面向多目标跟踪的密集行人群轨迹提取和运动语义感知
2021-12-31游峰梁健中曹水金肖智豪吴镇江王海玮
游峰,梁健中,曹水金,肖智豪,吴镇江,王海玮
(1.华南理工大学,土木与交通学院,广州 510641;2.华南理工大学,亚热带建筑科学国家重点实验室,广州 510640;3.广东交通职业技术学院,运输与经济管理学院,广州 510650)
0 引言
随着我国汽车保有量的增长,我国城市道路车流量逐年攀升。同时,慢行交通、TOD 等交通设计理念在城市规划中不断得到认可,城市的步行空间和功能也日益丰富和完善,促进了步行交通的发展。然而,行人作为交通参与者中的弱势群体,面临着严峻的安全问题。世界卫生组织统计数据显示,行人占道路交通事故总死亡人数的23%[1],我国每年约有10万人在车祸中丧生,其中,约25%是行人。研究表明,行人受伤害严重程度随车辆撞击速度增加而明显增加[2],若车辆时速在35 km以下,行人的存活机会为90%;时速在65 km 时,存活机会将低于50%。为此,使车辆尽早感知行人存在,并避免或缓解人-车冲突风险伤害,是保护行人的有效措施。行人运动建模和轨迹预测,在其中起到关键作用。提取和挖掘视频监控中行人群轨迹数据和特征,是行人行为预测分析的必要工作。
1 研究现状
行人目标运动轨迹研究是行人运动建模分析的一种典型形式,多建立于时空维度上。孙亚圣等[3]融合引入注意力机制的LSTM(Long Short Term Memory)和社会对抗网络(Social Generative Adverserial Network,SGAN),提出适用于密集交互场景下的行人轨迹预测模型。李琳辉等[4]引入一种行人间交互社会关系定义的注意力机制,提高LSTM 在行人轨迹预测中的速度。BHUJEL 等[5]在LSTM 网络中融合语义分割网络提供的物理注意力机制,采取Encoder-Decoder的结构,获得更高的轨迹预测精度。这类轨迹建模研究方法主要是在ETH[6]、UCY[7]等开源数据集上进行轨迹预测建模,对人群密集、交互频繁的场景下能保持较好的预测精度,重点是在基准数据集上,探索和验证更优的轨迹预测算法模型,未考虑新的轨迹数据来源。另一方面,目标检测和跟踪是获取运动轨迹的必要前序工作。ZHAO 等[8]用Faster-RCNN(Faster Regions with CNN features)的RPN(Region Proposal Network)结构生成不同的行人目标框尺度先验,使行人检测推理实时性显著提高。LI等[9]提出整合GhostNet 和SENet 网络结构特点的YOLOv5-GS行人检测、重识别多任务联合模型,根据目标的数量自适应调整网络结构,目标识别率达到93.6%。WOJKE 等[10]将外观特征和运动信息进行深度关联,提出了Deepsort 多目标跟踪算法,使遮挡导致的跟踪失败率降低45%。基于深度学习网络的行人检测和跟踪模型表现出良好的性能,但大部分行人检测跟踪算法的相关研究,更关注算法结构优化,提高行人目标检测跟踪精度,而由此得到的多目标跟踪结果蕴含的特征信息有待进一步挖掘。
综上所述,一方面,现有的目标检测跟踪、轨迹预测建模研究相对独立,所研究的轨迹在时间、空间范围内跨度较为有限,城市平面道路交叉口的长时间、高密度行人群过街场景下,其运动特征提取和挖掘等相关应用工作仍待完善,“目标跟踪-轨迹提取-数据驱动建模”等多环节融合仍是值得探索的问题,海量的道路交叉口交通视频监控数据亟待充分利用。另一方面,密集人群视频场景中的运动语义等信息的应用仍值得进一步研究和分析。因此,本文的工作是尝试在上述研究领域间建立联系,通过多目标跟踪算法,获取视频监控中密集行人群的轨迹簇,解析和挖掘潜在的轨迹源点和消失点等语义信息,为后续行人群运动行为规律和轨迹预测建模提供更充足的先验信息。
2 行人多目标运动特征提取
本文的研究工作主要包含3个部分:(1)在高密度行人群场景下应用多目标跟踪算法框架。用密集人群数据集CrowdHuman 对多目标跟踪FairMOT[11]框架的目标检测主干分支DLA-34[12]进行二次训练,提高密集人群场景的行人目标识别和跟踪性能。(2)基于多目标跟踪的行人运动轨迹特征提取。用第1部分训练好的多目标跟踪算法,捕获连续视频帧中行人的运动特征,构建特征描述子,生成目标运动轨迹;结合轨迹数据的时空分布特点,设计基于协方差矩阵值的异常轨迹检测方法,清洗原始运动轨迹簇,提高轨迹特征的鲁棒性。(3)基于轨迹簇的运动语义挖掘。利用K-means 聚类方法,对清洗后的轨迹簇进行聚类,以S 系数(Silhouette Coefficient)和DB 指数(Davies Bouldin Index)为评估指标,解析出视频场景中的轨迹簇源点和消失点等运动语义特征信息。
经过上述各步骤后,将视频监控序列中的行人目标轨迹提取、提纯,提取出场景语义信息,创建路侧监控视角下的密集行人群轨迹库,为后续数据驱动的行人行为分析预测建模提供数据支持。本文主要研究内容如图1所示。

