基于激光雷达的无人驾驶障碍物检测和跟踪
2021-12-28曾文浩
王 涛 ,曾文浩 ,于 琪
(西南交通大学电气工程学院,四川 成都 610031)
近些年,随着人工智能和机器人技术的不断发展,无人驾驶汽车作为人工智能领域的一个重要的分支已经成为国内外的研究热点. 无人驾驶汽车主要通过激光雷达、相机、毫米波雷达、IMU (inertial measurement unit) 等传感器实现对周围环境的感知.障碍物检测和跟踪是环境感知的重要环节,检测和跟踪的效果好坏直接影响无人车的安全行驶. 近些年基于相机图像的检测技术获得了很大发展,但是其检测效果易受光线等环境影响. 激光雷达则因其能够获得障碍物的基本形貌、距离和位置等信息,同时具有精度高等优点,被广泛运用于无人驾驶的障碍物检测和跟踪中[1].
国内外学者对障碍物检测和跟踪的做了大量研究. 文献[2]基于八叉树网格法检测运动物体,然后用DBSCAN (density-based spatial clustering of applications with noise)算法聚类. 然而其网格绘制过程复杂、难度大;文献[3]用选取4 个代表点取代对所有点的搜索去改进DBSCAN,实现激光雷达目标物的快速、准确检测,但是其代表点的选取方法可能选入之前访问过的点从而降低效率. 文献[4]通过引入区域步长参数的方式,将激光点云数据距离测量值与搜索半径建立了关联. 这样在距离增大时,搜索半径也随之增大,适应了激光雷达数据在距离增大时测量点密度降低的变化趋势,使得算法对于区域密度分布不均匀的数据具备更好的普适性,在单线激光雷达中效果优于传统DBSCAN. 文献[5]和文献[6]采用自适应的最小聚类数量MinPts 适应远近聚类的物体点云,水平和垂直方向采用不同搜索半径适应激光雷达点云分布,但是该方法的搜索半径都没有随距离调整,当物体足够远时候选点的邻域点可能不存在,导致聚类失败. 文献[7]对聚类后的障碍物采用最近邻数据关联算法对距离特征进行前后帧关联,再使用卡尔曼滤波器进行运动状态估计和速度估计,但是用单一特征对障碍物进行关联,容易造成漏跟和错跟;文献[8]认为如果前后帧两个对象的边界框重叠,则被认为是同一个对象,然而该方法只适用于缓慢移动的物体,一旦速度过快就会关联失败. 汪世财等[9]考虑了障碍物的点云位置特征和几何特征,利用多特征提高了障碍物关联的可靠性,但是特征权重值通过经验获得的固定值,无法随着位置不断调整.
本文可分为障碍物检测和跟踪两个部分,其中障碍物检测分为点云预处理和聚类两个部分. 在点云预处理部分主要是道路边缘检测和地面点去除等预处理工作;在聚类部分,本文对传统的DBSCAN进行改进,采用自适应搜索参数和代表候选点法,分别提高聚类适用性和实时性. 在障碍物跟踪部分,本文利用加权的最小二乘法进行速度估计,然后采用一种自适应权重的多特征关联算法进行多目标关联.
最后在实验中,采用16 线激光雷达进行障碍物检测和跟踪,验证了本文障碍物聚类和关联算法的有效性. 通过实验表明整个检测流程能够对10 帧/s的激光雷达数据实现准确、稳定地检测和跟踪.
1 点云预处理
本文使用的激光雷达点云数据来源于两台型号为Velodyne VLP-16 的激光雷达,这两台激光雷达被安装在“智轨”列车的左右两侧,“智轨”列车为中车株洲电力机车研究所有限公司自主研发的智能轨道快运列车. 本文数据处理硬件平台为个人电脑,硬件配置为Intel 8 核2.3 GHz 处理器,内存8 GB,软件采用Ubuntu16.04 下的ROS 机器人操作系统. 图1 所示为“智轨”列车平台和数据采集场所——某市的株洲大道.

