基于Transformer神经网络模型的网络入侵检测方法
2021-12-21郭志民周劼英
郭志民, 周劼英,王 丹,吕 卓,杨 文
(1.国网河南省电力公司电力科学研究院,郑州 450000;2.国家电网有限公司,北京 100031; 3.国网河南省电力公司,郑州 450000)
当今网络安全形势日益严峻,网络攻击者利用巧妙的攻击手法避开防火墙,入侵网络系统获取隐私信息、破坏网络系统或导致服务器瘫痪,关于网络入侵检测研究已成为当今网络安全最重要的研究方向之一。网络入侵检测通过对计算机系统和网络事件分析,检测入侵和攻击行为。在一个网络系统中,任何未经授权的活动,以及企图绕过网络安全机制的行为,都可视为网络入侵行为[1]。网络入侵检测可被分为基于异常的检测和基于误用的检测2种[2-3]。基于异常的检测系统通过观察网络、系统或用户的异常行为来检测攻击行为,基于误用的检测系统则使用先验的攻击模式和签名来检测攻击行为。
随着人工智能和机器学习的发展,越来越多研究开始尝试使用机器学习的方法解决网络入侵检测的难题。Chowdhur等人[4]以互联网上的流量数据为训练集,一次性选取任意3组特征作为SVM的输入进行训练,给予了SVM一定检测任意网络异常行为的能力。Mohsen等人提出了用于入侵检测的最小-最大K均值聚类方法[5]。该算法试图最小化簇的最大内部方差,而不是像K均值算法那样最小化内部方差的和。每个集群都有一定的权重,并将较高的权重分配给内部方差较大的集群,该算法获得了81%的检测率。Li等人[6]提出了2阶段的“智能入侵检测方法”。第一阶段包括使用随机森林算法,通过权衡特征的重要性来获得特征的子集。第二个阶段是一种基于特征子集作为输入的分类器“基于混合聚类的Adaboost算法”。Jaiganesh等人[7]提出一种基于神经网络的入侵检测算法,通过专门选取入侵数据,使用反向传播算法训练神经网络权重,使算法具有检测入侵行为的能力。Sinapiromsaran等人提出了多属性框架决策树[8],将数据分为左、中、右3个区域,从最远的一对中选择一个核心向量来对入侵行为进行分类。李俊等人[9]考虑了网络入侵数据的时序特点,使用GRU_RNN网络结构在KDD数据集上进行训练,获得比其他非时序网络更好的识别率与收敛性。
尽管许多现有研究探索了机器学习在网络入侵检测中的应用,这些研究对正常行为和攻击行为进行分类,基于机器学习方法构建入侵检测模型,具有一定检测效果,但仍存在一些问题。主要体现在:1) 训练样本中标签为正常行为的数据量远大于非法行为,数据特征分布严重不均,导致模型难以训练且泛化能力不足。2) 网络入侵通常是时间上的一段连续行为,大多数模型不具备时序学习能力而丢失了时序特征,部分基于循环神经网络的方法虽能够学习时序特征,但其基于序列的串行训练方式存在训练耗时长且收敛效率较低等问题。
Transformer[10]最初应用于自然语言处理(NLP)任务中,其结构完全抛弃了RNN和CNN等网络结构,而仅采用Attention机制来进行机器翻译任务,且取得了很好效果,其网络结构如图1所示。Devlin等人提出的BERT[11],Brown等人提出的GPT-3[12],这些基于Transformer的模型都在NLP领域取得了重大突破。Transformer与基于RNN的时序神经网络有明显不同,RNN的训练是迭代的、串行的,而 Transformer 的训练是并行的,即所有特征是同时训练的,大幅增加计算效率。

图1 Transformer网络结构Fig. 1 Transformer network structure
通过分析网络入侵行为的数据特征,提出基于Transformer神经网络模型的入侵检测方法。通过在多个数据集上进行实验,选取最优的损失函数和网络结构,最后在测试数据集上,相较于对比机器学习方法,提升训练效率和识别率。主要贡献包括:
1) 针对网络入侵行为数据的时间相关性,提出了一种基于Transformer的网络入侵检测方法,进一步提升网络入侵检测的准确性。
2) 设计一种基于降维特征的多头自注意力机制Transformer网络模型,以解决传统串行化时序神经网络模型不易收敛且时间开销较大问题,通过选取最优损失函数和训练参数进行并行化训练,从而实现网络入侵行为检测。
3) 在多个数据集上进行对比实验,结果表明,提出的基于Transformer网络模型的网络入侵检测方法在多个数据集上均获得了99%以上的精度和检出率。
1 数据分析及预处理
1.1 数据分析
实验采用的数据集为KDD-Cup-99和NSL-KDD网络入侵数据集。KDD-Cup-99数据集[13]是第三届国际知识发现和数据挖掘工具竞赛所使用的数据集,共计23种标签、4898431条数据,包含正常和22种攻击类型标签。NSL-KDD 数据集[14]是KDD-Cup-99数据集的改进版本,包含125973条网络连接记录。数据集如表1所示。