图1 主要研究内容Fig.1 Research content flow chart
2.1 FairMOT多目标跟踪框架
FairMOT 为Zhang 等[11]在2020年9月提出的,是目前行人多目标跟踪领域性能突出的模型,它整合了目标检测和行人跟踪两大分支,目标检测分支是采用可变形卷积Deformable Convolution 的CenterNet[13],以中心点热力图的形式实现目标定位,简化了极大值抑制(Non Maximum Suppression,NMS)流程,减少背景的干扰。目标检测特征提取主干网络为DLA-34,融合多尺度、多通道、多模组的特征,提高目标检测定位精度,保障目标跟踪分支算法的性能。FairMOT 算法的基本流程如图2所示。
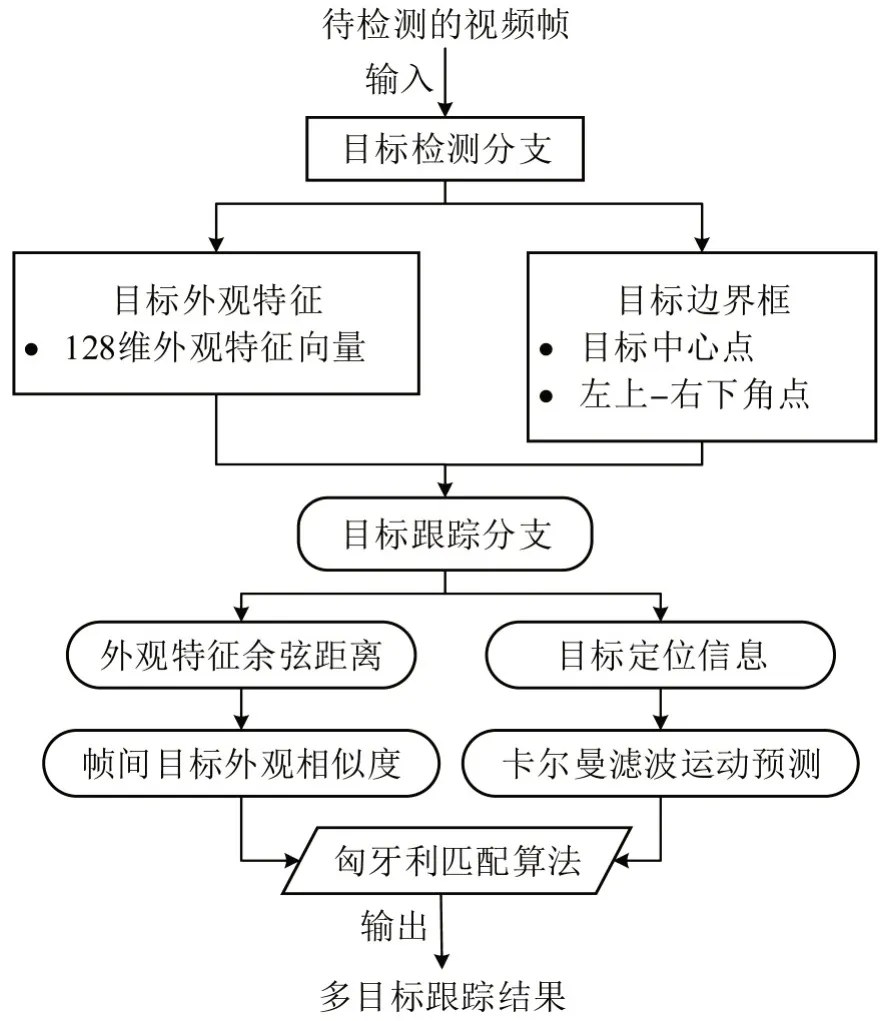
图2 FairMOT多目标跟踪框架的两大分支和逻辑结构Fig.2 Two main streamlines of FairMOT multi-object tracking framework
FairMOT 采用的损失函数值包括4 个部分:hm_loss(Lhm)、wh_loss(Lwh)、offset_loss(Loffset)和id_loss(Lidentity)的加权和。总的损失函数Ltotal是目标检测分支和目标重识别分支两者损失的加权和,即

式中:w1和w2分别为目标检测分支损失和目标识别分支损失的权重,两者均为在模型训练过程中可动态变化的参数;λ1、λ2、λ3为常量,反映了目标检测分支中热力图损失hm_loss(Lhm)、目标中心点预测损失offset_loss(Loffset)和目标边界框回归宽高比损失wh_loss(Lwh)的加权系数。各个损失值含义如表1所示。

表1 多目标跟踪网络损失函数Table 1 Loss functions of multi-object tracking algorithm
2.2 运动轨迹时序特征描述子
利用FairMOT 框架检测跟踪视频中的行人目标,逐帧输出各目标运动轨迹时序特征描述子,反映视频序列中各个目标的可观测物理属性,是包含了行人目标身份唯一标识,目标的位置,以及目标所存在的帧数等信息的7维特征向量,即

