基于无人机多光谱数据的水稻LAI反演与应用
2021-12-24刘小娟莫佳才
王 靖 彭 漪* 刘小娟 莫佳才 梁 婷
(1.武汉大学 遥感信息工程学院,武汉 430079; 2. 武汉大学 生命科学学院,武汉 430072)
水稻是我国重要粮食作物之一,2019—2020年我国水稻的消费量约为2亿t,占全世界水稻消费总量的40.8%,水稻生产直接影响到我国的粮食供应与世界粮食市场的平稳[1]。叶面积指数(Leaf area index, LAI)是单位土地面积上植株单侧叶片平铺面积的总和,与作物的色素含量、碳循环、生物量、物候等生化参数密切相关,是表征作物生长状况以及预测作物生物量的重要参数[2]。
传统叶面积指数测量方法费时费力,便捷、高效的遥感技术助力精准农业。遥感技术依据传感器搭载平台可大致分为地面平台和卫星平台2 类。在地面平台上,通过测量多光谱或高光谱数据计算红边参数、植被指数和其他光谱特征参数建立LAI反演的经验或半经验模型[3-5]仍是目前估算LAI的主流方法,地面平台可获取高空间分辨率和高时间分辨率的数据,但在测量大范围的田块时人工成本较高;在卫星平台上,利用影像对LAI的估算也取得了一定的发展,如MODIS-LAI[6]和GLASS LAI[7]产品已经在大范围得到应用。由于卫星LAI产品空间分辨率较低,无法为精准农业提供支撑。无人机兼具有高空间分辨率和高时间分辨率的特点,可以短时间内获取较大范围的高分辨光谱影像[8]。依据无人机影像数据反演LAI的植被指数法[9]、改进型光谱特征参数法预测LAI[10]以及使用无人机影像数据的纹理特征估计LAI[11]等方面均已有研究。
基于各种技术平台的不同反演方法虽然可以取得较好的反演精确度,但大都只是将单个试验区的数据分成建模集和验证集来进行反演与精确度验证,应用上受限于试验区域的跨度与遥感平台的限制,对于不同区域模型的可移植性缺乏验证。机器学习本质上属于基于先验知识的统计模型,常用的植被指数经验回归反演LAI方法也属于机器学习方法的一种[12]。由于机器学习模型仅学习已知样本,并基于统计学知识对结果进行解释,因此当环境胁迫因素发生改变,模型训练容易过拟合或欠拟合,再加上不同模型机理的限制,会对不同模型的迁移性产生不同影响[13]。
鄂州与海南区域跨度大,两地地理环境因素差异大,并且试验区数据包含了不同品种的水稻。因此,为检测机器学习模型反演LAI的可移植性,本研究拟以鄂州与海南两地的水稻为研究对象,依据无人机平台获取的水稻不同生育期的多光谱影像数据,采用鄂州水稻影像光谱数据作为建模集,并采用海南试验区的水稻影像数据作为验证集,评估海南试验区的水稻生长状况,以期为水稻LAI机器学习估计模型的迁移性验证提供依据,同时为海南地区水稻品种选择提供参考。
