基于便携式近红外光谱仪的樱桃番茄糖分快速分析模型
2021-12-27孙阳刘翠玲孙晓荣闻世震
孙阳,刘翠玲,孙晓荣,闻世震
(北京工商大学 人工智能学院,食品安全大数据技术北京市重点实验室,北京,100048)
樱桃番茄又名圣女果、千禧果、珍珠小番茄等,是茄科番茄属中多汁浆果一年生草本植物,被联合国粮农组织(Food and Agriculture Organization of the United Nations,FAO)列为优先推广的四大水果之一[1-2]。樱桃番茄表面光亮,色泽鲜艳,营养价值高,具有防癌、降压、降胆固醇等保健作用[3-7],近年来深受消费者喜爱。相比于人们日常食用的普通番茄,樱桃番茄的口感更佳,味道更甜。香甜可口也成为了樱桃番茄在如今市场备受欢迎的一大原因。影响樱桃番茄口感的因素有很多,如糖分、有机酸、纤维素等,但糖分是衡量樱桃番茄口感及品质的一项重要指标。
光谱检测技术作为一种快速的检测手段,目前已广泛应用于农业、工业、食品检测等领域[8]。常用的光谱检测技术有近红外光谱检测技术、拉曼光谱检测技术、高光谱成像检测技术、荧光光谱检测技术等[9-13]。目前,番茄的光谱检测大部分集中在使用实验室大型仪器上,对使用便携式近红外光谱仪器研究樱桃番茄光谱尤为少见,王凡等[14]建立了基于樱桃番茄近红外透射光谱的可溶性固形物含量分析模型,但对实验环境的要求很高,仪器昂贵,无法做到便携、快速地检测。雷鹰等[15]使用便携式近红外光谱仪器扫描苹果光谱数据,对苹果糖分含量建立模型,使用偏最小二乘算法最终得到的模型预测集相关系数为0.918 9,均方根误差为0.237;刘伟[16]使用便携式近红外光谱仪器,以赣南脐橙和苹果为实验对象,对这2种水果的光谱数据建立了糖度分析模型,赣南脐橙糖分分析模型预测集的相关系数为0.77,均方根误差为0.83,苹果糖分分析模型的预测集相关系数为0.75,均方根误差为0.82,均取得了较为理想的实验结果。在现实生活中,使用便携式仪器实现现场快速检测可以使果农们在种植樱桃番茄时能够无损地检测作物中的含糖情况,可依此来安排其具体采摘时间和进行光照及养分调整;同时在面向市场时,商家可以用该方法来检验货物以保证货物质量,更大程度上满足消费者们的需求。综上,在这些实际生活需求和众多研究基础上,本文提出用便携式近红外光谱仪器对樱桃番茄的糖分进行建模分析,实现现场的快速无损检测。