式中各分量意义如表2所示。
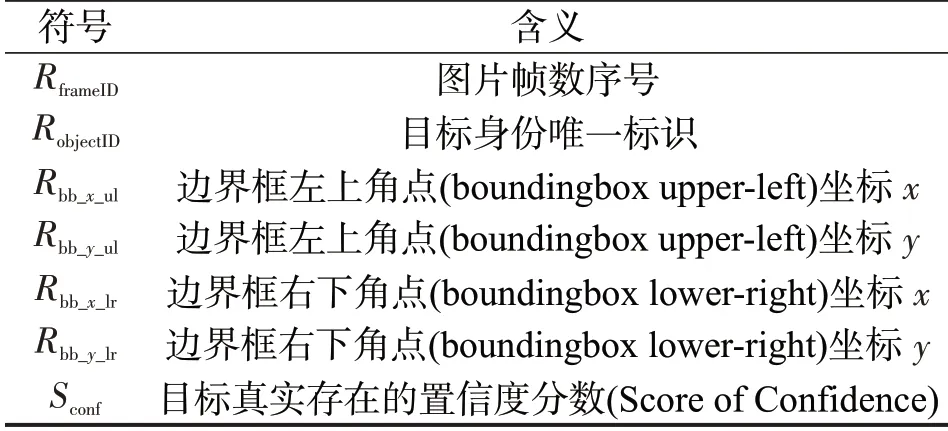
表2 行人多目标跟踪算法的输出结果Table 2 Results of multi-object pedestrian tracking
对于行人目标,从视频中出现直至消失时间内的所有特征描述子,构成该目标运动轨迹特征向量。为简洁地描述目标在不同时刻的位置属性,将目标边界框坐标转化为质心点坐标,即

式中:(xc,yc)为像素坐标系下的目标质心位置。
得到目标质心点位置的表征后,进一步求解目标的运动方向和位移特征描述子,通过逐帧质心差分实现,即

最终,目标运动轨迹时序特征描述子为

整合目标身份标识相同的所有特征描述子,得到描述运动轨迹特征的向量组。每一个向量组在坐标平面内可形成一条轨迹,各目标的轨迹构成一个轨迹簇。

式中:Fi为视频中第i个目标的所有特征描述子V所组成的运动轨迹特征向量组;FTraj为从视频序列中提取的轨迹簇,包含N个目标的运动轨迹特征向量组。
3 运动轨迹清洗和语义特征提取
3.1 基于协方差矩阵参数值的轨迹数据清洗
提取行人目标运动轨迹,获取各个目标在时空维度的变化信息,是数据驱动轨迹建模必要的基础。因而,数据质量是关键,有必要识别出轨迹中的噪声,加以修正或剔除,实现对提取原始轨迹信息的清洗。
通过分析FairMOT 多目标跟踪算法提取的行人原始轨迹簇,结合行人过街的完整过程,本文定义一种“准静态轨迹”,这类轨迹源于目标跟踪算法对监控视野内存在的目标无差别地展开跟踪,从而捕捉到行人驻足等待红绿灯或者在路缘带上逗留等原地驻足或小幅度徘徊行为的轨迹,在图像中,这类轨迹分布在以某特定点为圆心的小半径圆域范围内。相对于行人过街的正常轨迹,准静态轨迹无明确方向性,缺乏对行人过街轨迹移动的整体趋势和OD 等语义信息描述,若不予剔除,将对后续行人过街行为的空间起点、终点等OD语义特征的提取和分析引入噪声干扰。
协方差(covariance)可衡量随机变量观测值之间的变化程度,本文将其用以判定一个轨迹样本是否属于准静态轨迹。对于行人目标j,选取特征描述子xc、yc分量,构成目标j的运动轨迹,每个轨迹点表示为一个坐标对(xt,yt),t=1,2,3,…,n,n是目标j在视频中出现的总帧数。所有轨迹点的x分量和y分量构成两个向量X、Y,X=(x1,x2,x3,…,xn)和Y=(y1,y2,y3,…,yn),计算X、Y的协方差矩阵Σ,即

