基于机器学习分类算法的地层水合物识别方法研究
2021-12-30叶智慧宁禹强李晓蓉
叶智慧,宁禹强,张 敏,李晓蓉
(1.中国石油大学(北京)安全与海洋工程学院,北京102249;2.大庆油田采油工程研究院,黑龙江 大庆 163453;3.中国石油大学(北京)石油工程学院,北京102249)
南海北部陆缘位于东亚大陆边缘构造域内,经历了由板内裂陷演变为边缘坳陷的地史历程,形成了珠江口盆地、琼东南盆地、西沙海槽盆地、台西南盆地、双峰北盆地和笔架南盆地等新生代沉积盆地。特别是位于陆坡深水区的新生代大型沉积盆地,地质构造独特,具备良好的天然气水合物成藏地质条件[1]。天然气水合物(以下简称水合物)是一种天然气与水在高压低温条件下形成的类冰状的结晶物质,在我国青藏高原冻土带和南海北部深海海底都有发现,已被我国正式确认为一种新的矿产资源。天然气水合物因其资源密度高,全球分布广泛,并且绿色清洁无污染,商业化开发已被世界多国提上日程[2]。1 m3水合物大约可分解出160 m3天然气(标准状态下),其碳含量约为现有化石燃料总和的2倍,一旦取得技术突破,其必将形成对常规油气的“第二次革命”[3-4],水合物的精准识别是勘探开发的前提。
目前国内外地层水合物识别方法主要分为直接法与间接法。直接识别法主要包括肉眼观察法、岩心红外测温法、钻探异常、生物识别法等。间接识别法主要是通过测井数据或地震资料对地层水合物进行识别。采用直接识别法能够最为直观地识别出地层的水合物,但也存在着一系列的问题。例如取芯成本过高,取芯过程中易导致水合物分解。直接识别法与观察者的主观因素有关,有时很可能因为观察者的失误或经验不足而做出错误的判断。在钻进过程中可以通过测量地层电阻率、声波时差、地层密度和地层伽马值等测井参数综合分析地层情况[5]。间接识别法通常可根据地层水合物的伽马值低、井直径大、电阻率高、密度低、中子孔隙度高以及声波时差低等测井特征来定性地判别天然气水合物。但是传统的测井曲线识别方法往往依靠专家判断,主观性强,而且耗时较长,在要求实时快速决策时具有明显的缺点,因此需要寻找一种快速、准确率高、适应性好的识别方法,以适应未来智能化钻井需求。随着人工智能的高速发展,越来越多研究者将机器学习方法应用于水合物识别的过程,并取得了良好的成果。其中研究较多的机器学习算法包括BP神经网络算法[6]、支持向量机算法[7]、决策树算法[8]、马尔科夫随机场[9]、KNN算法[10]等。但上述算法在实际运用过程中存在一定的局限性,具体表现为:支持向量机和神经网络都属于黑箱模型,无法控制与分析模型的中间过程;对于决策树模型,过多的冗余样本会导致树底层决策质量的降低,并伴随过拟合现象的产生[11];KNN算法每次预测都需要对所有数据进行重新计算,其效率较低[12]。