基于改进时间序列模型的球团厂主引风风量预测
2021-12-17汪向硕
汪向硕
(首钢集团有限公司矿业公司)
首钢集团球团厂二系列采用链篦机—回转窑生产工艺,该工艺是国内外较为成熟的生产工艺。随着球团工艺和技术的不断改进,对球团矿产量和质量要求不断提高。生产线车间主要包含配料室、混合室、造球室、布料系统、焙烧系统、成品系统、风系统。主引风系统[1]是风系统中的关键部分,对球团矿产量和质量的高低产生重要影响。链篦机预热Ⅰ段和抽风干燥Ⅰ段、抽风干燥Ⅱ段风箱的废气汇集后,经由除尘器进行除尘然后脱硫脱硝[2],在主引风机的抽引下,通过烟囱排出。主引风的不稳定将直接影响生产,严重时链篦机内积累的热量将会对设备造成不可逆损坏。将主引风风量序列进行分解可降低主引风波动性、非平稳的特点,首先采用时间序列模型对主引风风量进行预测,同时需要对原始非平稳时间序列进行差分运算,采用模糊熵理论对各分量进行复杂度评估,将复杂度相近的相邻分量重新组合,从而有效降低预测时间并减少计算量,新组成的各个子序列分别建立ARIMA模型进行预测,然后对各分量做残差序列检验,再对存在异方差特性的分量建立ARIMA-GARCH模型;最后线性叠加各分量预测结果最终得到主引风风量预测值。该预测值可为后续生产提供依据,同时检测主引风系统运行情况,从而提高生产效率,降低生产成本。
1 理论基础
1.1 EMD方法原理
经验模态分解(Empirical Mode Decomposition,EMD)是一种自适应时频分析方法,对非线性、非平稳信号的处理具有较好的效果[3]。EMD将不同时间尺度的信号分解为相对平稳的本征模态函数(Intrinsic Mode Function,IMF)。
通过经验模态分解,信号x(t)被分解成n个基本分量c i(t),i=1,2,…,n和1个余项r n(t)的和,记为

1.2 EEMD方法原理
由于经验模态分解方法在分解过程中存在模态混叠现象,因此对该方法进行了改进,即集合经验模态分解方法[4]。该方法是在EMD的基础上加入了高斯白噪声,使信号在不同的时间尺度上具有连续性,因此避免了经验模态分解方法在分解过程中由于IMF不连续造成的模态混叠现象[5],其步骤如下。
(1)在原序列h(t)中加入若干次均值为0,标准差为常数的高斯白噪声n i(t),表达式为
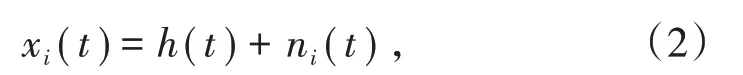
式中,x i(t)为第i次加入白噪声的信号。
(2)对x i(t)进行集合经验模态分解,分解结果如下
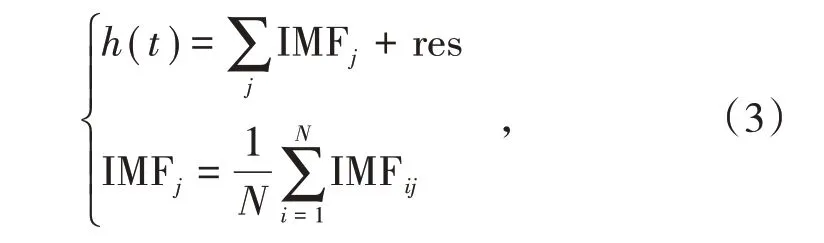
式中,IMFij为第i次加入白噪声分解后得到的第j个本征模态分量;res为剩余分量;N为加入噪声的次数。
1.3 CEEMD方法原理
由于集合经验模态分解方法引入了白噪声[6],虽然模态混叠问题有所改善,但是噪声的引入将对原始信号产生一定程度上的破坏。同时,引入噪声后会存在残余,因而对原序列产生了不良影响。故而引入互补的噪声,这些噪声独立同分布,完全负相关,在重构信号时冗余噪声在很大程度上被消除。CEEMD方法步骤如下。
(1)向原信号中加入m组正负成对的白噪声,从而得到新的混合信号