图1 “智轨”列车平台以及株洲大道Fig. 1 ART Train Platform and Zhuzhou Avenue
1.1 路沿检测和感兴趣区域提取
VLP-16 的竖直视场角为30°,竖直方向有16 线激光束,水平视场角为360°. 工作频率为10 Hz 时,一台激光雷达每一帧大约有3 万个点. 两台激光雷达的数据量是单台的两倍,因此有必要减少无关点云对数据处理速度的影响.
激光雷达回传的点云数据中包含许多与行驶区域无关的点,提取出可行驶区域,可以减少数据量,提高计算速度. 首先进行道路边沿检测[10]. 根据激光雷达点云在路缘石处存在高程突变的特点,提取出每一线的激光点云;然后按坐标y的绝对值对左右雷达点云分别排序(激光雷达坐标系符合空间坐标系的右手法则);利用“滑动窗口”对坐标z的值突变较大的“窗口”进行标记,将其“窗口”内突变最大的点作为路沿点. 提取效果如图2 所示,图中红色大点即为路沿点. 然后选取路沿中间的区域和路沿附近的区域作为感兴趣区域,其余区域不参与之后的处理,从而减少计算量.
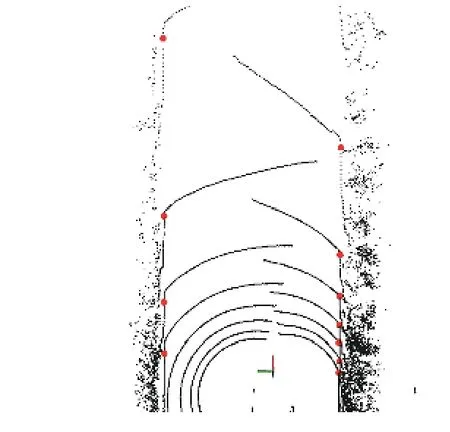
图2 路沿点提取效果Fig. 2 Effect of curb point extraction
1.2 地面分割
感兴趣区域内的点云数据中不仅包含障碍物的点,还包含大量的地面点,障碍物检测关心的是地面以上的点,因此需要去除地面点. 由于现实的地面并不是一个完美的平面,而且当距离较大时激光雷达会存在一定的测量噪声,单一的平面模型并不足以描述现实的地面. 本文使用基于扫描线束的分割算法[11]对地面进行分割,该算法的核心是以射线的形式来组织点云. 将点云的 (x,y,z) 三维空间降到 (x,y) 平面来看,计算每一个点的水平夹角θ,对同一水平夹角的点按照水平距离r进行排序,计算前后两点的坡度Δp是否大于事先设定的坡度阈值,从而判断点是否为地面点,计算如式(1).

式中:m为测量点序号;zm和rm分别为点m的z方向距离和水平距离.
分割效果如图3 所示,图3(a)为原始点云,包括地面和障碍物点云,图3(b)为地面分割算法得到的障碍物点云. 由图3 可见,通过以上方法,成功达到了减少点云数据数量并保留障碍物点云的效果.
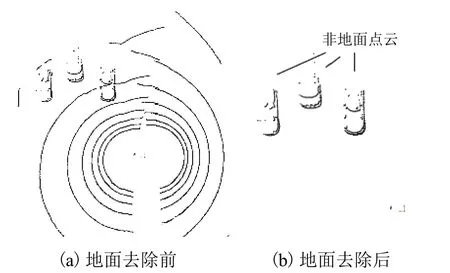
图3 地面分割效果Fig. 3 Effect of ground segmentation
2 优化的DBSCAN 聚类检测算法
本文采用自适应的聚类算法进行障碍物检测,并提取障碍物的几何特征特征. DBSCAN 是经典的密度聚类算法,该方法将具有足够高密度的区域划分为簇,可发现任意形状的聚类. DBSCAN 算法需要两个参数:搜索半径ε和最小包含点数MinPts.DBSCAN 算法的思想是在数据集中任选一点q作为起始点,如果q的ε邻域内的点数量不小于MinPts,则q的邻域点作为即候选点,通过不断查找从候选点的邻域点来扩展该簇,直至找到1 个完整的簇;如果q的ε邻域内的点数量小于MinPts,则q被暂时标注为噪声点. 对数据集中未被处理的点重复上述过程,进行其他簇的扩展,直至所有点均被访问.
2.1 自适应参数的改进
全局固定ε阈值会导致分割程度的不确定性,阈值设置过大会导致距离较近的两类物体被分为一类,阈值过小会导致本应该属于同一个物体的点云被分开,这就造成了存在分割不足或者分割过当的情况[12]. 因此ε的取值应该随点云分布而变化,本文采用随距离增大而线性增大的ε值.
由于激光雷达在水平方向的分辨率与竖直方向的分辨率一般不同,所以某些情况下两个距离很近的物体,无论用较大的ε还是较小的ε都无法有效分割,因此ε的选择不仅需要随着离激光雷达原点距离变化,还要在不同方向上取不同的值,最终形成一个空间中大小不断变化的“搜索椭球”,如图4所示.
图4 中:L和H分别为两个相邻点之间的水平和竖直距离;εh和εv分别为水平和竖直搜索半径,即“搜索椭球”的半短轴和半长轴.
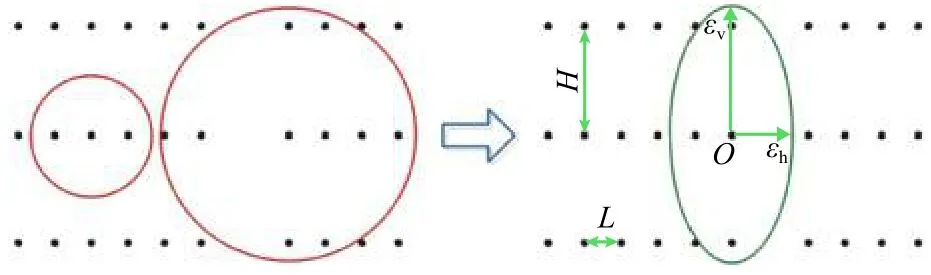
图4 球型搜索和椭球型搜索示意Fig. 4 Illustration of spherical search and ellipsoid search
可以使用式(2)计算两个相邻点之间的L和H.

