期和流水型几乎一样但是在资源数量利用上远超过流水型NTT。与文献[15]相比, 本设计使用了更少的LUT资源, 减少幅度达到9.01%。与文献[13]的设计相比, 本设计使用了更多的LUT和FF资源, 但是在赛灵思7系列的FPGA中, 一块DSP块大致相当于102个FPGA片, 一块36K BRAM块大致相当于196个FPGA片[16]。因此在DSP和BRAM的资源上和本设计相差无几。对于迭代型NTT来说, 由于NTT模块只使用了单个模乘单元, 因此在DSP和BRAM的使用数量上均显著少于其他的设计, 但因迭代型NTT模块中蝶形操作的乘法均复用一个DSP模块, 所以整个执行周期比其他设计略高。
4.2 MLWE整体方案实现对比
本文的MLWE 密码处理器使用 Kintex-7 (KC705) FPGA 综合实现并使用 Xilinx Vivado 2018.3 实现。 表 2 以 Slice/LUT/FF、DSP、BRAM 为资源消耗、频率的单位为MHz、 Cycles为加密解密需要的时钟周期数。为了与其他设计进行综合性能比较, 本文提供了一个面积时间乘积 (Area-Time- Product, ATP) 指标来评估执行时间和使用的Slice数量之间的权衡, 其计算公式为综合后的Slice片数量乘执行时间μs得来的, 而Slice是在FPGA芯片中占到比重最大的重要资源。ATP 的值越小, 设计就越高效, 该设计是一个更折中的综合性能较优的设计。 “Op/s”列包含加密和解密处理器每秒可以执行的周期数, 通过周期数除频率计算得到。为了确保公平比较, 本文还选择了不同的RLWE 公钥加密方案, 其中n= 512 (RLWE512) 具有相同的安全级别公钥加密方案和具有相似的多项式运算复杂度的RLWE 的方案, 其中n= 256 (RLWE256)。

表2 本文提出的 MLWE 方案与其他的基于 FPGA的设计结果比较Table 2 FPGA based results comparisons of our proposed MLWE scheme with other designs
与实际的 RLWE 处理器[23]相比, 本设计提出的结构消耗更少的资源和更少的周期次数, 并且从ATP参数来看在实现效率方面具有明显的优势。以小面积成本实现的高效的 RLWE512设计[9]优化了 NTT 模块中的内存访问方案并获得更高的频率, 但是本设计在周期和执行时间方面具有更好的性能, 从而每秒处理更多操作。此设计没有报告消耗的Slice数量, 因此无法获得准确的ATP值。基于最先进的最快的可用Schoolbook多项式乘法的高效 RLWE 设计[24]具有最高频率, 但是, 与NTT算法相比, 该设计消耗的时钟周期数依旧过多。Kyber在FPGA上的处理器设计[12]仅包括针对多项式向量的优化 NTT 设计, 文献[13]是Kyber整体协议的实现, 而本文提出的MLWE加解密适用于需要高安全级别且资源受限设备。
本文提出的设计在加密时, 具有较少的9717个周期数和最小的23.76的ATP值, 并且在解密时需要2808个周期和5.96的ATP。与最佳设计相比, 本文提出的单独MLWE设计比RLWE512[9]具有1.83×的Op/s上的提升, 与RLWE256[24]相比有55.4%在 ATP 权衡上的提升。本设计以合理的面积消耗为代价, 是有良好性能的折中硬件设计。
5 结论
本文针对后量子加密中极具前景的Kyber加密设计了两种不同的NTT结构, 分别为流水型NTT结构和迭代型NTT结构, 此外基于迭代型NTT结构设计出一种MLWE的整体实现方案。实验结果表明, 本文的提出的流水型NTT结构具备更好的速度性能, 在速度上相较于之前的设计提升11.64%和59.43%。同时, 基于迭代型NTT的MLWE整体实现方案, 在使用了最少的周期和最小的 ATP时, 其效率比最新的硬件实现高2倍左右。在未来的工作中, 将使用流水型NTT结构来搭建Kyber的完整协议, 并且将所提出的 MLWE 处理器扩展到整个 CRYSTALS- Kyber 算法和其他参数集。
致 谢感谢南京航空航天大学电子信息工程学院新兴集成电路实验室的各位老师和同学在实验过程中的帮助和支持,感谢审稿专家和编辑老师的指导建议。