式中:Varregularized(X)和Varregularized(Y)是为了消除轨迹长度的影响,对X和Y向量的原始方差进行规范化的结果,即

理论上,若某个轨迹为准静态轨迹时,该轨迹X向量的方差Varregularized(X) ,Y向量的方差Varregularized(Y)以及X、Y的协方差Cov(X,Y)等指标值将明显小于正常轨迹情况下对应的指标值。
为了从原始轨迹簇中针对性地筛除准静态轨迹,根据协方差矩阵中元素值的分布特点,本文提出一种时空坐标协方差滤波算法STCCF(Spatial-Time Coordinate Covariance Filtering)。C0、C1分别表示原始轨迹簇、准静态轨迹簇所构成的集合,滤波流程如下:
(1)初始化判别阈值Gx,Gy,Gco(协方差、方差阈值)。
(2)遍历C0中的各样本Ti,计算Ti的协方差矩阵元素值 Varregularized(TiX)、 Varregularized(TiY)、Cov(TiX,TiY);若(Varregularized(TiX)<Gx⋃Varregularized(TiY)<Gy)⋂(Cov(TiX,TiY)<Gco),则C0=C0Ti,C1=C1⋃Ti。
(3)遍历结束,输出C0。
其中,对各轨迹样本分别计算如式(12)所示的协方差矩阵,绘制协方差矩阵中Varregularized(X) 、Varregularized(Y)、Cov(X,Y)等参数的散点图,根据散点图中的数据分布规律特征,能将准静态和非准静态轨迹对应的参数数据点分离的数值即为对应的判别阈值Gx,Gy,Gco。
基于上述分析,计算原始轨迹簇中X和Y坐标的协方差矩阵。对比计算结果发现,若轨迹为准静态轨迹时,轨迹点高度集中分布,X、Y序列之间的相关性弱,轨迹的X向量方差Varregularized(X),Y向量方差Varregularized(Y) 以及X、Y的协方差Cov(X,Y)等指标值均显著低于正常轨迹对应的指标值。由此,通过阈值判断,剔除准静态轨迹,得到清洗后的轨迹簇,用于后续轨迹数据分析和特征提取工作。两类轨迹典型形态如图3所示。
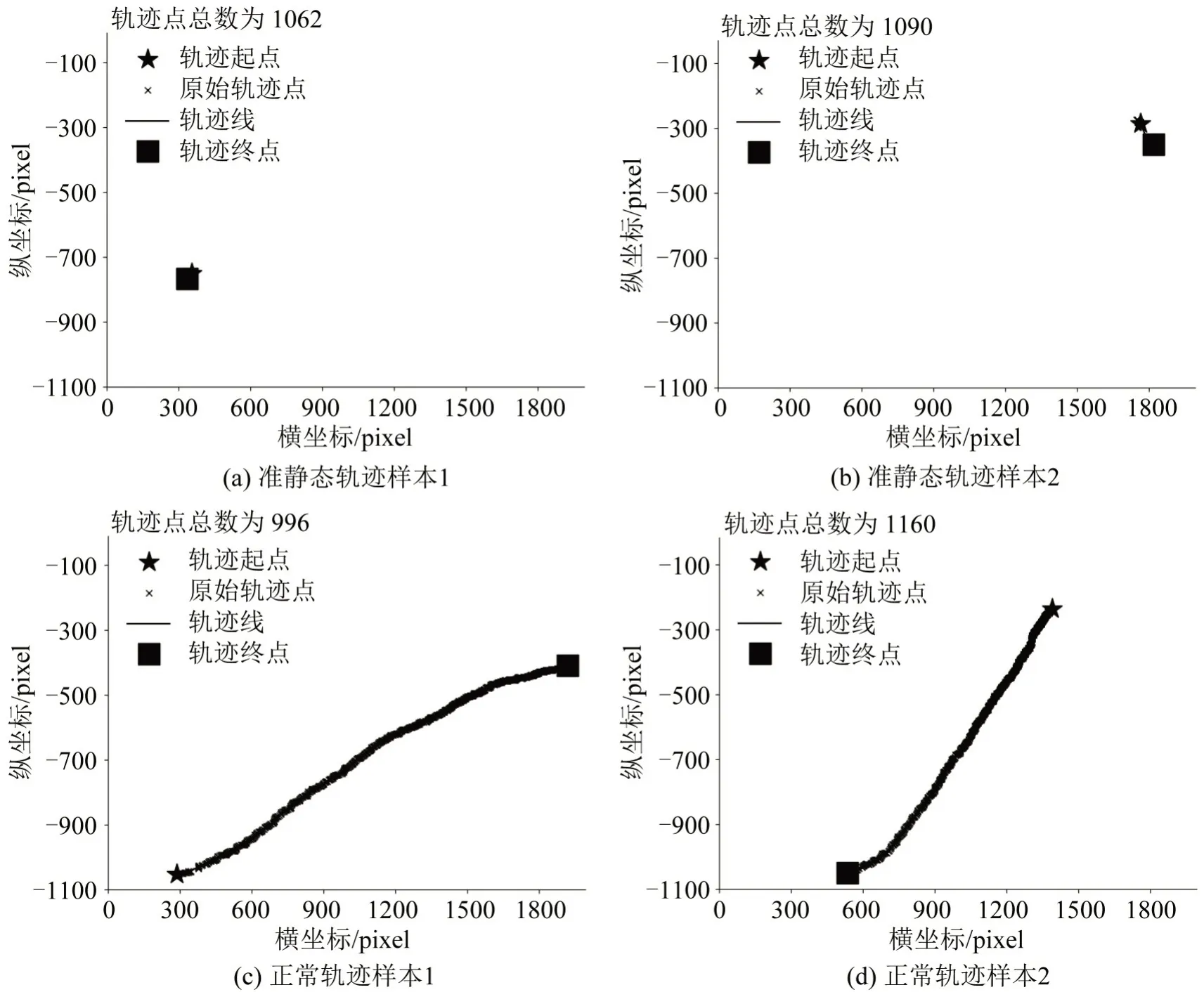
图3 准静态与非准静态轨迹形态对比Fig.3 Comparison between quasi-stationary and normal trajectory samples
图3(a)、(b)为视频中位于人行横道两侧的准静态轨迹样本,图3(c)、(d)为正常轨迹样本,两类轨迹在空间形态上有明显区别(图中所有坐标系均为同一个像素坐标系)。值得注意的是,若捕获的行人轨迹同时包含准静态阶段和正常过街阶段,该轨迹整体的协方差矩阵参数值亦显著区别于单纯的准静态轨迹,因此,本文STCCF算法将选择性地滤除单纯的准静态轨迹。
3.2 基于K-means聚类的轨迹语义特征解析
对于监控场景,行人目标轨迹反映其运动的状态,大量目标个体轨迹构成的轨迹簇,隐含了该场景中目标的“源点”“消失点”等具有统计性描述意义的语义特征信息,对应行人过街行为的空间起点、终点,表征行人群过街行为发生的源头和行人过街的去向。本文将行人进入监控视野和离开监控视野分别定义为事件A和事件B,基于概率统计原理,设事件A、事件B发生频率最大的位置为“源点”及“消失点”。在特定场景下,源点和消失点是相对固定的,如图4(a)所示,在人行横道上,正常情况下行人产生过街行为的起点、终点位置多分布在人行道的两端,若某时刻某个行人轨迹的“源点”“消失点”出现较大的变动,如图4(b)所示,可认为目标存在异常过街行为。本节采用K-means算法,从大量轨迹簇中解析出“源点”“消失点”等语义信息,后续可进一步用于数据驱动的行人轨迹建模分析或行人异常轨迹检测。
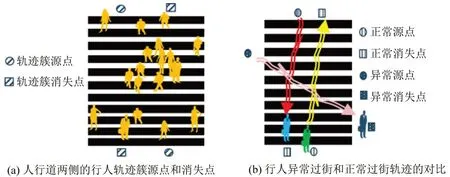
图4 多目标运动语义信息Fig.4 Illustration of multi-object motion semantic information
对于每一个目标i,从前述定义的特征描述子中的Si提取前3 帧和末3 帧的质心坐标xci,yci,i=1,2,3,n,n-1,n-2,取均值作为该目标运动轨迹的源点oi和消失点di。设集合O和D为源点集和轨迹集,分别包含多目标跟踪算法捕获的原始轨迹(包括准静态轨迹)的所有源点和消失点。

