基于地表覆盖及夜间灯光的分区人口空间化
——以京津冀地区为例
2021-12-17金耀李士成倪永杨楠
金耀,李士成,倪永,杨楠
(1.中国地质环境监测院,北京 100081;2.中国地质大学(武汉)公共管理学院,武汉 430074;3.中国环境监测总站 国家环境保护环境监测质量控制重点实验室,北京 100012)
0 引言
人口空间分布形态可以刻画人类活动的强度和范围,是研究人地关系的重要指标,其广泛应用于区域规划、资源配置、政府决策、灾害评估及生态保护等各个领域。掌握和研究人口信息数据可以为区域协同发展研究、总体规划等工作提供科学支撑。传统的人口数据主要来源于人口普查和年度人口统计年鉴数据,通常以行政单元逐级汇总而来,存在分辨率低、更新周期长、空间粒度粗的问题。此外,在进行空间分析或与其他数据融合时,存在行政单元和自然单元边界不一致、受行政界线变迁影响等问题[1-3]。人口数据格网化,是按照数学模型将基于行政区的人口数据分配到格网中,实现统计单元由行政单元向格网的转换[4],能直观、多尺度地表达人口的真实分布,是对统计数据的细化和补充,已经成为人口空间分布研究信息获取的主要手段之一。
人口格网化的研究历史较早,可以追溯到1936年Wright[5]使用地形图估算各类型居民点人口密度,将分区密度制图理念引入人口空间分布研究中,这成为后期人口数据格网化的主要理论依据。此后,国外学者利用遥感数据、土地分类数据建立人口分布模型来研究人口格网化[6-11]。目前,国际上一些科研机构已发布了全球人口空间化栅格数据,如英国南安普顿大学发布的WorldPop世界人口密度数据以及哥伦比亚大学发布的GPW(gridded population of the world)人口数据。
国内也有很多人口格网化方面的研究。早期的学者应用面积权重模型进行人口数据格网化,如吕安民等[12]提出的面积内插法和范一大等[13]提出的面积权重法,该类方法未考虑影响人口空间分布的环境因素。后来有些学者通过建立环境因子模型研究人口数据格网化,如文献[14-15]基于地表覆盖、河流及道路等环境因子进行人口格网化,该方法模型影响因子较多,不易确定各因子的权重系数。夜间灯光数据可以指示区域社会经济发展及人类活动,文献[16-17]采用夜间灯光进行人口模拟,该方法虽参数少,但是在人口高密度的城市地区及人口低密度的乡村地区误差较大。因此,文献[18-19]把地表覆盖类型和DMSP/OLS夜间灯光数据结合进行人口格网化研究。随着新一代夜间灯光数据NPP/VIIRS的应用,很多学者开始采用NPP/VIIRS数据进行人口格网化研究[20-23],并取得了较好的模拟效果。胡云锋等[24]对比了DMSP/OLS和NPP/VIIRS夜间灯光数据进行人口模拟,认为NPP/VIIRS夜间灯光数据更适用于人口数据空间化研究。