BP神经网络模型预测天然气水合物生成,是采用以经验风险最小化(Empirical Risk Minimize,ERM)的传统统计学理论为基础,这样容易降低BP神经网络的稳定性,甚至出现局部过优情况[13-14]。采用BP神经网络方法进行水合物多属性储层参数预测,理论上随着属性的增加可以降低误差,而仅应用于井旁地震道的训练数据符合时,但是在预测其他数据时,有可能没有效果欠佳,即“过度训练”[15]。彭炎等[16]采用支持向量回归算法,预测青海木里地区冻土区天然气水合物地层,预测的结果基本符合实际,对后续勘探有一定指导意义。
总之,目前采用的识别方法普遍存在一些问题,如泛化能力不强、计算效率不高、准确率不高、有过拟合现象等,需要寻找一种更适合实时测井数据的快速识别方法,具备快速、高效、小样本以及准确性等要求。本文运用了四种典型的分类学习算法,通过各种评价指标对最终的识别结果做出评价,发现集成学习方法具有更高的准确性,并找到最优化的方法和参数组合,在钻进水合物过程中实现快速、实时、小样本、准确的识别,为实时钻井过程中机器自主岩性识别方法提供参考。
1 研究方法
本文主要利用AdaBoost集成学习算法、支持向量机、决策树、随机森林4种典型的机器学习分类算法,基于测井曲线数据对水合物层段进行识别。以下介绍这几种算法的基本原理。
1.1 AdaBoost 集成学习算法
基于 Boosting 的集成学习算法中最常用的是AdaBoost 集成学习算法。其核心思想是训练一系列弱分类器,然后将弱分类器加权联合,构成一个强分类器。
给定数据集:(x1,y1),(x2,y2),(xN,yN),其中yi∈{-1,1},用于表示样本的类别标签,xi表示样本的特征向量,i=1,…,N,N为样本总数。集成学习的具体步骤如下。
第一步:初始化数据的权值分布向量D1。
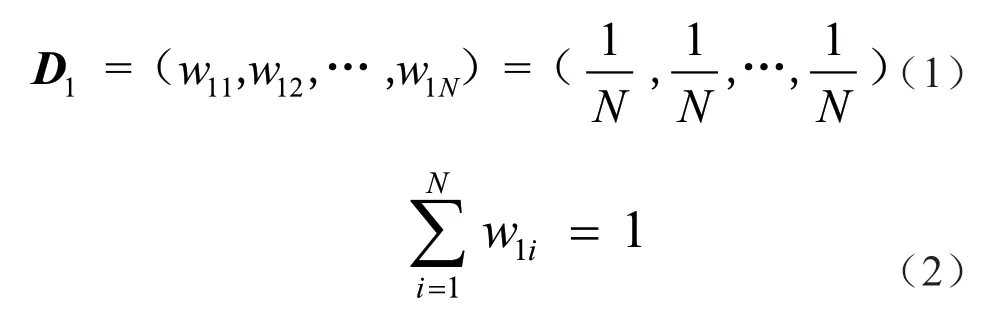
式中,w1i表示第1次迭代时第i个样本的权值。
第二步:进行迭代运算,达到设定值时停止。对于第t次迭代,进行如下步骤(t=1,2,…,T,T为总迭代次数)。
选取一个当前误差率最低的弱分类器ht,并计算该弱分类器在分布Dt上的预测误差率et。
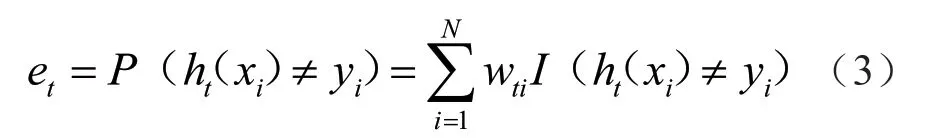
式中,ht(xi)表示弱分类器对样本xi的分类,若分类错误则I(·)值取1,反之取0。
计算该弱分类器在集成分类器中所占权重αt为:
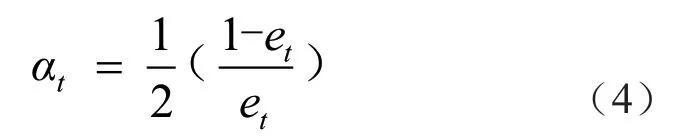
更新训练样本的权值分布Dt+1。

