一种基于区域共享的云存储系统的设计与实现
2021-12-18刘峰





摘要:利用闲置的计算机的设备及带宽构建成一个基于共享模式的存储系统,是一个有价值的研究方向,基于该模式构建的分布式云存储系统具有利用空闲资源,提高社会资源利用率的特点。在该方向上拥有较为成熟的体系和解决方案的是IPFS(InterPlanetary File System,星际文件系统)。IPFS是一个去中心化的分布式文件系统,其是一个针对于全球范围的结合区块链技术的共享模式的分布式存储系统。而其系统非常庞大和复杂。基于人类生活的习惯,往往主要在某一片区域内活动,多数情况仅需要特定一个区域内的服务。根据中国架设的互联网的结构,在同一片区域内的节点之间连通性相对较好,延迟相对较低,且容易达到较高的网速。因此本研究将会设计并实现一个基于区域共享的云存储系统,该系统相比IPFS,具备更好更高效的区域服务性能和更低的区域服务成本,以及更轻量级、对硬件的要求更低的系统。
关键词:云存储;区块链;共享模式;去中心化;IPFS
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)31-0020-06
Design and Implementation of a Cloud Storage System Based on Regional Sharing
LIU Feng
(System R&D Department,PPLabs Networking Technology (Shanghai) Ltd., Shanghai 200120, China)
Abstract: Using idle computer equipment and bandwidth to build a storage system based on a shared mode is a valuable research direction. A distributed cloud storage system based on this mode has the characteristics of using idle resources to improve the utilization of social resources. The IPFS (InterPlanetary File System, InterPlanetary File System) project has a more mature system and solution in this direction. IPFS is a decentralized distributed file system, and it is a distributed storage system for a global sharing model combined with blockchain technology. The system is very large and complex. Based on the habits of human life, activities tend to be mainly in a certain area, and most of the time, only services in a specific area are needed. According to the structure of the Internet set up in China, the connectivity between nodes in the same area is relatively good, the delay is relatively low, and it is easy to achieve higher network speeds. Therefore, this research will design and implement a cloud storage system based on regional sharing. Compared with IPFS, this system has better and more efficient regional service performance, lower regional service cost. And which lighter the system, lower the requirements.