地形是影响人口分布的重要自然环境因素,当前基于地表覆盖数据和夜间灯光的人口空间化研究,仅考虑了地表覆盖和夜间灯光数据与人口数量的关系,而忽略了地形因素,这不利于研究范围较大且地形复杂区域的人口空间化研究。基于夜间灯光和地表覆盖的人口空间化模拟误差容易出现在人口密度极低或极高区域,在人口密度差异较大的区域,影响人口分布的主导因子也存各异,使用统一的模型参数较难适配所有的地区。此外,在以往研究中,高分辨率的地表覆盖数据会被重采样为与低空间分辨率夜间灯光数据相同的空间分辨率,这会牺牲原始地表覆盖数据的精度,因此,本文中尝试在模拟过程中采用较高空间分辨率的输入数据。鉴于此,本研究以地形复杂且人口空间分布异质性较高的京津冀地区为例,引入地形和人口密度因子进行分区建模的思路,采用2017年度NPP/VIIRS夜间灯光数据及高分辨率的土地覆盖数据,与区县级常住人口统计数据回归建模,得到高精度的人口空间化数据。本文旨在完善在地形复杂且人口空间分布异质性较高地区的人口空间化的方法,建立京津冀地区2017年度的精细化格网人口数据。
1 研究区与数据来源
1.1 研究区简介
京津冀位于中国华北,包括北京、天津两个直辖市和河北省全境,界于36°05′N~42°40′N,113°27′E~119°50′E之间,面积21.8×104km2。区域东临渤海,西为太行山,北为燕山,地势西北高、东南低,由西北向东南倾斜(图1),兼有高原、山地、丘陵、平原、草原和海滨地貌类型,丰富的地貌类型使得该地区具有代表性。研究其人口空间化,可为其他地形复杂地区的人口空间化研究提供参考。

注:该图基于自然资源部标准地图服务下载的审图号为GS(2019)3266号的标准地图制作,底图无修改。
此外,京津冀地区是华北地区重要的人口聚集地和区域中心,2018年该地区常住人口达11 270.1万人,占全国总人口的8.08%[25],区域平均人口密度达523人/km2。但是该区域人口分布不均衡,既有人口密集的国际化大都市,也有人口稀疏的海滨晒盐场,这给人口格网化增加了难度。此外,人口分布的巨大差异对跨区域人口管理、资源协同配置及城市群产业布局提出了挑战,研究精细化的人口空间分布特征可为京津冀协同发展战略决策提供基础数据和技术支持。吴健生等[26]基于DMSP/OLS夜间灯光、土地覆盖和其他因子数据建模模拟京津冀地区2010年人口数据,模型涉及的参数因子较多,且确定各因子权重所采用的层次分析法与专家打分法比较复杂。王晓洁等[27]采用2000年DMSP/OLS夜间灯光结合2019年的手机定位趋势来模拟京津冀地区2000年人口数据,方法较新颖,但数据的时间一致性还有待商榷。此外,这两项研究模拟的人口数据的年度较早,难以满足当前人口精细化管理对数据的高时效性。因此,本文采用新一代NPP/VIIRS夜间灯光和土地覆盖数据,引入地形和人口密度因子分区,利用逐步回归模型来模拟京津冀地区2017年高精度人口格网数据。
