一种基于离线深度强化学习的工业控制优化方法
2021-12-30华电忻州广宇煤电有限公司高亚磊郝政忠李继平
华电忻州广宇煤电有限公司 高亚磊 郝政忠 李继平
1 工业控制自动化现状与发展趋势
我国工业控制自动化的发展道路,大多是在引进成套设备的同时进行消化吸收,然后进行二次开发和应用,目前工业控制自动化技术正在向智能化、网络化和集成化方向发展。智能化主要归结于人工智能技术的发展与应用,如运用神经网络、遗传算法、进化计算、混沌控制等智能技术,使仪器仪表实现高速、高效、多功能、高机动灵活等性能;再如运用模糊规则的模糊推理技术,对事物的各种模糊关系进行各种类型的模糊决策;又如充分利用人工神经网络技术强有力的自学习、自适应、自组织能力,联想、记忆功能以及对非线性复杂关系的输入、输出间的黑箱映射特性等。而人工神经网络中的深度强化学习最适合用于工业控制自动化,实现智能化。
深度强化学习是深度学习与强化学习相结合的产物,集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了端到端学习。深度强化学习的出现使得强化学习技术真正走向实用,得以解决现实场景中的复杂问题。过去几年间,深度强化学习算法在不同领域大显神通:在视频游戏[1]、棋类游戏上打败人类顶尖高手[2];控制复杂的机械进行操作[3];调配网络资源[4];为数据中心大幅节能[5];甚至对机器学习算法自动调参[6]。控制领域是强化学习思想的发源地之一,也是强化学习技术应用最成熟的领域。一个常见的例子是使用人工智能来调优机器和设备,在这之前这些工作需专家级操作人员才能完成。如DeepMind 的强化学习技术帮助Google 显着降低了其数据中心的能耗(HVAC)[5]。
2 传统工业控制优化的弊端
依赖现场试验。传统优化方法主要通过在现场试验中收集不同工况、控制策略下的运行情况数据,结合机理、经验公式进行优化。在大部分情况下,为了收集机理、经验公式要求的相应数据需额外加装传感器测点,或多或少牵扯到技术改造。项目投入大、试验数据收集费时费力,成本高,设备改造对实际的生产运行影响也较大。基于深度强化学习的方法只需使用运行一段时间内的历史数据,依赖于已有数据,不涉及加装及硬件改造,成本低,对正常运行影响小。
基于物理方程和机理模型。传统控制优化方法主要基于物理方程及机理进行建模,包含大量经验、假设性的参数。传统控制优化方法过于依赖设备原有的设计参数,然而设备在运行一段时间后,其真实运行参数必然会相较出厂设计参数有一定的偏差,造成对系统描述的失准。此外传统方法建模过程过于理想化,缺乏对设备真实数据的利用和考虑。基于深度强化学习的方法充分使用真实运行的历史数据,在建模过程中较少依赖机组设计参数,不加入额外假设或经验性参数,从数据本事直接学习系统真实的变化特征,对于系统刻画描述的能力更强。
工况适应性差。传统控制优化方法建立的模型一旦完成、基本是固化的,不具备自学习能力及适应后续工况变化的可调节性。然而设备的工况每天都会因为损耗、材料特性的改变产生微小的工况变化,长期积累下来必然会导致原有固化模型的失准,如需重新适应新的工况特性、则需重新建模。基于深度强化学习的方法因为纯数据驱动,模型本身具备可学习性及很强的适应能力。在工况发生变化后,只需收集最新的历史运行数据、在原有模型参数的基础上进行再训练和调整,即可适应最新的工况特性。
拆解成子系统用简化模型优化。大部分控制优化问题本身复杂性高,传统方法解决优化问题主要将整个系统拆解成多个简化的子系统、子模块,然后对每个子系统的少量控制变量做局部优化以达到优化目的。然而此种建模方法过度简化,缺乏对系统整体建模的考虑,忽视了各子系统之间复杂的交互影响。此外每个子系统达到最优、无法保证系统的全局最优,甚至单一子系统本身的优化可能对其他子系统产生不良的影响。基于深度强化学习的方法对系统进行整体性建模,不做子系统拆解,最大程度上考虑各子系统之间复杂的依赖、影响关系。通过对整个系统的优化目标进行寻优,保证控制量推荐结果的全局最优。