式中,S为原始信号;N为白噪声;M1、M2为正、负成对的白噪声。
(2)CEEMD的分解步骤与EEMD的分解步骤是相同的,将2个混合信号分解成2组IMF,最后由对应的每一阶IMF求平均值,该平均值就是最终的分解结果。
2 改进时间序列模型
2.1 差分自回归滑动平均模型
自回归滑动平均模型(ARMA)可有效改善时间序列模型的适应性,消除迟延问题,提高预测精度[7]。自回归模型AR(p)和滑动平均模型MA(q)可以认为是自回归滑动平均模型ARMA(p,q)的特例,当q=0时,ARMA(p,q)模型即变为AR模型;当p=0时,ARMA(p,q)模型即变为MA模型。

式中,p为自回归阶数,q为滑动平均阶数,Y t为时间序列,a t为白噪声序列。
由于ARMA模型只能解决平稳过程的时间序列,为了利用ARMA来描述非平稳时间序列,需要对非平稳时间序列进行平稳化处理[8],故而对原始非平稳时间序列进行差分运算,该模型称为差分自回归滑动平均模型(ARIMA)。

式中,W t为随机序列Y t经d阶差分处理后的平稳时间序列;∇d为d阶差分算子。
2.2 模型定阶
对于确定平稳时间序列模型的阶数[9],采用贝叶斯信息准则(Bayesian Information Criterion,BIC)进行模型的定阶,准则定义如下

式中,k为模型的参数数量;n为所选样本数量;L为似然函数。
2.3 模糊熵
模糊熵[10]是对样本熵的改进,也是一种复杂度评估方法。模糊熵运用了隶属度函数用来替代硬阈值方法。对于1个共有N点的采样序列可以表示为,按照顺序的连续性重构生成1组n维矢量,表达式为式中,{ }
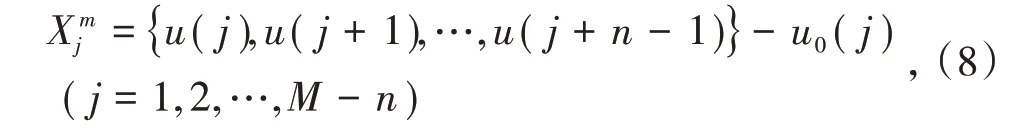
u(j),u(j+1),…,u(j+n-1)为第j个点开始连续n个u的值;u0(j)为均值。
定义2个n维矢量和对应元素差值的最大值为,表达式为
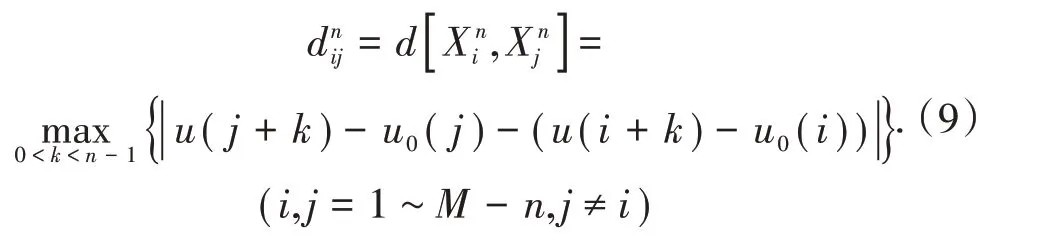
定义2个矢量和的相似度为
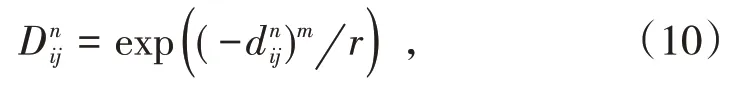
式中,m为维数;r为相似容限度。
定义函数

模糊熵可以由FuzzyEn(m,r,N)表示,最终表达式为

2.4 异方差检验
在时间序列中,残差项中可能存在可利用的信息。因此需要对残差项进行异方差检验,对于存在异方差特性的分量建立ARIMA-GARCH模型。模型GARCH(m,n)对方差的数学表达为

式中,φi、αj均为未知参数;为了保证条件方差是正数,因此要求αj≥0,j=0,1,…,n;φi≥0,i=0,1,…,m。为了保证e t平稳,要求
LM(拉格朗日乘子)检验是常用的自回归条件异方差效应检验方法。LM检验过程如下。
假定检验的原假设为