1.2 数据来源
1)NPP/VIIRS夜间灯光数据。NPP/VIIRS是新一代夜间灯光数据,较DMSP/OLS夜间灯光数据具有更高的灰度级和空间分辨率。受到杂散光污染,数据在夏季像元值缺失严重,因此,本文采用了陈慕琳等[28]使用三次Hermite插值法校正的京津冀地区2017年NPP/VIIRS年平均夜间灯光数据。
2)地表覆盖数据(land cover,LC)。本文使用的LC数据来自于清华大学发布的10 m分辨率全球地表覆盖图(FROM-GLC10)[29],时间为2017年,该数据集将地表覆盖/覆被分为耕地、林地、草地、水域、不透水面等十个类别。
3)人口统计数据。本文使用的区县和乡镇人口数据是常住人口统计数据,区县人口统计数据来自京津冀各统计局公布的统计年鉴数据,乡镇人口数据来自《中国县域统计年鉴(乡镇卷)-2018》[30]。
4)行政区边界数据。本文所使用的行政边界包括区县和乡镇行政边界,数据来源于国家地球系统科学数据中心[31-32](http://geodata.cn)。
5)地形数据。本文使用的地形数据是SRTM3(shuttle radar topography mission),空间分辨率为90 m,数据来源于中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn)。
6)WorldPop人口数据。本文使用的WorldPop人口数据是由英国南安普顿大学地理数据研究所发布的,时间为2017年,空间分辨率为3″(约100 m)和30″(约1 km)[33-34],数据来源于WorldPop网站(https://wopr.worldpop.org)。
1.3 数据预处理
本文采用的所有空间数据都转化为Albers-equal-area投影,中央经线为105°E,标准纬线为25°N和47°N。采用双线性插值法将15″空间分辨率的NPP/VIIRS夜间灯光数据重采样为10 m和100 m空间分辨率。采用众数法将10 m空间分辨率的地表覆盖数据重采样为100 m。使用SRTM3地形数据生成地形起伏度(relief degree of land surface,RDLS),计算每个区县的平均地形起伏度和平均海拔(height)。
区县和乡镇行政边界数据分别为2015年和2012年,通过对比参考民政部网站公布的行政区划变更信息,把行政边界数据调整更新到2017年。将人口统计信息与行政边界数据关联,为每个行政区域赋值常住人口,并计算每个区县的人口密度。

表1 数据来源及属性
2 研究方法