式中,Zt为归一化常数,。
第三步:按弱分类器权值t组合各个弱分类器,得到集成学习分类器[17]。

1.2 支持向量机算法
支持向量机算法本质上属于有监督的、可扩展分类元的、可跨越线性与非线性障碍的高效、受限、广义分类器,为了实现非线性的多核数据挖掘与聚类效果,提高内存的耗费比,平衡泛化能力与学习能力[18]。通过预测模型构造出损失函数,再基于结构风险最小化原则得到支持向量机算法。它要解决一个原始最优化问题,其形式如下。
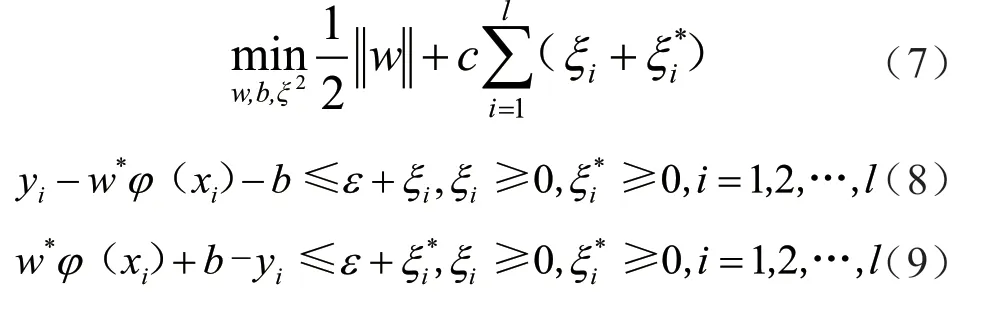
式中,w为权值向量;w*为w的伴随矩阵;c为惩罚参数;ξi、ξi*为松弛变量;φ(xi)为映射函数;xi为输入变量;yi为输出变量;l为样本个数;b为偏值;ε为误差上限。
通过代入拉格朗日乘子ai和ai*,将式(7)转化为拉格朗日多项式,用E表示,即

式中,k(xi,xj)为核函数;xi、xj为输入变量;l为样本个数。
由上式求解,可得到支持向量机的预测函数如下。
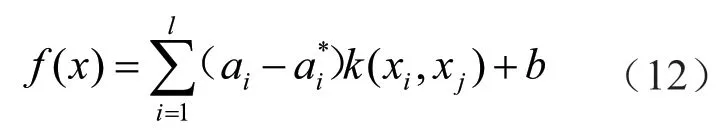
基于Mercer条件,且将高斯RBF作为核函数,g为核函数的内部参数,g>0,则有

式(7)中的惩罚参数c和式(13)中核函数的内部参数g决定了SVM的预测精确度。因此,为了构建高精度的预测模型,需要对SVM内部的参数(c,g)进行优化以确定最优参数[19]。
1.3 决策树算法
决策树分类算法的实质是通过对样本进行训练,并在这一过程中不断总结与归纳实现样本自学习,从而得到相应的决策树或者决策树规则。之后,依据所获得的决策树或者决策树规则完成数据的准确分类。
给定数据集D={d1,d2,…,dn},每个数据集的类别属性值可用A1,A2,…,Am进行表示,设定类别属性有n个互不相等的值。由此,可将数据集分割为S1,S2,…,Sn个子集,则数据集D的平均信息量可以用下式进行表征。

