一种结合自注意和多尺度生成对抗网络的图像去雨方法*
2021-12-23周子淏张月芳罗东升邓红霞
李 然,周子淏,张月芳,罗东升,邓红霞
(太原理工大学信息与计算机学院,山西 晋中 030600)
1 引言
近年来许多技术需要对不同时期所拍摄的照片进行分割、识别和分析等处理,像苹果物候期自动检测技术等,而受不同天气所影响,雨天拍摄的照片清晰度下降,严重影响图像的分析结果。图像质量降低的主要原因是被雨滴遮挡区域与清晰区域相比,包含不同的映象,与不被雨滴覆盖的区域不同,雨滴覆盖区域是由来自更广泛环境的反射光形成的。此外,在大多数情况下,相机的焦点都在背景场景上,使得雨滴的外观变得模糊。图像去雨的难点在于被雨滴覆盖区域未知,封闭未知区域的信息丢失的问题,因此本文提出自注意多尺度生成对抗网络。
为了检测和去除雨滴,许多人提出了相应的解决方案,包括传统方法[1 -4]、基于非生成对抗网络的图像去雨技术[5 -8]和基于生成对抗网络[9]的图像去雨技术。其中,传统方法包括Huang等[2]提出的一种通过对输入图像进行上下文约束、构造学习字典用于重建以及使用稀疏编码原理,实现自动识别常见雨模式的方法;Tanaka等[3]提出的一种从立体图像中检测干扰噪声的方法,通过对立体图像测量的视差和立体相机系统与玻璃表面之间的距离进行比较,检测图像中雨滴的位置。这些方法可用于检测雨滴但不能去除雨滴。
基于非生成对抗网络的图像去雨技术研究有:Tan等[10]提出了一种仅使用马尔可夫随机场框架中的单幅图像输入进行功能开发的自动化方法,基于清晰图像和有雨图像对比度不同,在马尔可夫随机场的框架下设计算法实现雨线去除。Li等[11]使用简单的基于补丁的先验来处理背景和雨层,这些先验基于高斯混合模型,能够适应雨条纹的多个方向和尺度,解决了单幅图像中雨条纹的去除问题。Yang等[12]提出了一种方法,该方法通过层层迭代、循环和优化3个卷积通道,并引入3个损失来实现图像去雨。Li等[13]提出了基于编解码器结构的模型,通过引入的生成损失和特征融合实现图像中雨条纹的去除。非生成对抗网络方法更适合于雨线的去除,对大雨滴或浓密雨滴的去除效果欠佳。
基于生成对抗网络实现图像去雨的技术有:Zhang等[14]提出了一种基于条件生成对抗网络的框架,用于改善生成网络,生成网络的结构为自编码器,定义了一种新的感知损失函数,在公共和综合数据集上进行了广泛的实验,并与现有的先进方法进行了定性和定量比较,结果表明该框架提升了去雨效果。