首先,分析研究区域县级常住人口数量与各类地表覆盖像元数、地表覆盖夜间灯光指数总量及地形因子之间的相关性,为后期参数选择及模型构建提供依据。然后,利用地形因子和人口密度,对研究区进行分区,再采用多源逐步回归分析,建立各个分区区县人口数量与地表覆盖像元数量及夜间灯光指数总量的回归模型。利用回归模型估算格网人口数量,基于区县人口统计数据对模拟结果进行校正。最后,对人口空间化模拟结果进行精度分析。详细的人口空间化技术路线如图2所示。
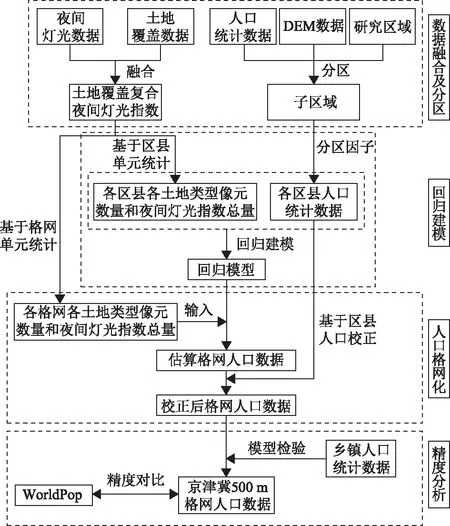
图2 人口空间化技术路线
2.1 数据融合及分区
1)数据融合。土地覆盖可定性地指示人口的空间分布范围,如土地覆盖中的不透水面主要为人造地表,是人类活动的主要场所,湖泊和河流等水域基本无人居住。夜间灯光数据是较综合的指标,涵盖了居民点、交通、社会经济等信息,灯光的强度可以指示人口数量的情况。基于土地覆盖和夜间灯光数据进行建模,模型参数相对较少,易于构建。但是在高人口密度地区灯光强度趋于饱和,且由于夜间灯光数据空间分辨率较大,无法识别出人口数量的差异。此外,土地覆盖数据在分类的过程中会存在一定误差,一些零散的人口聚集点可能无法识别。
因此,把高分辨率的土地覆盖与夜间灯光数据进行融合,生成地表覆盖夜间灯光指数,不仅可以识别散落在耕地、林地及草地上的人口集聚点,还可以细化灯光强度饱和区的人口空间分布情况。土地覆盖数据中的不透水面(impervious surface)与人口分布关系比较密切,耕地(cropland)、林地(forest)和草地(grassland)上会存在零散的人口分布点。因此,从土地覆盖中提取这四类土地类型,并将NPP/VIIRS夜间灯光数据与其进行融合,生成耕地夜间灯光指数、林地夜间灯光指数、草地夜间灯光指数及不透水面夜间灯光指数四个数据。其表达如式(1)所示。
(1)
式中:M为参与构建模型的土地类型个数,这里取值为4;LLCj为第j种地表覆盖类型上的夜光灯指数;LCjk为第k个格网第j种地表覆盖类型;Lightjk为第k个格网第j种地表覆盖类型上的夜光灯指数。
2)基于地形和人口密度分区。在地形地貌复杂地区,地形是人口分布不可忽略的影响因子,研究表明人口分布密度与海拔呈负相关[35],且人口分布向地形起伏度低的地区集中[36]。因此在构建模型前,通过海拔和地形起伏度两个地形因子把研究区划分成了山地和平原区,可以兼顾地形因子对人口的影响。此外,基于夜间灯光和地表覆盖的人口空间化模拟误差容易出现在人口密度极低或极高区域,因此,按照人口密度把研究区再分区,可以确保分区构建的模型在不同人口密度区内达到最佳的拟合效果。
2.2 回归建模及人口空间化
以区县级常住人口数作为因变量,以区县各地表覆盖类型像元数(面积)和各地表覆盖夜间灯光指数总量为自变量,建立逐步回归分析模型,求解模拟参数。为了保证模型估算的人口数量为非负,在进行回归分析时,剔除系数为负的变量,然后将剩余变量再次引入模型进行回归,最终得到的模型所有自变量的回归系数全为正。模型表达如式(2)所示。