本研究使用AMBER Ⅱ便携式近红外光谱仪器,以樱桃番茄为实验样本,获取其近红外光谱数据。使用Kennard-Stone(K-S)算法对172个样本进行样本划分,用标准归一化(standard normal variate,SNV)和Savitzky-Golay卷积平滑相结合的方式对光谱数据进行预处理,将预处理过后的光谱数据进行无信息变量消除算法(uniformative variable elimination,UVE)和连续投影算法(successive projections algorithm,SPA)联合使用提取特征波长,在此基础上进行偏最小二乘(partial least squares,PLS)方法建模,建立樱桃番茄糖分预测模型。
1 材料与方法
1.1 实验仪器
AMBER Ⅱ便携式近红外光谱检测仪,北京凯胜天成科技有限公司。为使测量结果更为准确,设置样本扫描次数为10次,最终得到样品扫描10次的平均光谱。波长测量范围为900~1 700 nm,测量的波长点数为605个。通过USB接口与控制器进行连接。ANBER Ⅱ便携式近红外光谱检测仪器如图1所示。爱宕PAL-1数显糖度计,日本Atago。仪器的测量范围为:糖度(Brix)0.0%~53.0%;测量精度为:糖度(Brix)整幅0.2%。

图1 AMBER Ⅱ便携式近红外光谱仪Fig.1 AMBER Ⅱ portable near infrared spectrometer
1.2 实验方法
1.2.1 实验样本及糖度检测
实验样本为来自3个不同大型果蔬超市所采购的樱桃番茄,产地分别为海南省陵水市、广西省田阳县和福建省晋江市,样本总数为172个,平均果径为2.32 cm。
首先用水果刀将樱桃番茄从赤道处切开,将使用滤布过滤后的番茄汁液滴于检测仪器上用于检测,显示结果为23 ℃室温条件下的可溶性物质含量值(%Brix),将3次测量结果的平均值作为实际测量值。图2为樱桃番茄样本的糖分分布,从图中可知,采集到的样本糖分分布大致符合正态分布。
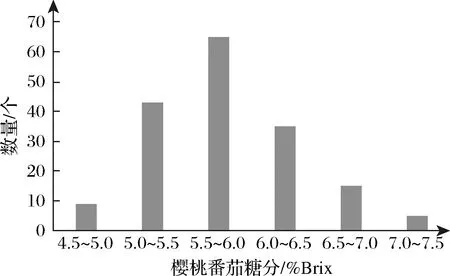
图2 樱桃番茄糖分与样品数量的关系图Fig.2 Relationship between cherry tomatoes sugar and sample quantity