Xiang等[15]提出了用于单幅图像去除雨水的F-SGAN(Feature-Supervised Generative Adversarial Network),生成网络进行特征监督,在去雨过程中,同时提取清晰图像的特征,通过该特征引导生成网络更有效地学习雨滴区域的特征,逐步优化该特征监督生成对抗网络,以实现图像去雨。这些方法重点关注局部区域(雨滴区域),而对图像的整体依赖性关注不足。与传统方法和非生成对抗网络相比,生成对抗网络生成的图像清晰度更高、更真实。因此,本文在自动编码器结构中的卷积层之后添加自注意层,以提升图像的全局依赖性,引入多尺度判别器,以提升图像的清晰度,实现图像中雨滴的去除。
2 自注意多尺度生成对抗网络
2.1 网络框架
生成对抗网络有2个主要的部分:生成网络和判别网络。输入图像为附着雨滴的图像,本文的生成网络可生成没有雨滴接近清晰的图像。判别网络评估生成网络的结果与清晰图像之间的差异,以验证去雨图像是否足够清晰。经过不断迭代,直到判别网络无法判别去雨图像是否真实即可停止。
Qian等[16]提出了注意力生成对抗网络来实现图像去雨,在生成网络中增加了注意-循环网络,以生成注意力分布图来引导网络检测和去除雨滴区域。如图1所示,本文方法在已有的网络基础上针对网络结构进行了2点(椭圆所圈)改进:
(1)在自动编码器结构中的卷积层之后添加自注意层[17],以提升图像的全局依赖性,所添加的自注意层如图1右上角深色部分中黑色所代表的层。
(2)引入多尺度判别器[18],图1中右下角浅灰色部分为判别网络部分。
网络中生成网络右侧自编码器[19]包含16个conv-ReLu块和跳跃连接,以及2个自注意层,判别网络所用判别器个数为2个。
2.2 自注意生成网络
为解决被雨滴遮挡区域未知,且背景信息丢失和注意力生成对抗网络重点关注局部区域(雨滴区域),而对图像的整体依赖性关注不足的问题,本文在生成网络中添加自注意层,并在原自注意层基础上增加特征叠加细节。如图2所示为添加自注意层的整体结构图,其中黑色虚线部分是所添加的特征叠加细节。自注意层的输出结果为上一卷积层与原自注意层输出特征图相加(黑色虚线部分)的结果。
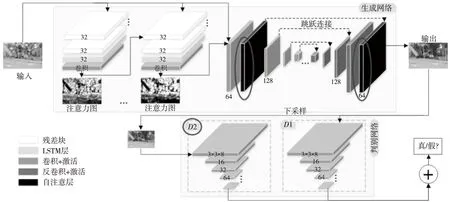
Figure 1 Structure of self-attention multi-scale GAN proposed in this paper图1 自注意多尺度生成对抗网络结构图
该层首先将上一个卷积层输出的特征x∈RC×N转换为3个特征空间f,g和h,以获取注意力信息。
(1)
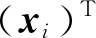
(2)
