一种基于图像内容和遗传编程的决策机制
2021-12-30贾保柱钟正一卫寒泽刘荣荣王群
贾保柱 钟正一 卫寒泽 刘荣荣 王群

摘要:通过自主学习和进化演变,通用型智能体能够在几乎没有领域相关知识的状态下适应不同的场景。其中的挑战之一就是如何设计一种通用方法从场景中捕捉该场景的状态特征。本文提出了一种进化策略,通过采用遗传编程直接从原始图像中演化出状态特征,进而使用投票机制决定智能体的行为。
关键词:通用型人工智能,遗传编程,图像内容
Through autonomous learning and evolution, the general purpose intelligent agent is able to adapt to different environments with little domain knowledge. One of the greatest challenges is to develop a general approach for extracting state features out of different scenes. We introduced a new method which uses genetic programming to evolve state features from raw images. A voting method is involved to determine the behavioral strategy of the agent.
Keywords: General artificial intelligence, Genetic programming, Image Content
1. 背景
近些年来,人工智能得到了爆发式的发展。尤其是在医学图像领域,人工智能在某些细分方向上已经达到或者超越了人类的表现。例如,Diego Ardila 等人[1] 在2019年提出了一种用于识别肺部肿瘤CT扫描的深度学习模型。该模型在肺癌筛查实验中的准确率达到了94.4%,已经优于与团队合作的六名资深放射科医生的判断准确度。与此同时,有大量研究成果也表明,最先进的人工智能模型在眼科的临床诊断和分析能力上均高于中等水平的眼科专家 [2, 3]。然而,不容忽视的是,这些模型都是针对某些特定应用领域而专门设计的。也就是说,在一个应用场景内训练得到的模型是无法在另一场景中使用的。為解决这一难题,研究人员提出了多种思路,其中通用型人工智能这一方向逐渐成为诸多学者竞相追逐的热点。
2. 相关研究
自2005年起,AAAI每年都会组织通用型人工智能游戏比赛。蒙特卡洛树搜索(Mento-Carol Tree Search)很早就在通用游戏对弈(General Game Playing)中证明它具有强大的搜索能力。
Naddaf 等在Atari 2600 主机游戏中引入了两个无模型的 AI 智能体。一个智能体使用强化学习,另一个使用蒙特卡罗搜索树。2015 年,DeepMind在视频游戏Atari 2600 中使用了Deep Q-Network。这种新型网络结合了深度学习和强化学习,在多项游戏测试中都达到了人类玩家的智能程度。2016年,DeepMind创造的AlphaGo击败了顶级围棋选手李世石。本文主要从自主学习角度出发,利用遗传策略训练了一个可以自主学习游戏特征表示的方法。
3. 内容
3.1应用场景介绍
基于GVG-AI 的游戏引擎能够实现多项类似 Atari 2600 的游戏。我们使用由该引擎驱动的三款不同的游戏来测试我们的视频游戏智能体,分别是太空入侵者、青蛙和导弹司令部。太空侵略者是一款经典的街机游戏。外星人驾驶太空船从屏幕上方向下入侵。玩家控制屏幕底部的一把枪。枪口垂直向上射击抵御入侵的太空船;游戏蛙是一款经典游戏。屏幕中有一只青蛙在过马路。玩家将青蛙从屏幕底部移动到位于屏幕顶部的目标位置即可获胜。玩家的任务是保证青蛙在过马路时必须时刻注意不被往来的汽车撞到;在导弹司令部游戏中,玩家需要使用智能炸弹来摧毁来袭的弹道导弹。玩家决定下一个智能炸弹将在什么位置爆炸。智能炸弹会摧毁一定半径内的所有来袭的导弹。
4. 应用场景的状态特征提取
4.1场景的状态特征的进化