1 研究区域与数据
1.1 研究区域概况
本研究选择华中及华南地区2个不同地域、不同气候类型的试验区。
华中试验区位于湖北省鄂州市试验基地(30°22′22.27″ N, 114°45′7.03″ E),地处长江中游南岸,属亚热带季风气候,夏季高温多雨,适宜水稻生长。试验区分为48个小块,种植48种不同品种的水稻,总面积约为2 000 m2(图1(a))。2019年5月11日育秧,6月9日移栽,移栽密度为22.5×106株/km2,施肥适量且均等。
华南试验区位于海南省陵水黎族自治县多品种杂交水稻试验基地(18°31′47.10″ N,110°03′34.90″ E),属典型的热带岛屿季风型气候,全年高温,干湿季分明,土壤肥沃(图1(b))。试验区总面积为518.24 m2,分成了12个小块,种植了珞优9348和丰两优4号2 种水稻,并分别施用了4种不同的氮肥水平,N00、N08、N12和N16分别代表纯氮0、12 000、18 000、240 000 kg/km2,氮肥分3次施用,其中基肥(50%)、幼穗分化期(25%)、抽穗期(25%)。磷肥、钾肥均基肥施用(磷肥:P2O59 000 kg/km2;钾肥:18 000 kg/km2)。2017年11月10日育秧,12月10日移栽,移栽密度为22.5×106株/km2。
1.2 数据获取
1.2.1无人机影像数据
试验采用大疆公司生产的多轴八旋翼无人机,搭载了Mini MCA 12通道数码相机(Mini-MCA 12, Terracam Inc., Chatsworth, CA, USA),相机每个通道1 280像素×1 024像素,各通道波长及波段宽度见表1。无人机影像数据采集尽量选择在无云无风、中午12点左右太阳高度角近似90°的时候进行,航高约为200 m。
湖北省鄂州杂交水稻试验基地选定13个测量日期为:2019-06-26、2019-07-02、2019-07-06、2019-07-16、2019-07-21、2019-07-26、2019-08-01、2019-08-06、2019-08-11、2019-08-17、2019-08-21、2019-08-26、2019-09-02。海南省陵水杂交水稻试验基地选定9个测量日期为:2018-01-29、2018-02-02、2018-02-07、2018-02-12、2018-02-20、2018-03-03、2018-03-11、2018-03-25、2018-04-01。
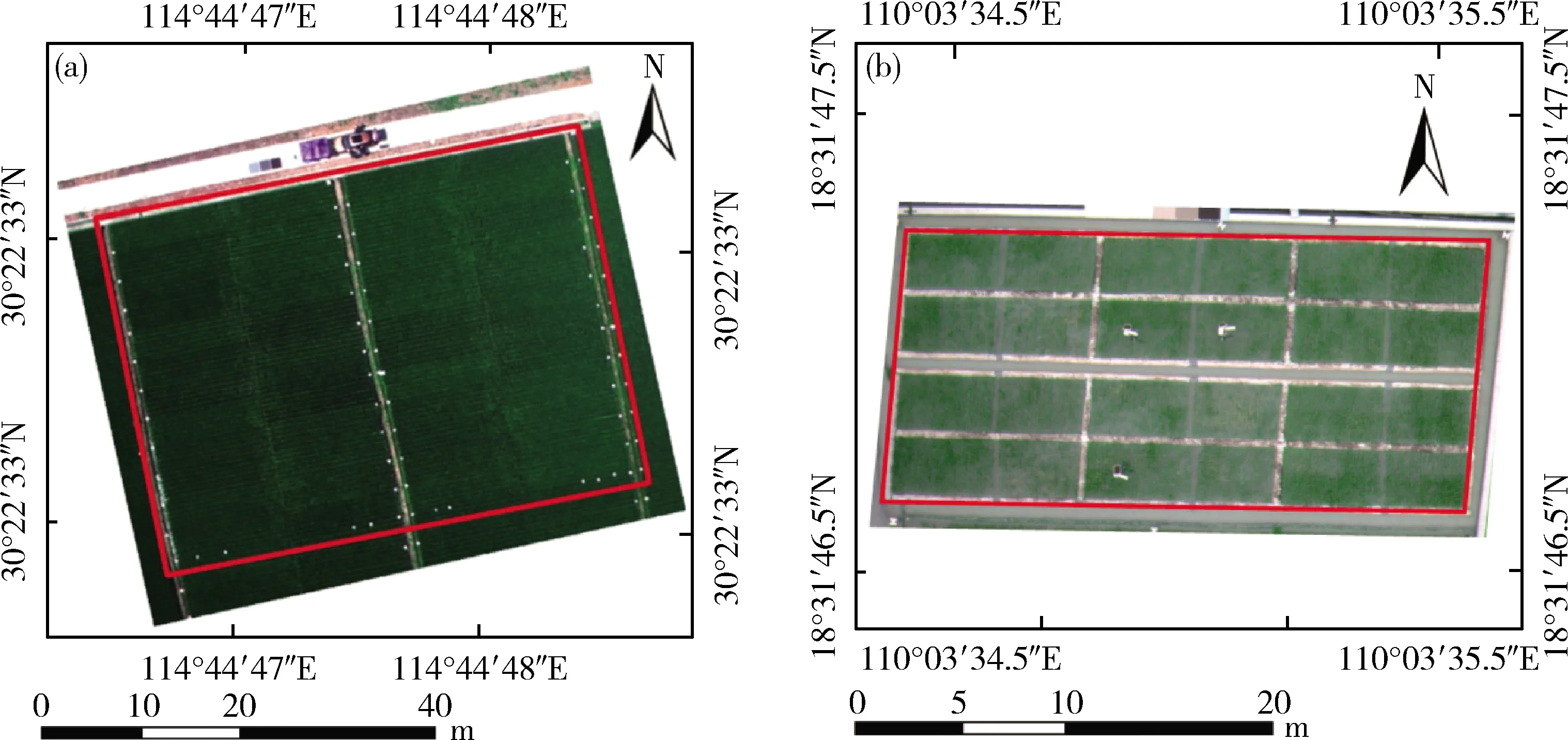