式中:d为测量点到激光雷达原点的距离;θh和θv分别为激光雷达的水平和垂直角分辨率. 查阅VLP-16 用户手册可知,激光雷达在10 Hz 的工作频率下其水平和垂直角分辨率分别为0.2° 和2.0°.
为了确保可以搜索到同一物体表面的相邻点,搜索半径应大于或等于该位置的两个相邻点之间的距离. 所以水平和竖直搜索半径εh和εv可表示为

式中:a为搜索系数,代表着搜索半径跨越的激光束的数量,a≥ 1.
MinPts 值是根据从搜索椭球内收集的最大点数以及障碍物倾斜角度来估算的. 当激光束垂直照射到障碍物时,障碍物点数达到最大值,此时可以将椭球体视为椭圆形. 直接计算椭圆内的点数很困难,因此可以利用蒙特卡洛随机模拟法的思想求解椭圆内点数. 即首先计算长为εv、宽为εh的矩形内的点数量Nr,再根据矩形和椭圆的面积比,计算出椭圆内点的数量为
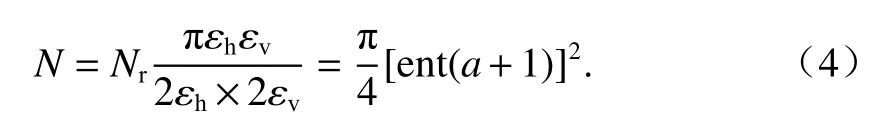
考虑到实际情况下激光束与障碍物平面之间的角度可能不为90°,障碍物的总点数等于或小于计算的N值. 假设原本激光束与障碍物平面夹角为90°,而现在发生水平方向偏转角度φh,如图5 所示.O为激光雷达原点,E为相邻点连线的与相邻激光束角平分线交点,原来相邻点A、B之间的水平距离为L(AB长度),旋转φh度后为点C、D,距离变成L1(CE长度)+L2(DE长度).
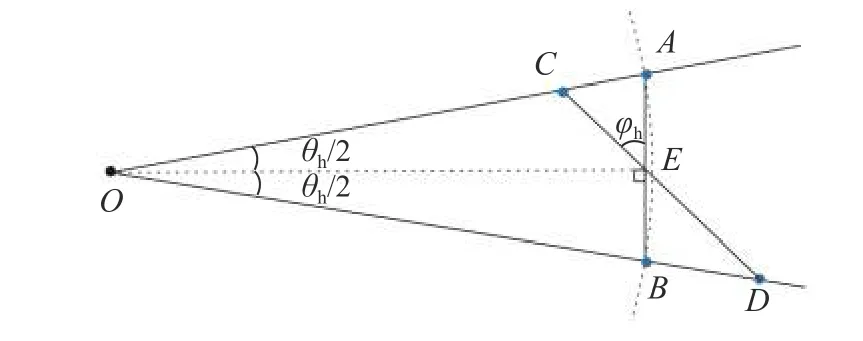
图5 物体发生倾斜时的示意Fig. 5 Schematic diagram in the case of tilted object
此时两个相邻点之间的竖直距离不会发生变化,而水平距离会发生变化. 计算方法如式(5).
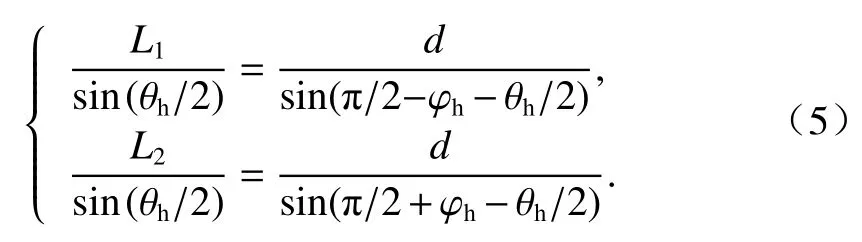
经化简可计算出偏转后相邻点之间的水平距离Lr(CD长度) 为