Key words: cloud storage; blockchain; sharing mode; decentralization; IPFS
1 背景
早在1978年,美國的学者就提出了共享经济的理念,自2010年以来,共享的模式从原本的小规模或者是无偿模式逐渐演变出了一种新的模式,这种模式以获得一定收益为目的,通过大型的中介平台共享自己的闲置资源。例如 Uber、Airbnb 等平台的运作模式。而闲置的资源并不局限于车辆、房屋等。闲置的计算机设备,有剩余流量的宽带线路,闲置的存储设备等,均是共享模式的新的角度。IPFS (星际文件系统)是由 Juan Benet 设计的,并于2014年开始由Protocol Labs 在开源社区的帮助下发展的一个网络传输协议,其旨在创建持久且分布式存储和共享文件。因为该项目是一个P2P、去中心化,基于密码学技术的文件系统,所以其具备了安全性、隐私和可靠性方面的优点[1]。
而其为了满足全网的服务能力,其对于每一个文件,根据文件的 CID 进行检索,检索范围是整个系统,而其服务范围会跨越国家,当 Miner(拥有闲置存储和带宽资源希望获得收益的人,也称矿工)和 User (用户)不在相近的区域内,不仅两个节点直接通信的质量不好,且其他模块(verifer验证者,indexer检索者)也需要进行位于不同区域的通信[2-3]。从而不仅会对网络的服务质量有影响,且会对于提高其他模块的复杂程度,从而提高了对硬件的要求。由于所有的矿工和所有的用户均在同一个系统内,因此整个系统负载的每秒交易量较大。容易出现交易拥堵的情况,其存储市场的交易是区块链的链上交易,因此尽管IPFS已经采取了相应的手段减小了 gas 费用(交易被记账、打包成区块的费用),但该费用仍然较为高昂。因此基于上述原因,本研究考虑到,实际应用场景下,大多数需求均为同一地区的服务,因此设计并实现了一个按区域划分的系统,每个区域的存储系统独立运行。并且针对该场景,设计并实现了一个混合扩容区块链的方案。
2 区块链交易模块的设计
2.1 混合扩容而成的区块链交易模块的设计思路
该模块为本系统的交易模块,提供钱包、交易以及结算的功能。即为本系统存储部分提供交易的服务。由于存储部分的交易结算的流程并不是一次性支付全部的费用,而是每成功进行一次时空证明后进行一次支付(该部分在3.1节中会介绍),因此每一个文件的存储都会产生大量的交易,从而该系统最大能存储的文件的个数会被交易模块的 TPS (每秒交易次数)所限制。可知 TPS 的大小为该系统的可行性的重要指标。
如果使用传统的区块链公链条作为该系统的结算模块,将会出现最大TPS难以满足需求的情况,例如比特币的交易效率为每秒仅支持7笔交易,而目前的以太坊也仅支持每秒 15 笔左右的交易[4]。并且还存在高昂的gas费用的问题。业界很多技术人员尝试为区块链扩容。例如比特币中出现了依据信任程度打分的方式提高交易效率的方案[5]。而以太坊中目前扩容方案主要有两类:Layer 1 扩容方案,即直接增加链上的交易处理能力,这种方式也被称为链上扩容。常见的技术方案有: Sharding 和 DAG。Layer 2 扩容方案,即将链上的相当一部分工作量转移到链下来完成。常见则是通过侧链的方式进行。
由于本项目的交易的群体相对固定,用户均为该共享的云存储系统中的成员。因此可以通过Layer2的方案进行扩容,不必在公链(比特币、以太坊等)上进行交易,通过2.4节实现中所示的跨链协议,支持将公链上账户的钱转入侧链和将侧链上账户的钱转回公链。而矿工以及用户的存储的收益和费用的交易均在侧链中进行,从而TPS能力将不受制于公链的TPS,也不会因公链的拥堵造成该系统的阻塞。该侧链仅由该系统参与者形成,因此节点数目远小于公链。从而需要进行共识的节点数目也会较少,从而该链达成一致性的成本较低,从而gas费用较小。从而比直接使用以太坊作为提供合约的链拥有更好的效果,并且通过使用 POS 或者 POA 方式构建的侧链 TPS 可以达到1000以上。