LM检验统计量为
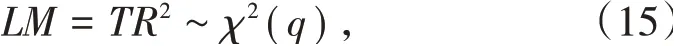
式中,T为样本数;R2为拟合优度。
在原假设下的LM统计量一般渐进服从χ2(q)分布。因此,在给定的显著水平下,如果LM=T R2>χ2(q),那么原假设被拒绝,这意味着存在ARCH效应。反之,则不存在ARCH效应。
3 CEEMD-FE-ARIMA-GARCH模型
主引风风量时间序列具有非线性和非平稳性的特点,本文提出互补集合经验模态分解和改进ARIMA模型相结合的超短期预测模型,步骤如下。
(1)对主引风风量时间序列进行J层分解,将历史主引风风量时间序列分解为具有不同尺度的模态分量,从而降低主引风风量序列的复杂度。
(2)应用模糊熵对各分量进行复杂度评估,对模糊熵值相近的相邻分量做叠加处理,这样可减少计算时间,提高预测效率。
(3)对新组合的各分量建立ARIMA模型,采用贝叶斯信息准则确定模型阶数。
(4)判断新组合的各分量是否存在异方差性,如果存在异方差性,对该分量建立ARIMA-GARCH模型,对各分量进行预测。
(5)将所有分量预测结果线性叠加得到最终的主引风风量预测值。预测模型流程见图1。

4 算例分析
4.1 原始数据
选择首钢球团厂二系列200个主引风风量数据作为训练样本,采样间隔为5 min,进行预测。历史主引风风量数据见图2。
4.2 数据分析
对历史主引风风量序列进行互补集合经验模态分解,从而可以降低主引风的波动性,结果见图3。