定义水平偏转系数kh,当水平偏转φh时相邻点之间的水平距离增加kh倍,则kh可以表示为
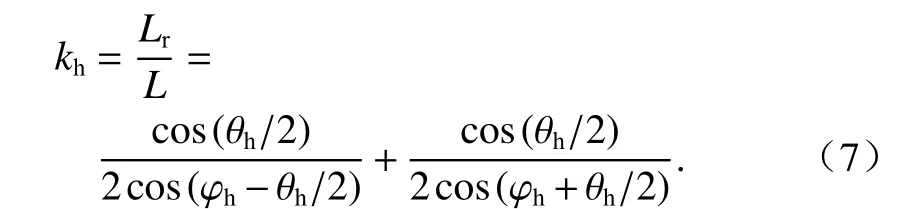
实际过程中水平角分辨率θh很小,可当作趋近于0;而若φh趋近于90° 时,该面将无法接收点云.因此:

同理可以得到竖直偏转系数kv,kv≈1/cosφv,φv为垂直偏转角. 因此,结合式(4)、(5)、(7)和式(8)可得,物体与激光数发生偏转后椭圆内的点数量为
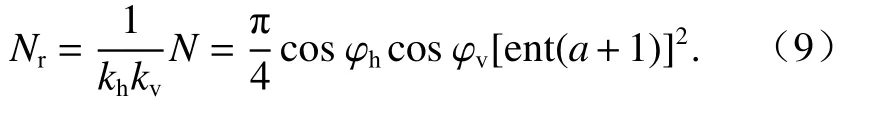
考虑实际情况,水平方向偏转角度φh最大取60°且竖直方向偏转角度φv最大取45°. 另外由于空气中雨雾、尘埃和镜面反射等原因会造成的点云空缺和偏移,所以引入损失系数η,取值0.8. 则最后MinPts 取值为

按照以上方法选择自适应搜索半径ε和最小包含点数MMinPts,可以对不同距离和倾角的障碍物3 维点云进行准确聚类.
2.2 实时性优化
原始的聚类算法中,核心点的邻域内所有的点都会作为候选点,而实际起作用的点主要是邻域边缘的数据点,选取全部邻域点必定会浪费较多的搜索时间. 为了加速DBSCAN 算法,文本选取核心点邻域内某些具有代表性的点作为候选种子点,简称代表点. 如图6 所示,P为核心点,三角形和圆形点是P的邻域点. 在未被访问过的领域核心点中选出离6 个边缘点(εh,0,0)、(−εh,0,0)、(0,εh,0)、(0,−εh,0)、(0,0,εv)和(0,0,−εv)距离最近的点作为代表点,添加入该种子簇,如图6 中三角形. 若某个代表点被选择两次,则它只被添加一次. 采用这种方法,在激光雷达点云数据中,任意核心点最多6 个代表点. 因此可以有效减少计算量,提高聚类速度.
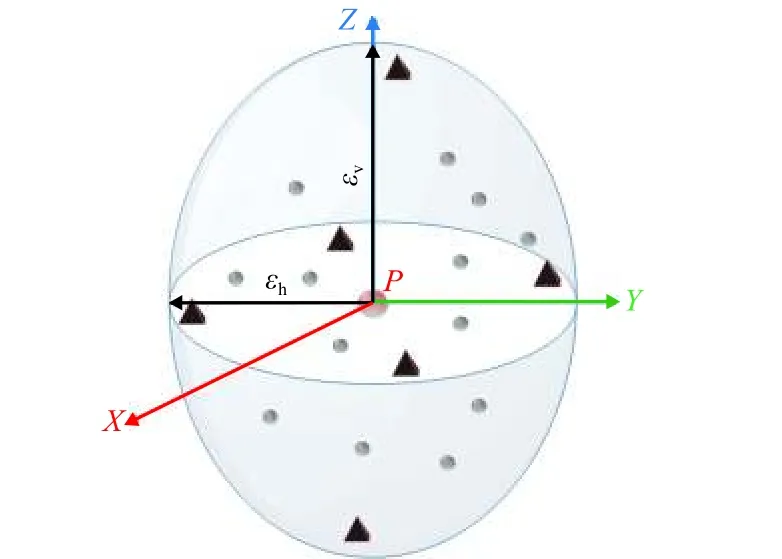
图6 椭球域及其代表对象的三维邻域Fig. 6 Three-dimensional neighborhood of ellipsoidal domain and its representative objects
本文采用的激光雷达是低线束激光雷达,如果使用64 线、128 线等激光雷达时,因为数据量过于大,该算法内存消耗较大,会出现延迟. 此时可以考虑对点云进行栅格化处理,然后对有序的栅格进行聚类,以提高算法实时性.
3 障碍物跟踪
为了获取动态障碍物的动态特性,需要将当前帧信息与历史信息进行匹配[13]. 本文利用加权的多特征数据关联算法结合滤波算法实现对动态障碍物的跟踪. 激光雷达点云前后帧间隔0.1 s,每帧之间可以认为是线性运动,而卡尔曼滤波器是一个线性递归滤波器,相比于粒子滤波也具有更高的实时性.因此本文先采用卡尔曼滤波器对目标障碍物的位置进行预测后,再用多特征数据关联算法在前后相邻两帧之间进行关联,最后采用卡尔曼滤波器对目标障碍物的位置进行滤波,经过以上步骤即可完成对目标跟踪. 算法流程如图7 所示.
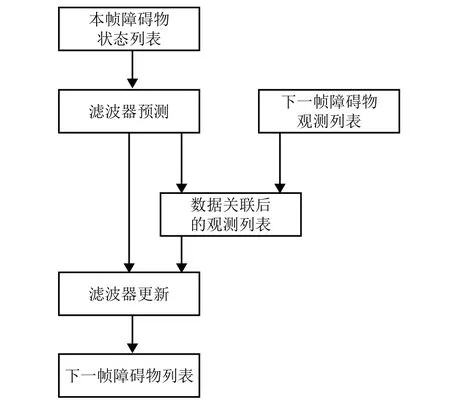
图7 障碍物跟踪算法流程Fig. 7 Flowchart of obstacle tracking algorithm
3.1 滤波器预测
受测量噪声和自主驾驶车辆车体自身运动的影响,直接对前后帧的障碍物进行关联,有可能导致关联错误. 为了解决目标跟踪中测量噪声引起的目标运动轨迹的大幅变动对预测目标运动轨迹造成的影响,以及在障碍物关联中对于预测目标下一帧位置的需要,有必要采用卡尔曼滤波器对目标的位置进行预测.
卡尔曼滤波的预测方程如式(11).