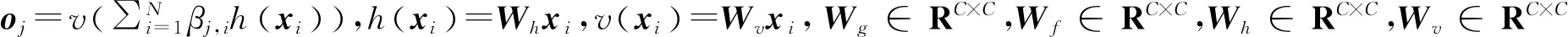
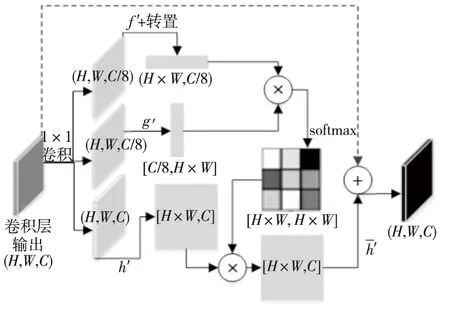
Figure 2 Structure of self-attention layer 图2 自注意层结构
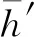
2.3 多尺度判别网络
为了进一步提升图像的清晰度,本文引入多尺度判别器[18],以区分所生成去雨图像和清晰图像之间的差异。多尺度判别器的原理:可以有个数不同的并行的判别器,这些判别器的构成完全一致,区别在于输入图像的大小不同,即对生成网络生成的图像进行不同比例的下采样,并将获得的不同分辨率的结果图像分别作为各个判别器的输入,整个判别网络的判别结果为各个判别器结果的加权和,将该结果传回生成网络以引导优化生成网络。
如图3所示,本文使用的多尺度判别网络[20]为2个并行的判别器。判别器D1包含7个卷积层,内核大小为(3,3),全连接层大小为1 024,最后使用Sigmoid激活函数。图3中2个判别器的结构完全一致,生成网络生成的去雨图像直接输入D1,对生成网络的输出结果进行2倍下采样,所得结果输入D2,将D1和D2的判别结果分别加权,判别网络的最终结果为加权后的总和,以该最终 结果引导优化生成网络。因此,多尺度判别器可从不同分辨率的输入图像角度由粗到细逐渐优化网络,以生成更清晰的图像。
《诗·小雅·正月》:“载输尔载,将伯助予! ”《传》:“将,请;伯,长也。”意谓车欲堕而请长者帮助。后用作求助或受助的意思。《聊斋志异·连琐》:“将伯之助,义不敢忘。 ”〔2〕132
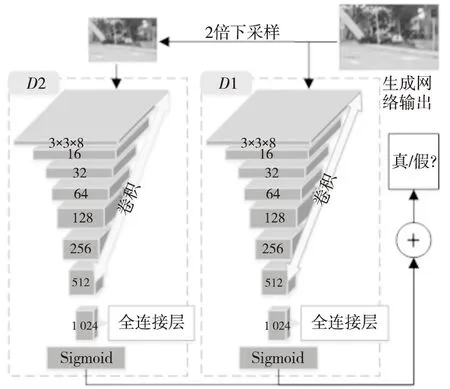
Figure 3 Structure of multi-scale discriminator 图3 多尺度判别器结构图
2.4 损失
本文方法中包含多尺度损失和感知损失[21]。多尺度损失通过比较不同解码器层提取的特征以及真实图像对应特征之间的差异,获取广泛的上下文信息,如式(3)所示:
(3)
其中,LM(,)表示多尺度损失,M是所选取解码器层的个数;LMSE(,)表示均方误差;Si表示从解码器层中提取的第i个输出特征;{S}表示从选取的不同解码器层中提取的特征集合;{Ti}表示与{Si}具有相同尺度的真实特征;{T}表示对应各解码器层相同尺度的真实特征集合;λi是不同尺度的权重。感知损失可测量自动编码器输出的特征与相应的清晰图像之间的总体差异。这些功能可从受过训练的CNN中提取。VGG是预训练的CNN模型,可生成给定输入图像的特征,如式(4)所示:
LP(O,T)=LMSE(VGG(O),VGG(T))
(4)
本文生成网络的损失如式(5)所示:
LG=10-2LGAN(O)+LATT({A},M)+
LM({S},{T})+LP(O,T)
(5)
其中,A是注意-循环网络生成的注意力图,{A}是注意力图的集合。LATT表示注意力损失。M表示二值掩码。LGAN(O)=log(1-D(O)),O=g(I)。D(O)是判别网络生成的判别概率,I是生成对抗网络的输入噪声。O是自动编码器的输出图像或者整个生成网络的输出图像。
3 实验和结果分析
3.1 数据
去雨实验过程中,所拍摄的有雨图像和清晰图像必须为同一个背景,雨滴区域所对应的背景需完全一致。为了使实验结果更加有效,数据集中有一个训练集和一个测试集,其中,训练集包含3 600幅有雨图像和3 600幅清晰图像,测试集包含清晰图像和附有雨滴图像各425幅。各参数分别设置如下:学习率为0.000 2,批量大小为1。
3.2 评价指标
本文采用PSNR和SSIM评价指标。PSRN的计算公式如式(6)所示:
(6)
(7)
其中,MSE是当前图像X和参考图像Y的均方误差;H和W分别是图像的高和宽;n是每个像素的比特数,通常取8,即像素的灰度为256。PSNR是基于误差敏感性的图像质量评估指标,值越大效果越好。
SSIM分别比较了图像之间的亮度、对比度和结构,其计算公式如式(8)所示:
综上所述,医护人员需要密切关注气管插管患者的病情,给与科学合理精心的护理,注意基础护理、气管插管之后的湿化,感染的预防,以及各种并发症的护理等等。同时需要关注患者的饮食,根据患者情况给与鼻饲、喂养和自理等,一切依照不同患者的情况选择不同的方案。应该遵循从流食到普食的原则。患者的心理状态作为新时代的医护人员液应关注,加强同患者的沟通,对于患者和亲属可给与一定适度的相关知识教育,对于其疑问应耐心科学的解答以及建立随访制度。如此多方面综合的给与患者关怀,减轻患者痛苦,减轻家庭社会负担,提高其生存率以及生存质量。
SSIM(X,Y)=l(X,Y)·c(X,Y)·s(X,Y)
(8)
(9)

SSIM是完全参考的图像质量评估指标,取值为[0,1],该值越大表示失真越小。
3.3 实验结果