K-means 算法是无监督机器学习算法,将一系列数据点划分为若干类。包含以下步骤:
Step 1 给定一包含了z个样本的数据向量X(x1,x2,…,xj),xj∈Rn(j=1,2,3,…,z),期望将样本聚类成K个类。
Step 2 随机选取K个聚类中心,分别是{μ1,μ2,…,μK} ,μ(j)∈Rn(j=1,2,3,…,K)。
Step 3 针对每个样本xi,遍历计算它与第j个聚类中心的距离,j=1,2,3,…,K,与之距离最小的那一类视为该样本所属的类 ,
Step 4 遍历所有样本,计算它们所属的类,并通过更新聚类中心为

式中:1{·} 为二值判别式,条件为真时该判别式(19)取值为1;否则,取值为0。
Step 5 重复循环Step 3 和Step 4,直至式计算的聚类中心收敛,并输出收敛时的聚类中心。
本文算法提取语义特征的关键是确定场景中行人目标源点和消失点的最佳数量和位置,为实现该目的,引入轮廓系数S(Silhouette Coefficient)和DB指数(Davies Bouldin Index)两种指标。定义聚类后的每一个类ζ(ζ=1,2,3,…,K)的轮廓系数Pζ为
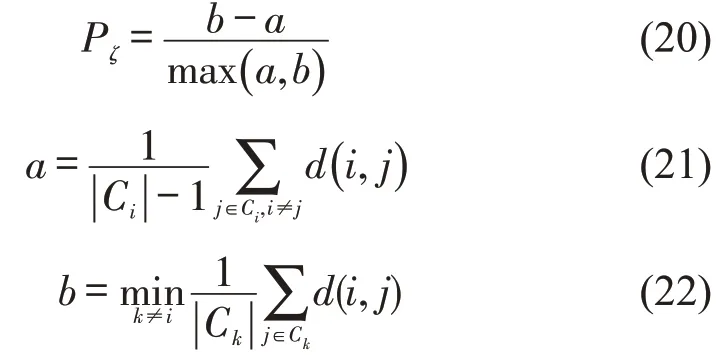
式中:d(i,j)为第i个样本和第j个样本的距离;|· |为某个类中的样本数量;a为遍历属于类Cm的任意一个样本点i,计算它与类内其他所有样本点距离的均值,a衡量了属于同一聚类簇内样本数据的相似度;b为遍历属于类Cm的任意一个样本点i,计算每一个样本点与距离最近的一个聚类中心Ck所对应的那一类中所有样本点的距离,并取所有距离的均值,b衡量了属于不同类样本数据彼此间的差异度。在b值计算过程中,类与类之间距离的衡量依据是类中心点之间的欧氏距离,即

式中:Ωi、Ωj为类i、类j的中心点;Di,j为类i和类j的欧氏距离。
对全体数据的聚类结果,S 系数(Silhouette Coefficient)定义为

设一个含N个数据点的集合,聚类算法将其划分为K个类,DB指数定义为

式中:Ωζ为第ζ个类的中心点;为第ζ个类中所有样本到该类中心的距离的平均值。
4 实验设计与结果分析
为验证多目标跟踪FairMOT 框架及K-means聚类行人轨迹提取方法的有效性,本文实验介绍行人多目标跟踪和运动轨迹提取的视频监控数据,针对多目标跟踪FairMOT框架进行二次训练,提取视频中的行人运动轨迹;应用本文所述的协方差滤波算法,剔除准静态轨迹,实现数据清洗;依据S指数和DB 指数判定基于K-means 的最佳聚类数量,提取行人运动轨迹簇中的语义特征。
4.1 视频监控数据概述
为获取足量行人目标轨迹样本,视频监控视角选取市区中心行人流量较大的平面道路交叉口。实验中的视频监控序列取自网络上公开的实时监控数据,位于日本东京都新宿区西新宿1 丁目(139.70°E,35.70°N)的一个高位监控视角,全天候捕获1 个标准4 路交叉口十字路口的实时路况,视频监控设备位于东出口处。该位置的地图、卫星俯视图和实景监控视角如图5所示。

