基于EfficientDet 的全球小麦麦穗检测方法研究
2021-12-28王季
王季
(200093 上海市 上海理工大学 机械工程学院)
0 引言
目前,在室外野外图像中进行准确的小麦头视觉检测依然具有挑战性。密集的小麦植株经常重叠,风会使照片模糊;外观会因成熟度、颜色、基因型和头部方向而异。由于小麦在世界范围内种植,因此必须考虑不同的品种、种植密度、样式和田间条件,针对小麦麦穗开发的模型需要适应不同的生长环境。当前的检测方法涉及一级和二级检测器,但是即使在使用大型数据集进行训练时,仍然存在对训练区域的过度拟合[1-2]。
1 数据准备
1.1 样本采集
本文所用数据集源于Kaggle 的Global Wheat Detection 比赛,该数据集是由来自7 个国家的研究机构牵头,包括东京大学、法国国家农业食品与环境研究院、阿尔瓦利斯植物研究院、苏黎世联邦理工学院、萨斯喀彻温大学、昆士兰大学、南京农业大学和英国洛桑研究所。该数据集提供了尺寸为1 024×1 024 的小麦图片共3 422 张,给出麦穗边界框的中心点的坐标以及边界框的尺寸。本次比赛提供的数据集相关尺寸见表1。

表1 小麦相关数据Tab.1 Wheat related data
表1 中:宽度,高度——数据集中图片的宽和高;麦穗框坐标——图片中麦穗边界框中心点坐标以及边界框的长、宽;来源地——图片中小麦的来源地。
1.2 数据分析以及难例挖掘
根据表1 数据,结合具体的小麦图片可知,对小麦麦穗检测的难点如下:
(1)密集的小麦植株经常重叠;
(2)风会使照片模糊;
(3)外观会因成熟度、颜色、基因型和头部方向而异,且地域来源分布对外观的影响尤为重要。地域来源分布如图1 所示。
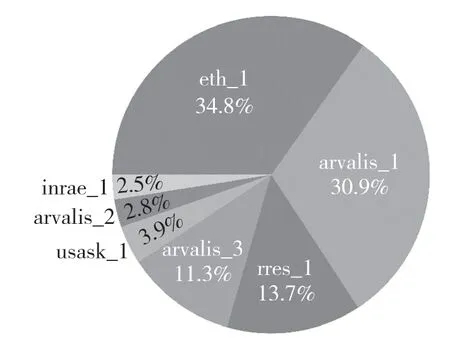
图1 小麦来源分布图Fig.1 Wheat source distribution map
使用LabelImg 开源图像标注工具对部分标注不准确的边界框进行了修正,输出修正后的新数据集,下面训练过程将使用修正过后的数据集。
1.3 划分数据集
将数据集进行StratifiedKFold 交叉验证。划分后得到5 组数据集,每组数据集分布为训练集2 800 张,测试集573 张。对数据集划分的具体实现方式为以小麦的来源为依据,对数据集进行有策略的五折交叉验证划分,使得划分出来的训练集和测试集的小麦来源分布保持和未划分之前的数据集一致,以避免因为分布不均衡而使模型效果不佳。
1.4 图片处理
原始图片为1 024×1 024,若使用该尺寸图片进行训练容易造成溢出显存的现象,因此将图片转换成512×512 尺寸,且对图片进行数据增强。
使用Pytorch 框架加载图片的过程中,针对密集的小麦植株经常重叠以及风会使得采样得到的小麦图片变得模糊这一难例,对训练集采样mixup 方法进行图像增强,具体实现方法如下:
对于输入的一个批量的训练图片,采取部分直接加载图片,部分将其和随机抽取的图片进行相加融合,融合比例λ=0.8,融合时将两张图片对应的每个像素值按融合比例对应相加,得到混合张量X,公式如式(1):

式中:M1——原始图片;M2——随机挑选出来的图片;λ——融合比例;X——混合张量。
混合张量X 即为新的输入变量,传递给模型得到输出张量Y,随后计算损失函数时,针对2个图片的标签分别计算损失函数,然后按照比例λ进行损失函数的加权求和,公式如式(2):
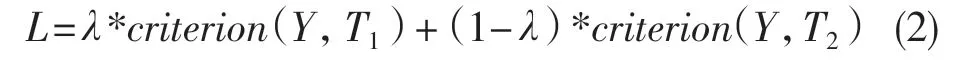
式中:λ——融合比例;Y——预测值;T1——原始图片的标签;T2——随机抽取的图片的标签;criterion()——损失函数;L——总损失函数
mixup 实现的效果如图2 所示。

图2 图片融合效果图Fig.2 Mixup effect drawing
2 基于EfficientDet 算法的小麦麦穗检测试验
2.1 EfficientDet 算法原理
EfficientDet 使用EfficientNet 网格作为主干网络,同时提出BiFPN,使模型实现高效的双向跨尺度连接和加权特征融合[3],其结构图如图3 所示。基于以上的特点,EfficientDet-D7 在COCO 数据集上实现了当前最优的51.0mAP,准确率超越之前最优检测器(+0.3%mAP),其规模仅为之前最优检测器的1/4,而后者的FLOPS更是EfficientDet-D7 的9.3 倍[4]。所以,本文选用EfficientDet 作为实验模型。