图1 湖北鄂州(a)与海南陵水(b)试验田Fig.1 Experimental field in Ezhou, Hubei Province (a) and Lingshui, Hainan Province (b)
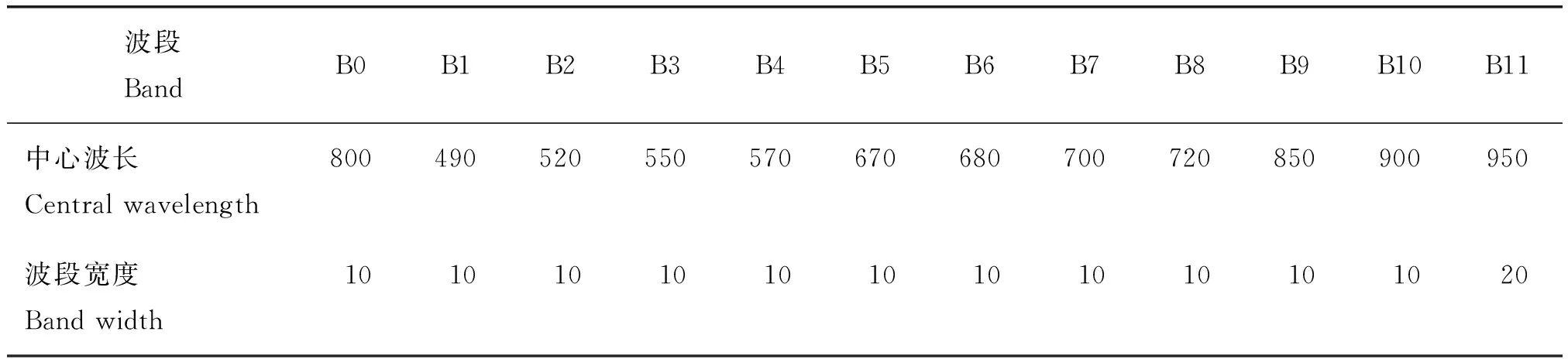
表1 无人机传感器12通道中心波长及波段宽度Table 1 Central wavelength and band width of 12 bands of UAV sensor
1.2.2叶面积指数测量
叶面积指数的测量使用LAI-2200植物冠层分析仪(LI-COR 2010)(LI-COR Inc., Lincoln, Nebraska, USA)对水稻进行非破坏性有效的叶面积值测量。LAI-2200配备鱼眼光学传感器,其中5 个同心环的天顶角中心分别为7°、22°、38°、52°和68°,通过测量上下辐射冠层,估算5个角度的冠层光截距和透射率,进而使用Beer-Lambert定律来计算叶面积指数,是室外试验广泛使用的叶面积测量仪器[14]。为了避免直射阳光引起的测量误差,测量时间在06:30—09:30和16:30—19:30进行,与MCA无人机测量日期同步。
1.3 数据处理
1.3.1几何校正
Mini MCA多光谱相机为推扫式相机,在实验室内对MCA相机的镜头进行几何校正,使得12个波段的多光谱影像位于同一坐标系,并消除影像的镜头畸变,用以下公式对无人机多光谱影像进行几何校正:
Δx=(x-x0)(k1r2+k2r4+k3r6)+p1(r2+2(x-x0)2)+2p2(x-x0)(y-y0)+α(x-x0)+β(y-y0)
(1)
Δy=(y-y0)(k1r2+k2r4+k3r6)+p2(r2+2(y-y0)2)+2p1(x-x0)(y-y0)
(2)

利用以上公式几何纠正单波段影像,其他镜头根据相似关系进行配准。
1.3.2辐射校正
此外,将数字灰度值(Digital number,DN)转化成具有实际物理意义的地物光谱反射率ρ需要进行辐射校正。利用地面标准辐射定标版的已知反射率,与影像DN值建立线性回归模型对影像进行辐射定标,6块定标毯在可见光至近红外波段范围内的反射率值依次为:0.03、0.12、0.24、0.36、0.56和0.80,根据以下公式定标:
Ri=DNi×Gaini+Offseti
(3)
式中:Ri为第i波段的地表反射率;i=1,2,…, 12;DNi为传感器在第i波段的DN值;Gaini为第i波段的增益系数;Offseti为第i波段的偏置值。
1.3.3水稻分类
图像预处理完成后,将每个田块中所有水稻像元的反射率进行平均计算,将平均值作为每个田块LAI测量值所对应的光谱反射率,因此需要先将水稻像元从背景中提取出来。计算像元NDVI,并使用K均值聚类将像元分为植被与非植被2 类,从而提取田块中的水稻像元。利用目视勾选田块像元,检验分类精确度,均达到了92%以上。