而该系统的应用场景是针对每一个区域提供服务,因此可以利用该特性继续优化扩容该区块链交易模块,在原有的layer2的链的基础上,继续扩容,将每一个区域单独划分成一个交易子模块zkStore。而在某个特定的区域内,所有的用户和矿工均通过 zkStore 进行交易,而 zkStore 与真正的链不同,其并没有独立进行共识和交易的能力。其通过利用侧链提供的合约功能,由Operator(交易收集器)收集一定的交易之后,生成 proof 提交侧链的合约进行验证。从而将区域内用户和矿工之间的交易的 gas 费用降低。
基于上述,依据交易群体相对固定和交易发生在特定区域的性质进行的两次扩容后,假设每进行M次结算交易之后用户将会将余额进行存取,Operator 每收集N个交易进行一次验证,则平均一次交易的gas费用满足如下公式:
其中 Gasmainchain 为公链一次转账的花费, Gassidechain 为往侧链合约中转账的开销,Gasproof为侧链一次验证proof的花费,Gasoperator为Operator收集交易并打包的花费。而实际测试得N稳定在30,而M和用户习惯有关系,通常使用情况下M大于1000,因此造成Gasmainchain 和 Gassidechain 的开销可以忽略,且 Gasoperator 的花费为 Gasmainchain 的1/30,Gasproof约等于3~5倍的Gasoperator,因此基于該结构下,整体Gas约为以太坊的1/25。
测试zkStore模块的TPS,得到表2所示的zkStore的TPS测试数据。
系统可承载的最大zkStore的个数为:
其中Numzkstore为最大 zkStore 的个数,C为每秒一个 zkStore 造成侧链的交易数量,TPSsidechain为侧链的TPS,侧链的 TPS 由侧链的实现方式决定,使用 POS 或者 POA 的情况下侧链的TPS通常可以达到1000。zkStore 刚开始运行的时候负载较低 TPS 测得的值会偏高,长时间稳定运行之后测得zkStore的TPS为3。
从而系统的总最大TPS满足如下公式:
依据该公式,以及测试得到的数据,最大可并行11174个zkStore,也就是按照地理位置可以将服务划分成11174个区域,每一个区域的均运行着TPS为3的zkStore模块,系统理论情况下总共达最大可以到了33522的TPS,远大于仅仅使用以太坊值为15的TPS。
2.2 侧链的设计
若在该侧链中采用类似公链的 POW(工作量证明)共识机制构建,通过算力来决定记账权的归属,使用账单内容和种子构成的块的 hash 值的方式进行算力加密(该种子需要全系统构成的算力总量求解10分钟才能得到的结果,从而让伪造变得几乎无法完成)。该方案最具有去中心的特性但伴随的大量的算力浪费。且若考虑在本系统中采用该方案打造侧链,会因为参与的节点不及公链的规模导致构成的算力规模不大,容易遇到51%攻击的问题。且基于POW的侧链会导致TPS不够。因而不能使用 POW 的方式构建侧链。如果通过基于 POS(权益证明)或 POA(权威证明)的方式打造侧链,虽然牺牲了区块链的一些去中心化的特性,但是可以大大地减小算力的消耗。POS 基于选举验证者的策略,验证者需要在该系统中拥有一定数量的货币,而这些货币作为保证金,当验证者验证了虚假的交易的时候,其保证金将会受到惩罚,其失去的钱会大于通过虚假交易获得的利润。也可以通过POW的策略,通过抵押信誉的方式,进一步牺牲了一些去中心化的特征,但是不需要节点间的通信,且仅需要更少的算力,因此具备了更高的TPS和更低的Gas费用。
2.3 zkStore的设计