(2)
式中:Pi为第i个县级统计人口;M为参与构建模型的土地类型个数,这里取值为4;LCij、LLCij分别为第i个区县第j种地表覆盖类型上的像元总个数和夜间灯光指数总量;aj、bj为回归系数。利用上述结果得到格网尺度人口,计算如式(3)所示。
(3)
式中:Pi k为第i个区县内第k个格网的模拟人口数;LCijk、LLCijk分别为第i个区县第k个格网第j种地表覆盖类型上的像元数和夜光灯指数总量。
通过式(3)初步模拟各个格网的人口数量,采用区县常住人口统计数据对初始模拟人口进行校正,确保县域尺度上汇总的模拟的人口数量与实际统计的人口数量保持一致。校正如式(4)所示。
(4)
式中:P′i k为第i个县内第k个格网上的最终模拟人口数;Pi m为第i个县内第m个格网上的初始模拟人口数;N为第i个区县的格网个数。
2.3 精度评价
对模拟的人口空间化结果采用乡镇级人口统计数据进行检验。本文选择相关系数(R)、均方根误差(root mean square error,RMSE)及平均相对误差(mean relative error,MRE)三个指标来衡量模拟结果的精度。
3 人口空间化结果及精度分析
3.1 人口与人口分布因子相关性
通过相关性分析发现(表2),京津冀地区县级常住人口数量与四类地表覆盖类型的夜间灯光指数总量及不透水面像元数量五个因子显著正相关,与地形起伏度和海拔因子负相关。

表2 各区县人口统计值与各要素之间的相关系数
地表覆盖中的不透水面主要为人造地表,是人类活动的主要场所,与人口数量的相关性大于0.58,通过与夜间灯光数据融合,其相关性提升到了0.81以上。而地表覆盖中的耕地、林地及草地的像元数与人口相关性较低,通过与夜间灯光指数融合,这三种地表覆盖类型与人口数量的相关性大幅提升。
3.2 分区及模型参数
把平均海拔大于1 km或平均地形起伏度大于50 m的区县划分为山地区,其他区县划为平原区,再以平原区166个区县人口密度的平均值833人/km2为阈值,把平原地区划分为高和低密度人口区。通过地形和人口密度分区,京津冀地区200个区县划分成了3个区,其中34个区县属于山地区(人口密度差距不大,未按人口密度再分区),111个区县属于平原低密度人口区,55个区县属于平原高密度人口区。分区结果如图3所示。
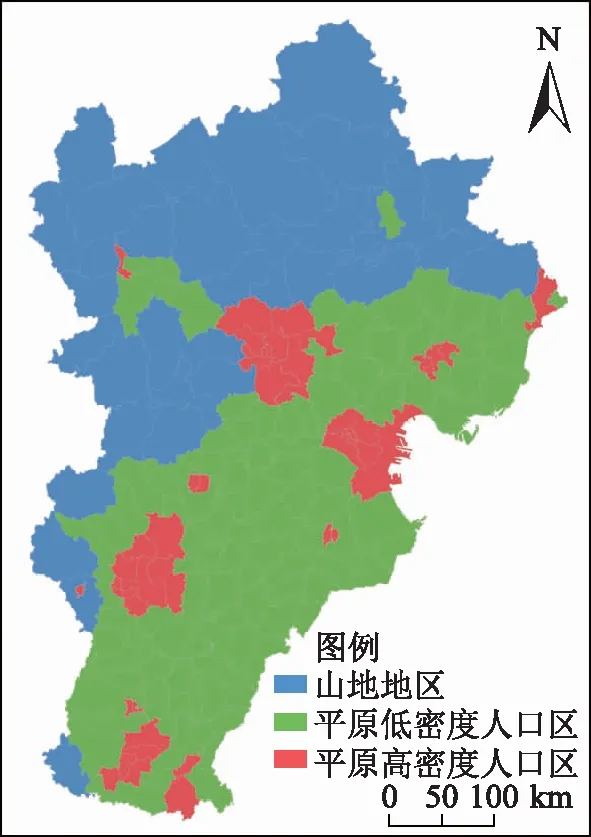
注:该图基于自然资源部标准地图服务下载的审图号为GS(2019)3266号的标准地图制作,底图无修改。
在进行人口格网化的过程中,为了探索分区建模及输入数据的空间分辨率对人口模拟精度的影响。本文中采用了分区/不分区及输入数据为10 m/100 m空间分辨率两个因素,形成四组模拟方案进行人口格网化模拟对比。最终得到回归方程参数如表3所示。