表1 网络入侵数据集
分析了KDD-Cup-99及NSL-KDD数据集的数据分布,分析结果如图2所示。

图2 KDD-Cup-99及NSL-KDD数据分布Fig. 2 Data distribution of KDD-Cup-99 and NSL-KDD
分析结果表明,KDD-Cup-99数据集分布不平衡,这种不平衡数据分布会导致模型性能欠佳,导致漏检率升高,而NSL-KDD数据存在信息冗余的问题[15]。为解决这一问题,引入特征提取模型,通过数据表征和降维,避免因数据冗余造成收敛性能降低。
1.2 数据特征提取
1.2.1 字符数据编码
由于原始数据集包含了字符串特征,不利于直接向量化,为了方便计算,将数据标签进行One-hot编码。One-hot编码是机器学习分类任务中常用的数据编码方式,它可以将原数据中离散的值转化为欧式空间的点,使各标签之间保持合理的特征距离。数据集中的每条数据被分为正常或异常2种类别,正常编码为01,异常编码为10,具体编码方式见表2所示。

表2 数据标签编码
1.2.2 归一化
由于原始数据中数据范围相差较大,不利于网络训练。所以需要对原始数据的每一列进行归一化处理。将同一列数据归一化到(0,1)之间。其归一化公式为
(1)
其中:x为原始数据集的任意一列数据值;xmin为统计整列获得的最小值;xmax为最大值;x*为归一化后的数据值。
1.2.3 特征降维
为了去除数据集中冗余信息对检测准确性的影响,引入一个特征提取网络F作为入侵检测模型的前置网络,该网络由2层全连接层构成,其目的是将冗余的低级特征映射为高级特征。特征提取网络F的计算过程如公式2所示。
y=σ(x′)=σ(F(x*)),
(2)

2 基于Transformer网络模型的网络入侵检测
2.1 时序编码
首先对网络入侵数据进行时序编码,对于特征数据集D,需要将时序信息嵌入到输入特征中,通过一层全连接层,对不同时间的特征进行相应的时序编码。时序编码计算公式如下
PE(pos,2i)=sin(pos/10 0002i/dx),
(3)
PE(pos,2i+1)=cos(pos/10 0002i/dx),
(4)
其中:pos指的是一段序列中某个时刻特征的位置,取值范围为[0, 最大序列长度];dx是特征维度;i表示在时序编码向量中的索引,取值范围为[0,...,dx]。位置嵌入函数的周期从2π到10 000×2π变化,而每一个位置在编码维度上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,最终使得模型学到位置之间的依赖关系和自然语言的时序特性[4]。
2.2 编解码模块
从时序编码后的特征序列中取一个长度为t的连续序列Xt=x1,....,xt|xi∈Rdx,其中xt是在t时刻维度为dx的网络信息特征向量。输出为一个长度为t的Yt=y1,....,yt|yi∈(0,1)状态集,其中yt是在t时刻的状态。输入数据经过时序编码后进入编码模块,编码模块将特征映射到更高维的特征图(如图3所示),并将其输入到解码模块中,解码模块输出最终的状态集。