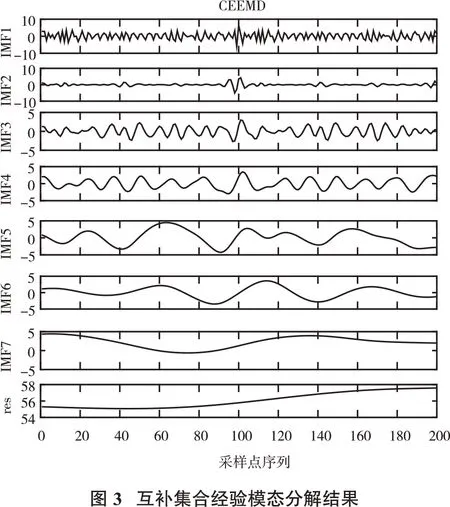
由图3可见,互补集合经验模态分解对历史主引风风量序列进行逐层分解后实现了各个分量的准确分离,从而有效降低了主引风风量时间序列的非平稳特性。由于分量过多,同时会增加预测时间与计算量,故采用模糊熵对各分量做复杂度评估,各分量评估结果见图4。
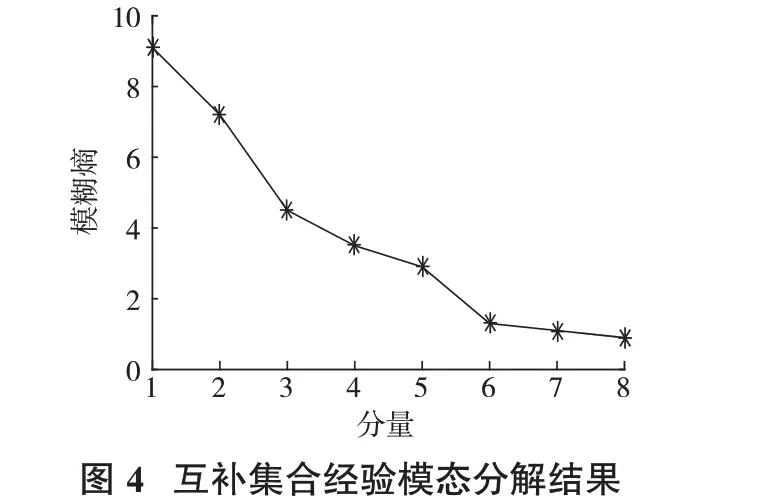
由图4可见,各分量的模糊熵按其顺序呈下降走势,说明各分量复杂度也在不断降低,故将IMF4、IMF5组合成1个新的分量;IMF6、IMF7和res组成1个新的分量,从而降低预测时间和计算量。
4.3 异方差检验
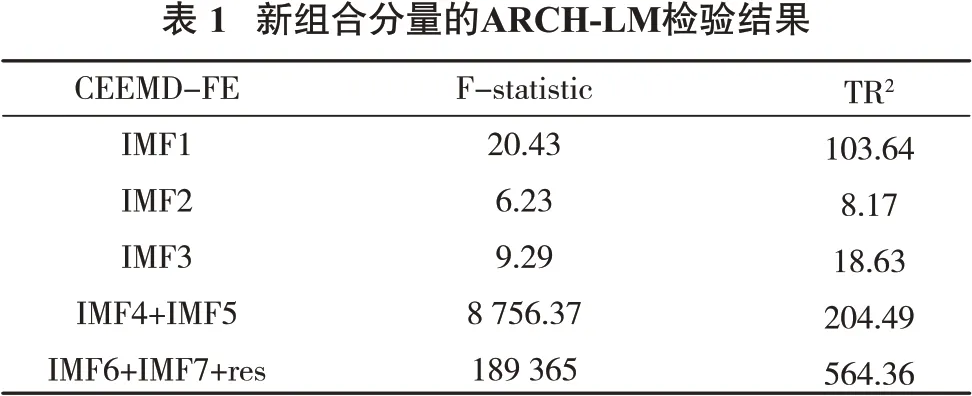
由于多阶GARCH模型参数估计非常复杂且具有多重共线性,因此选择GARCH(1,1)模型。对新组合的各分量进行LM检验,结果见表1。
?
由表1可知,对于LM统计量大于F统计量的分量,原假设H0被拒绝,说明该分量的拟合残差存在自回归异方差效应,IMF1、IMF2、IMF3均存在自回归异方差效应。因此,对上述模型建立ARIMA-GARCH(1,1)模型。
4.4 预测结果及分析
为了判断各预测模型的准确性,应用平均相对误差(MRE)评价指标进行对比分析。
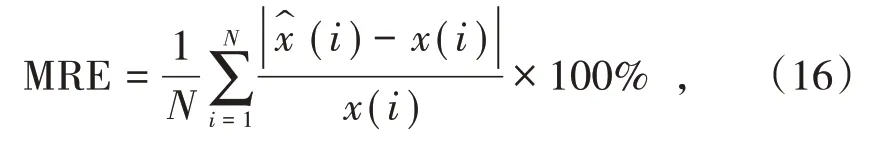
主引风风量预测结果见图5。

由图5可见,模型预测的主引风风量序列与实际主引风风量变化趋势总体一致,本文所提预测模型精度最高。ARIMA-GARCH模型、加入经验模态分解的EMD-FE-ARIMA-GARCH模型、改进经验模态分解的EEMD-FE-ARIMA-GARCH模型、本研究所提CEEMD-FE-ARIMA-GARCH模型的预测误差对比结果见表2。

?
由表2可知,本研究所提预测模型与其他组合预测模型相比具有更高的预测精度,平均相对误差越小,说明预测误差的整体波动越小,预测越准确。因此,该方法为后续生产提供了依据,可有效提高生产效率,降低生产成本。
5 结 论
本文通过互补集合经验模态分解将历史主引风风量分解为若干分量,从而降低其非平稳性;采用模糊熵理论对各分量进行复杂度评估,将复杂度相近的相邻分量重新组合,从而有效降低预测时间并减少计算量,新组成的各个子序列分别建立ARIMA模型进行预测,同时对残差序列中存在异方差特性的分量建立ARIMA-GARCH模型,各分量进行主引风风量预测;再将各分量的预测值叠加得到最终的主引风风量预测值。通过仿真试验可知,CEEMD方法结合了EMD和EEMD 2种方法的优点,不仅消除了EMD方法出现的模态混叠现象,而且避免了EEMD方法在分解过程中产生的重构误差和分解不完整的缺陷,具有更好的分解效果;该预测方法只需少量历史主引风风量数据便可以建立精度较高的预测模型,对球团安全高效生产具有重要意义;该时间序列模型适用于超短期或短期预测,但对长期预测效果不佳,这是该预测模型的不足之处。