其中,P(Si)=|P(Si)|/|D|。
建立决策树也即逐步缩小分类不确定性的步骤,若Aj具有r个值al,其中1<l<r,依照Aj将S子集分割为数量为t的子集,则限定Aj=al时,各Sil子集被归类于第i类数据集合。此时,数据集D的平均信息量可以用下式进行表征。
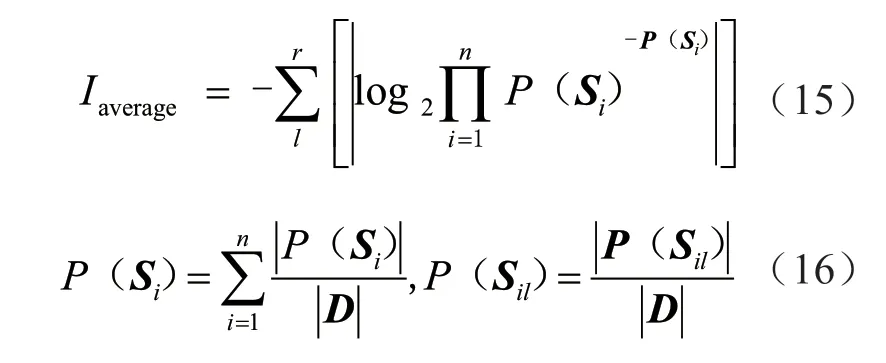
此时,数据集D的信息增益量可以用式(17)进行表征[20]。
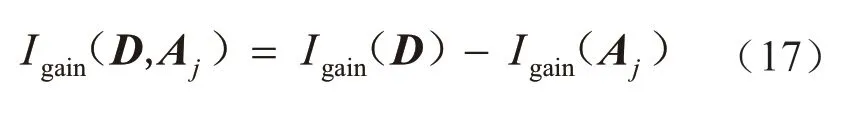
1.4 随机森林算法
随机森林是复合决策树的集成机器学习算法。随机森林使用booststrap方法构建n个训练集,每个训练集对应生成一个决策树,总体就有n个决策树,因为每个决策树的数据集都不相同,所以每棵树又有少量区别。最后对所有的决策树的预测结果取平均减少预测的方差,提高在测试集上的性能表现。相比较单棵树训练过程,随机性主要体现在两个方面:每次迭代是在原始数据集中重新抽样获得不同的训练集;对于每一个树节点,考虑不同的随机特征子集来进行分裂。
随机森林的数学模型公式如下。

式中,N为回归树模型回归树的数量[21]。
2 评价指标
关于预测结果的评价参数算法,对于识别水合物的情况,在二元分类中分类结果只有两种,真和假。一般用T(True)表示预测结果正确(与实际相符),F(False)表示预测结果不正确(与实际不符),P(Positive)表示真实的正样本,N(Negative)表示真实的负样本,那么预测就会有四种结果产生,如表1所示。

表1 评价结果指标意义
一般用4种典型的评价参数来评价预测结果准确性,包括准确率Acc、精确度P、召回率R和F1分数。

精确度和召回率可能往往是相互矛盾的。实际的情况中我们往往希望两个参数值都比较高。例如当预测的结果与实际结果完全一致时,FP与FN两个参数均为0,此时精确度与召回率均为1。这是一种理想的情况。

精确度与召回率可能是相互矛盾的,因此需要综合考虑二者,因此引入F1分数,定义如下。

3 水合物识别分析
本节基于乌伦盆地和神狐海域的2口井的测井资料进行训练与测试,并对识别的结果进行了分析,从不同的角度验证了集成学习方法在水合物识别的准确性。
3.1 UBGH2-10井
UBGH2-10井位于乌伦盆地的东北部,在该区域海底500 m范围内广泛分布着两个与天然气水合物分布有关的沉积单元:主要为新近纪晚期的物质运移沉积,以及更新世和全新世的大量浊积岩和半远洋沉积。地区的地层主要由覆盖在厚物质输导沉积序列上的半远洋沉积物组成,在该输运沉积层之下,可以看到另一个平行沉积层序列。密度—孔隙度和体积密度测井值显示了在海底以下190 m深度范围内的典型压实曲线,在该曲线中,块状物质运移沉积单元的出现导致体积密度突然降低,孔隙度随之增加。这口井的随钻测井数据中的P波波速表明直至海底深度下135 m波速都较低,这些数值来源于软沉积物以及工具发出的直接纵波与井眼与工具串相互作用产生的二次波重叠到达的复杂干涉图样。从测井图(图1 左)中可以看出地层中包含水合物的层段为2 220~2 307 m[22]。