3 离线深度强化学习算法框架
实际应用环境中往往需要满足一定的安全限制条件,本文引入安全价值模型来评估当前策略的安全风险,在优化策略的同时满足安全需求。本算法由数据驱动、以最大化长期价值为目标,同时受限于安全约束,定义为受限的高维动态优化问题。本方法完全基于真实离线数据集,通过安全约束和受限的策略探索方法学习出安全有效的策略。
首先构建基准策略分布网络,使用真实数据训练、得到历史策略的分布,作为强化学习算法的基准。然后分别构建奖励价值网络和安全风险网络用于评估策略的长期价值和安全风险。模型训练使用真实数据,首先从基准策略中采样得到基准动作,然在基准动作基础上用扰动网络进行探索,通过价值网络评估探索策略的价值和风险,最后通过最大化长期价值和最小化风险为目标进行训练迭代,得到最优策略。本方法的最优策略是在历史策略的安全范围内进行有效探索得到,分布更接近历史策略分布,最大化价值的同时保证满足安全约束条件,可以满足工业控制领域的需求。
首先从真实数据中采样一定数量的样本训练基准策略模型。基准策略模型只用真实数据训练,不是最优的策略但可以反映真实数据的分布,然后用扰动网络进行探索、得到最优策略。基准策略模型优选方案是使用变分编码器VAE(Variational Auto-encoder)。VAE 由两部分的网络构成,一部分称为encoder,从一个高维的输入映射到一个低维的隐变量上;另外一部分称为decoder,从低维的隐变量再映射回高维的输入。分为模型训练阶段和采样阶段,训练阶段模型输入为当前状态s 和执行的动作a,输出为动作a,encode 和decoder 两个部分协同训练;采样阶段只使用decoder 部分批量采样一定数量的样本。
接着,从样本池中采样一定数量的样本,在每个样本的状态下,从基准策略分布中采样得到基准动作,在基础动作基础上通过扰动策略网络进行探索。按照一定的比例,将扰动添加到基准动作上、产生探索动作。然后用奖励价值网络评估探索动作的长期价值,用安全价值网络评估探索动作的安全风险。以最大化长期价值和最小化安全风险为目标,通过策略梯度的方法来训练扰动网络。目标如下:
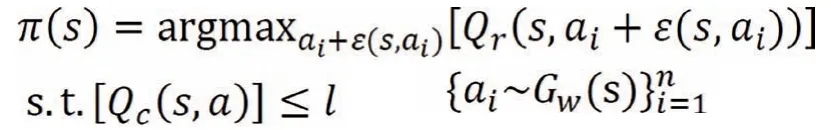
其中,Gw是生成模型(本文中为VAE 模型),结合价值网络Qr可作为策略使用,从Gw采样得到n个动作,再用Qr筛选出价值最高的动作。为了增加探索,用扰动网络εφ(s,a,φ)生成在范围[-φ,φ]内针对动作的调整,扰动网络提供了安全区域内的有效探索。Qr,Qc分别为奖励价值网络和安全价值网络,l 为安全约束。
最后,从样本池采样一定数量的样本训练学习策略模型、奖励价值模型和安全价值模型。训练方法采用经典的“演员-评论家”(actor-critic)方法,通过在单步转移数据(s,a,r,s)上最小化贝尔曼误差(Bellman errors)来学习一个动作值函数,然后通过最大化动作值函数来进行策略更新。奖励价值函数的目标为: ,其中D 为经验池,Qr为所要学习的奖励价值网络,Q 表示目标价值网络,按照目标函数进行交替迭代训练。同理可得安全价值函数的目标。
本算法已实际应用于华电忻州广宇煤电有限公司50MW 超临界参数燃煤汽轮发电机组的锅炉燃烧优化系统中。自2020年12月全部开发调试完毕,进入上机实测阶段。在2021年1月份进行了多批次、多负荷段、多工况场景的上机实测。测试中离线强化学习算法运行稳定、性能可靠,优化价值凸显。优化系统可及时提供提高锅炉效率的调整方向,能够使机组在调整后锅炉效率得到提升。按提供的控制指导策略进行机组运行控制时,能够实现通过人工智能算法快速提供优化指导方案,提高操作人员工作效率,降低劳动强度。算法的优化效果获得了专家的一致认可。