2 试验方法
本研究将光谱数据及光谱数据经过计算得到的植被指数与测量LAI建模,采用传统植被指数经验模型以及机器学习的方法,完整的技术路线图如图2 所示。
2.1 植被指数经验模型
植被指数提取出植被的光谱反射特征,与叶面积指数表现出强相关性。基于植被指数的经验模型需要确定3个关键要素:光谱特征参数、经验关系数和用于模型参数计算的叶面积指数[15]。本研究中使用2种回归模型:
线性模型:y=ax+b非线性模型:y=alnx+b
式中:y为计算的植被指数;x为实测的LAI值;a和b分别为待求解的系数。
选取8种经典的植被指数参与模型反演,如表2 所示,其中ρgreen、ρred、ρrededge、ρNIR所用波段分别为550、670、720、800 nm。
2.2 机器学习方法
采用比较常见的用于多元向量拟合的机器学习方法,将不同波段组合的光谱反射率作为特征值,投入回归算法进行训练。使用的方法有:贝叶斯岭(Bayesian ridge, BR)[22]、随机森林(Random forest, RF)[23]和梯度提升回归(Gradient boosting regression, GBR)[24]这3种常见的机器学习算法。
贝叶斯岭回归(BR)的核心思想是贝叶斯估计,岭回归则是在贝叶斯线性回归的损失函数中加入了一个范数的惩罚项。贝叶斯岭回归不仅可以解决极大似然估计找那个存在的过拟合问题,而且对样本数据的利用率是100%,同时对于样本中存在多重共线性的情况保持较好的稳定性。
随机森林(RF)是一种以决策树为基分类器的集成学习算法。每棵子树在训练时从原始的样本中随机进行有放回的采样,同时在构建决策树时从总的特征中随机的选择一部分特征用于训练。因此随机森林中基分类器的多样性不仅来自样本的扰动,还来自特征的扰动,这就使得最终集成的泛化性能可以通过个体学习器之间的差异度的增加而进一步提升。
梯度提升回归(GBR)算法的思想借鉴于梯度提升法,基本原理是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。GBR算法不需要对数据进行缩放就可以表现的很好,而且适用于二元特征与连续特征同时存在的数据集。

图2 技术路线Fig.2 Technology roadmap

表2 植被指数计算公式Table 2 Formula of vegetation index
2.3 模型验证及评价标准