式中:Xt为第t帧(即时刻t)障碍物中心的状态向量,
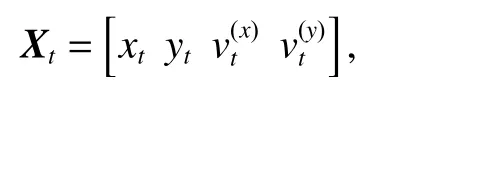

本文激光雷达工作频率为10 Hz,所以每帧时间间隔T取0.1 s;
ωt为状态噪声,满足ωt~N(0,Q)的高斯分布,本文取Q= 0.01E4,E4为4 阶单位矩阵.
则障碍物中心的状态向量预测值和预测协方差方程分别为

式中:Xt|t和Pt|t分别为时刻t的预测值向量和预测协方差向量.

令S(a0,a1,a2)取最小值,即可得到系数a0、a1、a2,拟合后可求出时刻t的速度值.
当障碍物出现次数为1,即新出现时,认为速度为0;当障碍物出现次数为2,即前面只有1 帧时,速度即为前一帧的速度;当障碍物出现次数为3、4、5 时,进行1 次函数拟合;当障碍物出现次数大于5,即前面的5 帧以上时,则利用前面的5 帧数据进行上述二次曲线拟合计算当前时刻的速度.
3.2 多特征数据关联
逐帧动态跟踪目标属于动态规划领域中的“配对问题”[14],两组点可基于距离进行配对. 本文采用最近邻算法进行数据关联,最近邻算法计算所有观测数据和目标预测值之间的差异度,然后再取差异度最小的一个观测数据作为该目标的观测值.
设第t帧内检测到的第i个障碍物与第t+1 帧内检测到的第j个障碍物之间的差异度函数通常采用欧式距离计算, 如式 (16).
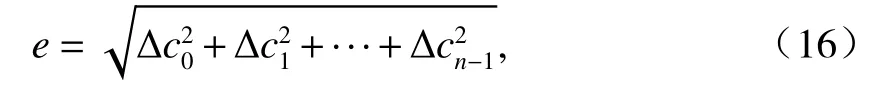
式中:n为障碍物数;Δck为第t帧检测到的第i个障碍物与第t+1 帧检测到的第j个障碍物之间第k个特征的差值.
由于16 线激光雷达垂直方向分辨率低,运动的障碍物的点云在垂直方向会有很大突变,所以本文不使用垂直方向特征. 根据激光雷达的扫描特性,物体位于激光雷达不同位置会被扫描到不同形态的点云,例如物体位于激光雷达正前后方,则点云主要是yOz面点云,如图8 的物体A,其长度特性消失;物体位于激光雷达侧方,则点云主要是xOz面点云,如图8 的物体B,其宽度特性消失;物体位于激光雷达其他位置,则点云由xOz和yOz面按组成点云,图8的物体C,同时拥有宽度和长度特性.
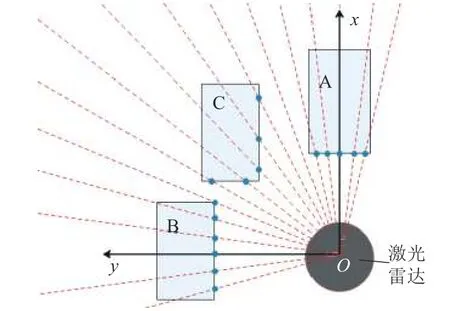
图8 障碍物与激光雷达的相对位置Fig. 8 Relative position of obstacles and LiDAR
假设图中x方向为长度方向,y方向为宽度方向. 越靠近x轴障碍物的点云的宽度特征越明显;越靠近y轴障碍物的点云的长度特征越明显. 因此障碍物长和宽特征的权值可以根据障碍物相对激光雷达的水平位置而调节.
当收到第t+1 帧障碍物观测点云时,计算其与第t帧障碍物预测状态的加权欧式距离,然后将差异度最小的点进行关联. 则第t帧的第i个障碍物和第t+1 帧的第j个障碍物差异度计算如式(17).