zkStore 是基于 zkRollup 的思想通过零知识证明的原理[6]实现的。上链前有两种证明的策略,欺诈证明和有效性证明,而欺诈证明是一种乐观的方式,认为很少会发生作恶的情况,因此不需要对每一笔交易耗费算力去做零知识证明,而是交易在上链之前都会“公示”一段时间,而这一段时间该交易的涉及人发现作恶行为,便可以提出欺诈证明,从而否决掉该交易,但是存在涉及 DDOS 攻击等因素,导致交易无法进行提交欺诈证明导致缺乏安全。而有效性证明则是所有交易的上链必须提交零知识证明,开销大但是安全性高[7]。因此 zkStore 选择的是有效性证明方案。
基于 VitalikButerin 的研究[8],零知识证明具体有两种实现方法,交互性和非交互性,而交互性则是通过若干次询问,让欺诈的概率降到可以忽略的时候,从而信任对方。而 zkStore 则是采用非交互的方案。非交互方案并不是指完全不交互,而是仅交互数次便完成了零知识证明,虽然消耗额外的算力,但是证明的通信过程会变得简洁。其本质原理是 ZKSNARK 中的核心思想,计算机无法在多项式的时间复杂度内求出椭圆曲线的对数问题从而确保安全[9]。
2.4 公链与侧链之间的跨链协议
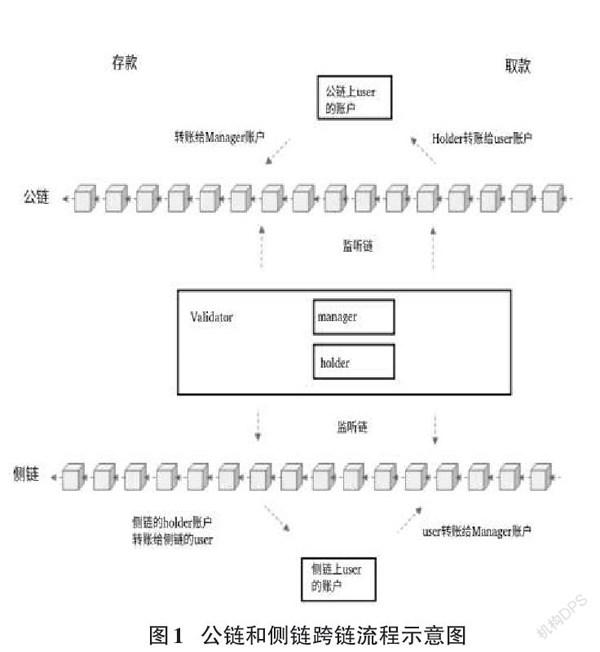
公链和侧链之间的转账通过跨链协议实现,跨链使用 Validator 模块完成。如图1所示,公链和侧链均有一个 Validato r模块的账号分别为 Manager 和 Holder,该模块将会监听公链上的所有往 Manager 转账的交易。当出现公链上的用户往公链上的 Manager 账户转账,则会在侧链的 Holder 账户中往侧链的上该用户对应的账户转账,即完成存款操作。当出现侧链上用户往侧链上的 Holder 账户转账时,则会在公链的 Manager 账户中往公链的上该用户对应的账户转账,即完成取款。所有公链的交易都是公开可查的,并且所有侧链上的交易必须公开才能被确认,因此 Validator 伪造任何的交易记录都会和公链上的交易记录无法形成匹配,从而无法伪造,因此该方案具备安全性。
2.5 侧链和 zkStore 的关系
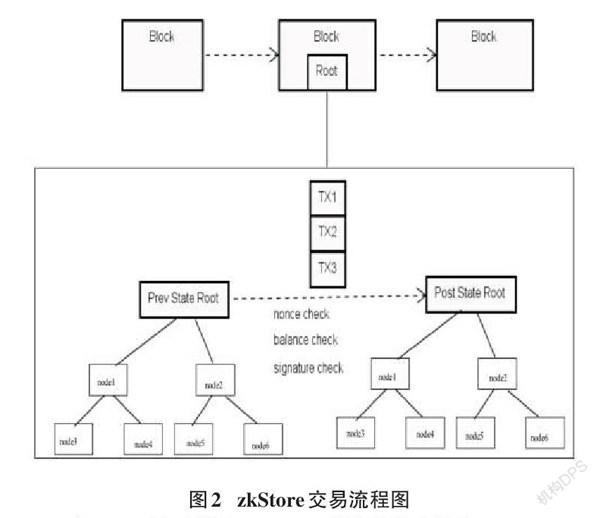
侧链上会运行大量的 zkStore,每一个 zkStore 负责该区域的交易的收集,而 zkStore 主要功能就是收集交易并打包生成 proof,然后提交至侧链的合约进行校验。zkStore 收集交易并进行零知识证明的运算都不需要通过侧链,在链下完成。每一次的状态转变都需要提供零知识证明,由侧链上的合约进行验证,只有验证通过才能更改状态。合约不需要单独校验每笔交易的合法性,只需要校验 proof 是否有效,从而降低了链上 gas 消耗。
1)zkStore 链下利用 Merkle tree[10]存储账户状态。
2)由 zkStore 中的交易汇总器(Operator)收集用户的交易(TX1,TX2,TX3......)。
3)交易收集完成后 Operator 会执行每个交易(校验余额,校验nonce,校验签名,执行状态转换)。
4)当交易执行完成后会产生一个新的 Merkle tree Root。
5)为了证明链下状态转移是正确的,Operator 会在交易执行完成后生成一个零知识证明的 proof。
6)如图2所示,Operator 把 prev state root,post state root,交易数据和 proof 证明提交至侧链的合约。
7)合约校验 proof ,通过后,将新的状态写入到链上。
3 云存储系统的设计
3.1 整体设计思路
在存储部分的目标是实现一个基于区域的、去中心化、低存储费用、支持分享资源的系统。该系统与传统的中心化存储系统(百度网盘、腾讯网盘、115网盘等)不同,该系统不依赖传统的中心化集群的机房的存储和带宽资源,而是利用零散在各地的空闲带宽和存储资源,提高了整个网络的利用率。对比现有的中心存储解决方案来说,隐私程度更高。该文件系统中,用户无需暴露任何身份信息,通过不需要第三方参与的账户创建模式,保证了整个系统中的匿名性[11-12]。本系统与有相同研究方向的 IPFS 项目不同,本系统参考了部分 IPFS 的思想,并且在此基础上进行了划分区域,提高了服务的质量且降低了服务的成本。并且通过多副本的方式,提高了文件的可靠性。