本研究中,鄂州试验区共有587个有效样本,其中抽穗前有381个样本,满足正态分布;海南试验区共有215个有效样本,皆为水稻抽穗前数据,其中珞优9348有107个样本,丰两优4号有108个样本,皆满足正态分布。本研究使用K折交叉验证对模型反演精确度进行评估[25],避免模型对样本的偏重,直接估计泛化误差。模型的精确度评价由决定系数(R2)和变异系数(CV)来表征。
3 结果与分析
3.1 鄂州试验区建模精确度
K折交叉验证选择K=3,将鄂州试验区的样本分成3份,每份包含127个样本点。选择MTVI1、EVI2、OSAVI、MTCI、NDRE、CIgreen、NDVI和CIrededge这8种植被指数,分别用线性函数和非线性函数进行回归,结果见图3。由图3可知,除了CIgreen、CIrededge,MTCI这3 种指数,其他指数的线性模型精确度都要低于非线性模型。非线性模型精确度最高的植被指数为EVI2(R2=0.66,CV=29.83%);线性模型精确度最高的植被指数为MTCI(R2=0.64,CV=30.96%)。而NDVI(R2=0.25)和CIgreen(R2=0.34)两种植被指数,线性和非线性模型的R2都小于0.4,因此后续海南试验区验证模型精确度不使用这两种指数。
从1到12个波段依次增加波段数量,并列出所有可能的波段组合,然后投入机器学习算法。该穷举法是为了找到机器学习最佳的波段组合,判断最佳波段组合的依据是CV达到最小,结果见图4。从图中可以看到,4种机器学习算法在波段数量为1~4 的时候精确度迅速提升,但再随着波段数的增加,大约在波段数>5的时候精确度不再出现明显提升,在波段数>9的时候,RF、GBR和BR算法的拟合精确度反而出现下降的情况。
将经验回归模型中拟合精确度最好的EVI2非线性模型(CV=29.83%)以及MTCI线性模型(CV=30.96%)与其他机器学习算法一起进行比较,在投入相同的波段数下,机器学习模型的精确度高于植被指数回归模型,其中在投入2、3波段数时GBR模型精确度最优,CV分别为28.46%和26.45%。
3.2 海南试验区验证精确度
将海南试验区的数据输入用鄂州数据集训练好的EVI2、MTCI、MTVI1、CIrededge、NDRE、OSAVI等6 种植被指数的线性与非线性回归模型,以及最佳2波段、3波段组合的BR、GBR、RF这3种种机器学习模型。共计18个模型。为了消除不同波段量纲的影响,使用CV作为评价标准,结果见表3。表3比较了鄂州试验区的建模精确度和海南试验区的验证精确度:首先,OSAVI的线性与非线性回归模型在海南试验区CV>1 000%,已经完全不适用,一定程度上反映鄂州与海南两地的土壤条件差异;其次,与线性模型与机器学习模型相比,非线性的植被指数模型的推广性较差。除去MTVI1的非线性拟合模型推广后依然较为稳定(鄂州区CV=31.96%,海南区CV=30.73%),其余非线性植被指数模型在推广至海南试验区后,CV升高且超过了40%。