最近邻数据关联算法计算量小,适用于目标数量较少时的前后匹配. 但在目标数目较多、运动情况复杂时,可以考虑历史信息或者概率信息,比如采用JPDA (joint probabilistic data association) 或者MHT (multiple hypothesis tracking) 算法,提高对多目标复杂场景的抗干扰能力.
3.3 滤波器更新
当前一帧预测后的状态与下一帧观测状态关联上之后,需要利用下一帧的观测值对上一帧的预测值进行修正,得到下一帧状态作为最优估计,即卡尔曼滤波的更新过程.
测量状态转移方程如下:

νt为状态噪声,满足νt~N(0,R) 的高斯分布.其中,R为测量噪声,本文取R=0.001E2,E2为2 阶单位矩阵.
则时刻t+1 的误差增益、更新值和滤波误差的协方差矩阵分别为
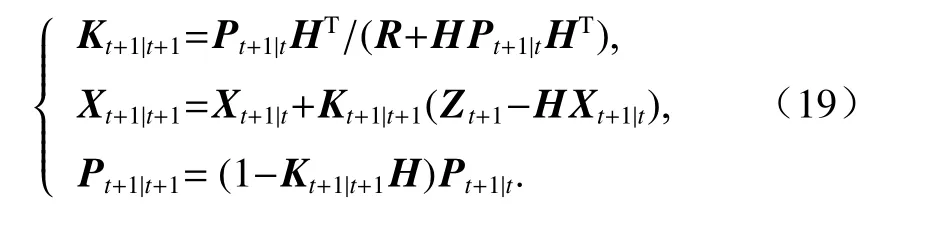
4 实验结果
为了验证本文算法的有效性,在Ubuntu 的ROS系统下,采用C++编程处理激光雷达采集的数据.
由于城市道路环境相对单调,在聚类算法实验中,采用激光雷达固定,3 人在雷达面前自由活动,然后对人员进行聚类,最后将聚类结果用三维边框进行框选,方便观察效果.
为了验证自适应搜索半径的作用,对比加入和未加入自适应搜索半径的DBSCAN 算法对同一数据的处理效果. 其中自适应算法的搜索系数a取10,传统算法的搜索半径ε取0.2 m 和0.8 m,最小聚类数量均取MinPts 值取22. 其中第260 帧数据聚类的俯视图效果如图9 所示. 由图9 可见:传统算法搜索半径取0.2 m 时漏检了左侧人员,如图9(a);搜索半径为0.8 m 时又出现了分割不足的现象,将中间和右侧人员归入一类,如图9(b);而优化后的算法可以检测出所有人员,如图9(c).
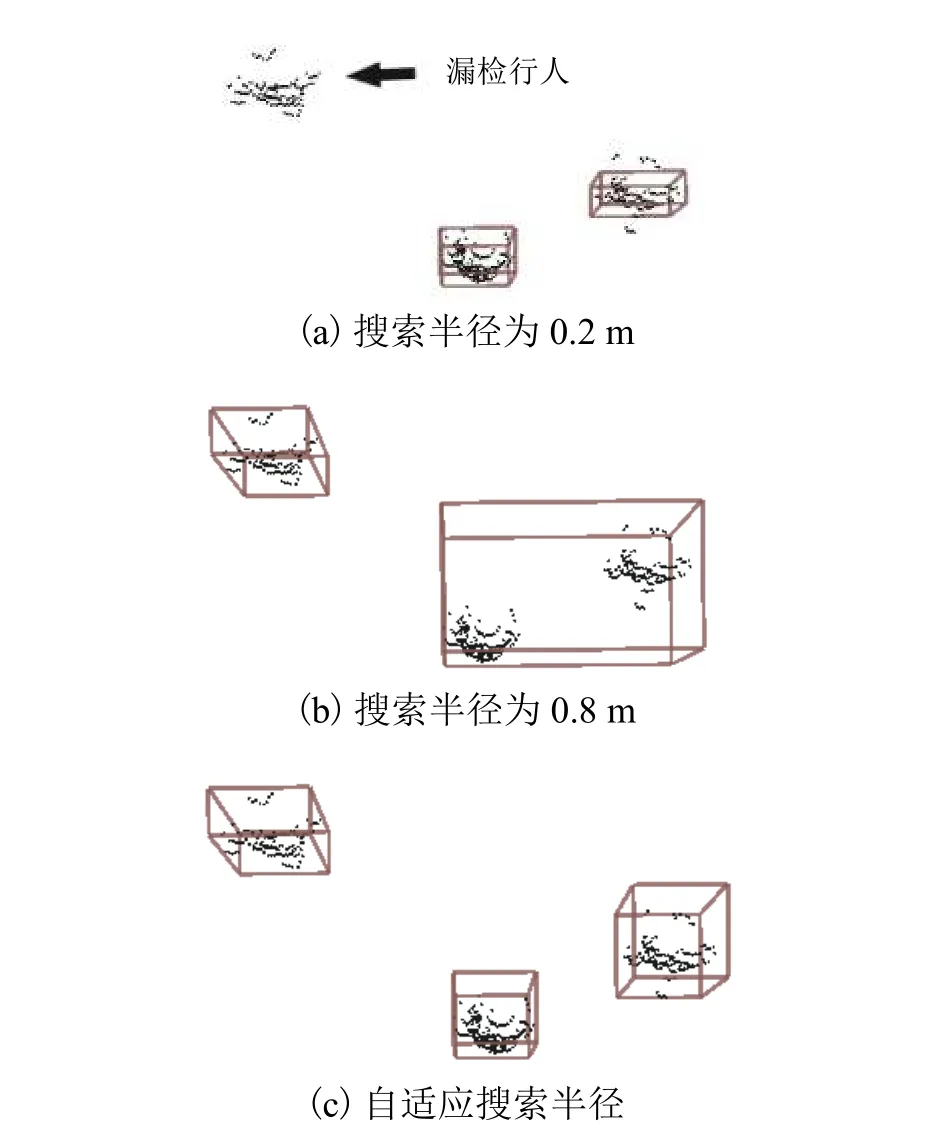
图9 第260 帧的聚类结果Fig. 9 Clustering results at the frame 260th
为了验证“椭球搜索”的作用,对比加入和未加入“椭球搜索”的算法对同一数据的处理效果.截取第280 帧结果的正视图效果,如图10 所示. 由图10 可见:未加入“椭球搜索”存在分割不完全的现象,如图10(a);加入“椭球搜索”后可以聚类出完整的障碍物点云,如图10(b).