1.2.2 实验样本光谱采集
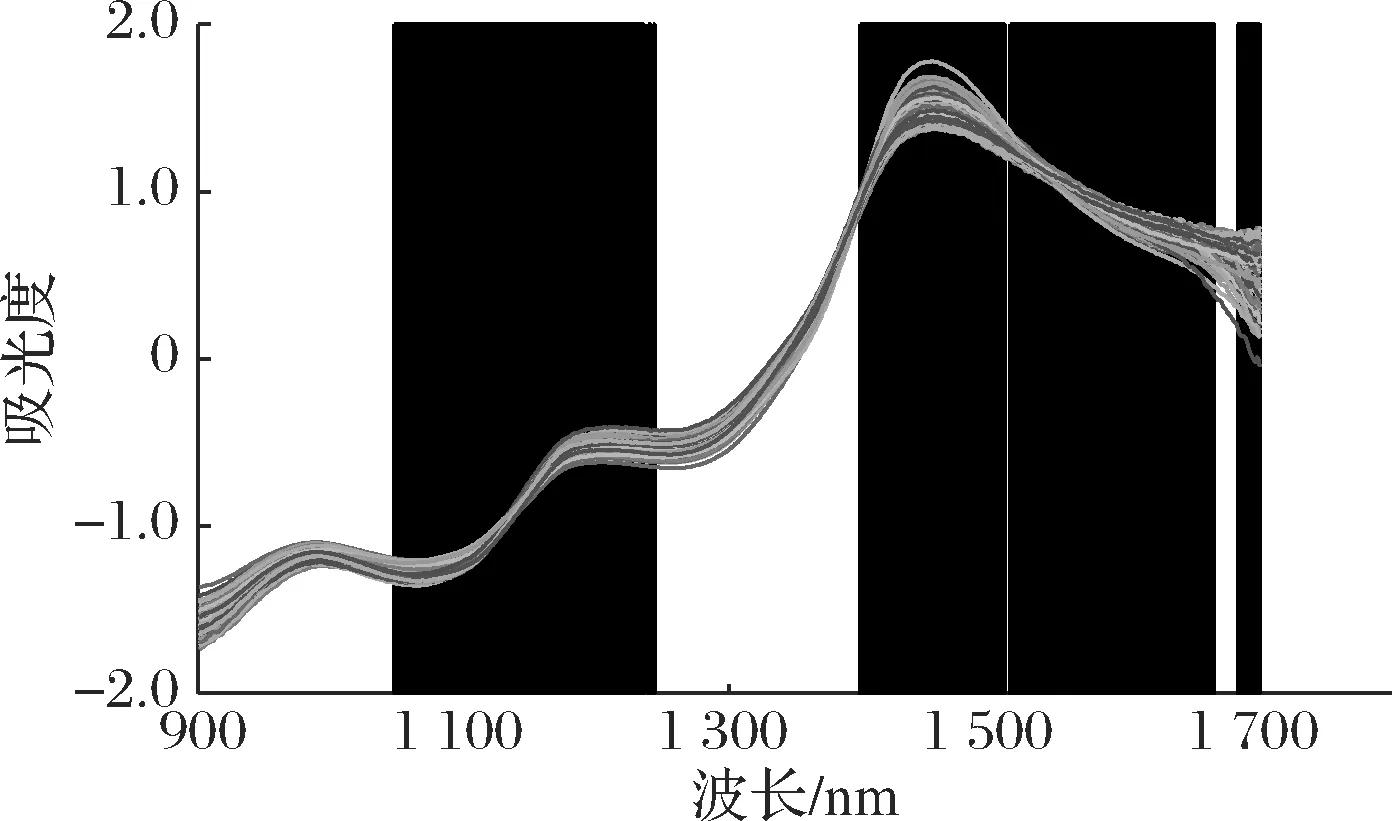
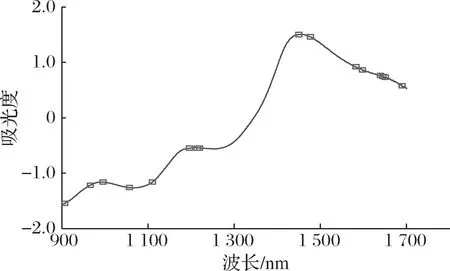
AMBER Ⅱ便携式近红外光谱仪器所检测的谱频区域为900~1 700 nm,获取的原始光谱如图3所示。光谱在980、1 200和1 450 nm处出现了波峰。樱桃番茄中的糖分主要为果糖、葡萄糖和蔗糖[17],1 080 nm处为C—H基团的2倍频吸收峰,980 nm处为O—H基团的二级倍频特征波峰,1 200 nm处为C—H键的二级倍频特征波峰,1 450 nm为C—H键的一级倍频特征波峰,具有较强特征性。
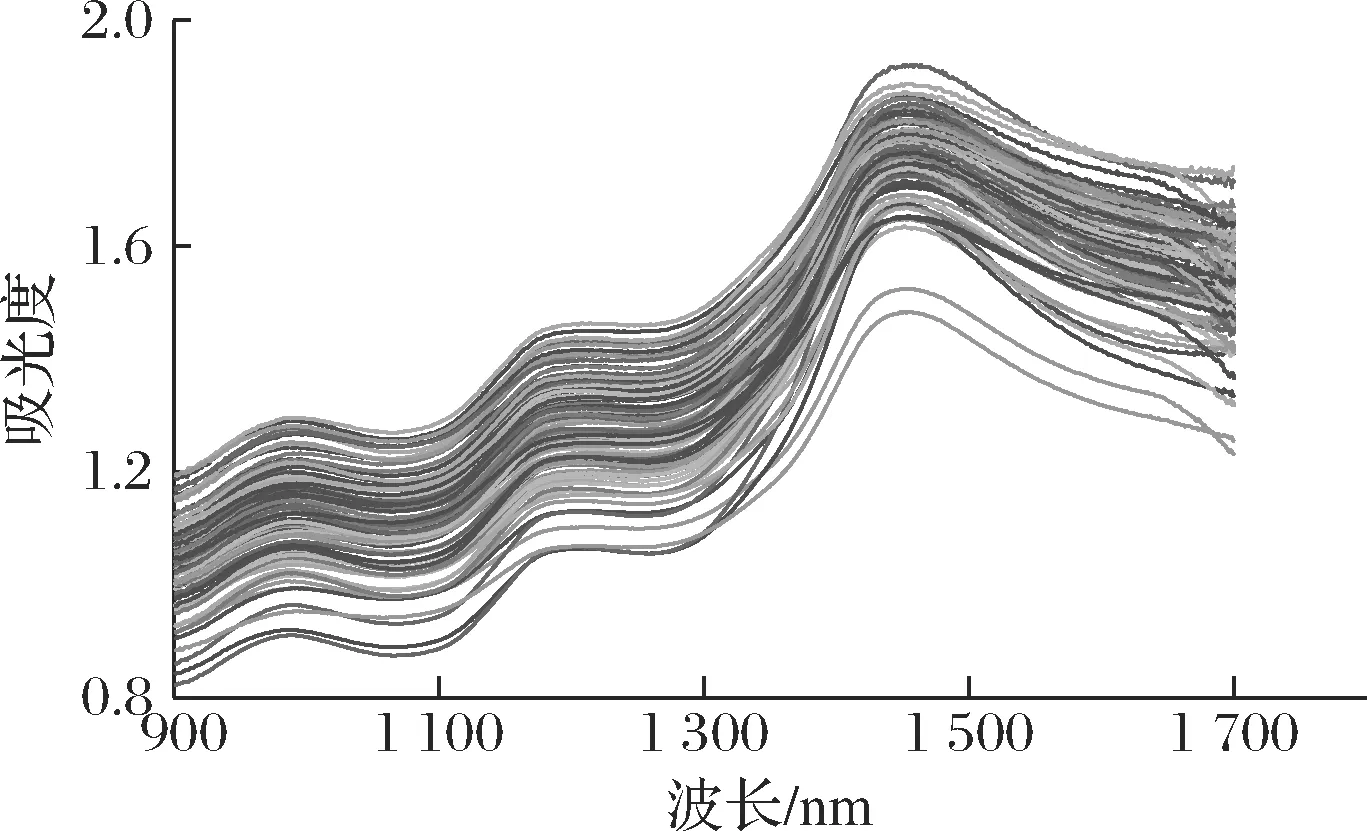
图3 樱桃番茄近红外原始光谱图Fig.3 Near infrared spectrum of cherry tomatoes
1.3 实验算法原理
1.3.1 Kennard-Stone算法
为了使所建立的模型鲁棒性更强,训练集和预测集的样品更具有代表性,使用K-S算法将样本集以3∶1的比例划分为训练集和验证集。K-S算法将所有的样本全部看作训练集的候选样本,随后依次从中挑选样本进行划分。该算法首先选择欧式距离最远的2个样本进入训练集,随后对剩下的样本计算到训练集中每一个已知样本的欧氏距离。分别找到拥有最大最小距离的样本放入训练集,以此类推,直到训练集样本个数达到数量要求。该算法的优点是可以确保训练集中的样本按照空间距离均匀的分布。欧式距离的计算如公式(1)所示。
(1)
式中:xp和xq,2个不同的样本;N表示样本的光谱点数。
1.3.2 UVE无信息变量消除法
UVE算法[18]是用于光谱波长变量筛选的一种算法。它可以有效减少最终PLS模型中包含的变量数,将有效的特征波段应用于模型中,从而降低PLS模型的复杂性,并且提高模型的预测能力。在实际采集的樱桃番茄光谱数据中,会有大量不包含糖分信息的波长点存在,因此为了提高模型精度,使用UVE算法去除不包含信息的波长点是尤为必要的。
UVE算法是一种基于分析PLS回归系数的算法,目的在于消除不提供有效信息的变量。在PLS模型中光谱数据矩阵(X)和浓度矩阵(Y)的回归关系如公式(2)所示。
Y=Xb+e
(2)
式中:b,模型的回归系数向量,e,误差向量。