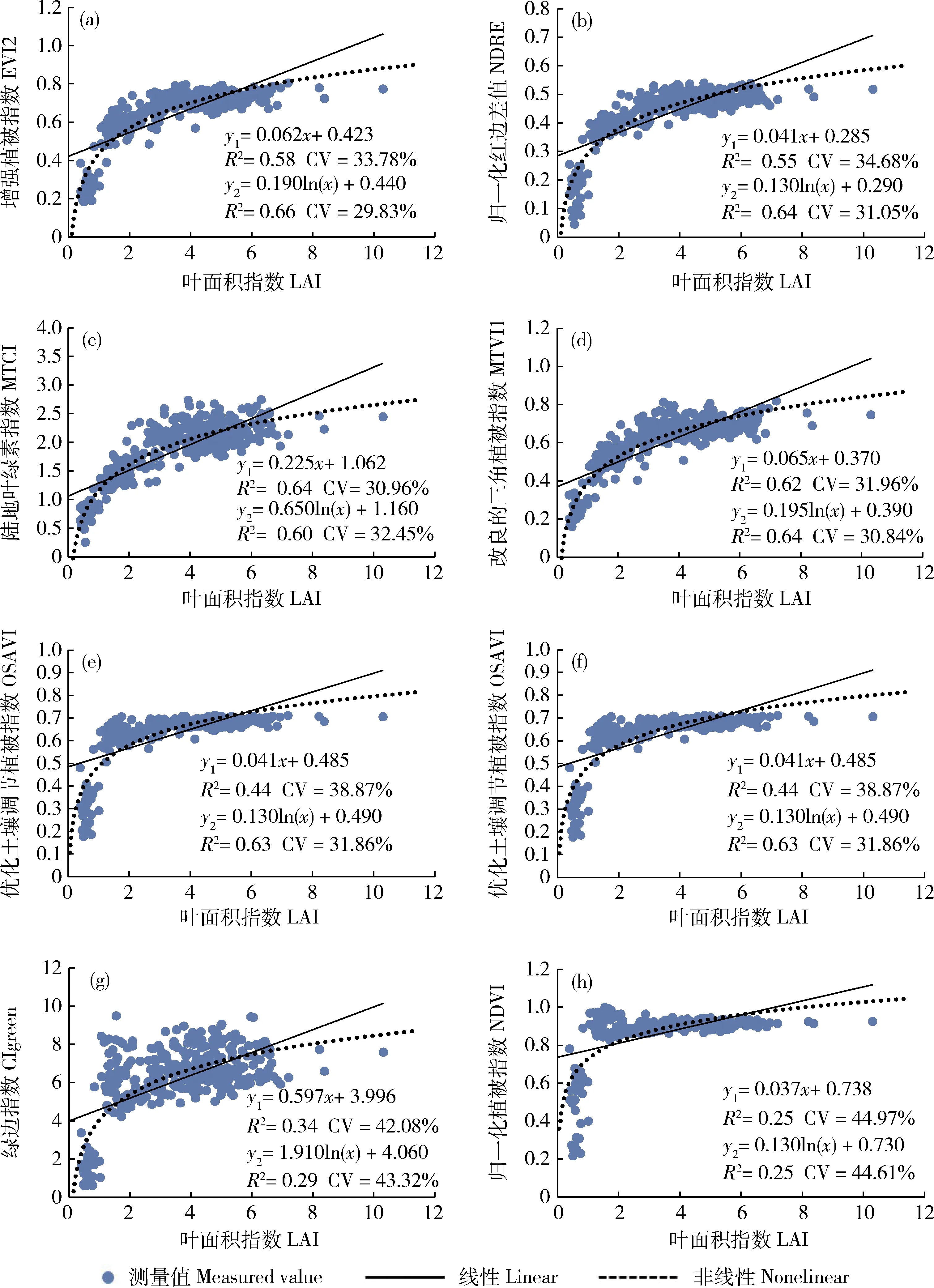
x代表LAI,y1代表线性模型的回归结果,y2代表非线性模型的回归结果。 x represents LAI, y1 represents the regression result of linear model, and y2 represents the regression result of nonlinear model.图3 8种植被指数线性与非线性模型模型Fig.3 Linear model and nonlinear model of 8 vegetation index
将海南试验区的估计值与真实值进行比较,结果见图5。首先在试验设计之初,测量日期2月12日—2月20日是水稻生长迅猛的时间,由于并未缩短测量间隔,因此造成了LAI 2~3的一段空缺,但这不影响模型的验证。从图5中可以发现: RF算法当LAI较高时,易出现偏低估计,且精确度点分布较散。BR算法精确度点分布则出现了偏离的情况,在LAI较低时估计偏低,在LAI较高时则估计偏高。对于植被指数的线性拟合模型来说,基本上在LAI较低的情况下都会出现估计偏低的情况,对于植被指数的非线性拟合模型,在LAI较高的情况下估计分散,且估计普遍偏高。
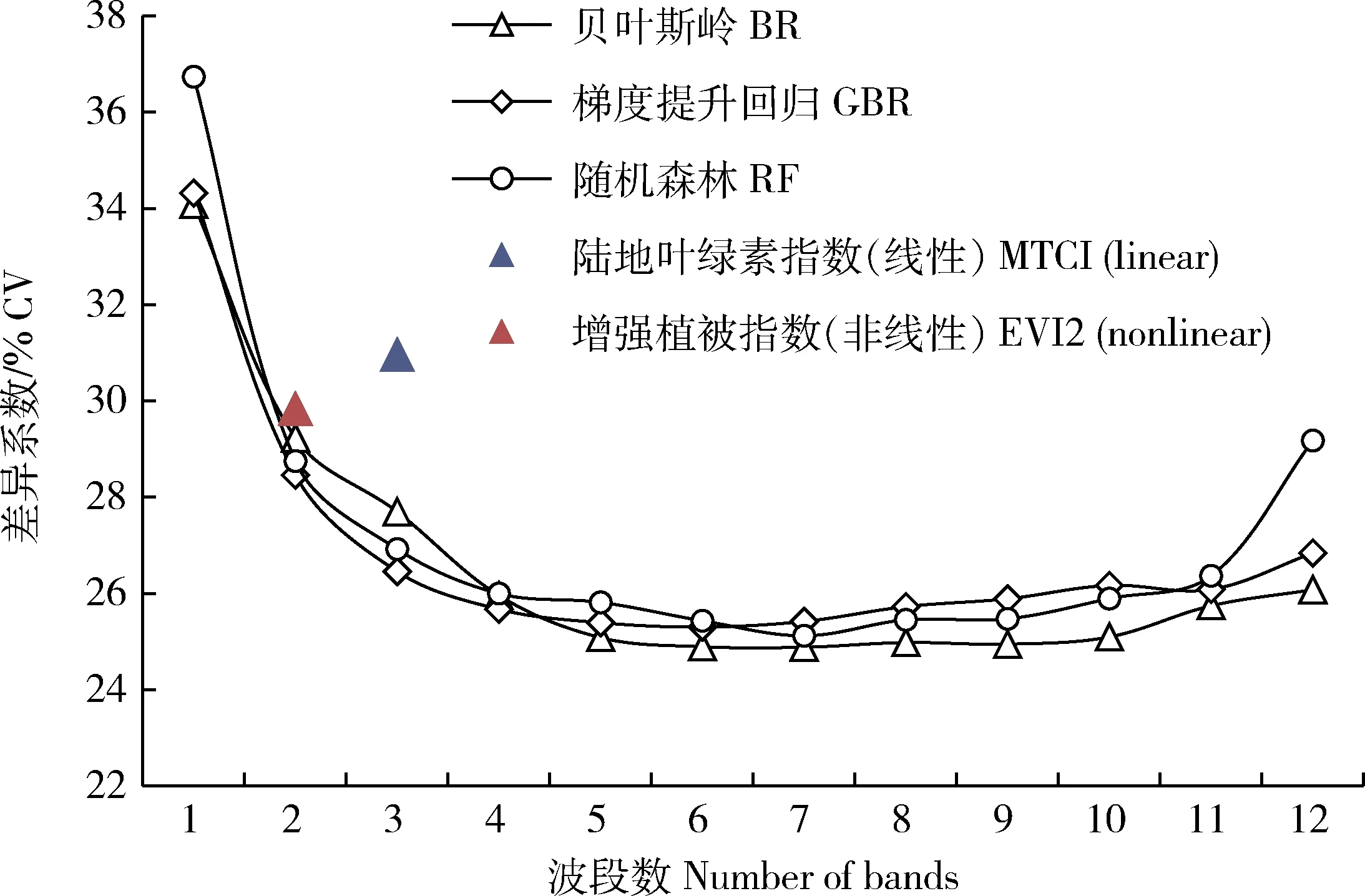
图4 不同模型随波段数变化的CVFig.4 Coefficient of variations (CV) of different models under different number of bands
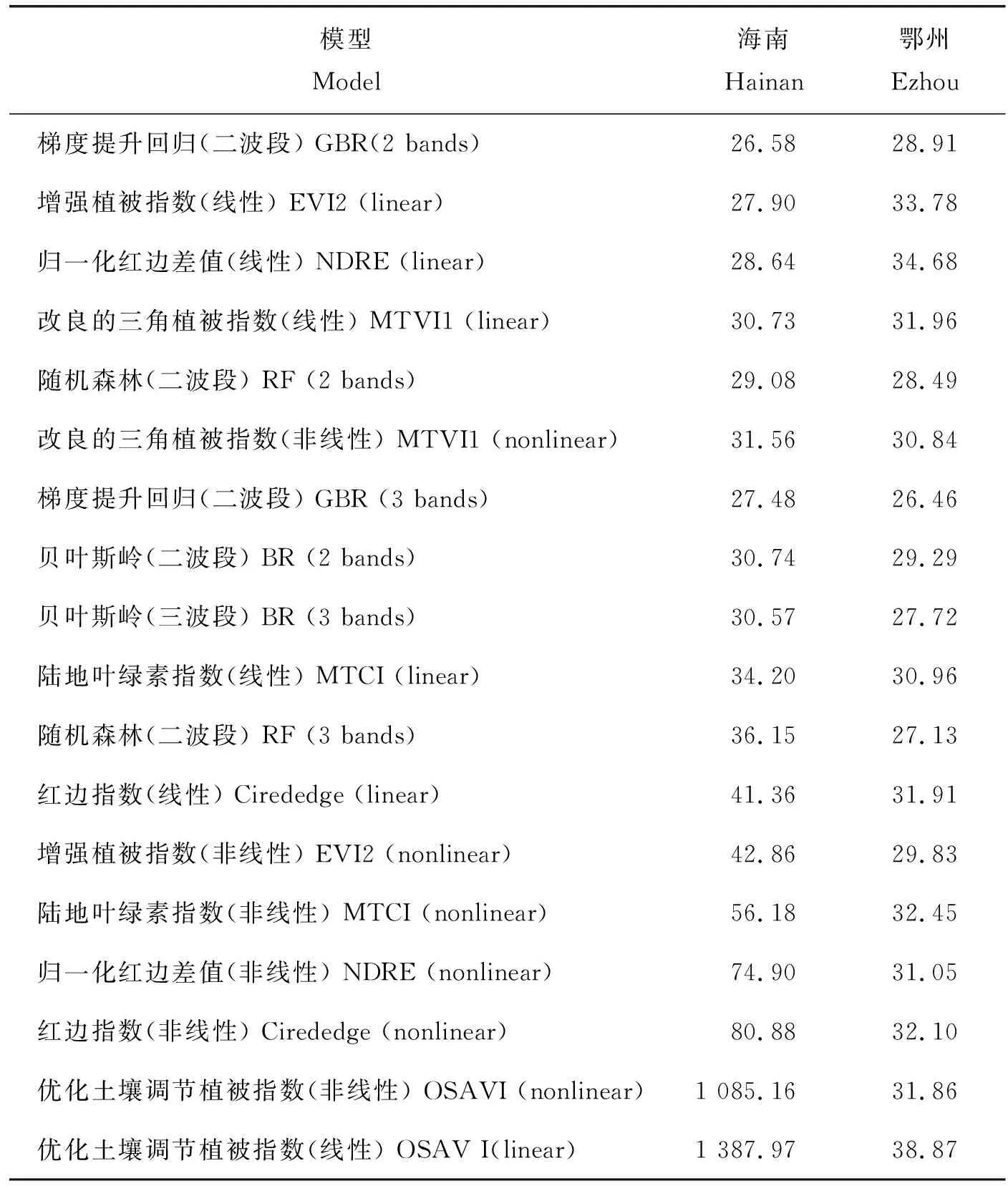
表3 不同模型鄂州建模集精确度与海南验证集精确度的比较Table 3 Comparison of the accuracy of different models Ezhou modeling set and Hainan verification set %
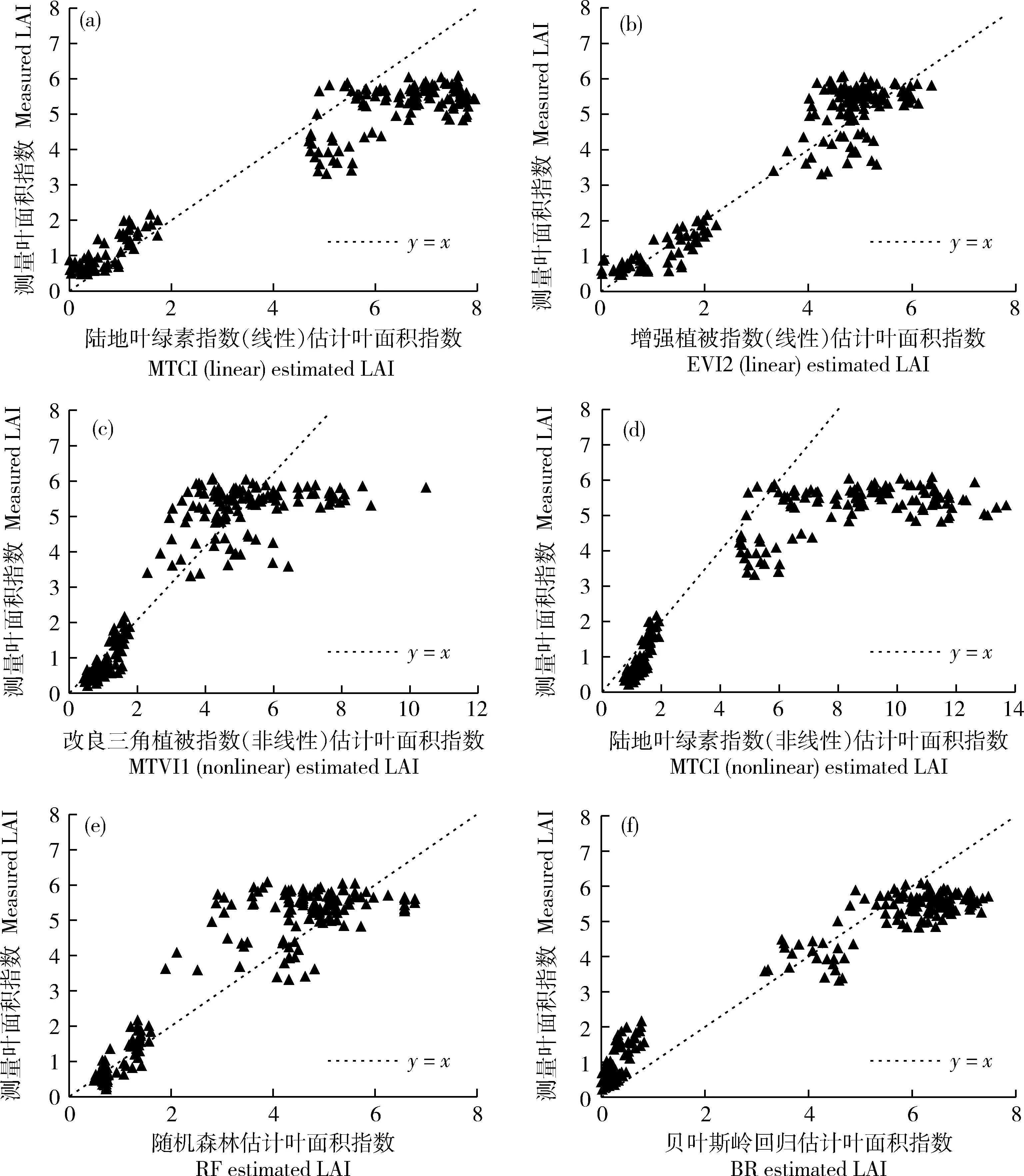
图5 不同模型估计值与真实值得比较Fig.5 Comparison of the estimated values and mesured values of different models
综上可知:各模型推广至海南试验区后精确度最高的是GBR二波段模型,海南试验区的CV为26.58%(鄂州试验区CV为28.91%);植被指数EVI2的线性模型次之,海南试验区的CV为27.90%(鄂州试验区CV为33.78%)。