我们用树结构表征一个遗传编程对象,并用ECJ 包实现了遗传编程算法。游戏引擎通过 TCP/IP 协议与 ECJ 通信,将每一步的屏幕截图发送到 ECJ,经程序计算后,将下一步需要进行的动作返回给游戏引擎。
表 1 展示的是本文中用到的终端集合。所有终端返回的都是 Image 类型的对象。每个终端的返回值对应了游戏画面截图的一个通道:红色通道、绿色通道、蓝色通道、黄色通道和灰色通道。其中红、绿、蓝通道可以从屏幕截图中直接获得,黄色和灰色通道由红、绿、蓝三个通道计算得到。
4.2 行动投票机制
本文中,遗传编程搜索树的输出是一个与输入图像大小相同的图像。我们在输出结果中搜索最大值 (Vmax) 和最小值 (Vmin) 的位置。最大值对应的点被标为游戏的目标位置。最小值对应的点被标为对游戏玩家角色的潜在威胁的位置。智能体的行为由两个方面决定:第一,它应该始终朝着目标前进;同时,它还应该密切关注潜在威胁。一旦潜在威胁进入玩家角色周围的某个区域,智能体就会发出使玩家角色远离威胁的指令。
5. 结果
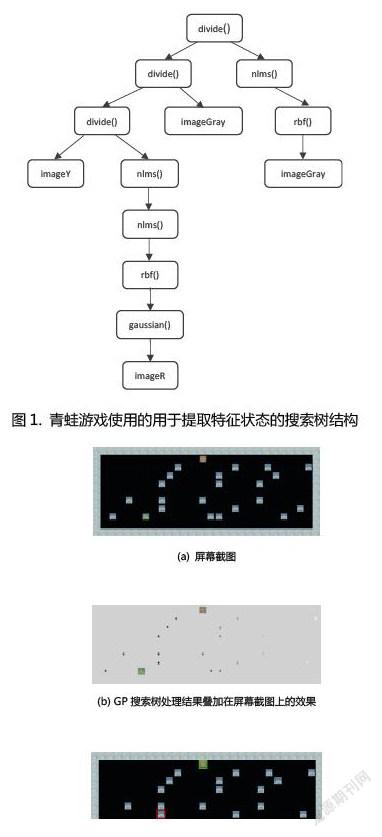
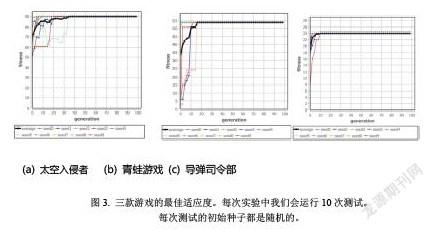
图1展示的是用于提取青蛙游戏中的状态特征的搜索树结构。输入图像是屏幕截图经等比例缩小后得到的。搜索树的返回值也是一个图像,如图2所示。我们在返回的图像中搜索最大值和最小值,然后将这两个值对应的点叠加在原始屏幕截图上。最大值用绿色矩形标记,最小值用红色矩形标记。在图中,我们可以看到具有最大值的点是青蛙期望的家的位置。具有最小值的点是对青蛙最危险的汽车所在的位置。 图 3展示的是三款游戏中最佳个体的适应度。针对每款游戏,我们进行10 次测试。每个游戏的最佳个体的平均适应度以粗线显示。
6. 结论
在本文中,我们使用遗传编程技术训练了一个智能体,可以直接从原始图像中学习场景的状态特征。遗传编程智能体的输入是当前游戏状态截图的各颜色通道,通过计算输出一个二维特征矩阵。在该特征矩阵中,最大响应点和最小响应点分别对应了期望的目标位置和可能存在威胁的位置。算法采用投票机制最终确定智能体下一步的规划。我们在三个不同的场景中对本文所提出的算法进行了测试。结果表明,与使用人工提取特征的算法相比,该算法能够更快地找到最优的策略。
参考文献
1. Ardila D, Kiraly AP, Bharadwaj S, Choi B, Reicher JJ, Peng L, Tse D, Etemadi M, Ye W, Corrado G, Naidich DP, Shetty S. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nat Med. 2019 Jun;25(6):954-961.
2. Ting DSW, Pasquale LR, Peng L, Campbell JP, Lee AY, Raman R, Tan GSW, Schmetterer L, Keane PA, Wong TY. Artificial intelligence and deep learning in ophthalmology. Br J Ophthalmol. 2019 Feb;103(2):167-175.
3. Keane PA, Topol EJ. With an eye to AI and autonomous diagnosis. NPJ Digit Med. 2018 Aug 28;1:40.
作者簡介:姓名:贾保柱,性别:男,出生年月:1987.05.13,籍贯:山东,学历:博士,职称:副研究员,单位:中国科学院苏州生物医学工程技术研究所,研究方向:人工智能。姓名:钟正一,性别:男,出生年月:1997年11月,籍贯:四川成都,学历:本科,单位:中国科学院苏州生物医学工程技术研究所,研究方向:电子电气工程。
姓名:卫寒泽,男,出生年月:1996.11,籍贯:山西临汾,学历:学士,单位:中国科学院苏州生物医学工程技术研究所,研究方向:电子电气工程。
姓名:刘荣荣,性别:男,出生年月:1999年2月,籍贯:江西赣州,学历:本科,单位:中国科学院苏州生物医学工程技术研究所,研究方向:电子电气工程。
基金:国家重点研发计划(2019YFC0118004)资助的课题