UVE算法首先要产生一个与自变量矩阵相同变量数目的随机矩阵,将其等同于噪音,并将该随机矩阵加入到原光谱矩阵中。随后通过留一交叉验证的方法逐一建立PLS模型,最终得到回归系数的矩阵B。计算回归系数矩阵中的回归系数向量b的平均值和标准偏差的商,记为Ci,如公式(3)所示。
Ci=mean(bi)/S(bi)
(3)
式中:mean(bi),回归系数向量b的平均值;S(bi),回顾系数向量b的标准偏差,下标i为B矩阵中的第i列,具体算法如下:
(1)产生一随机噪声矩阵R(n×m),将其与光谱矩阵X(n×m)合成矩阵XR(n×2m),其中前m列为X后m列为R;
(2)将矩阵XR与浓度矩阵Y(n×1)进行PLS回归,使用留一交叉验证方法,每次得到一个回归系数向量b,共得到n个回归系数向量,组成矩阵B(n×2m);
(3)按列计算回归系数矩阵B平均值与标准偏差的商,计算Ci=mean(bi)/S(bi),i=1,2,…,2m;
(4)在[m+1,2m]区间取C的最大绝对值Cmax=max[abs(C)];
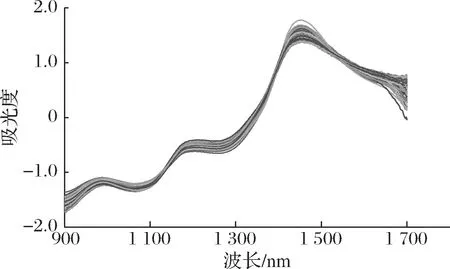
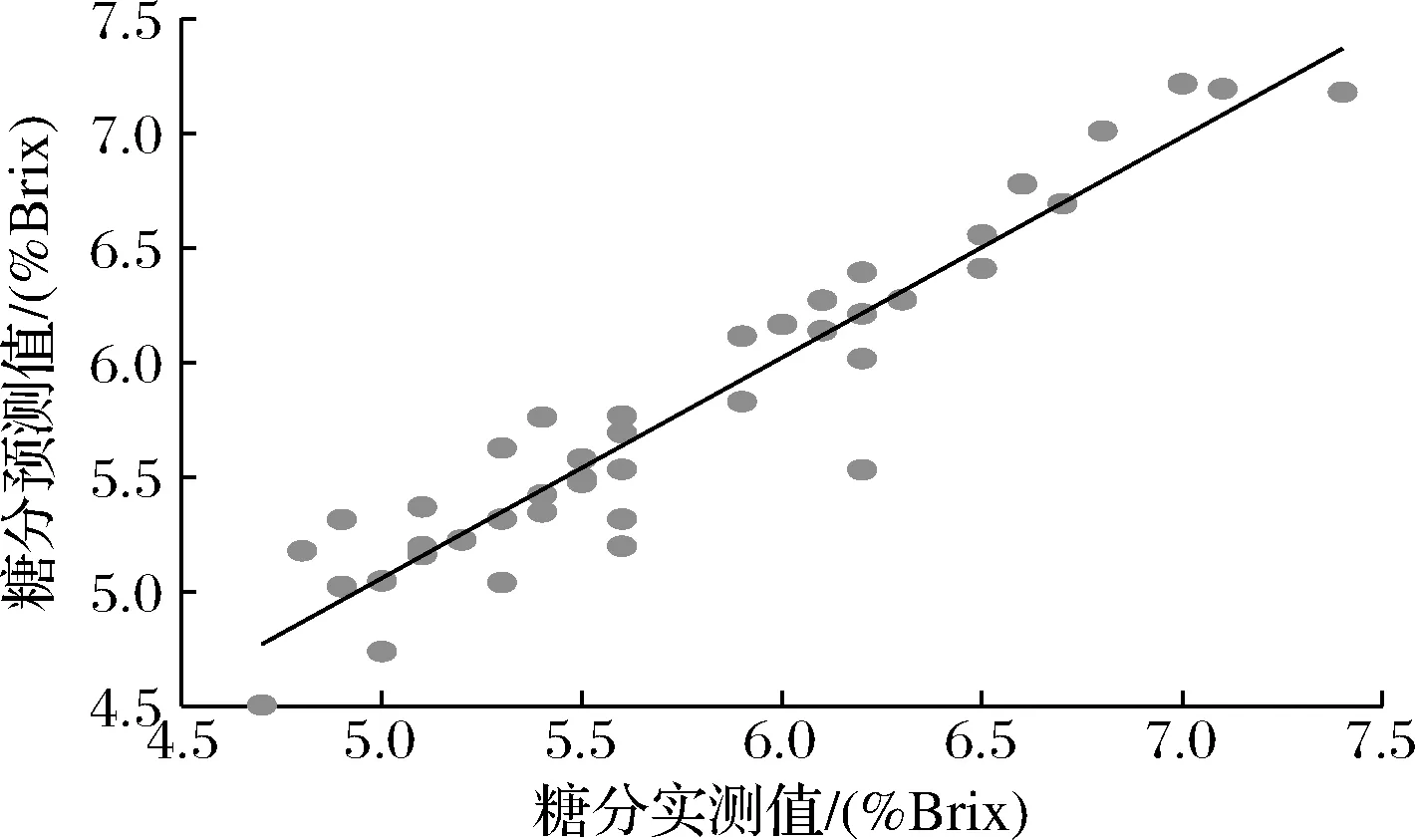
(5)在[1,m]区间内去除Ci 1.3.3 SPA连续投影算法 SPA算法[19-20]为一种波长选择算法,该算法对波长进行选择的主要原理是从某一个波长点出发,不断地采用连续投影策略选择与已有波长线性相关度最小的波长点构成一个波长子集,重复这一操作选出一系列的波长子集,随后将这些选择出来的波长子集建模后的模型预测能力进行比较,选出结果最优的波长子集。计算未选择变量xj(j∈s)在已选择的特征变量xk(t-1)构成的正交子空间上的投影,如公式(4)所示。其中,P为投影算子;I为单位矩阵。这一算法的优势在于尽可能地降低了被选波长之间所存在的共线性问题。 (4) 在本研究中使用的模型评价指标有决定系数、验证均方根误差 (root-mean-square error of collection,RMSEC)、预测均方根误差 (root-mean-square error of prediction,RMSEP)和相对分析误差(relative percent deviation,RPD)。