图1 采集与实际测井曲线对比
3.1.1 数据处理
将文献中测井曲线进行数字化,借助石油云网站中测井曲线数字化功能模块,将多条曲线数据按照深度进行埋深对齐,得到可用于模型训练和测试的测井数据。石油云的测井曲线数字化模块主要基于曲线色域差对曲线像素进行自动识别,并去除背景噪声,进行插值补齐,得到还原度较高的曲线。整理后部分地层测井数据如表2所示,表格中的第一列为井深,最后一列为地层含水合物与否的标签,表格中间的部分为测井参数数据。

表 2 UBGH2-10井测井部分数据
图1展示了采集的数据与原数据曲线的对比,图中左边为实测测井曲线,右图为根据采集数据后绘制的测井曲线,红线标注的地层为含水合物地层。对比发现左右两幅图基本一致,验证了测井数据的准确性。
3.1.2 模型训练测试
运用典型的机器学习分类算法,包括AdaBoost、决策树、随机森林和SVM方法,对UBGH2-10井测井数据进行训练和测试,进行水合物层段识别,本例选择了50%的测井数据用于模型训练,其余的50%用于预测。图2展示了识别结果,最左侧为地层实际情况,右侧展示了不同方法预测的结果,水合物层段用绿色表示,其余用红色表示。

图2 地层识别结果
从图2可以看出,采用AdaBoost算法预测出了大部分的水合物地层,准确率达到95.02%,准确率依次降低的是随机森林方法、决策树,而支持向量机SVM算法并未预测出水合物地层。当改变训练集在整个数据集中的比例,即增加或减少训练集数据时,不同方法的预测准确率如表3所示。

表3 预测准确率

图3 UBGH2-10井识别结果
从预测结果中可以看出:一般情况下,采用集成学习AdaBoost的预测准确率均高于其他算法。随着训练集占比的增加,各算法预测准确率大部分呈增长趋势。在训练集占比较高时,AdaBoost、随机森林和决策树算法的准确率均大于SVM算法,其中集成学习在水合物识别中的准确率最高。
准确率反应的是预测结果与实际结果的对比,依靠这个参数反应的地层情况是片面的。例如以上例子中采用SVM方法完全没有识别出含水合物层段,这说明仅凭准确率一个参数作为算法分类好坏的标准是不够的,因此要引入精确度与召回率两个参数作为综合评价。分别计算以上各井的精确度、召回率和F1分数。下表为各方法训练集占测井数据的50%时的测试结果。

表4 不同算法的精确度、召回率和F1分数(UBGH2-10井)
上表表明:当训练集占比为50%时,F1分数、精确度以及召回率最大的均为AdaBoost算法,数值分别为0.907、0.929、0.886。在识别结果中,采用50%测井数据的SVM的测试结果中没有识别出含有水合物的层段。所以,识别结果中的TP部分为0,精确度与召回率的值均为0,因此F1的值为0。
3.1.3 测井参数优化组合及分析
参数优化主要以降低参数个数为基础,通过不同测井参数的排列组合,以此分析各个参数(组合)的影响,从而找到对水合物准确识别影响较高的参数组合,为测井工作的优化提供参考依据。对UBGH2-10井的测井数据采用集成学习AdaBoost方法,以训练集占总数据集50%为例,逐一降低参数个数,测试结果如表5至表9所示。

表5 5组测井数据识别结果

表9 1组测井数据识别结果
采用5组测井数据时(表 5),准确率最高的组合为孔隙度、伽马射线、电阻率、密度、纵波速度,前五组的参数组合准确率均在0.8以上,而去掉纵波速度以后,准确率大幅降低,降到0.729,可见采用5组测井数据时,纵波速度是一个影响较大的参数。
采用4组测井数据时(表 6),取准确率最高的十组数据组合进行分析。伽马射线、电阻率、井径和密度组合的准确率最高,其值达0.853;识别最差的组合准确率只有0.787,没有伽马射线和纵波速度,表示这两个参数在4组数据的情况下影响较大。