图3 编码模块及解码模块结构图Fig. 3 Structure of encoding module and decoding moudle
编码模块与解码模块具有相同的结构,主要由多头自注意力层和前馈网络组成。为了让模型去关注不同方面的信息,采用了多头自注意力层将注意力模块分为多个头,从而产生多个子空间,增强模型性能。
2.3 网络结构设计
网络由编码器和解码器组成(如图4所示),其中编码器主要由输入层,时序编码层和编码模块组成,输入层通过全连接层将输入时间序列数据映射到高维的向量,然后将输入的向量与时序编码向量逐元素相加,对其特征进行时序编码。然后将结果输入到编码层,在经过编码器后生成的特征向量,将其送入解码器中。
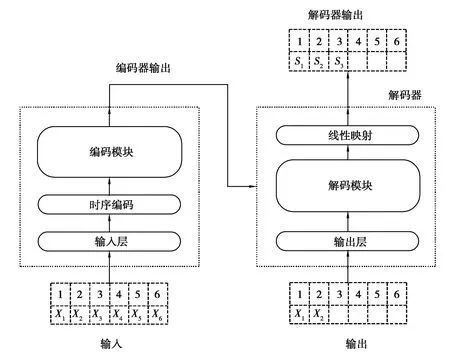
图4 基于Transformer网络入侵检测模型Fig. 4 Network intrusion detection model based on transformer
在推理的过程中采用动态解码的方式,在经过编码器之后获得高维特征图,将其输出到解码器中,同时根据前面时刻的预测结果依次进行。
2.4 损失函数
由于数据样本中存在正负样本不均衡的问题,采用Focal Loss[16]作为损失函数,如公式(5)所示,其广泛用于目标检测任务中的困难样本挖掘,通过调整正负样本的权重,使得模型在训练中更关注难分类的样本,有效缓解数据分布不均问题。
(5)
其中:y为分类层激活函数的输出;y′为真实值,即编码后的标签;α和γ为调节因子,α取值为0.25,γ取值为2。
3 实验分析
3.1 实验环境
本次实验中采用的硬件环境配置为Intel(R) Core(TM) i7-9700 CPU 64位处理器、32 GB内存,并采用GTX 3080运算加速,操作系统为Ubuntu 16.04。按比例4 ∶1随机拆分训练集和测试集,优化器采用Adam,设置初始学习率为0.001,epoch数为100。
3.2 验证方法
为了对实验结果进行有效性能评估,采用二分类任务评价的标准混淆矩阵,混淆矩阵如表3所示。

表3 混淆矩阵
根据混淆矩阵,可以得到以下3个评价指标包括精度(PRE)、检出率(TPR)、 F1分数,如公式(6)、(7)和(8)所示。
精度(PRE)
(6)
检出率(TPR)
(7)
F1分数
(8)
3.3 性能评估
与传统方法机器学习方法、基于深度学习的机器学习方法进行对比分析实验[17-21]。传统方法,与基于特征提取的支持向量机(SVM)算法及基于聚类的最邻近结点算法(KNN)算法进行对比。深度学习方法,与深度神经网络(DNN)和基于递归神经网络的长短时记忆神经网络(LSTM)进行对比。在不同数据集上,采用精度、检出率和F1分数3个准确性指标进行对比实验,验证相对于其他模型,基于Transformer网络模型的检测方法在检测效果上的优势。图5、图6分别展示了与传统方法和与深度学习方法的对比实验结果。
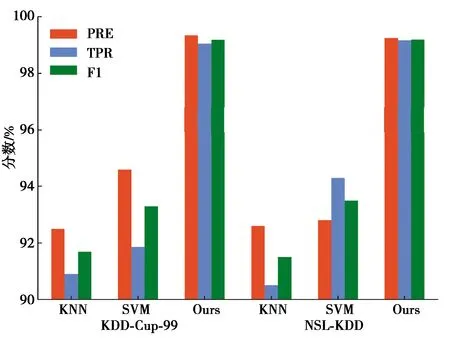
图5 传统方法对比实验结果Fig. 5 Comparison experimental results of traditional methods

图6 深度学习方法对比实验结果Fig. 6 Comparison experimental results of deep learning methods
1)与传统方法相比,提出的检测方法在精度和检出率方面都有明显优势,SVM相较KNN提升一定检测效果,但仍不佳。在不同数据集上,传统方法检测效果受影响较大,而研究方法无论是在数据分布不均的KDD-Cup-99数据集上,还是在数据相对分布均匀的NSL-KDD数据集上,都能取得好的检测效果。
2)与深度学习方法进行对比实验,采用相同的模型,使用不同的数据集训练,DNN与LSTM的检测效果也会受到影响,各指标波动明显大于检测模型,这表明方法在模型泛化性能上更具优势。采用相同的训练集训练,使用不同的模型进行对比,深度学习模型均能取得95%以上的精度和检出率,且具有时序学习能力的LSTM比DNN有更好的准确性,说明网络入侵行为存在可用的时序信息,提出检测方法在各指标上取得了99%以上分数,优于其他深度学习模型。实验结果表明,针对数据分布、时序信息学习及网络结构改进都有效提升网络入侵检测效果。
4 结 语
提出一种基于Transformer网络模型的网络入侵检测方法。所提出的Transformer网络模型基于降维特征,利用多头自注意力机制学习到网络入侵数据时序特征,通过选取最优的损失函数和训练参数进行并行化训练,结合特征提取的数据预处理方式,缓解数据分布不均衡问题,有效提高检测效果。实验结果表明,在不同数据集上,相比传统方法以及深度学习方法,采用精度、检出率和F1分数作为指标,都取得了最佳检测效果。