(1)定量评估。将本文方法与其他现有方法(Eigen[22]、F-SGAN[15]、IPM CA(Integrating Physics Model and Conditional Adversarial)[23]、Att GAN(Attentive Generative Adversarial Network)[16]、Pix2Pix[24])在不同数据集上进行了比较。表1给出了定量结果。表1中的值有效,可看出本文所提方法在雨滴、雨线(稀疏)和雨线(稠密)3个数据集上的评价指标值均表现出优势。其中针对雨滴数据集,网络结构中单独加入自注意层时,PSNR值为30.84 dB;单独加入多尺度判别器时,PSNR值为31.02 dB。而原网络测试结果的PSNR值为31.57 dB,即网络中单独加入自注意层Att+SA或多尺度判别器Att+MS时,PSNR值没有提升。这表明本文的方法可以产生更清晰的图像结果,在图像的像素点、亮度、对比度和结构方面都有优势。
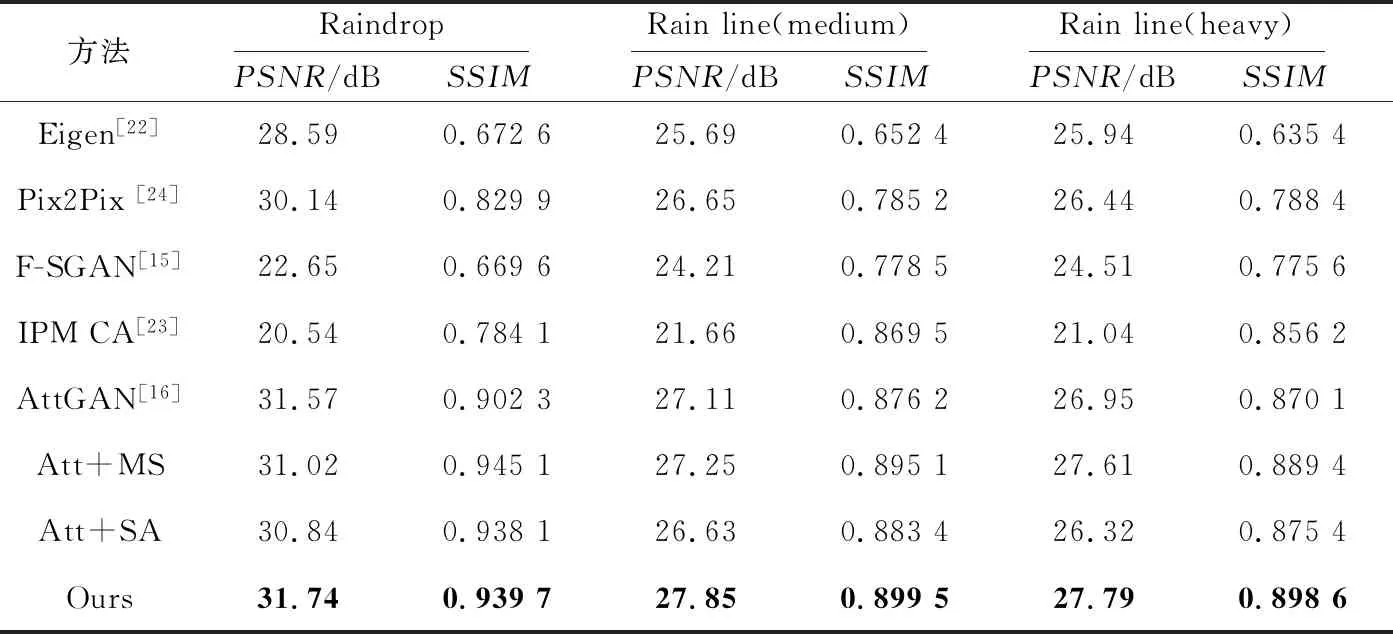
Table 1 Quantitative results of different methods表1 定量评估结果

Figure 4 Rain removal results of different methods图4 不同方法的去雨结果

Figure 5 Rain removal results of the method proposed in this paper图5 本文方法的去雨结果
(2)定性评估。如图4所示,在雨滴、雨线(稀疏)和雨线(稠密)3个数据集上,与Att GAN[16]、F-SGAN[15]、IPM CA[23]和Pix2Pix[24]相比,自注意多尺度生成对抗网络去除雨滴获得的图像分辨率更高、更有效。如图5所示为自对比实验结果,包含只引入多尺度判别器(Att+MS)、只添加自注意层(Att+SA)和本文方法。结果表明,本文方法所生成的去雨图像的颜色和对比度等方面更接近真实的图像,图像更清晰。
如图6所示为损失值结果的自对比图,可以看出,最下方黑色折线(本文方法)的损失值收敛效果更好,损失值更低,更趋近于0。
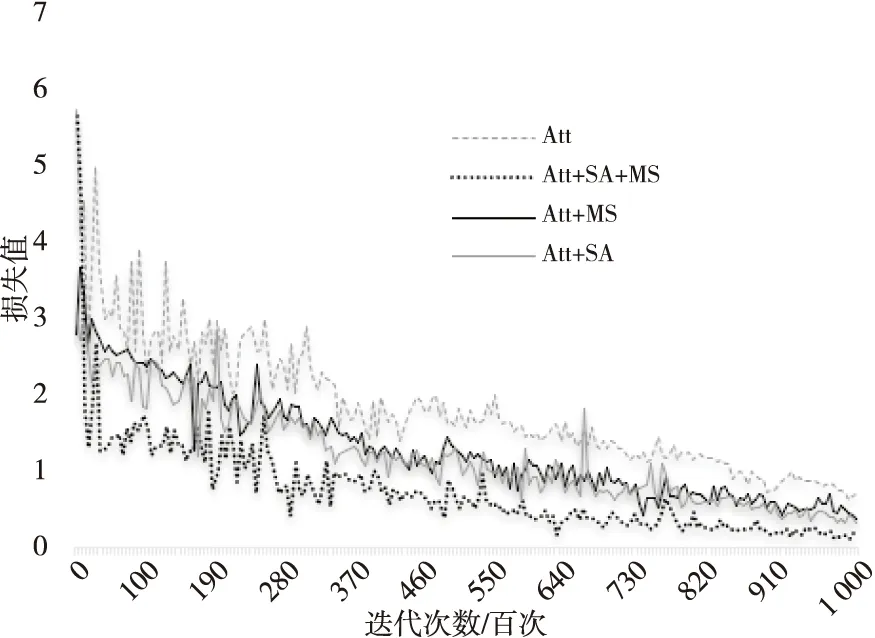
Figure 6 Self-contrast chart of loss value图6 损失值自对比图
4 结束语
本文提出了一种基于自注意多尺度生成对抗网络的图像去雨方法。该方法基础框架为注意力生成对抗网络,其中生成网络由注意-循环网络和自动编码器组成。本文在自编码器的卷积层后添加了自注意层,以弥补注意-循环网络对图像全局信息的关注不足。判别网络引入多尺度判别器,即2个并行判别器,使用生成网络的2倍下采样结果和原始输出结果作为2个判别器的输入,从而产生更清晰的图像。相比之下,本文方法效果更好。