图5 实验中选取的监控视角地理位置和实景图Fig.5 Demonstration of location of road side surveillance scenario
4.2 模型训练基本配置
训练FairMOT目标检测分支网络用到的设备:操作系统windows10,CPU 为Intel Core i5 6500,内存为DDR4 16 G,GPU 为Nvidia RTX2060S(8 G),训练环境为pytorch1.2.0,torchvision0.4.0。
4.3 FairMOT二次训练
城市路侧监控视角下,密集小目标行人群场景较常见,为提高FairMOT对密集行人小目标的检测和跟踪能力,使算法提取到更完整、更充足的轨迹数据,本文选取旷视科技的开源数据集CrowdHuman 对目标检测分支CenterNet 部分的网络进行训练。该数据集拍摄的视角包括水平拍摄和高位拍摄,场景涵盖都市区步行街、游行、聚会等高密度人群的场景,平均每张图片包含22.64 个人类个体。CrowdHuman 与目前用于行人检测的开源数据集相比,在单张图片包含的人类个体数、人类个体动作姿态的多样性等指标上明显更优。
目标检测分支采用Centernet网络,其主干网络选取在COCO数据集上预训练的DLA-34模型。选取CrowdHuman开源数据集中的15000张图片作为训练集,4370 张作为测试集,对DLA-34 网络结构进行二次训练,设置训练轮数为30 轮,batchsize 为2,采用学习率递减的策略,初始学习率为10-4,每迭代满20 个epoch 时学习率衰减为原来的10%。优化器为Adam,其余的训练超参数设置参考CenterNet开源模型[13]中的建议值,如表3所示。

表3 多目标跟踪网络训练参数设置Table 3 Hyperparameters for training multi-object tracking network
训练时的损失函数、目标检测的平均精度(mAP)和召回率(Recall)随训练轮数的变化曲线分别如图6~图8所示。从总的训练损失看,虽然训练5轮之后网络总的损失函数已基本收敛,但第20轮时调整模型学习率后,总损失仍有小幅度下降。

图6 FairMOT目标检测分支训练轮数-损失值变化曲线Fig. 6 Curve of loss function value versus training epoch of object detection branch in FairMOT

图7 FairMOT目标检测平均精度变化曲线Fig.7 Curve of FairMOT object detection branch mAP versus training epoch

图8 FairMOT 目标检测平均召回率变化曲线Fig.8 Curve of FairMOT object detection recall versus training epoch
hm_loss、id_loss、offset_loss 和wh_loss 这4 个损失值随训练轮数变化曲线如图9所示。纵轴为各项损失值,横轴为训练轮数。在轮数为20时,模型训练学习率从10-4调整为10-5,因而,曲线出现不同程度的抖动,随着训练的推进,各损失值再次呈现下降趋势,且在20轮之后的训练中,各项损失值曲线趋于平缓,可认为模型训练逐渐逼近收敛态。
图9 训练过程中损失函数各项损失值时变曲线Fig.9 Time-varying curve of each loss function component during training
考虑到从20 轮开始,训练的各项损失函数值变化逐渐趋缓,为确定最佳的网络训练权重,综合对比分析训练20 轮之后模型的平均精度和召回率,如图7和图8所示,第30轮时平均精度mAP最高,达0.5772,召回率达0.6794,仅次于27 轮的0.6797。因此,选取第30 轮训练所得的权重载入FairMOT目标检测分支,二次训练后的FairMOT将对整个视频监控场景(包括:靠近摄像头一侧的人行道,距离摄像头较远的人行道)内的行人个体实施目标跟踪和轨迹捕获,输出目标出现在监控视野时段内的运动轨迹时序特征描述子。
实验中,城市平面交叉口人行道高密度、小目标行人场景下,模型跟踪性能达7.2 frame·s-1。CrowdHuman数据集二次训练前、训练后模型的检测性能对比如图10所示。小矩形方框包围的区域表示算法检测和跟踪的行人目标。

图10 CrowdHuman数据集训练前、后模型对高密度、小尺寸行人群目标检测效果对比Fig.10 Trained and untrained model performance comparison in dense crowd and small pedestrian target scenario
图10(a)、(c)对比结果显示,经二次训练后的模型,在距离摄像头较远、目标密度较大、目标尺寸较小的条件下,仍可检测出视野中的行人目标;图10(b)、(d)对比表明,本文引入的二次训练提高了模型在距离摄像头较近的接近垂直视角下的密集行人群检测能力,使模型从视频中提取到的目标轨迹鲁棒性更强。
利用FairMOT 算法提取视频帧中人行道上的行人目标运动轨迹,共提取2689 条行人轨迹。实验发现,距离摄像头较近一侧人行横道上的目标运动特征更加明显,该区域轨迹长度比其他方位人行横道区域中的目标轨迹更长,包含更丰富的时序运动特征,更利于数据驱动的轨迹建模分析。因此,本文设置了场景中的感兴趣区域AOI(Area of Interests),如图11所示。