其中,模型最终计算出的RMSEC和RMSEP的值越小、R2的值越接近于1则说明模型越稳定,预测能力越强。一般情况下,RMSEC和RMSEP的值相差不多,若RMSEC和RMSEP的值相差过大,则说明建模集样本或预测集的样本不具有代表性,出现了欠拟合或过拟合的状况,需要重新对样本集进行划分。RPD的值可以说明模型的预测能力,当其值大于1.4时便说明该模型数据有预测能力,值越大则说明模型的预测能力越强。RMSEP和RMSEC的计算公式相同,如公式(5)所示,R2的计算公式如公式(6)所示。 (5) (6) 采集的实验样本一共为172个,利用K-S算法对实验样本数据进行分析。以3∶1的比例将样本划分为建模集和预测集,即建模集样本为129个,预测集样本为43个。样本划分过后的糖含量统计值如表1所示。 表1 样本含糖量统计表Table 1 Statistical value of sample sugar content 在原始光谱数据中可以观察到,该光谱数据具有明显的噪音及漂移,因此在建立模型前对光谱数据进行预处理。预处理方法选用了SNV、Savitzky-Golay卷积平滑处理和一阶导数差分[21-23]。使用不同预处理方法后基于PLS方法建模的结果如表2所示。 表2 樱桃番茄糖分模型不同预处理方法建模结果Table 2 Modeling results of different pretreatment methods for sugar model of cherry tomatoes 由表2可知,无论是用哪一种预处理方案,该模型验证集和预测集的R2均>0.7,RPD均>1.4,说明每一种预处理方案下的模型均具有一定的预测能力。但采用SNV+S-G卷积平滑预处理方法后所建立模型的R2值最大,且RMSEC和RMSEV的值最小,说明在该预处理方法下的模型性能为最优。预处理过后的近红外光谱图如图4所示。 图4 樱桃番茄近红外预处理光谱图Fig.4 Near infrared pretreatment spectrum of cherry tomatoes 2.3.1 基于全谱段的PLS樱桃番茄糖分分析模型 选择最佳预处理方法后,使用全波段的光谱数据进行PLS建模分析,最终得到的糖分分析模型建模集和预测集的决定系数R2分别为0.894 2和0.892 9,预测均方根误差RMSEC和RMSEP分别0.159 6和0.223 4,RPD的值为2.22。