图10 第280 帧的聚类结果Fig. 10 Clustering results at the frame 280th
城市道路的障碍物大部分为运动车辆,对障碍物检测的实时性要求比较高. 在聚类算法实时性验证和跟踪算法实验中,采集城市道路上的激光雷达数据,该数据由2 台安装在“智轨”两侧的VLP-16 雷达在某市的城市道路采集.
为验证代表点方法对DBSCAN 算法实时性的提升,对比采用和不采用代表点加速的算法对同一数据的处理效果. 统计第t1−2 帧到第t1+92 帧数据的聚类处理时间(t1∈t),每隔10 帧采样一次,每次采样取该帧前、后共5 帧的平均值,最后绘制曲线如图11 所示. 由图11 可见:采用代表点法的DBSCAN 算法处理同一帧数据的时间明显小于不采用代表点法DBSCAN. 可求出传统算法平均耗时0.015 1 s,代表点法加速算法平均耗时0.011 4 s,时间上缩短32%.

图11 聚类所消耗的时间对比Fig. 11 Comparison of time consumed by clustering
为验证跟踪算法的可靠性,在城市道路数据中,对路上行驶车辆进行检测并对车辆进行框选,然后对框选的车辆进行跟踪和标号(ID),对比同一车辆前后帧的标号是否发生变化和不同车辆标号是否不同,以验证数据关联和跟踪算法的可靠性. 实验结果如图12 所示. 