表3 模型回归系数表
3.3 精度分析
1)精度验证及误差分析。随机选取京津冀地区140个乡镇街道作为验证数据,计算乡镇街道2017年常住人口统计数据与格网化人口数据的误差。表4是各组方案模拟结果的对比。由表4可以看出,在其他因子不变情况下,分区模拟的效果要好于不分区模拟;入参数据空间分辨率100 m要优于10 m。因此,最优的模拟方案为在模拟时地表覆盖数据和夜间灯光数据采样为100 m分辨率进行分区模拟,模拟的人口数与乡镇人口统计数的相关系数达到了0.88,平均相对误差为32.71%。通过与已有的同类研究进行对比发现,文献[24]基于NPP/VIIRS夜间灯光与LC数据的川渝地区人口空间化模拟结果的平均相对误差为44.62%。这表明在模拟时,参考地形和人口密度因子分区可以提升基于LC和夜间灯光数据的人口空间化的模拟精度。
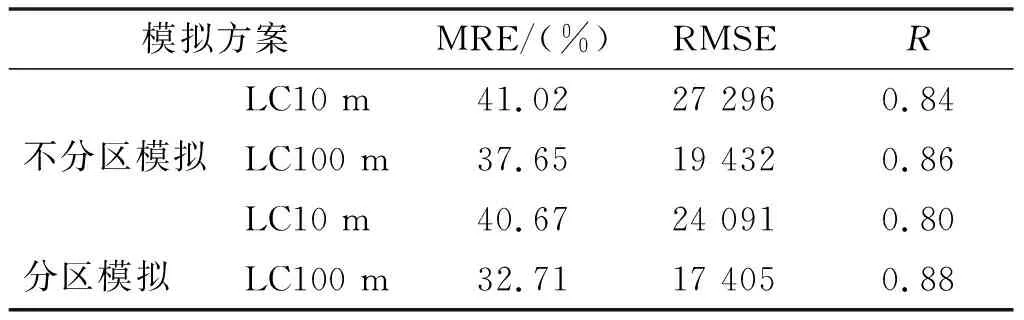
表4 各模拟方案人口空间化误差统计表
对分区模拟的相对误差做进一步的分级统计(图4),可以看出人口空间化准确(MRE≤15%)的乡镇个数为42,占总乡镇数的30.00%;人口空间化较准确(15%
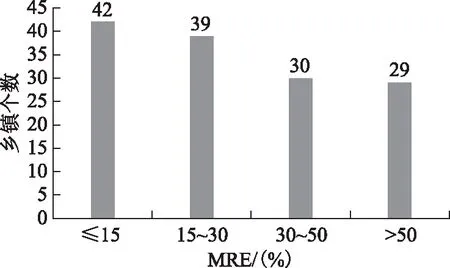
图4 相对误差分级统计表
2)与WorldPop数据对比。
(1)定量误差。以200个区县和140个乡镇的统计人口数据为检验标准,把模拟的最优人口数据结果JJJPop(500 m空间分辨率)与WorldPop(1 km及100 m空间分辨率)进行比较,结果如表4所示。通过分析发现:在整个区域和区县层面,JJJPop精度远优于WorldPop;在乡镇层面,除了WorldPop(100 m)的MRE稍小于JJJPop之外,JJJPop其他精度都优于WorldPop。这是由于本研究是基于区县级别的人口统计数据进行的模拟,且在模拟过程中采用了区县级人口校正,确保了模拟的人口结果在整个区域和区县层面与统计人口基本一致,但在乡镇级别的人口模拟精度会衰减,而WorldPop(100 m)由于有较高的空间分辨率,在乡镇层面的人口统计稍有优势。
(2)区域对比。选择承德市及邯郸市的JJJPop和WorldPop进行区域对比(图5)。WorldPop数据在邯郸市中心人口偏少,在承德市的双滦区和鹰手营子矿区的人口分布偏少,这与实际情况不符,此外,WorldPop(100 m)在局部的人口空间化跳跃性较大。因此,JJJPop在承德市和邯郸市的人口空间分布模拟更为合理。
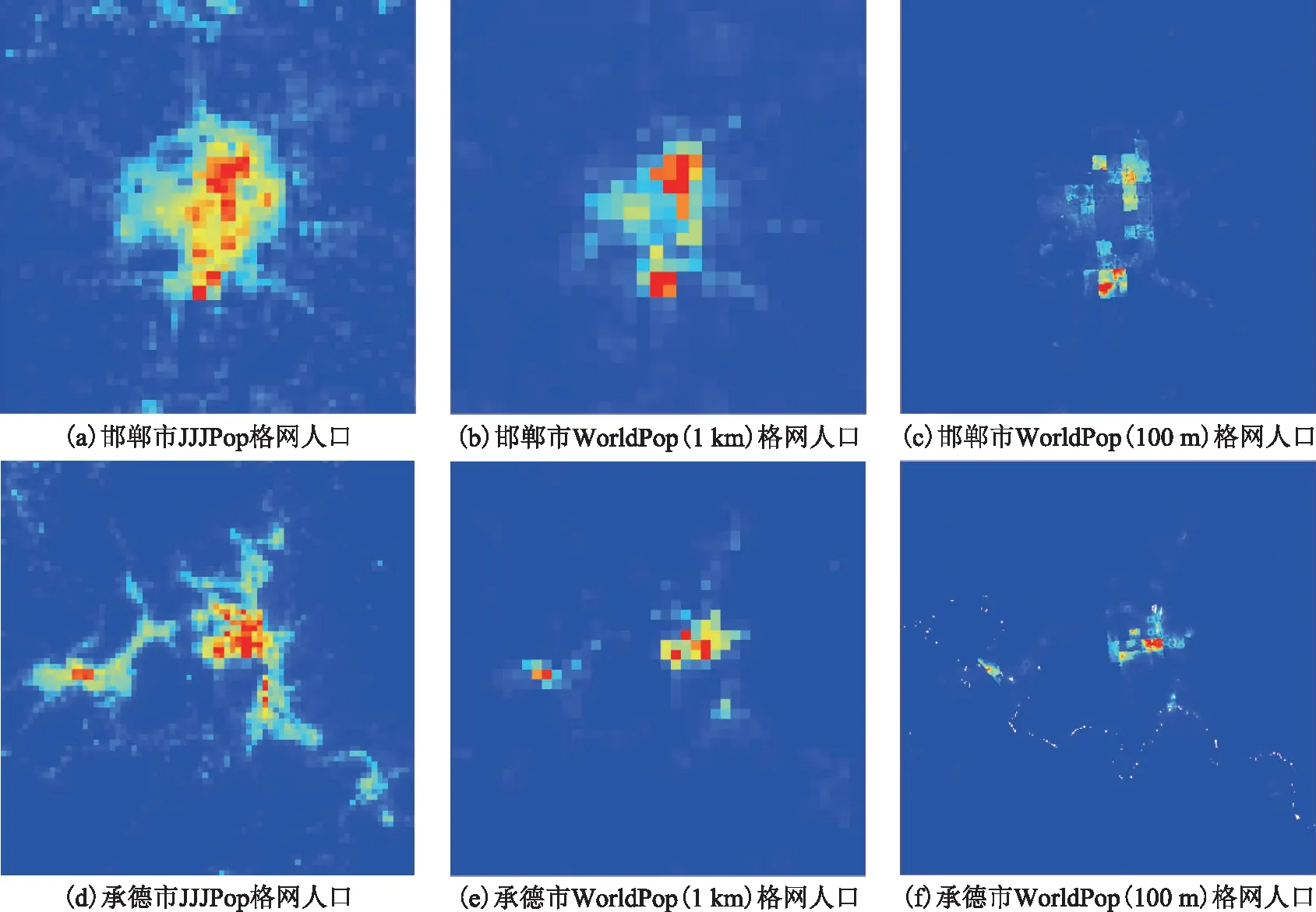
图5 JJJPop与WorldPop模拟对比

表5 两种人口分布数据对比特征
