基于大数据分析的潜在固移融合用户挖掘研究
2021-12-16张晴晴韩玉辉程新洲王云云中国联通研究院北京100048
张晴晴,张 涛,韩玉辉,程新洲,王云云,高 洁(中国联通研究院,北京 100048)
0 引言
在整体收入增速放缓、公众市场饱和的大背景下,各大运营商均在探索如何在公众市场实现存量客户价值运营,同时对增量客户进行有效挖掘。其中发展融合业务用户便成为运营商加固维稳存量客户,同时有效挖掘增量客户的有效利器。所谓融合业务,是运营商根据其业务特点将多类产品进行捆绑销售,常见的捆绑策略为将固网产品、移动网产品和IPTV 等产品进行融合,通过各类融合套餐产品的创新性设计可实现客户价值提升,同时提升客户满意度。融合产品将是势不可挡的大趋势,未来运营商的产品将随着业务边界不断扩展向深度融合和广度覆盖方向转变,故对于融合用户的发展和挖掘将是未来运营商客户运营的一项重要工作。
中国联通对于融合捆绑的策略相对于友商起步较晚,虽然也有固移套餐、主副卡(亲情卡)等产品,但整体融合力度稍弱,所以对于融合用户发展的市场空间较大。尤其在携号转网服务全面开放后,大力发展融合业务将有助于中国联通加固维稳存量客户,同时也有助于实现异网拉新。本文基于移动网络大数据和宽带网络大数据的联合分析,针对单移用户的移动网络业务行为特征,构建机器学习模型识别其真实用宽带状态,并推送给市场前端进行精准营销,促进用户进行固移融合套餐产品的迁转。中国联通各省分公司可以根据自身资源禀赋和用户规模占比,分别采取不同的固移用户发展策略。
1 固移融合用户挖掘流程和方法体系架构
为了实现对单移用户中潜在宽带用户的精准识别,本文基于移动网络大数据和宽带网络大数据的联合分析,构建了潜在宽带用户识别的方法体系架构,如图1所示。

图1 潜在宽带用户识别流程
该框架由2 部分组成:线下训练部分和市场推送部分。
a)线下训练部分。主要目的是利用现有的历史数据得到理想的分类模型,并将训练好的稳定鲁棒模型用于现网数据识别,得到潜在宽带用户列表。
b)市场推送部分。将模型得到的后台结果推送到市场前端进行精准营销,市场前端通过不同触点触达用户并进行融合产品营销。由于最终用户是否成功办理转化会涉及各类原因,故前端在接触客户时要分别记录模型预测准确率以及办理意向率,并将结果反馈给线下训练模型,从而实现模型的迭代训练。
2 基于模型的目标用户识别方法
2.1 数据准备
首先进行数据准备,构造模型训练所需的正负样本集合。根据BSS 端用户的签约信息,收集有宽带业务和无宽带业务用户的历史OSS数据和BSS数据。对于无宽带业务用户,仅通过套餐签约识别会出现不准确的情况,要结合家庭关系库以及OSS 用户行为特征来进行准确识别,为模型训练打好数据基础。另外在数据准备过程中的另一个挑战是正负样本不均衡,会导致模型过拟合问题,所以在数据准备阶段要尽可能多的收集正负样本集合。
2.2 特征工程
特征工程是提高机器学习模型表现和准确性的重要步骤。对于潜在宽带用户识别问题,基于对业务目标的理解以及手中掌握的数据,构造特征集合。本文在进行特征选择时,会通过可视化的方式,比较有宽带用户和无宽带用户在各个特征上的差异性,将有明显区分性的特征加入到特征集合中。图2展示了有宽带用户和非宽带用户的小时流量使用对比,可以看到有宽带用户的夜间流量使用有明显的下降特征。图3 展示了有宽带用户和非宽带用户在白天(8:00-18:00)的流量与夜晚流量(19:00-24:00)的流量对比,可以发现无宽带用户无论在白天还是晚上的流量总体消耗都更多,尤其在夜晚会更加明显,无宽带用户与有宽带用户夜晚流量比值为1.6 倍,要大于二者白天流量比值的1.2 倍。其他特征的构造方法类似,这里不再赘述,最终形成的部分用户特征总结如表1 所示,分别构造了O域特征与B域特征共约40个特征。