针对隐私性高的文件,将会在每一个Miner中存储该文件的非全部分片,从而任何一个Miner均不能还原该文件,保证了文件的隐私性。通过参考IPFS实现的复制证明和时空证明的确认机制以及王玉秀[13]等人的 merkle树校验方案,实现高的安全性的检验策略,以防止女巫攻击(Sybil Attack)、外部数据源攻击(Outsourcing Attack)、生成攻击(Generation Attack)的功能。存储费用的支付参考微支付[14]的思路。该文件存放若干天,每一天都需要进行若干次时空证明。每一次Miner通过时空证明后支付一部分的费用方式取代一开始就付完全部费用的方式。从而降低无论哪一方发生作恶时的损失。从TPS角度考虑,本系统可以支持最大的文件数量满足如下公式。
其中TPS表示系统总共的 TPS,由上文推导得为33522,Avgcnt 表示平均文件的分片数量,D 表示每一天文件需要进行时空证明的次数。Avgcnt 通常平均为64,D 通常为1,因此该系统最大支持45254700个文件。
本系统可以用于多种场景,文件分享,文件的存储备份,以及视频类文件的点播等。
3.2 云存储系统的结构
首先通过域名解析,让 User 和 Miner 获得一些 Bootstrap 節点的地址。从而接入整个系统。当用户和Miner接入系统后,将会形成如下所示的结构(图3仅代表各个角色之间的关系,并不代表数量关系,每一个角色在系统中都会有多个)。
如图3所示为系统的整体结构,各个角色的功能如下介绍:
Indexer:索引者,主要功能是内置了一个 bitmap,bitmap 记录每个文件的每个分片存储在哪一个 Miner 上。User 上传的文件是分成许多分片的,而这些分片会分散在许多 Miner 之间。从而需要 Indexer 进行索引。 该模块由索引矿工运行。
Bootstrap:用于服务发现,提供接入系统的User 以及 Miner一个List(列表),该列表中包含了该系统中其他节点以及indexer和verifier的地址。
Verifier:用于验证 Miner 以及 User 是否作恶。当 User 上传了文件后,则需要通知 Verifier 去检验文件是否真实的存在于 Miner 中。而其中对于 Miner 是否真的存储了这个文件以及Miner是否真的存在女巫攻击等行为,通过复制证明和时空证明的方法实现。
Miner:矿工的客户端,定期接受 Verifier 的检查。接受到用户的存储请求后,接收用户的文件分片并存储。对于高隐私度的文件每一个Miner都会存储每一个文件的部分分片。从而有两个优点,第一是安全性高,任意一个 Miner 均不能获得完整的文件数据,第二是传输效率高,文件可以从多个 Miner 同时下载。
User:用户的客户端,当上线的时候,会通过 Bootstrap 发现服务节点,然后需要上传文件时,与 Indexer 协调分片信息以及每个片存放的 Miner,而后连接 Miner 通过直接上传和 Miner间的互相的传输并完成本次存储。分享则是产生分享码,该码可向其他 Miner 证明自己拥有文件的下载权利,从而别的 User 可以依据该分享码进行下载。下载时,通过调度算法,从多个 Miner 同时下载。
3.3 系统传输模型
从实际角度分析,用户侧的流量成本是最高的,因此需要让用户侧的传输量最少,在文件需要进行多副本存储的情况下,不能让用户对这个文件进行多次上传。采取如下策略,每当用户上传文件的一个分片的时候,通过先将该分片上传至一个 Miner,然后通过 Miner 将该分片分发给其他的 Miner。由于是基于分片级别的转发,当收到一个文件的分片的时候,将会立即进行转发,因此上传一个副本和上传多个副本的耗时相差不大。用户还需将该分片的 merkle 树的树顶结点的 Hash 值发送给 Verifier,而后最开始获得分片以及获得副本的Miner 需要对 Verifier 进行存储证明和时空证明。从而使用户上传了一份文件但是完成了多副本的存储。
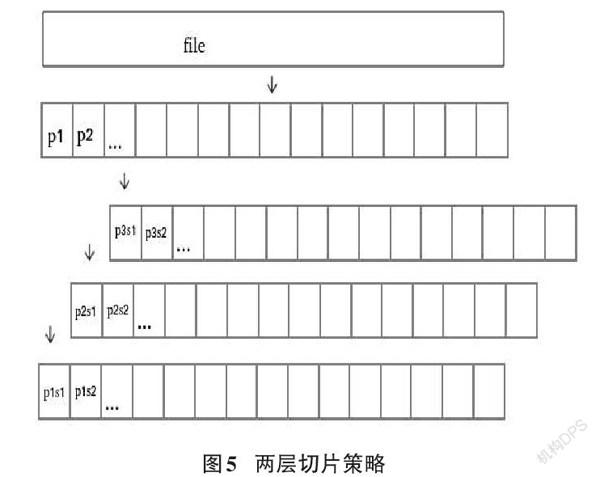