3.3 模型应用及评估
在区分4种施氮差异的基础上,分别对2个品种验证模型精确度,然后不区分品种综合验证模型精确度,显示了EVI2线性经验模型和GBR二波段模型在2种水稻品种间的精确度差异,得到表4。由表4中可知:对于同一氮水平,使用EVI2线性模型在2个不同品种间的差异最大为5.95%(N16水平下);在品种间差异较小,而GBR模型在N16水平下,不同品种间的差异达到12.69%(N16水平下),品种间差异较大。因此,尽管GBR模型的整体精确度(CV=26.58%)比EVI2经验模型(CV=27.90%)高,但EVI2在品种间的差异更小,且单独验证不同品种的精确度与统一验证所有品种间的差异不大,因此可以使用EVI2经验模型推广至海南地区的水稻LAI反演。

表4 EVI2经验模型与GBR二波段模型在海南试验区品种差异系数Table 4 Coefficient of variation between EVI2 empirical model and GBR two band model in Hainan experimental area %
EVI2线性模型推广至海南试验区后各田块叶面积指数的分布情况见图8。随着水稻的生长,各田块LAI逐渐增大,2018-02-12—2018-02-20直观胀现水稻从分蘖期到拔节期呈现迅猛生长的态势。

图6 2种水稻在4种氮水平下不同日期的LAI估计值比较Fig.6 Comparison of LAI estimates of two rice varieties at different dates under four nitrogen levels
图6是9个不同时期、2个水稻品种(珞优9348和丰两优4号)、4种施氮条件下LAI的均值比较。海南土壤肥沃,土质本身含有丰富的氮元素,十分适宜水稻种植,在水稻分蘖期(2018-01-29—2018-02-12),随着氮肥量的增加,水稻叶面积指数反而出现下降的状况;在水稻拔节期(2018-02-20—2018-03-25),水稻叶片迅速生长,LAI迅速达到一个较高水平(LAI>8);当水稻进入孕穗期(2018-03-25—2018-04-01),叶鞘吸氮量降低,穗吸氮量将显著提高,累积干物质,此时LAI将会降低。另外,在同氮水平下,珞优8348的LAI性状预测表现明显高于丰两优4号。该差异在水稻分蘖期十分明显(2018-01-29—2018-02-12),但随着水稻生长,差异减小,在拔节期(2018-02-20—2018-03-25)两者差异较小,而随着进入孕穗期(2018-04-01),差异又迅速增大。N00、N08、N12和N16水平下,珞优9348的LAI值分别比丰两优4号超出1.03、0.85、0.56和0.43。