表6 4组测井数据识别结果
采用3组测井数据时(表 7),取准确率最高的十组数据组合进行分析。准确率最高的组合为电阻率、密度和井径,其准确率达0.844,准确率最低的组合为孔隙度、井径和纵波速度,准确率仅有0.751。准确率最高的排名前四的组合中,电阻率均在组合中,是较为重要的参数,而组合参数中含有孔隙度时,准确率相对较低。

表7 3组测井数据识别结果
采用2组测井数据时(表 8),取准确率最高的十组数据组合进行分析。准确率最高的组合为电阻率和井径,其值为0.787,电阻率和伽马射线组合的准确率次之,其值为0.782,识别准确率最低的组合是密度和纵波速度,其值仅有0.653。

表8 2组测井数据识别结果
采用1组测井数据时(表 9),准确率最高是用的参数是电阻率,其值为0.676,最低时用的参数是密度,识别准确率为0.52。
综合参数组合优化的结果,图4展示了不同参数情况下最高的准确率以及参数组合,可以看到电阻率在各个组合中均有出现,另外在3至5个参数的情况下,最高准确率均能达到0.8以上,因此,在之后的研究中应重点关注电阻率的测试结果。

图4 不同参数情况下准确率最高的测井数据组合
3.2 SH3井
神狐海域水合物研究区位于南海北部陆坡中部神狐暗沙与东沙群岛之间的海域,构造上位于珠江口盆地珠二坳陷南翼[23]。本区海底地形较平坦,总体趋势为北向南倾斜,水深从1 000 m逐渐加深到1 700 m以上。以1 350 m水深线为界分为南北2部分,北部地区地形较陡,从西到东发育3个近南北向的海底沟槽,海底沟槽与海底山脊相间排列[24]。南部地形平坦,向南逐渐进入深海平原。研究区主要发育海丘、海谷、冲蚀槽、冲蚀沟、反向坡坎及海底沟槽等地貌类型[25]。SH3井是神狐地区在第一次天然气水合物钻探考察中钻探的第一口井,图5的左图为该区域含水合物沉积物的测井解释层,深度范围为50~200 m。测井数据包括井径,伽马射线和电阻率[26]。
3.2.1 数据处理
与UBGH2-10井的处理方法相似, SH3井的测井曲线也采用石油云曲线数字化模块进行采集。图5为采集的数据与原数据曲线的对比图,图中左边为实测测井曲线,右边为根据采集数据后绘制的测井曲线。对比发现左右两幅图基本一致,从而验证了测井数据的准确性。
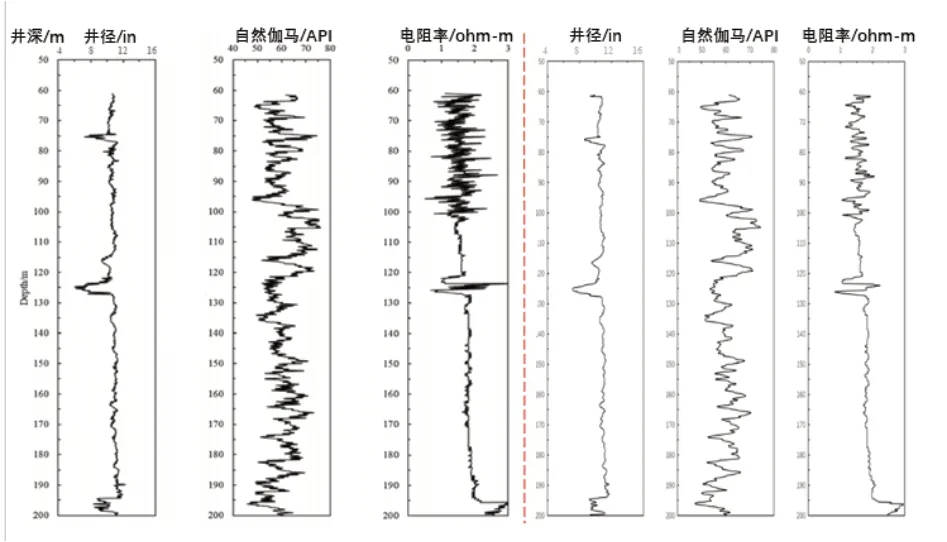
图5 采集与实际测井曲线对比
3.2.2 模型训练测试
首先对该地层进行识别,采用测试训练集占比为50%时,Adaboost、决策树随机森林和SVM方法的识别情况展示在图6中,左侧为地层实际情况。对比发现,相对于其他方法,集成学习Adaboost方法准确率高,且水合物层段可以较为准确识别出来。决策树准确率次之,也能识别出水合物层段。随机森林和支持向量机SVM方法虽然也有较高准确率,但未能有效识别水合物层段。