图11 视频监控场景中AOI以及完整场景下的轨迹跟踪结果Fig.11 AOI in surveillance scenario and whole trajectory tracking results
图11(a)中感兴趣区域范围内的行人目标运动轨迹,作为后续数据驱动的轨迹预测建模的样本;提取整个视频视角内行人轨迹语义特征时,选用整个监控视频区域内提取到的2689条行人目标运动轨迹。
4.4 轨迹簇协方差滤波
实验中使用滑动平均滤波法[14]对轨迹坐标序列进行平滑,消除轨迹的毛刺。对原始FairMOT算法输出的2689 条轨迹进行协方差滤波处理,经实验反复尝试,最终阈值的设置如表4所示。

表4 轨迹坐标协方差滤波法参数设置Table 4 Parameters setting in trajectory coordinate covariance filtering algorithm
在上述阈值参数设定下,算法筛选出179条判断为准静态轨迹的样本,经统计分析,有219 条准静态轨迹,算法检出率为81.73%。造成漏检的主要原因是:由于阈值设置是综合考虑了各个轨迹的数据取值范围等分布规律后设定的固定阈值,靠近摄像头区域的目标成像相对较大,准静态轨迹在图像中占据更大的像素范围,相应的坐标协方差参数超过阈值的可能性也相应增加,导致在统一的阈值设定下,算法将部分位于近景处的准静态样本识别为正常轨迹(图12(a)中的虚线箭头),距离较远的则被成功识别(图12(b)中实线箭头)。后续将考虑引入场景语义分割掩膜,精细化地将场景分块,对处于近景处和远景处的轨迹采用不同的固定阈值,以进一步提高准静态轨迹的检出率。

图12 近景处和远景处准静态轨迹示意图Fig.12 Demonstration of near view quasi-stationary trajectory and far view quasi-stationary trajectory
为验证本文将协方差矩阵参数作为准静态轨迹判据的可行性,针对成功识别出的准静态轨迹和正常轨迹两类轨迹,分别提取并统计其中若干样本的坐标协方差数值分布特征。如图13所示。两类轨迹的协方差矩阵参数具有不同的数值分布特征,证明了本文所提出的协方差滤波方法的有效性。

图13 准静态轨迹与正常轨迹的坐标协方差参数值特征对比Fig.13 Comparison of coordinate covariance values between quasi-stationary trajectories and normal trajectories
4.5 K-means聚类轨迹簇语义信息提取
将提取得到的轨迹簇作为K-means 算法的输入,待聚类的样本数据分别是前述的源点集O和消失点集D,实验中设置不同的聚类数k,k∈[2,15] ,为了简洁,源点聚类的部分结果如图14所示,图中标记位置为算法解析出的聚类中心。

图14 不同聚类数下的轨迹源点-消失点聚类结果Fig.14 Source-Vnishing point results with different clustering number
k∈[2,15] 对应的S 系数和DB 指数曲线图如图15所示。
图15(a)为源点聚类的S 系数和DB 指数随聚类数的变化曲线,图15(b)为消失点聚类结果的S系数和DB指数随聚类数变化的曲线。轮廓系数S取值范围为[-1,1],聚类结果中同类别样本距离越近,不同类别样本距离越远,聚类效果越好,S越接近于1;通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与观测数据中心点距离平方和来度量观测数据的分离度,DB指数计算不同聚类簇之间的相似度,DB指数越小,类间相似度越小,聚类效果越好。
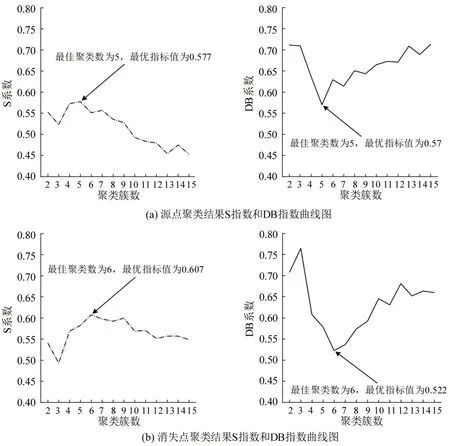
图15 不同聚类数对应的S指数和DB指数曲线Fig.15 Coefficient and DB index-cluster numbers curves
对于源点聚类,聚类数k=5 时,S 系数达到峰值0.577,DB 指数达到最小值0.57;对于消失点聚类,聚类数k=6 时,S系数达到峰值0.607,DB指数达到最小值0.522,因此,认为实验选取的视频监控中行人源点有5 处,消失点有6 处。分别将源点和消失点聚类中心坐标提取出来,绘制在视频监控图像上,得到对应实景图中的行人源点和消失点如图16所示,图中圆形和三角形标记区域为K-means算法输出的聚类中心位置。