表1 O域与B域特征工程表

图2 有宽带用户和无宽带用户的小时流量对比

图3 有宽带用户和无宽带用户白天和夜晚流量对比
2.3 模型训练
对于模型训练部分,由于训练集合正负样本的不平衡特性,选择具有类权重参数的Class Weighted eXtreme Gradient Boosting(XGBoost)作为模型来进行模型训练。对于分类中不同样本数量的类别,分别赋予不同权重的方法,具体操作是设置类样本权重反比于类样本数量。XGBoost的最小化目标函数公式如下:

式(1)和(2)分为2 个部分,第1 部分为损失函数,第2 部分为正则化参数。对于XGBoost,在模型训练时,可通过调节参数‘scale_pos_weight’值来平衡正负权重。
2.4 模型评价和输出
在模型评估时,应选择与业务问题相匹配的评估方法。本文中的潜在用户挖掘问题是二分类问题,对于二分类模型,可采用多种不同的评估方式,如AUC(Area Under Roc Curve)、F1 值、查准率(Precision)、查全率(Recall)等。为了体现模型预测的准确性,将实例分为正类(Positive/+)或负类(Negative/-),对于模型是否预测正确,可形成混淆矩阵,基于得到的混淆矩阵结果可计算F1值、查准率和查全率。三者的计算公式如下:

根据交叉验证模型在测试集上的表现,得到模型评价指标结果:Precision 为51%,Recall为36.8%,F1值为42.4%。图4 显示了Roc 曲线结果,AUC 值为0.648。同时为了验证模型的泛化能力,绘制了学习曲线,学习曲线是将训练集误差和交叉验证集误差在不同样本点数量下的误差进行对比,从图5 的学习曲线结果来看,模型具备较好的泛化能力。
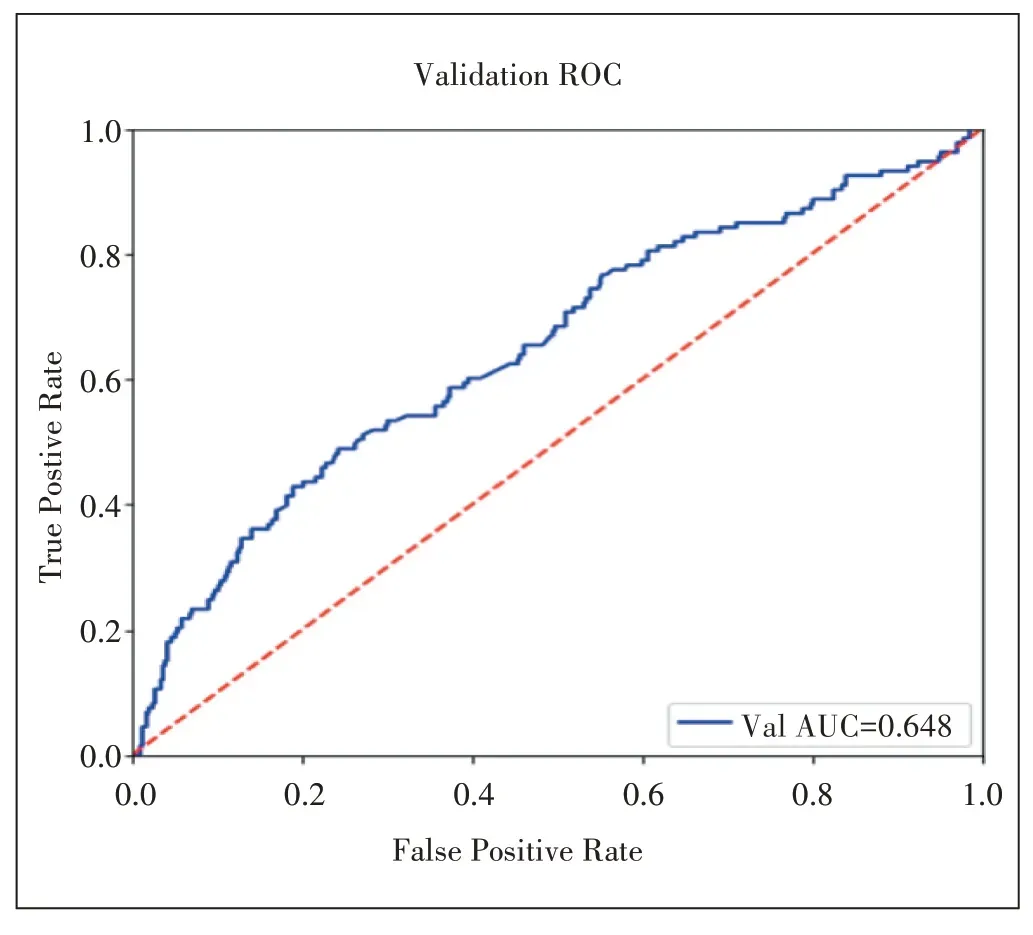
图4 潜在宽带用户识别Roc曲线
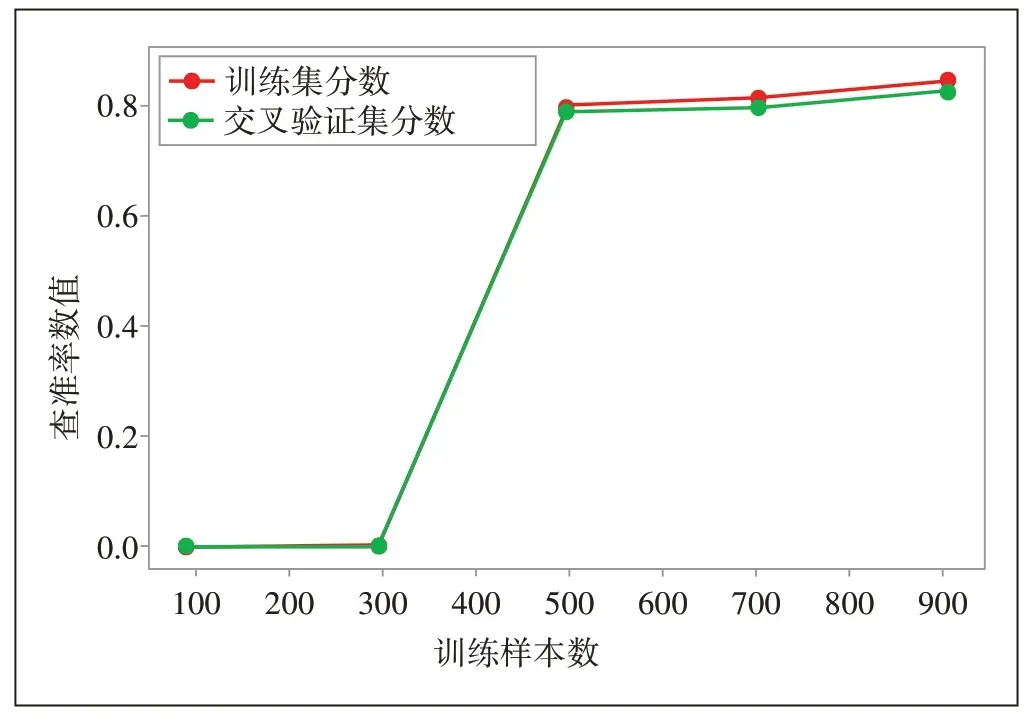
图5 潜在宽带用户模型学习曲线
3 现网验证效果
将形成的潜在用户列表推送到市场前端开展各种形式的触达及融合产品推广活动,在触达过程中记录用户真实宽带状态,以此作为2 种方法的直接验证指标。图6 为验证效果。由结果可以看出,命中到的真实无宽带用户及有宽带用户比例均高于随机组,说明方法是有效的,能够对现网中用户的真实状态进行更有效的判断。

图6 模型识别方法现网验证效果
4 结论
运营商发展融合业务用户是势不可挡的大趋势。本文基于移动网络大数据和宽带网络大数据的联合分析,提出基于模型的潜在固移融合目标用户挖掘方法体系可以显著提高目标用户的识别率,同时将结果推送到市场前端进行精准营销,促进用户进行固移融合套餐产品的迁转。现网实际验证的结果表明,运用本文提出的方法发展固移融合用户,不仅可以提升单用户ARPU 值,也有助于提高用户体验和用户忠诚度。在后续的研究中,根据市场前端的反馈,将对算法进行不断迭代,进一步提升整体模型的精准性。