预测结果如图5所示。 图5 全谱段的PLS模型樱桃番茄糖分预测结果Fig.5 Prediction of sugar content in cherry tomatoes based on PLS model 2.3.2 基于UVE-PLS的樱桃番茄糖分预测模型 为使模型更加简化,降低模型计算量,提高预测精度,将SNV+S-G卷积平滑预处理过后的光谱数据用UVE特征波段筛选方法对605个波长点进行筛选,将与预测糖分无关的特征变量去除[24]。UVE算法共去除了231个无信息波长点,保留信息变量374个。用全部波段的61.8%建立樱桃番茄糖分的定量分析模型,最终所选取的波段如图6所示。 图6 UVE算法对特征波段筛选的结果Fig.6 The result of selecting characteristic wavelength by UVE algorithm 基于UVE-PLS方法建立的樱桃番茄糖分模型建模集和预测集的决定系数R2分别为0.929 5和0.899 9,预测均方根误差RMSEC和RMSEP分别为0.135 9和0.215 9,RPD的值为2.29。预测结果如图7所示。 图7 UVE-PLS模型樱桃番茄糖分预测结果Fig.7 Prediction results of sugar content of cherry tomato based on UVE-PLS model 2.3.3 基于SPA-PLS樱桃番茄糖分预测模型 对樱桃番茄的光谱数据进行SNV+S-G卷积平滑预处理,将预处理过后的光谱进行SPA特征波长提取。由于SPA算法要求在优化过程中生成的每个波长子集的波长点数的数目是不能超过校正集中的样本个数的,因此在本实验中,用SPA算法所提取出的特征波长数量一定会少于21个,这使变量输入到PLS模型后的计算量在很大程度上得到了简化。使用SPA算法最终提取到了16个特征波长点,分别是906.15、966.04、995.60、1 056.44、1 109.99、1 196.42、1 214.36、1 220.32、1 450.70、1 476.74、1 582.20、1 596.57、1 639.11、1 644.12、1 650.11、1 689.61 nm。结果如图8所示。 