而当文件较大的时候,会出现文件切片数目太多,从而会导致 indexer 的开销较大,因为 indexer 需要支持查询文件的每一个分片在哪些Miner上进行了存储,分片数量太大将会需要indexer更大的存储能力和更高效的查询能力,并且针对每一个分片需要进行一次证明的生成,导致整个系统负担太大。为了减小分片数量,如果将文件的每一个分片的大小设置的更大,则会导致传输的成本增加,且对于在线播放等功能造成较大的延迟问题。因此通过二级分片的方案。先对文件进行第一次切片,保证文件的存储以第一级分片为单位进行,从而使indexer的索引仅仅需要提供第一级分片的索引即可。而传输的时候针对第一级分片进行第二次分片,从而减小传输时的延迟以及校验的复杂程度。
该系统的冗余率主要取决于,indexer 的索引开销,以及 miner 和 user 之间传输协议的开销,通过 iptables 流量统计的方式,抓取该程序的通信数据,得到表3所示的数据,当传输的文件较小的时候,会导致因为 indexer 的索引开销相比较大而造成较高的冗余率,当文件大小大于10M的时候,系统的冗余率趋于稳定。
3.4 下载调度算法
文件的下载有两种调度算法,稀缺性优先和紧急度优先,分别对应两种不同的场景。
稀缺性优先适用于普通的文件下载,普通的文件下载的时候,考虑到 Miner 可能会出现掉线或者被许多 User 连接导致网络拥堵。因此分配给每一个空闲 Miner 下载的分片,选择下载该 Miner 拥有的但是全局最稀缺的分片。从而使稳定性最高、完成时间的期望最短。其核心逻辑即为优先把稀缺的部分先下载完成,而非稀缺的部分如果出现一些 Miner 的波动,仍然可以通过别的 Miner 下载。
如下述例子所描述的场景,假设如分片1在 A、B、C、D 四个 Miner 中有备份,分片2在 B、C、D 三个 Miner 中有备份,分片3在 A、B 两个 Miner 中有存储,分片4在A中有存储。因此基于稀缺性优先的策略。此时选择 Miner A 下载分片4,因为分片4仅仅 A 中有备份,全局层面最稀缺。分配 B 下载分片3,因为仅仅在 A 与 B 中存在分片3,而 A 暂时为忙碌状态(下载分片4),所以在此情况下分片2能下载的只有 Miner B,因此优先使用 MinerB,然后需要分配 Miner C 和 Miner D,而 Miner C 与 Miner D均拥有分片1与分片2,则会随机分配从 C 中下载分片1,分片2将会从D下载。当有Miner下载完资源的时候,若还有新的分片也会按照上述策略进行继续分配。
当用户存储的视频类的文件,需要边下边播,则采用紧急度优先算法,紧急度优先算法的思路如下:
视频类文件的切片存在于各个 Miner,同时从这些 Miner中进行多路下载,从而获得一个较高的下载速度,而针对这个下载的过程,采用紧急度的优先调度算法。该策略是分别针对每一个分片进行决策,决策分片下载源时,首先计算所有 Miner 预期下载完成该分片的时间,选择预计最早完成的 Miner 进行下载。而每一次选择之后,该 Miner的任务列表中就加入了該分片的计划,而下一个分片调度时,要在上一个分片的调度结果上进行调度。如图6所示,每一个 tunnel 对应一个 Miner,默认对于该文件的前26个分片,这些分片在6个 Miner 上均有储存。
当调度完成 a、b、c 分片的时候,d分片会在a、b、c调度结果上继续计算,通过 tunnel1、tunnel2 下载,要先等待之前分片下载完成,因此预计完成为2s的时刻,而 tunnel3与tunnel4 则是速度较慢,分别要2s和4s时刻完成。tunnel5 则是在1.5秒时刻完成,tunnel6 为4s时刻完成,因此该分片将会调度到 tunnel5 下载。依据该算法在所有miner均拥有所有分片的情况下第N片分片的期望到达时刻为
其中size_i表示该分片i的大小,speed_i表示第i个下载链路的速度,m为总共Miner的数量。
4 结束语
本研究实现了一个基于区块链技术的区域共享型云存储系统,致力于为用户在某个特定的区域内提供服务,在该场景下的区块链扩容技术在实验室环境以及理论推导均有较好的TPS指标。系统核心技术主要由传输策略、检验策略、区块链扩容组成。可解决传统中心化云存储的数据不安全、价格太高的问题。