图12(a)为第t2帧车辆目标(t2∈t)标号为13、16、20 和21,图12(b)为第t2+1 帧跟踪后对应的位置;图12(c)为第t3帧车辆目标(t3∈t)标号为33、50 和51 号的车辆,图12(d)为第t3+1 帧跟踪后对应的位置. 由图12 可见:本文对动态障碍物进行了稳定检测和跟踪.
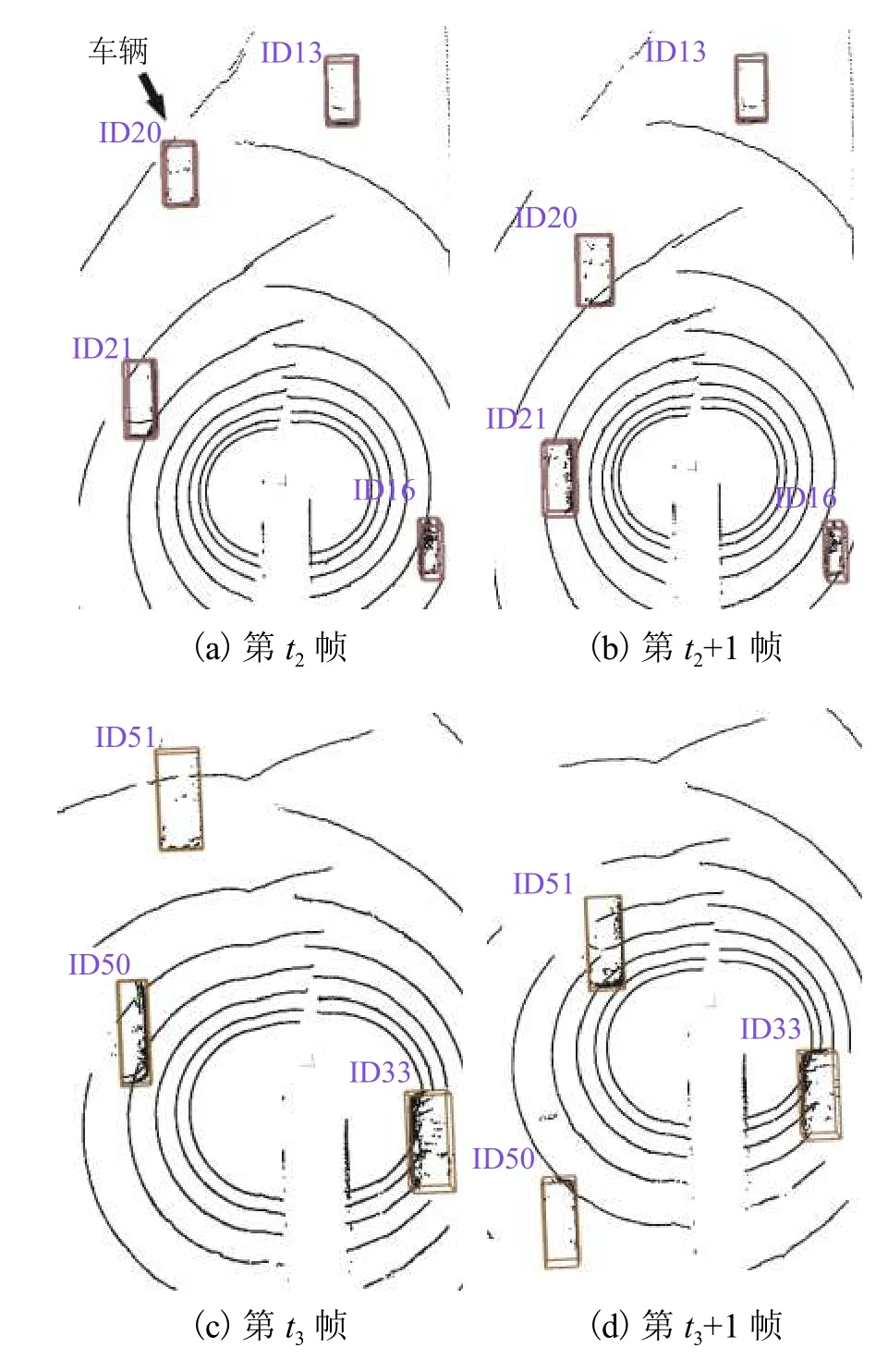
图12 动态障碍物跟踪效果Fig. 12 Effect of dynamic obstacle tracking
5 结 论
本文主要针对基于三维激光雷达的动态障碍物检测和跟踪问题进行研究. 在障碍物聚类过程中,对传统的DBSCAN 聚类方法进行改进,提出“椭球搜索”和自适应的搜索半径提升了激光雷达点云的聚类效果,使用代表对象法改进搜索速度,同时提高了障碍物聚类的适应性和实时性;在数据关联过程中,考虑了障碍物的位置特征和几何特征,利用多特征提高了障碍物关联的可靠性;然后采用加权的最小二乘法对障碍物的速度进行预测和采用卡尔曼滤波算法对障碍物位置进行预测和跟新,从而实现多目标跟踪. 最后分别就聚类效果和跟踪效果进行实验分析,结果表明:采用本文方法在障碍物检测时比传统聚类方法在处理效果和时间上都得到了提升,并且能够对动态的障碍物进行稳定地关联和跟踪. 实验过程中还发现,路旁的树木等障碍物会对跟踪算法准确性造成影响. 因此,后续研究考虑加入点云的类别信息,提高复杂场景的跟踪准确率.