图8 SPA算法选择的特征波段Fig.8 Characteristic wavelength selected by SPA algorithm 图9显示了基于SPA算法的PLS模型用不同波长数量进行交叉验证的均方根误差结果。随着选择的波段数的增加,PLS模型的均方根误差值在逐渐减小,随后减小趋势逐渐平缓最后几乎不变。当选择的波长数量<16时的均方根误差的值下降速率较快,当选择波长数量>16后,均方根误差的下降速率明显减小。因此,SPA算法最终选择的波长变量数为16个。 图9 SPA算法选择的变量个数Fig.9 Prediction results of sugar content of cherry tomato based on SPA-PLS model 将提取过后的特征波长进行PLS建模,建模集和预测集的决定系数R2分别为0.930 1和0.918 6,预测均方根误差RMSEC和RMSEP分别为0.130 4和0.194 7,RPD的值为2.53。预测结果如图10所示。 图10 SPA-PLS模型樱桃番茄糖分预测结果Fig.10 Prediction results of sugar content of cherry tomato based on SPA-PLS model 2.3.4 基于UVE-SPA-PLS樱桃番茄糖分预测模型 在研究中,分别将樱桃番茄的光谱数据进行了UVE和SPA算法的特征波长提取。单独使用UVE算法时,尽管消除了部分不具有信息的特征波长点,但被选择的特征波长点之间会存在共线性问题。同样,当在单独使用SPA算法进行特征波长提取时,虽然降低了特征波长点之间的共线性,但所选择的波长子集中很可能会包含一些无信息的、甚至会产生干扰的波长[25]。因此,在本实验中将UVE算法与SPA算法联合,实现两者之间的优势互补,建立基于UVE-SPA特征波段选取的PLS樱桃番茄糖分模型。经过2种算法的计算,最终被选取的特征波长点分别为1 056.44、1 109.99、1 196.42、1 214.36、1 220.32、1 476.74、1 582.20、1 596.57、1 639.11、1 644.12、1 650.11、1 689.61 nm,共12个特征波长点。基于UVE-SPA-PLS方法所建立的樱桃番茄糖分模型建模集和预测集的决定系数R2分别为0.938 5和0.934 7,预测均方根误差RMSEC和RMSEP分别为0.130 5和0.174 4,RPD的值为2.81。