3.4 京津冀地区人口分布特征
图6(a)是最终模拟的京津冀地区500 m格网人口数据。通过分析发现,京津冀地区人口分布大体上呈现西北山地区域人口密度低,东南平原人口密度高。将模拟的格网人口数据与京津冀分区图叠加分析发现:区域10.25%的人口位于占区域总面积45.69%的山地区,人口主要分布于山间地势平坦的谷地。区域43.59%的人口位于占区域总面积44.13%的平原低密度人口区,区域46.17%的人口聚集在占区域总面积10.18%的平原高密度人口区。平原区人口主要位于经济发达的区域中心城市及县城驻地附近,高密度人口区主要位于地级市市辖区及交通干道附近。通过分析图6(b)也可以得到京津冀人口分布的大体趋势,但其详细程度远低于空间化的人口数据,无法体现区县内部精细的人口分布特征。

注:该图基于自然资源部标准地图服务下载的审图号为GS(2019)3266号的标准地图制作,底图无修改。
4 结束语
本研究针对区域地貌复杂且人口空间分布异质性较高的京津冀地区,融合地表覆盖和NPP/VIIRS夜间灯光数据,引入地形和人口密度因子分区建模来模拟人口格网化数据,该方法提高了地形复杂且人口空间分布异质性较高地区人口空间化的精度,获得了京津冀地区2017年高精度的500 m格网人口数据。有以下结论。
1)分区模拟可以提升模拟结果的精度。在建立人口空间化回归方程时,为了确保模拟人口不出现负值,方程的各项回归系数都应该为正数。地形因子与人口数量呈负相关,在以往的人口格网化研究中,为了回归方程系数的非负性,地形因子常被忽略。基于地形因子把研究区分为山地和平原区,可兼顾地形因素对人口分布的影响。此外,按照人口密度分区建模,可以有效区分不同人口密度区的模型特征,实现区域最优模拟,从而提高人口模拟精度。
2)NPP/VIIRS夜间灯光与地表覆盖数据进行融合,可以有效提升地表覆盖数据与人口分布之间的相关性。地表覆盖分类数据在分类的过程中会存在一定误差,一些零星的地表覆盖类别可能无法识别。地表覆盖分类数据与NPP/VIIRS夜间灯光数据融合后,可以识别出耕地、林地及草地上的人口集聚点,提升地表覆盖数据与人口分布之间的相关性。
3)建模时将夜间灯光数据的空间分辨率重采样为与地表覆盖数据分辨率一样的100 m,可以获得较好的模拟效果。原始的10 m地表覆盖数据虽然空间分辨率高,但由于原始地表覆盖数据在生成过程中也存在一定误差,与夜间灯光数据融合后会将这种误差放大,从而影响最终的模拟精度。
4)本研究中模拟得到的京津冀500 m格网人口数据,精度优于WorldPop人口数据,其相对于基于区县统计人口密度数据,可以展现更详细的人口分布特征。京津冀地区人口分布大体上呈现西北山地区域人口密度低,东南平原人口密度高的特点。46.17%的人口聚集在占区域面积10.18%的地区,主要位于地级市市辖区及交通干道附近。