该系统还可以应用在流媒体平台的音视频加速、用户数据的加密存储等领域,可提升区块链的底层平台服务水平,进一步促进新型共识算法、链上数据保密等区块链服务发展。
从模式上来看,本项目通过利用区块链的激励系统刺激闲置的海量带宽与存储资源的共享,解决了传统的中心化云存储的价格太高的问题。
用户可以用更低廉的价格获取更优质的服务。该研究旨在为云服务的模式提供新的思路,面向广大开发者,可依赖本研究提供的去中心化存储资源和思路,在上层构建出更丰富的存储应用,比如去中心化的云计算,去中心化内容分发网络等。
参考文献:
[1] 苗齐.基于IPFS优化的区块链物流信息平台[J].电脑知识与技术,2021,17(11):257-259.
[2] 丁博文,徐跃东,王亮.IPFS网络内容和性能测量[J].计算机工程与应用:1-14.[2020-12-07].http://kns.cnki.net/kcms/detail/11.2127.TP.20210420.1330.060.html.
[3] 石秋娥,周喜,王轶.基于去中心化索引的IPFS数据获取方法研究[J].计算机工程与应用:1-10.[2020-12-07].http://kns.cnki.net/kcms/detail/11.2127.TP.20210419.1450.073.html.
[4] 李雯林.以太坊吞吐量瓶颈分析与优化研究[D].湘潭:湘潭大学,2020.
[5] Lepomäki L,Kanniainen J,Hansen H R.Retaliation in Bitcoin networks[J].Economics Letters,2021,203:109822.
[6] Miers I,Garman C,Green M,et al.Zerocoin:anonymous distributed E-cash from bitcoin[C]//2013 IEEE Symposium on Security and Privacy.May 19-22,2013,Berkeley,CA,USA.IEEE,2013:397-411.
[7] StarkWare.Validity Proofs vs.Fraud Proofs[EB/OL].[2020-10-23].https://medium.com/starkware/validity-proofs-vs-fraud-proofs-4ef8b4d3d87a.
[8] VitalikButerin.Quadratic Arithmetic Programs: from Zero to Hero[EB].[2020-10-23].https://medium.com/@VitalikButerin/quadratic-arithmetic-programs-from-zero-to-hero-f6d558cea649.
[9] 黎琳,张旭霞.zk-snark的双线性对的国密化方案[J].信息网络安全,2019(10):10-15.
[10] 胡逸飞.基于区块链的数字证书审计技术研究[D].合肥:中國科学技术大学,2019.
[11] 刘敖迪,杜学绘,王娜,等.区块链技术及其在信息安全领域的研究进展[J].软件学报,2018,29(7):2092-2115.
[12] 祝烈煌,高峰,沈蒙,等.区块链隐私保护研究综述[J].计算机研究与发展,2017,54(10):2170-2186.
[13] 王玉秀,杨青,程伟,等.基于格的线性同态签名在云存储数据动态验证方案中的应用[J].中国科技论文,2016,11(20):2381-2386.
[14] 刘怡.基于存储证明的区块链数字内容交易平台设计与实现[D].北京:北京邮电大学,2020.
【通联编辑:谢媛媛】
收稿日期:2021-06-20
基金项目:上海市科学技术委员会科研项目“基于区块链的高可用分布式存储与分发网络平台”(19511102300)
作者简介:刘峰(1982—),男,上海交通大学硕士,主要研究方向为区块链。