预测结果如图11所示。 图11 UVE-SPA-PLS模型樱桃番茄糖分预测结果Fig.11 Prediction results of sugar content of cherry tomato based on UVE-SPA-PLS model 表3是基于不同波长提取算法下PLS模型的模型参数,从表中可以看出,经过特征波长提取后的模型决定系数R2和相对分析误差RPD的值均有所提高,均方根误差RMSEC和REMSP均有所降低。其中UVE和SPA特征波长选取方法联合使用既去除了无消息特征波长点,又降低了波长之间的共线性,因此UVE-SPA-PLS建模方法达到的效果最佳。 表3 不同波长提取方法PLS建模结果表Table 3 PLS modeling results of different wavelength extraction methods 本实验用AMBER Ⅱ便携式近红外光谱仪器采集樱桃番茄的近红外光谱图,使用K-S算法将样本以3∶1的比例进行划分,建模集样本个数为129个,预测集样本个数为43个。用PLS方法建模,经过多种预处理方法比较,选用S-G卷积平滑和SNV预处理方法的建模结果最佳。建模集和预测集的决定系数R2分别为0.894 2和0.892 9,均方根误差RMSEC和REMSP分别为0.159 6和0.223 4,RPD的值为2.22。 对预处理过后的光谱数据分别使用UVE、SPA和UVE-SPA联合这3种方法进行特征波长提取,最终使用UVE-SPA特征波长提取方法提取到的12个特征波长进行PLS建模效果最佳,建模集和预测集的决定系数R2分别为0.938 5和0.934 7,均方根误差RMSEC和REMSP分别为0.130 5和0.174 4,RPD的值为2.81。建模集和预测集的决定系数都达到了0.9以上,均方根误差也都较低,说明了使用便携式近红外光谱仪扫描的数据可以建立精度较高的樱桃番茄的糖分预测模型。 在进一步研究中,应扩大样本获取范围,采集更多不同产地的樱桃番茄,增大样本数量,增大样本的糖分范围,尽量使不同产地樱桃番茄的采摘时间大致相同,使模型的预测性更高,应用更加广泛。1.4 模型评价标准
2 结果与分析
2.1 样本划分

2.2 光谱数据预处理

2.3 樱桃番茄糖分分析模型建立





3 结论与讨论