图7 EVI2线性模型反演海南试验区水稻LAIFig.7 EVI2 linear model inversion of rice LAI in Hainan experimental area
4 讨论与结论
4.1 讨论
本研究使用无人机获取的多光谱影像数据,通过植被指数的线性、非线性模型以及机器学习模型对水稻建立LAI反演模型,使用鄂州试验区的数据建模后推广至海南试验区。
利用植被指数经验模型反演LAI时,非线性模型优于线性模型,这是由于在水稻分蘖中后期,叶片覆盖度增加越来越慢,导致冠层光谱在红外波段的反射率增长愈加缓慢,因此LAI与植被指数之间呈现出非线性关系[21]。此外,NDVI与CIgreen的经验模型精确度较低,是由于水稻分蘖后期叶片迅速遮盖田地,红波段反射率迅速下降,而近红外波段反射率远高于红波段,造成NDVI迅速饱和;而在水稻拔节期,绿波段变化微小以及比值的构造使得CIgreen的样本点非常的分散。使用机器学习模型反演LAI,由于过多的波段数存在冗余信息,不仅会增加算法复杂度,且对提升模型精确度没有帮助。
在水稻叶片迅速生长阶段,叶鞘吸氮量占水稻各器官比例最高。不同品种水稻的叶鞘的吸氮能力不同,基本水平保持在80%以上[26]。当LAI迅速达到一个较高水平(LAI>8)时,需要适量追加氮肥。本研究发现:以海南陵水试验区的土质为基础,珞优9348适宜添加的氮水平是N08,过量增加氮肥对水稻生长无明显促进;丰两优4号适宜添加的氮水平是N12,N16水平的过量氮肥则会使得水稻LAI下降。
珞优9348属于氮高效品种,对于氮素的吸收利用效率高,抽穗期积累了大量的氮素为灌浆期提供良好基础,因此是高产品种。从珞优9348的叶面积指数来看,全生育期的高LAI水平有助于水稻的光合作用,干物质总量增加。但珞优9348氮高效机理尚不清楚。
4.2 结论
GBR二波段模型(鄂州建模集CV=28.91%,海南验证集CV=26.58%)与EVI的线性模型(鄂州建模集CV=33.78%,海南验证集CV=27.90%)具有较好的推广性;水稻种植施氮需要根据生长时期进行调整,以海南为例,分蘖期、拔节期水稻生长可以依赖土壤中的氮元素,分蘖期、孕穗期则需要追加氮肥;同等氮水平下,珞优9348是氮元素吸收利用更高效的品种。此外,水稻的叶面积指数虽然可以一定程度上反映出水稻的生长状况,但并不能完全指示水稻产量状况,例如有的水稻会出现徒长的情况,LAI很高但产量很低。因此,有必要进一步探究无人机多光谱数据与产量的关系,从无人机原始数据到水稻的抽穗期、LAI预测、产量预测等形成一条完整便捷的产品链,更好地助益农业生产。