图16 聚类算法输出视频监控中的行人源点和消失点Fig.16 Source and vanishing points generated by clustering algorithm
该监控场景下行人源点和消失点在西北角处有差异,其余5个位点处源点及消失点几乎成对出现。通过人工观察分析,产生差异的原因如图17所示(为简洁,仅绘制出导致差异的行人流线)。图17中,虚箭线表示沿该方向过街的人流量少,实箭线意义相反。图中编号②和③两股行人流流量悬殊,故A处存在由编号②的行人流构成的消失点,而无相应的源点;而B处既存在由编号①的行人流构成的消失点,也存在由编号②的行人流构成的源点。
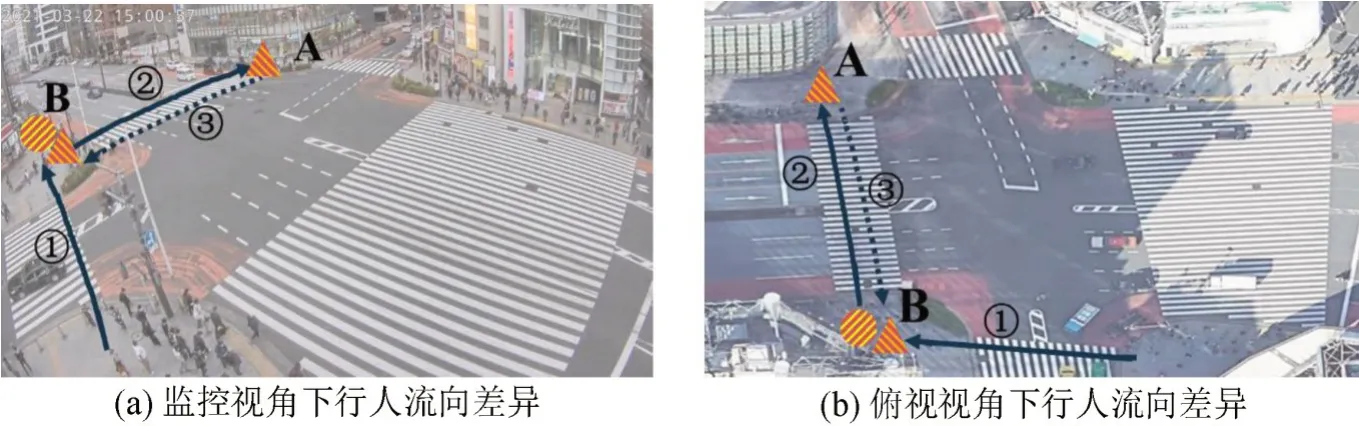
图17 行人流的方向性导致的源点-消失点匹配不平衡现象Fig.17 Illustration of unbalanced source-vanish points caused by directional pedestrian flows
通过基于多目标跟踪的轨迹数据聚类过程,挖掘大量的轨迹数据点和轨迹数据本身所包含的空间分布规律,提取出场景中人行道上行人源点和消失点,理解并解析出整个轨迹数据簇所包含的一种内在场景语义信息。本文算法和重点旨在自动地从城市平面交叉口人行道视频监控场景下,提取密集小目标行人群过街行为的轨迹,并感知行人流过街起点和终点,便于后续重点关注的源点-消失点区间范围内的轨迹,排除其余的无关片段,按照轨迹经过不同的源点-消失点进一步划分不同OD的轨迹集,针对性地分析各子集内的轨迹特性,以及在轨迹预测建模时,引入OD 先验信息等,提高行人过街行为分析的精度和细粒度。
本文的方法对不同交叉口监控视角均具有适用性,主要聚焦于密集小目标场景下的跟踪、跟踪结果数据语义特征信息的挖掘,减少人为的轨迹区域划定,轨迹起点、终点标定等主观干扰,所提取的语义信息立足于场景中行人个体的真实行为轨迹数据,在后续行人过街行为预测建模、异常过街行为检测等工作中提供先验判据。
5 结论
针对现有密集行人群相互遮挡、目标成像小、特征不突出,运动识别和轨迹提取较困难,场景中的运动语义信息分析不足等问题,本文借助密集人群数据集CrowdHuman训练后的FairMOT框架,从视频中提取密集行人群运动轨迹簇,提出协方差滤波算法STCCF 清洗原始轨迹簇,依据S 系数和DB指数确定最佳K-means聚类簇数,实现运动轨迹的语义感知。
实现城市平面4 路交叉监控场景下密集过街行人群的识别和跟踪,算法速度达7.2 frame·s-1,提取出2689 个行人目标的轨迹,存储为二维空间坐标的形式,算法检出和筛除179 条准静态轨迹,减少了轨迹集的数据噪声。本文从统计学概率角度,定义运动语义,利用K-means 算法,通过S 系数和DB 指数确定最佳的聚类数,对大量的行人目标轨迹簇的起点和终点进行聚类分析,并解析出该交叉路口场景中的5 处行人源点和6 处行人消失点,与人工判别的结果吻合,在未知视频场景中目标运动的起点、终点的条件下,自动剖析轨迹数据隐含的特征,合理地估计行人过街聚集和消散的区域。
本文利用多目标跟踪算法,从路侧交通监控视频中,提取出密集行人群过街的轨迹数据,考虑行人实际过街行为过程的细节,剔除准静态轨迹等异常数据,解析场景内行人流源点、消失点等运动语义,从场景中提取可供行人过街行为建模的原始轨迹数据集,验证了目标跟踪-轨迹提取-数据驱动建模的技术路线的可行性。