图6 SH3井水合物地层识别结果
采用不同比例的训练集占比时,不同方法的预测准确率如表10所示,图7展示了4种方法识别的准确率与训练占比的相关图。

表10 SH3井识别结果

图7 SH3井识别结果
对于各训练集占比识别准确率最高的是AdaBoost算法,识别准确率最低的为SVM算法,各算法识别准确率在大体上随着训练集占比的提高而增加,即训练所用的数据越多,预测就越准确。
除了计算准确率,基于50%训练集的情况,再计算精确度与召回率以及F1分数,从而更加全面地了解各个算法的预测效果。

表11 不同算法的精确度、召回率及F1分数(SH3井)
结果显示:F1分数最高的时AdaBoost算法,最低的是SVM算法;精确度最高的是AdaBoost算法,最低的是SVM算法;召回率最高的是AdaBoost算法和决策树算法,最低的是SVM算法。SVM算法虽然识别的准确率达到81.98%,但同样没有识别出含有水合物的层段,因此F1,精确度与召回率的值均为0。
3.2.3 测井参数优化组合及分析
对SH3井的测井数据采用集成学习AdaBoost方法,以训练集占总数据集50%为例,逐一降低参数个数,测试结果如表12和表13所示:

表12 2组测井数据识别结果

表13 1组测井数据识别结果
表12表明,采用2组测井数据时,准确率最高的组合是井径和电阻率,识别准确率最低的组合是井径和伽马射线。
表13说明,采用1组测井数据时,准确率最高的是电阻率,识别准确率最低的组合是井径。SH3测井参数较少,在选择测试参数时已经考虑了较关键的参数,因此预测准确率也较高,降低参数个数的测试结果,也保证了0.8以上的准确率,并且发现电阻率是较为关键的参数,能影响识别结果的准确率。
4 结 论
本文利用测井数据,引入机器学习分类算法,通过方法和参数的优选,进行地层水合物识别。利用石油云测井曲线数字化工具进行测井数据采集,用多种机器学习算法进行水合物层段识别,通过引入F1分数,精确度与召回率等参数作为识别结果的评价指标,对各种学习方法的测试结果进行系统的评判。最后采用降参数的方法探寻不同测井参数的最优组合,得到有重要影响的测井参数组合,为井下测井仪器选择提供依据。
验证结果表明:(1)与其他机器学习算法相比,集成学习算法AdaBoost在大多数的测试结果中的准确率都是最高的;(2)通过对识别结果的精确度,F1分数进行综合分析,找到综合结果最优的算法也是集成学习Adaboost算法,识别结果与实际地层的匹配程度较高,证明了集成学习算法在水合物识别方面的可行性;(3)改变参数个数,对不同测试参数组合识别结果进行评价,测试结果表明电阻率与声波传递速度在水合物的识别方面有很强的辨识性,这与水合物的特征相符。可以作为根据随钻测井参数识别地层水合物中需要重点关注的测井参数。
本文通过方法优选和参数优选,发现集成学习AdaBoost算法在水合物识别上具有较好的效果,为天然气水合物识别提供了新的思路,对未来实现钻进过程中智能识别有重要的借鉴意义。