图3 EfficientDet 结构图Fig.3 EfficientDet architecture
2.2 试验设置
对划分出的3373 副小麦数据集进行训练,模型基于pytorch 框架编写,系统试验的硬件环境为CentOs 系统,NVIDIA Tesla v100 显卡。实验参数如下:Batch_size=2,number_workers=2,n_poches=40,lr=0.000 4。
2.3 麦穗检测试验
对五折划分后的数据集分别采用EfficientDet进行训练,得到5 个目标检测模型。采用多个检测模型分别对训练集进行检测,然后对训练集的检测结果采用加权盒融合算法进行检测结果的融合,具体实现方法如下:
每个模型的每个预测框都被添加到一个列表B 中。该列表按置信度得分的降序排序。
为盒子簇和融合盒子定义空列表L 和F。列表L 中的每个位置可以包含一组盒子(或单个盒子),形成一个簇。F 中的每个位置只包含一个盒子,这是来自L 中相应聚类的融合盒子。生成融合盒子的方程将在后面讨论。
循环遍历B 中的预测框,并尝试在列表F中找到匹配的框。匹配被定义为与所讨论的框有很大重叠的框(IoU>0.55)。如果未找到匹配,则将列表B 中的框添加到列表L 和F 内,作为新条目。进入B 中的下一个预测框,如果找到匹配,则将此框添加到列表L 中与列表L 中匹配框对应的位置。重新计算F 中的当前盒子坐标和置信度得分,使用L 中累积的对应位置的所有T 个盒子,融合公式如式(3)—式(5):
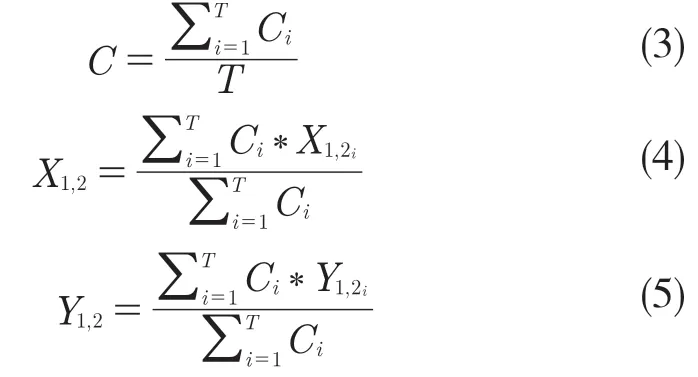
式中:C——置信度;T——检测框数量;X,Y——横纵坐标。
将融合盒子的置信度得分设置为组成它的所有盒子的平均置信度。融合盒子的坐标是组成它的盒子的坐标的加权和,其中权重是对应盒子的置信度得分,因此与置信度较低的盒子相比,具有较大置信度的盒子能够控制到融合后的盒子的坐标。
处理完B 中的所有盒子后,重新缩放F 列表中的置信度得分。将其乘以同一个类别中的盒子数量,然后除以模型数量n。以单个麦穗的检测框融合为例,加权盒子融合算法(WBF)流程图如图4 所示。

图4 加权盒子融合演示Fig.4 WBF demo
3 试验结果分析
3.1 评价指标
麦穗检测的主要指标是根据不同的交叉点(IoU)阈值的平均精度的平均值。具体计算方法如下[5-6]。
一组预测边界框和地面真实边界框的IoU 计算公式为
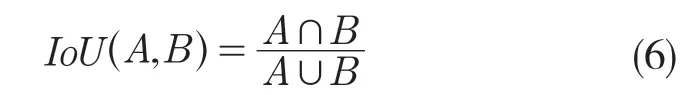
式中:A,B——真实框和预测框。
IoU 的阈值会在一定范围内变化,并在每个阈值下计算平均精度值。阈值从0.5 到0.75 按0.05等间隔变化。换句话说,在0.5 的阈值下,如果预测边界框与真实边界框的IoU 大于0.5,则将其视为预测准确。
对于每一个阈值t,精度值通过比较源于预测对象和真实对象的IoU。对于TP,FN,FP 计进行算,公式如式(7):
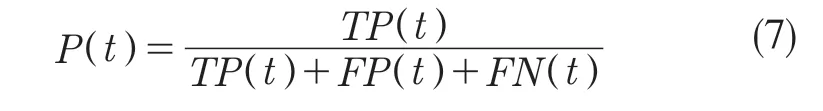
式中:P(t)——阈值t 时图像的平均精度,当预测对象和真实对象的IoU 大于阈值t 时,预测对象为TP;当预测对象和真实对象的IoU 小于阈值t 时,预测对象为FP;当真实对象不存在相匹配的预测对象时为FN。单张图像的平均精度值是指在不同阈值下的平均精度值求和的平均值,计算公式如式(8):
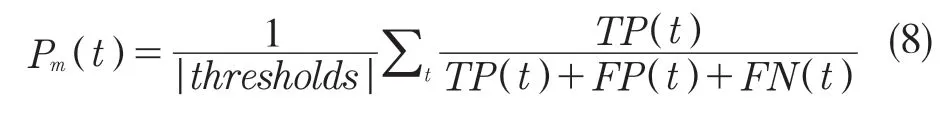
式中:thresholds——阈值的总数。
3.2 结果分析
根据评价指标,对测试集图片进行不同阈值下Iou 的平均精度的平均值进行计算,得到检测精度为0.732,部分检测成果如图5 所示。

图5 检测成果Fig.5 Detection results
4 结论
通过EfficientDet 方法构建了比较合适的全球小麦麦穗头的检测模型,实现了野外环境下对小麦麦穗头快速且较为准确的检测,模型的加测准确率为0.732 左右。
